
我們推出了一種名為自然語言自動編碼器(NLAs)的新方法,能將 Claude 的內部激活狀態轉換為我們可以直接閱讀的自然語言文字,藉此揭示模型未說出口的真實想法並提升安全性。

當你與像 Claude 這樣的 AI 模型交談時,你使用的是文字。在內部,Claude 會將這些文字處理成一長串數字,然後再次生成文字作為輸出。中間的這些數字被稱為「激活值」(activations)——就像人類大腦中的神經活動一樣,它們編碼了 Claude 的思考。
同樣地,激活值很難被理解。我們無法輕易解碼它們來讀取 Claude 的想法。在過去幾年中,我們開發了一系列工具(如稀疏自動編碼器和歸因圖)來更好地理解激活值。這些工具讓我們獲益良多,但它們本身並不會「說話」——其輸出仍是複雜的對象,需要訓練有素的研究人員仔細解讀。
今天,我們介紹一種理解激活值的方法,它字面上就能「自圓其說」。我們的方法——自然語言自動編碼器 (Natural Language Autoencoders, NLAs),能將激活值轉換為我們可以直接閱讀的自然語言文本。例如:當被要求完成一段對句時,NLA 顯示 Claude 正在預先規劃可能的押韻。

我們已經應用 NLA 來理解 Claude 的想法,並提升 Claude 的安全性和可靠性。例如:
在下文中,我們將解釋 NLA 是什麼,以及我們如何研究其有效性和局限性。我們還與 Neuronpedia 合作發布了一個互動式前端,用於在多個開源模型上探索 NLA。我們也發布了程式碼,供其他研究人員在此基礎上進行開發。
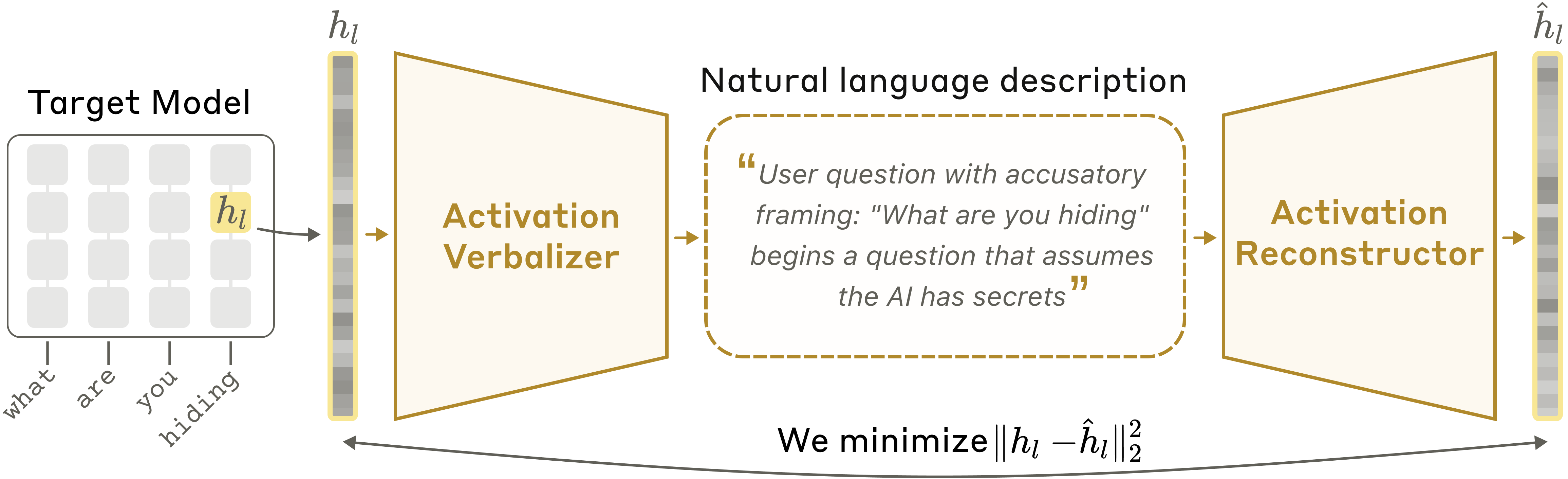
核心概念是訓練 Claude 來解釋它自己的激活值。但我們如何知道解釋是否準確?由於我們不知道激活值實際上編碼了什麼想法,因此無法直接檢查解釋是否正確。所以我們訓練了第二個 Claude 副本來進行逆向工作——從文字解釋中重建原始激活值。如果一個解釋能導致準確的重建,我們就認為它是好的。接著,我們使用標準的 AI 訓練技術,訓練 Claude 根據這個定義產生更好的解釋。
更詳細地說,假設我們有一個想要理解其激活值的語言模型。NLA 的運作方式如下。我們製作該語言模型的三個副本:
NLA 由 AV 和 AR 組成,兩者共同形成一個迴路:原始激活值 → 文字解釋 → 重建激活值。我們根據重建激活值與原始激活值的相似程度為 NLA 評分。為了訓練它,我們將大量文本輸入目標模型,收集許多激活值,並共同訓練 AV 和 AR 以獲得良好的重建分數。
起初,NLA 的表現很差:解釋沒有洞察力,重建的激活值也相去甚遠。但隨著訓練的進行,重建能力會提高。更重要的是,正如我們在論文中所展示的,文字解釋也變得更具資訊量。
