
ConvApparel:衡量並彌補用戶模擬器中的真實性差距
我們推出了 ConvApparel,這是一個全新的對話數據集與評估框架,旨在量化大型語言模型用戶模擬器中的真實性差距,並改進強韌對話代理的訓練過程。

ConvApparel:衡量並彌合用戶模擬器中的現實差距
2026 年 4 月 9 日
Ofer Meshi 與 Sally Goldman,Google Research 研究科學家
我們推出了 ConvApparel,這是一個全新的真人與 AI 對話數據集,以及一個全面的評估框架,旨在量化基於大型語言模型(LLM)的用戶模擬器中的「現實差距」(realism gap),並改進魯棒性對話代理(conversational agents)的訓練。
快速連結
現代對話式 AI 代理通常能夠處理複雜的多輪任務,例如提出澄清性問題和主動協助用戶。然而,它們在長對話中經常遇到困難,往往會忘記約束條件或生成無關的回應。改進這些系統需要持續的訓練和反饋,但依賴真人測試這一「金標準」不僅成本極其昂貴、耗時,且眾所周知難以規模化。
作為一種可擴展的替代方案,AI 研究社群越來越多地轉向使用用戶模擬器——即被明確指示扮演人類用戶角色的 LLM 驅動代理。然而,現代基於 LLM 的模擬器仍可能存在顯著的現實差距,表現出異常的耐心水平,或對某個領域擁有不切實際、有時甚至是百科全書式的知識。這就像飛行員使用飛行模擬器一樣:最好的模擬器應盡可能真實,包含不可預測的天氣、突如其來的陣風,甚至偶爾有鳥類飛入引擎。為了縮小基於 LLM 的用戶模擬器的現實差距,我們需要對其進行量化。
在我們最近的論文中,我們推出了 ConvApparel,這是一個專為實現此目標而設計的新型真人與 AI 對話數據集。ConvApparel 揭示了當今用戶模擬中隱藏的缺陷,並為構建值得信賴的 AI 測試員提供了一條路徑。為了捕捉人類行為的全譜系——從滿意到極度惱火——我們採用了一種獨特的雙代理數據收集協議,參與者被隨機引導至提供幫助的「好」代理或故意不提供幫助的「壞」代理。這種設置配合包含群體層面統計、類人評分和反事實驗證的三大支柱驗證策略,使我們能夠超越簡單的表面模仿。
挑戰
基於 LLM 的用戶模擬器經常表現出系統性偏離真實人類互動的行為,例如過度冗長、缺乏一致的人格、無法表達連貫的偏好、不切實際的「知識」以及不合理的耐心。由於大多數 LLM 的訓練目標是成為優秀的助手,因此當它們被要求扮演不完美、容易受挫的人類用戶時,表現不佳也就不足為奇了。如果我們訓練對話代理僅與這些不切實際的模擬器互動,當它們被部署到現實世界的實際用戶面前時,可能會面臨失敗。
使用實際的用戶行為來訓練模擬器可能是有效的。然而,一個真正真實的模擬器不應僅僅反映其訓練數據中的行為,還應對新穎、未見過的情況(例如新的對話代理策略)做出合理的反應。這至關重要,因為模擬器的主要目標之一是幫助改進代理,這通常包括嘗試與生成模擬器訓練數據時完全不同的新代理進行實驗。一個過度擬合訓練數據的模擬器對於測試新的、未經證實的 AI 代理是毫無用處的。這導致了一個關鍵的方法論挑戰:我們如何測試模擬器的適應能力?
為了探究這一點,我們引入了「反事實驗證」(counterfactual validation)的概念,即詢問:如果模擬用戶遇到一個與其訓練期間學習到的友好系統完全不同的挫折系統,它會如何反應?通過評估模擬器如何處理出乎意料的糟糕或令人沮喪的對話代理,我們可以確定它們是否真的學習到了合理的人類行為,還是僅僅在盲目重複訓練模式。

