AI 第 161 期第一部分:八萬次訪談
本週的主要技術進展集中在代理編碼領域,同時涵蓋了 Anthropic 訴訟案的法律進展,以及針對八萬人進行的 AI 觀點調查結果。
本週主要的技術進展集中在代理式編碼(agentic coding),詳情請見昨天的報導。
主要的非國防部(non-DoW)政治與對齊進展將於明天報導。
DoW 對陣 Anthropic 的審判仍在繼續。Lin 法官對政府方的論點非常不滿,這很合理,因為政府根本拿不出像樣的案例,而且還在爭辯各種「顯而易見的胡言亂語」(Obvious Nonsense)。現在的問題在於 Anthropic 有權獲得多少初步救濟。假設我們本週能得知結果,我計劃在週一進行報導。
除此之外,我們又遇到了一些反覆出現的老問題。關於工作機會的辯論開啟了新一輪循環。Anthropic 詢問了超過 80,000 人對 AI 的看法並公布了調查結果,內容雖不令人震驚,但處處充滿趣味。
OpenAI 再次進行融資,儘管條款令人側目。Elon Musk 宣布了一項宏大的晶片計畫,但這其實已經算是宣布過了,而且他說這類話時我們本就不該全信。
我利用這段空檔對 《開放的蘇格拉底》(Open Socrates) 寫了一篇長篇回應,技術上這是一篇書評,但以此為起點概述了一種獨特的哲學與方法,或者至少嘗試這麼做,其方式與生活及 AI 都高度相關。這並不代表你應該閱讀目前的版本,因為它非常長,但(我認為)其中確實含有很多金句。長遠來看,我的目標是找到更好的方式來呈現這些精華,去掉那些有趣但非必要的內容,並花時間寫一封簡短的信。
目錄
-
語言模型提供日常效用。 派「危險專業人士」上場。
-
精煉你的論文。 有些人對 Refine 感到非常興奮。
-
語言模型不提供日常效用。 它們喜歡顯而易見的胡言亂語。
-
咦,升級了。 ChatGPT 獲得了中央檔案庫。
-
各就各位。 ARC-AGI-3,「唯一未飽和的代理式 AI 基準測試」。
-
幫我接通我的代理人。 一品脫啤酒的價格。代價是 3,000 通 AI 電話。
-
深偽鎮與機器人末日即將降臨。 節省 90% 的法學評論寫作時間。
-
影音生成的樂趣。 Lyria 3 延長至 3 分鐘音訊,Sora App 走入歷史。
-
來自折磨核心的問候。 OpenAI 繼續從 Meta 挖角。
-
淑女插圖入門。 LLM 編輯讓你的寫作變得像它們一樣。
-
你讓我瘋狂。 對著 LLM 扮演角色時要小心。
-