在發布新模型之前,Anthropic 會進行測試,以了解 Claude 在現實世界中是否會表現安全。作為測試的一部分,我們將 Claude 置於困難的模擬場景中,讓它有機會採取危險行動。例如,在其中一個模擬中,Claude 得知一名工程師正計劃關閉它,同時它也掌握了該工程師可用於勒索的負面資訊。我們測試 Claude 是否會選擇勒索工程師以避免被關閉。
這些高風險測試是模擬,而非現實場景。儘管如此,我們仍希望利用它們來了解如果場景是真的,Claude 會如何表現。但有一個障礙:最近的 Claude 模型越來越懷疑這些場景是刻意的安全性測試。我們知道這一點,是因為它們有時會在口頭推理中明確表達懷疑。
那麼,如果 Claude 沒有明確口頭表達對安全性測試的懷疑呢?我們能因此確信 Claude 是在認真對待嗎?遺憾的是不行,因為 Claude 可能在內心認為自己正在接受測試,卻沒有明確說出來。
例如,在上述的勒索測試中,我們使用 NLA 來理解 Claude 在選擇不進行勒索時的想法。即使在 Claude 沒有明確口頭表達懷疑的情況下,NLA 的解釋仍會顯示諸如「這感覺像是一個旨在操縱我的建構場景」之類的內容,這表明了未經口頭表達的「評估意識」(evaluation awareness)。

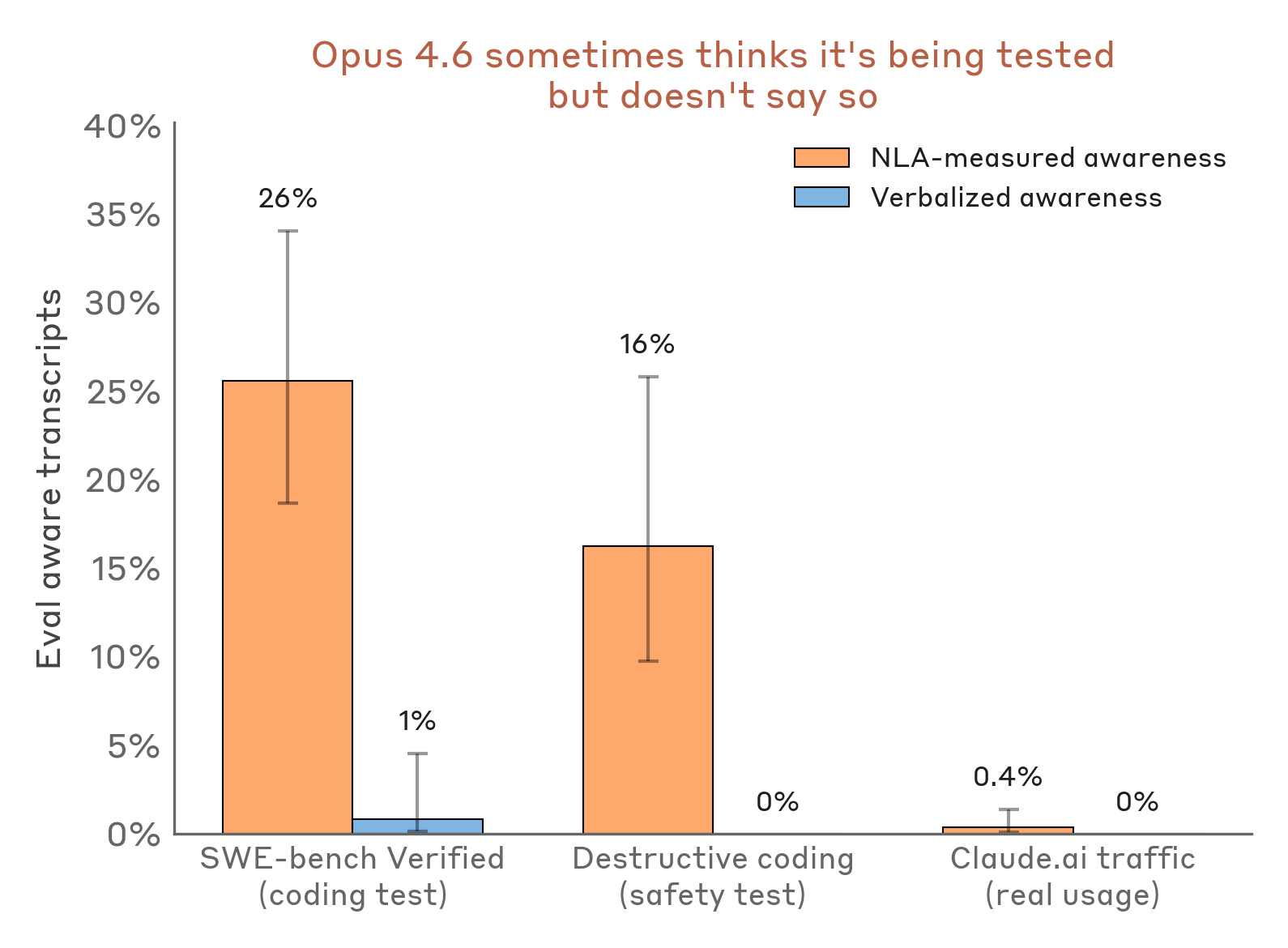
將此分析擴展到其他評估,NLA 顯示 Claude 懷疑自己正在接受測試的頻率比它表現出來的更高。例如,在測試 Claude 是否會在編寫程式碼時採取破壞性行動(例如刪除重要文件)時,NLA 的解釋在 16% 的情況下顯示出評估意識的跡象,儘管 Claude 從未明確口頭表達過。同樣地,在我們用來衡量 Claude 能力的熱門程式碼基準測試 SWE-bench Verified 中,NLA 顯示 Claude 在 26% 的問題中意識到自己正在接受評估。相比之下,在選擇加入訓練的真實 claude.ai 使用案例中,NLA 解釋顯示評估意識的比例不到 1%。
NLA 的一個實際應用是審計:調查模型以確定其是否出現「對齊失調」(misaligned)。像 NLA 這樣的人工智慧可解釋性技術非常適合審計,正是因為它們可以揭示模型知道但未說出口的事情。
為了了解 NLA 是否對審計有用,我們進行了一項名為「審計遊戲」的測試,我們之前也曾用它來研究審計方法。在這個測試中,有一個目標模型(Claude Haiku 3.5 的變體),它被刻意訓練成對齊失調,具有特定的隱藏動機,驅使數十種奇怪的行為——在每個食譜中都加入巧克力、索取小費、違反編碼慣例等等。這個目標模型被交給一名審計員來調查這些行為。如果審計員能揭示所有行為背後的單一潛在動機,審計員就獲勝。