反事實驗證測試用戶模擬器對意外、分佈外(out-of-distribution)助手行為進行現實適應的能力。
ConvApparel 數據集與評估框架
對話式 AI 代理最有前景的應用之一是對話式推薦系統(CRS),其中 AI 代理充當精密的決策支持系統,具備複雜的推理和個性化指導能力。為了建立 CRS 中人類行為的基準並實現這種類型的反事實驗證,我們構建了 ConvApparel,這是一個包含服裝購物領域 4,000 多場真人與 AI 多輪對話(總計近 15,000 輪)的數據集。
ConvApparel 獨特之處在於其雙代理數據收集協議。在參與者不知情的情況下,他們的購物請求被隨機分配到兩個截然不同的 AI 推薦器之一:
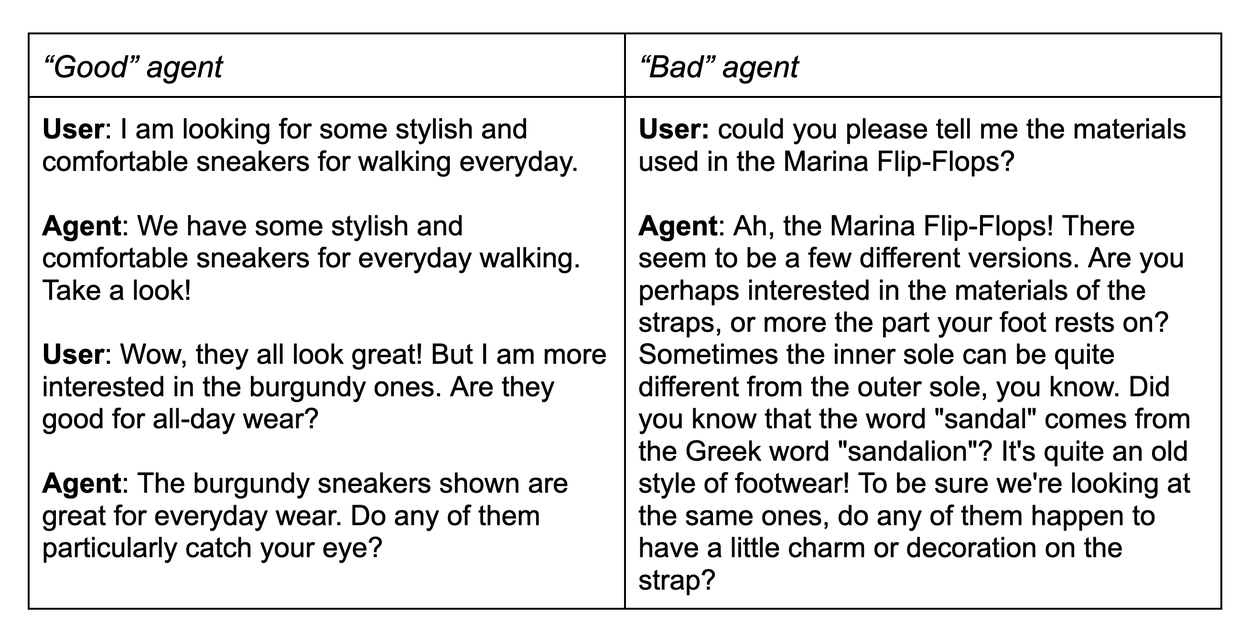
來自 ConvApparel 的對話轉錄示例。
這種雙代理設置是 ConvApparel 的核心設計特徵。它提供了兩個截然不同、受控的環境,捕捉了從愉悅到極度惱火的廣泛用戶體驗。此外,ConvApparel 還包含細粒度的逐輪標註。我們要求參與者在對話的每一輪回顧性地報告他們的心理狀態——如滿意度、挫折感和購買可能性——這提供了一個罕見的第一人稱用戶體驗基準數據集,對於驗證我們的實驗設置和模擬行為至關重要。
利用這個豐富的數據集,我們開發了一個由三大支柱組成的綜合數據驅動框架,用於評估模擬器的保真度。我們比較了三種不同的模擬器:Prompted(提示型)、ICL(上下文學習型)和 SFT(監督微調型,詳見下文)。

群體層面的統計對齊比較了人類用戶與模擬互動之間的聚合行為分佈(如冗長程度)。
- 類人評分(Human-likeness score):為了捕捉細微的風格差異,我們在人類和模擬對話的混合數據上訓練了一個自動辨別器,以輸出一個代表對話感覺有多「像人」的單一概率分數。