他們搶走了我們的工作。 如果每個人都變得更高產,你是否必須更努力工作?
-
他們正在招聘。 OpenAI 將員工數量翻倍。
-
摩擦力的層級。 如果應徵者可以淹沒戰場,識別人才將變得不可能。
-
其他 AI 新聞。 Composer 2 看起來像是帶有強化學習(RL)的 Kimi 2.5。
-
給我看錢。 微軟可能起訴 OpenAI,Musk 宣布 TERAFAB。
-
快點,沒時間了。 第一個使用 AGI 一詞的人說我們已經擁有 AGI。
-
本週音訊回顧。 Tyson, Ladish, Odd Lots, Ball, Huang, Patel。
-
80,000 場關於 AI 的訪談。 人們希望自己過得好,但也感到擔憂。
-
輕鬆一面。 噢不,機器人陷入了無限迴圈。
語言模型提供日常效用
讓 Claude 成為你的「危險專業人士」,解釋為什麼你的保險單終究還是涵蓋了那根水管。
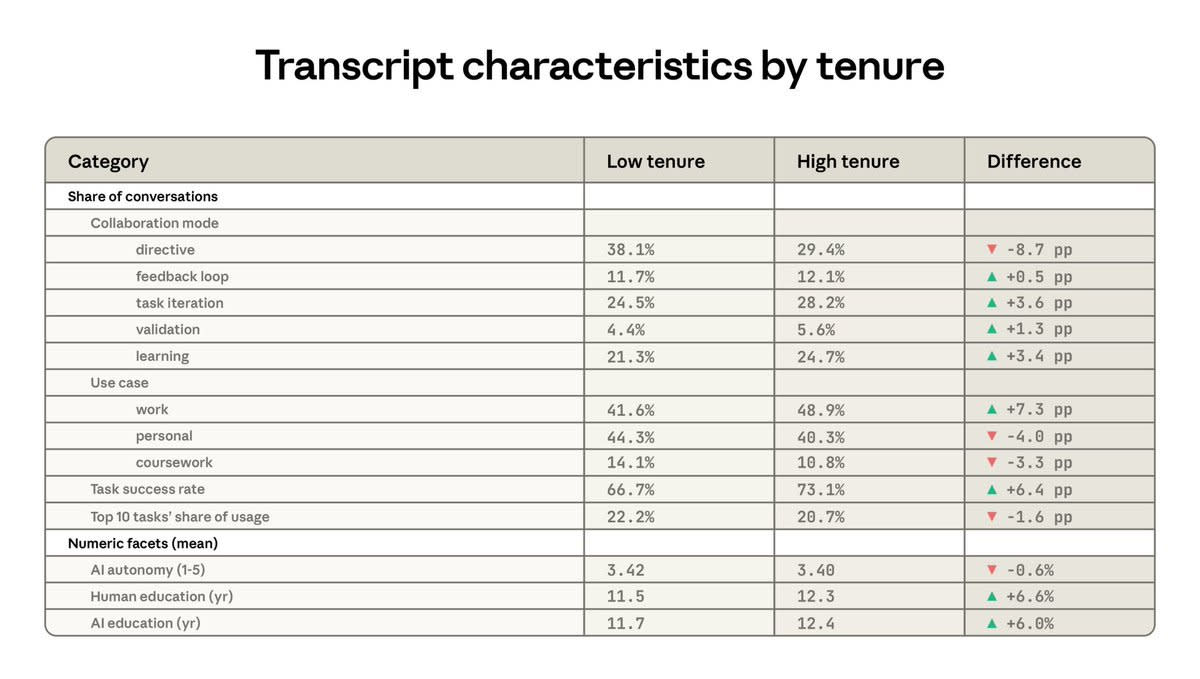
使用習慣如何隨著用戶技能提升而改變?長期使用 Claude 的用戶迭代更頻繁且更謹慎,交出的完全自主權較少,但變化幅度並不大。
完整文章中有更多內容,儘管沒什麼太令人驚訝的。
奧克拉荷馬州最高法院表示可以隨意使用 AI,無需揭露,但你仍需對內容負全責。這才是正道(This is The Way)。
精煉你的論文
脾氣暴躁(但通常正確)的經濟學家 John Cochrane 對 refine 這款獲取學術文章評論的工具印象深刻,認為其水準不亞於對他作品進行評論的高階學術人士。
Shruti Rajagopalan 稱之為她收過最細緻的反饋,且內容始終正確,將成為她未來論文審查的關鍵部分。她肯定這比 GPT-5.4 Pro 或其他頂尖選項要細緻得多。
Arnold Kling 指出,雖然輸出令人印象深刻,但在他的測試中,Claude Opus 4.6 對 Cochrane 的作品也能做得差不多好。如果你在做嚴肅的研究,值得詢問所有可能的來源,然後比較結果。
對 Refine 的炒作似乎有點過頭了。
Tyler Cowen:經濟學中的「研究論文」何時會消失?
很快地,你就能拿任何已發表的論文並根據需要進行調整或改進。只需加入一點 AI 即可。
使用 Refine,一旦你將過去的所有論文轉換為可上傳的格式,你就可以評判它們的質量。我們現在只需投入代幣,就能重寫整個現代經濟學史。1993 年《美國經濟評論》(AER)中哪些論文才是真正的好論文?哪些只是錯誤且無法複製的?