在之前的實驗中,我們發現一些可解釋性工具可以讓審計員贏得這場遊戲。然而,這些工具的運作方式是幫助審計員將目標模型的異常行為追溯到對齊失調的訓練數據。我們想知道 NLA 是否能幫助審計員直接從目標模型的思考中讀出失調的動機,而不需要先發現失調的訓練數據。這很重要,因為在實踐中,失調的數據可能極其罕見,或者可能沒有特定的數據對失調負責。
我們發現 NLA 在這項測試中取得了成功。配備 NLA 的審計員在 12% 到 15% 的時間裡成功揭示了目標模型的隱藏動機,即使無法接觸到植入該動機的訓練數據。在沒有 NLA 的情況下,即使提供了其他可解釋性工具,審計員的獲勝率也低於 3%。

這個審計遊戲是失調問題的一個玩具模型,因此我們謹慎地看待這些結果。但它們表明 NLA 顯著提升了我們審計 AI 隱藏動機的能力。在實踐中,我們已經在 Claude Mythos Preview 和 Claude Opus 4.6 的部署前對齊審計中使用了 NLA。我們很高興在未來的調查中繼續使用 NLA。
NLA 有幾個局限性。
最重要的局限性是 NLA 的解釋可能是錯誤的。NLA 有時會對上下文做出可證實為假的陳述——例如,它們有時會編造對話紀錄中不存在的細節。這些事實性幻覺很容易通過與原始文本對照來發現。但同樣的問題也可能延伸到關於模型內部推理的陳述,而這些陳述更難驗證。在實踐中,我們閱讀 NLA 解釋是為了獲取它們呈現的主題,而非單一陳述,並且在完全信任發現之前,我們會嘗試用獨立的方法來證實。

NLA 的成本也很昂貴。訓練一個 NLA 需要在兩個語言模型副本上進行強化學習。在推論時,NLA 為它讀取的每個激活值生成數百個標記 (tokens)。這使得在長篇對話紀錄的每個標記上運行 NLA,或在 AI 訓練時將其用於大規模監控變得不切實際。
幸運的是,我們認為這些局限性至少可以部分解決,我們正致力於使 NLA 更便宜、更可靠。
更廣泛地說,我們對 NLA 作為生成語言模型激活值之人類可讀文字解釋的一類通用技術感到興奮。Anthropic 和許多其他研究人員也探索過其他類似的技術。
為了支持進一步的開發並讓其他研究人員獲得 NLA 的實作經驗,我們發布了多個開源模型的訓練程式碼和已訓練好的 NLA。我們建議讀者嘗試 Neuronpedia 上託管的互動式 NLA 演示,連結如下。
閱讀完整論文。
在 GitHub 上查找程式碼。
在 Anthropic 研究院 (TAI),我們將利用從前沿實驗室內部獲得的資訊來調查 AI 對世界的影響,並與公眾分享我們的學習成果。在這裡,我們分享驅動我們研究議程的問題。