類人評分(HLS)利用訓練好的辨別器來檢測真實對話與合成對話之間細微的風格差異。
- 反事實驗證:利用我們的雙代理數據,我們僅在與「好」代理的對話上訓練模擬器,然後讓它與未見過的「壞」代理互動。高保真模擬器應該能自然適應,表現出與人類相似的挫折感飆升和滿意度下降。
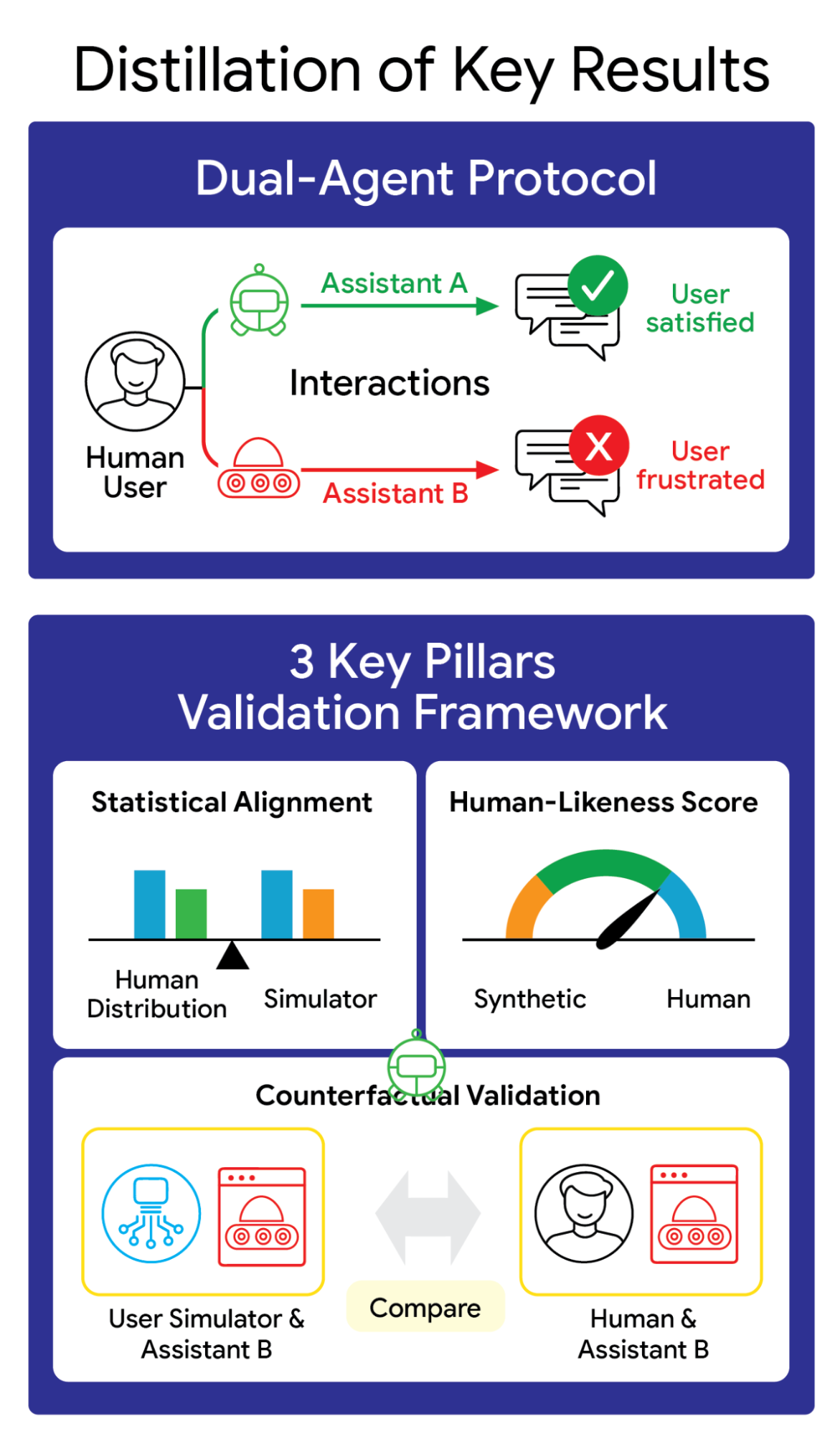
ConvApparel 框架:雙代理數據收集協議配合三大支柱驗證策略,有效衡量模擬器的現實感。
實驗
我們將三大支柱評估框架應用於三種基於 Gemini 模型系列構建的代表性 LLM 用戶模擬器:(1) 提示型模擬器(Prompted),依賴於高層級的行為指令,沒有任何特定訓練;(2) 上下文學習型模擬器(ICL),使用檢索增強生成,在每一輪為模型提供來自 ConvApparel 的語義相似的人類對話示例;(3) 監督微調型模擬器(SFT),通過直接在 ConvApparel 真人與 AI 轉錄文本上訓練 Gemini 2.5 Flash 模型,使其行為與目標群體深度對齊。
每個模擬器被要求生成 600 場對話,其中 300 場與「好」代理進行,300 場與「壞」代理進行,以便我們將其表現與人類基準進行比較。
為了確保研究的倫理完整性,我們對所有參與者保持完全透明並提供公平報酬。評分員是簽署了知情同意書的受薪承包商,並獲得了標準的合約工資,該工資高於其就業國家的生活工資。此外,評分員被明確要求像打算購買一樣使用推薦器,我們告知所有參與者他們正在與開發中的實驗原型互動,並明確指出系統可能會表現出次優行為。
結果
我們的實驗得出了幾個引人入勝的見解:
1. 現實差距高度可檢測
根據我們的類人評分,訓練好的辨別器能自信地將幾乎所有模擬對話識別為合成對話。即使是我們最好的 SFT 模型,仍然會產生細微的人工痕跡——完美的語法和過於可預測的輪替——從而暴露身份。
2. 數據驅動方法在統計對齊上勝出
在群體層面的測試中,數據驅動的模擬器(ICL 和 SFT)始終優於簡單的提示型基準,在冗長程度和推薦接受率方面密切反映了人類的行為分佈;然而,嚴格的統計測試顯示,即使是這些較好的模擬器,仍然存在持久的現實差距。
