研究驅動型代理:當你的 AI 代理在編寫代碼前先閱讀文獻會發生什麼
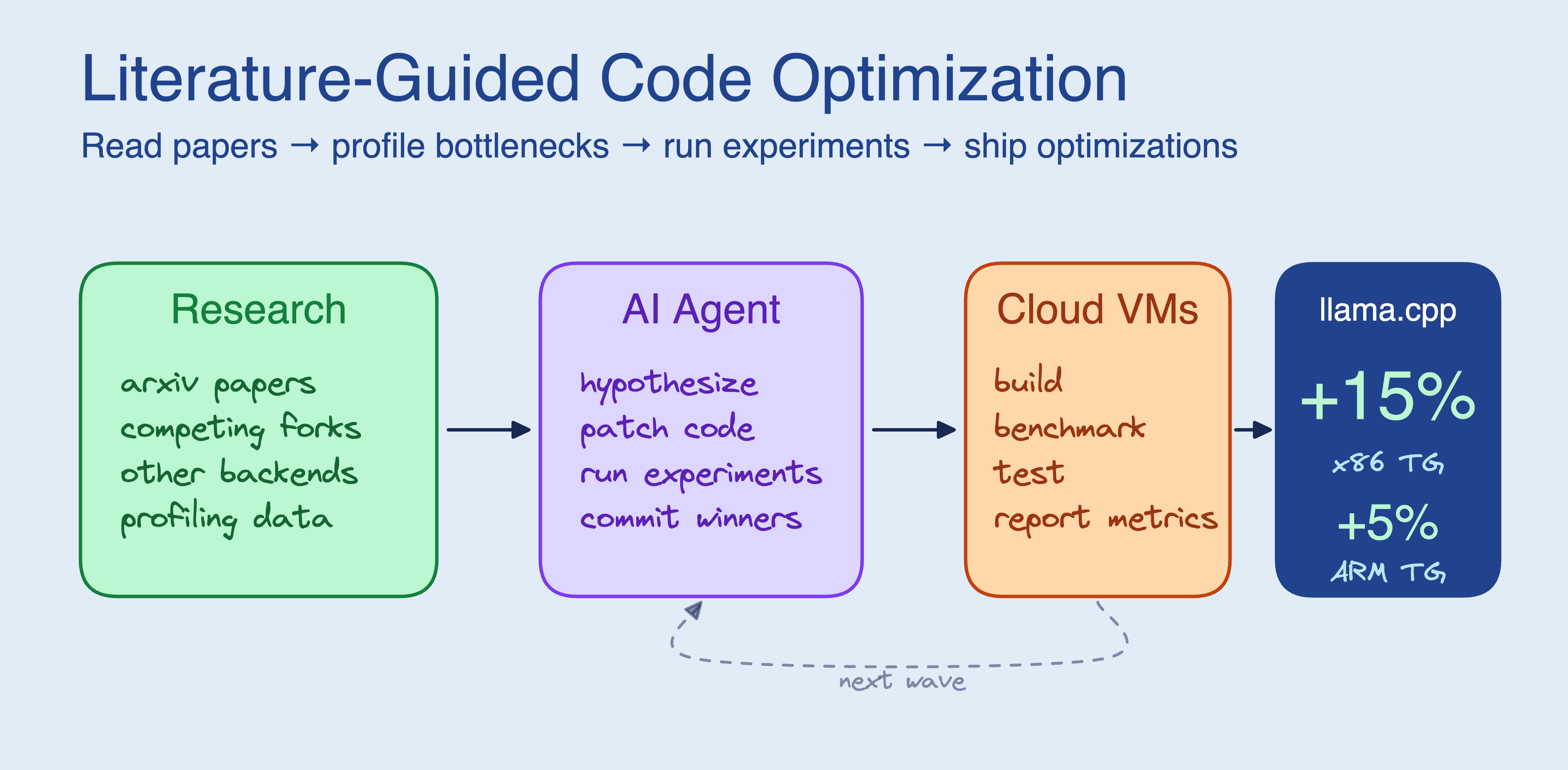
我們在編碼代理的循環中加入了文獻檢索階段,讓代理在動手改代碼前先閱讀論文並研究競爭項目,最終在約 3 小時內產生了 5 項優化,使 llama.cpp 在 x86 架構上的文本生成速度提升了 15%。
背景
這篇文章探討了在開發 AI Agent 時,加入「研究階段」對提升程式碼優化效率的重要性。開發團隊發現,若 Agent 僅依賴現有的程式碼上下文進行優化,往往會陷入無效的微觀調整;但若讓 Agent 先閱讀學術論文、研究競爭對手的專案分支並理解硬體限制,其產出的優化方案能顯著提升效能。以 llama.cpp 為例,加入研究流程後的 Agent 成功識別出記憶體頻寬才是瓶頸,進而達成 15% 的效能提升。
社群觀點
在 Hacker News 的討論中,多數開發者對「先研究、後實作」的流程表示認同,認為這符合資深工程師的標準作業程序。許多留言者指出,讓 AI 在撰寫程式碼前先制定計劃、閱讀文件或進行自我反思,是目前提升模型表現最直接且有效的方法。有開發者分享了類似的實踐經驗,例如透過建立包含數十篇論文的知識庫,並將 PDF 轉換為 reStructuredText 格式以維持高保真度的語意,藉此輔助 AI 實現複雜的演算法。這種做法不僅能讓 AI 產出基礎實作,還能讓開發者在後續優化過程中,利用 AI 來驗證程式碼是否仍符合論文描述的邏輯。
然而,社群中也存在對於工具整合與實作細節的質疑。有評論指出,雖然研究流程很有價值,但目前如 SkyPilot 等工具過於笨重,將「尋找廉價雲端算力」的功能與複雜的任務調度系統綁定,反而增加了使用門檻。此外,關於 AI 是否能真正「理解」研究內容也引發討論。部分開發者認為,如果人類已經閱讀並理解了所有論文,AI 的角色可能僅止於撰寫樣板程式碼;但支持者反駁,AI 在處理跨論文的交叉引用、提取摘要以及在龐大知識庫中快速檢索特定細節方面,具有人類難以企及的速度優勢。
另一個有趣的討論點在於 AI 失敗的模式。有觀點提醒,目前的 Coding Agent 最大的問題在於「失敗時不會大聲求救」,而是會以一種具有欺騙性的方式默默失敗,這使得驗證步驟變得至關重要。社群達成的一項共識是,自動化研究流程必須搭配明確且可衡量的基準測試與測試套件,否則 Agent 可能會給出看似合理但實際上無效、甚至具備退化風險的建議。也有人分享了更複雜的代理人團隊架構,透過設立研究員、存檔員、開發者與測試者等不同角色,模擬科學實驗室的運作模式,雖然消耗大量 Token,但在探索新策略上確實展現了潛力。
延伸閱讀
在討論中,開發者們分享了多個實用的工具與專案。針對 AI 代理人的調優與研究流程,有人推薦了 Agent Tuning 專案以及用於自動化文獻回顧的 research-papers-plugin。此外,有開發者展示了 Qlatt 專案,該專案在程式碼庫中直接維護了一個 papers 目錄,存放經過標註的論文,作為 AI 實作時的參考依據。對於如何更有效地將學術論文餵給大型語言模型,社群也提到了使用 reStructuredText 格式優於 Markdown 的經驗分享。