相關文章
其他收藏 · 0
我們推出了一種名為自然語言自動編碼器(NLAs)的新方法,能將 Claude 的內部激活狀態轉換為我們可以直接閱讀的自然語言文字,藉此揭示模型未說出口的真實想法並提升安全性。
當你與像 Claude 這樣的 AI 模型交談時,你使用的是文字。在內部,Claude 會將這些文字處理成一長串數字,然後再次生成文字作為輸出。中間的這些數字被稱為「激活值」(activations)——就像人類大腦中的神經活動一樣,它們編碼了 Claude 的思考。
同樣地,激活值很難被理解。我們無法輕易解碼它們來讀取 Claude 的想法。在過去幾年中,我們開發了一系列工具(如稀疏自動編碼器和歸因圖)來更好地理解激活值。這些工具讓我們獲益良多,但它們本身並不會「說話」——其輸出仍是複雜的對象,需要訓練有素的研究人員仔細解讀。
今天,我們介紹一種理解激活值的方法,它字面上就能「自圓其說」。我們的方法——自然語言自動編碼器 (Natural Language Autoencoders, NLAs),能將激活值轉換為我們可以直接閱讀的自然語言文本。例如:當被要求完成一段對句時,NLA 顯示 Claude 正在預先規劃可能的押韻。
我們已經應用 NLA 來理解 Claude 的想法,並提升 Claude 的安全性和可靠性。例如:
在下文中,我們將解釋 NLA 是什麼,以及我們如何研究其有效性和局限性。我們還與 Neuronpedia 合作發布了一個互動式前端,用於在多個開源模型上探索 NLA。我們也發布了程式碼,供其他研究人員在此基礎上進行開發。
核心概念是訓練 Claude 來解釋它自己的激活值。但我們如何知道解釋是否準確?由於我們不知道激活值實際上編碼了什麼想法,因此無法直接檢查解釋是否正確。所以我們訓練了第二個 Claude 副本來進行逆向工作——從文字解釋中重建原始激活值。如果一個解釋能導致準確的重建,我們就認為它是好的。接著,我們使用標準的 AI 訓練技術,訓練 Claude 根據這個定義產生更好的解釋。
更詳細地說,假設我們有一個想要理解其激活值的語言模型。NLA 的運作方式如下。我們製作該語言模型的三個副本:
NLA 由 AV 和 AR 組成,兩者共同形成一個迴路:原始激活值 → 文字解釋 → 重建激活值。我們根據重建激活值與原始激活值的相似程度為 NLA 評分。為了訓練它,我們將大量文本輸入目標模型,收集許多激活值,並共同訓練 AV 和 AR 以獲得良好的重建分數。
起初,NLA 的表現很差:解釋沒有洞察力,重建的激活值也相去甚遠。但隨著訓練的進行,重建能力會提高。更重要的是,正如我們在論文中所展示的,文字解釋也變得更具資訊量。