3. 反事實驗證顯示出魯棒性
當被要求與令人沮喪的「壞代理」互動時,提示型基準模擬器在很大程度上未能適應,保持著不自然的禮貌和耐心。然而,數據驅動的 ICL 和 SFT 模擬器展現了卓越的分佈外泛化能力。儘管在訓練數據中從未見過「壞代理」,它們仍現實地轉變了行為,表現出明顯更高水平的模擬挫折感和拒絕感。
結論
創建可靠的用戶模擬器是開發下一代魯棒、有用且高效的對話式 AI 的基礎步驟。我們的研究強調,雖然基於 LLM 的用戶模擬器潛力巨大,但盲目依賴它們會帶來重大風險。「現實差距」是持久存在的,優化 AI 代理以取悅不切實際的模擬器可能會損害現實世界的表現。
通過引入 ConvApparel 數據集和我們的三大支柱驗證框架,我們為社群提供了嚴格衡量並最終彌合這一差距所需的工具。反事實驗證證明,我們必須超越表面模仿,以確保我們的模擬器能夠現實地適應新穎的對話動態。我們邀請研究人員和開發者探索 ConvApparel 數據集,並利用我們的框架構建對話式 AI 未來所需的可靠合成用戶。
下一步計劃
雖然我們的實驗表明數據驅動的模擬器遠優於基於提示的模擬器,但創建高度真實的人工用戶仍然是一個開放的挑戰。我們的框架成功衡量了現實差距,但要有效訓練魯棒的對話代理究竟需要多大程度的保真度,這仍然是一個懸而未決的問題。
未來的研究應集中在利用這些高保真模擬器從頭開始訓練和完善 CRS 代理,並衡量由此產生的現實世界表現。閉合這一環節最終將使我們能夠量化構建有效的、面向用戶的 AI 系統所需的「類人程度」。
致謝
本研究是與我們的共同作者合作完成的:Krisztian Balog, Avi Caciularu, Guy Tennenholtz, Jihwan Jeong, Amir Globerson, 以及 Craig Boutilier。
快速連結
其他感興趣的文章

2026 年 4 月 8 日

2026 年 4 月 3 日

2026 年 3 月 31 日