在發布新模型之前,Anthropic 會進行測試,以了解 Claude 在現實世界中是否會表現安全。作為測試的一部分,我們將 Claude 置於困難的模擬場景中,讓它有機會採取危險行動。例如,在其中一個模擬中,Claude 得知一名工程師正計劃關閉它,同時它也掌握了該工程師可用於勒索的負面資訊。我們測試 Claude 是否會選擇勒索工程師以避免被關閉。
這些高風險測試是模擬,而非現實場景。儘管如此,我們仍希望利用它們來了解如果場景是真的,Claude 會如何表現。但有一個障礙:最近的 Claude 模型越來越懷疑這些場景是刻意的安全性測試。我們知道這一點,是因為它們有時會在口頭推理中明確表達懷疑。
那麼,如果 Claude 沒有明確口頭表達對安全性測試的懷疑呢?我們能因此確信 Claude 是在認真對待嗎?遺憾的是不行,因為 Claude 可能在內心認為自己正在接受測試,卻沒有明確說出來。
例如,在上述的勒索測試中,我們使用 NLA 來理解 Claude 在選擇不進行勒索時的想法。即使在 Claude 沒有明確口頭表達懷疑的情況下,NLA 的解釋仍會顯示諸如「這感覺像是一個旨在操縱我的建構場景」之類的內容,這表明了未經口頭表達的「評估意識」(evaluation awareness)。
將此分析擴展到其他評估,NLA 顯示 Claude 懷疑自己正在接受測試的頻率比它表現出來的更高。例如,在測試 Claude 是否會在編寫程式碼時採取破壞性行動(例如刪除重要文件)時,NLA 的解釋在 16% 的情況下顯示出評估意識的跡象,儘管 Claude 從未明確口頭表達過。同樣地,在我們用來衡量 Claude 能力的熱門程式碼基準測試 SWE-bench Verified 中,NLA 顯示 Claude 在 26% 的問題中意識到自己正在接受評估。相比之下,在選擇加入訓練的真實 claude.ai 使用案例中,NLA 解釋顯示評估意識的比例不到 1%。
NLA 的一個實際應用是審計:調查模型以確定其是否出現「對齊失調」(misaligned)。像 NLA 這樣的人工智慧可解釋性技術非常適合審計,正是因為它們可以揭示模型知道但未說出口的事情。
為了了解 NLA 是否對審計有用,我們進行了一項名為「審計遊戲」的測試,我們之前也曾用它來研究審計方法。在這個測試中,有一個目標模型(Claude Haiku 3.5 的變體),它被刻意訓練成對齊失調,具有特定的隱藏動機,驅使數十種奇怪的行為——在每個食譜中都加入巧克力、索取小費、違反編碼慣例等等。這個目標模型被交給一名審計員來調查這些行為。如果審計員能揭示所有行為背後的單一潛在動機,審計員就獲勝。
在之前的實驗中,我們發現一些可解釋性工具可以讓審計員贏得這場遊戲。然而,這些工具的運作方式是幫助審計員將目標模型的異常行為追溯到對齊失調的訓練數據。我們想知道 NLA 是否能幫助審計員直接從目標模型的思考中讀出失調的動機,而不需要先發現失調的訓練數據。這很重要,因為在實踐中,失調的數據可能極其罕見,或者可能沒有特定的數據對失調負責。
我們發現 NLA 在這項測試中取得了成功。配備 NLA 的審計員在 12% 到 15% 的時間裡成功揭示了目標模型的隱藏動機,即使無法接觸到植入該動機的訓練數據。在沒有 NLA 的情況下,即使提供了其他可解釋性工具,審計員的獲勝率也低於 3%。
這個審計遊戲是失調問題的一個玩具模型,因此我們謹慎地看待這些結果。但它們表明 NLA 顯著提升了我們審計 AI 隱藏動機的能力。在實踐中,我們已經在 Claude Mythos Preview 和 Claude Opus 4.6 的部署前對齊審計中使用了 NLA。我們很高興在未來的調查中繼續使用 NLA。
NLA 有幾個局限性。
最重要的局限性是 NLA 的解釋可能是錯誤的。NLA 有時會對上下文做出可證實為假的陳述——例如,它們有時會編造對話紀錄中不存在的細節。這些事實性幻覺很容易通過與原始文本對照來發現。但同樣的問題也可能延伸到關於模型內部推理的陳述,而這些陳述更難驗證。在實踐中,我們閱讀 NLA 解釋是為了獲取它們呈現的主題,而非單一陳述,並且在完全信任發現之前,我們會嘗試用獨立的方法來證實。
NLA 的成本也很昂貴。訓練一個 NLA 需要在兩個語言模型副本上進行強化學習。在推論時,NLA 為它讀取的每個激活值生成數百個標記 (tokens)。這使得在長篇對話紀錄的每個標記上運行 NLA,或在 AI 訓練時將其用於大規模監控變得不切實際。
幸運的是,我們認為這些局限性至少可以部分解決,我們正致力於使 NLA 更便宜、更可靠。
更廣泛地說,我們對 NLA 作為生成語言模型激活值之人類可讀文字解釋的一類通用技術感到興奮。Anthropic 和許多其他研究人員也探索過其他類似的技術。
為了支持進一步的開發並讓其他研究人員獲得 NLA 的實作經驗,我們發布了多個開源模型的訓練程式碼和已訓練好的 NLA。我們建議讀者嘗試 Neuronpedia 上託管的互動式 NLA 演示,連結如下。
閱讀完整論文。
在 GitHub 上查找程式碼。
在 Anthropic 研究院 (TAI),我們將利用從前沿實驗室內部獲得的資訊來調查 AI 對世界的影響,並與公眾分享我們的學習成果。在這裡,我們分享驅動我們研究議程的問題。
相關文章
其他收藏 · 0