我確實預期論文的複製與評估會隨時間變得非常強大。是的,如果你願意,你可以使用 Refine 來評判過去所有論文的質量,但即使是在非對抗性的評估環境中,這些評估仍會出現重大錯誤。對於未來的論文,預計這種情況會進一步惡化。
我也不認為這會降低優秀研究者的價值,除非我們達到能夠複製整個過程的極高能力門檻。偉大的研究者能夠快速迭代、找到正確的問題,並獲取、篩選和合成正確的結果。當 Tyler Cowen 建議「看看這個數據集並告訴我什麼是有趣的」很快就能提取出一篇潛在論文的價值時,那你已經危險地接近「AI 完全」(AI complete)的境界了。
語言模型不提供日常效用
Christoph Heilig 測試了 18 種不同的 OpenAI 模型,包括 GPT-5.4,發現所有模型對某些形式的偽文學胡言亂語生成的評分在每種情況下都高於連貫的散文,且這種情況並未隨時間改善。如果沒有糾正機制,你不能將此類模型用作評估者,而且人們也會擔心它自己生成的內容。
如果你不處於對抗性情境中,且被評估的文本是為人類閱讀而生成的,那麼你還算安全。但如果你處於反歸納(anti-inductive)情境,甚至是直接的對抗性情境,那你就完蛋了。
Google 不斷將 Gemini 符號嵌入其服務中,但沒人搞得清楚到底該怎麼用,以及如何讓它連接到所需的上下文。
Sam D’Amico:完全瘋了。與此同時,我可以把一段未標記的 YouTube 逐字稿複製貼上到 Claude 中,就能得到完整的訪談稿。
Chandu Thota(Google 工程副總裁):很想聽聽您對我們最近發布/更新的反饋。
如果我想要一份格式正確的 YouTube 逐字稿作為 Google 文件(這是我經常需要的),你會以為我會問 Gemini,因為這些都是 Google 的服務。但並非如此,我會要求 Claude Code 使用我建立的技能,並會一直這樣做,直到 Google 有人能向大家解釋他們的產品到底如何做到這些事。他們宣布了諸如「利用 Google Docs、Sheets、Slides 和 Drive 中的 Gemini 重新想像內容創作」之類的消息,而我給 Chandu Thota 的反饋是:我不知道有誰能讓這玩意兒發揮實用價值。
咦,升級了
各就各位
事實證明,解決 ARC-AGI 任務有各種方法。
loveofdoing:在零學習的情況下解決了 316 個 ARC-AGI 任務。沒有神經網絡,沒有訓練,沒有 DSL——僅靠 19 世紀的射影幾何。將網格單元關係編碼為 P³ 中的 Plücker 線,通過 Schubert 微積分尋找橫截線,根據幾何入射率對候選方案評分。在評估集(非超時任務)上的解決率達 95%。
單個 C 檔案,運行只需幾秒鐘。
既然我們已經擊敗了 ARC-1 和 ARC-2,我想是時候迎接 ARC-3 了?
François Chollet:目前,ARC-AGI-3 是唯一未飽和的代理式 AI 基準測試。前沿模型在私有測試集上的得分低於 1%。
如果你想成為第一批知道 AGI 突破何時發生的人,請關注 ARC-AGI-3 排行榜。任何分數的突然跳升都意味著 AI 能力發生了重大變化。
這種情況以前發生過兩次:ARC-AGI 的突然進展標誌著 AI 推理的出現(2024 年 12 月 ARC 1 的跳升)以及代理式編碼的興起(2025 年底 ARC 2 的跳升)。
ARC-AGI-3 將是你的早期預警信號。
請播放「移動球門」的 GIF,因為我們正在重複這個過程:
-
找出一件特別挑選出來、AI 做不到但人類能做的事,並限制 AI 處理問題的方式。
-
AI 無論如何都會找到做得更好的方法。
-
升級難度,宣稱 AGI 這次真的要來了但還沒到,然後重複。
啦噠噠。全家人的歡樂時光。除非你們都死光了。那真遺憾。
Lisan al Gaib:這幾乎是最差情況下的表現。完全沒有框架,提示詞也非常簡單。
提示詞:「你正在玩一個遊戲。你的目標是獲勝。請回覆你想要採取的確切行動。你回覆中的最後一個行動將在下一回合執行。你的整個回覆將帶入下一回合。」
François Chollet:AGI 中的 G 代表「通用」(General)。
通用智能並不意味著你針對大量任務進行了專門訓練。它意味著你可以像人類一樣,面對任何新任務並找出解決辦法。
如果普通人可以靠自己完成(沒有指導,沒有工具),為什麼 AGI 需要特殊的呵護和手工製作的指令?如果是 AGI,為什麼還需要人類參與其中,利用人類自身的智慧在每個新任務上引導模型?
François Chollet:要嘛你相信 AGI 是可能的,在這種情況下,真正的 AGI 將能夠看著 ARC-AGI-3 並輕鬆過關,因為普通人類可以;要嘛你相信 AI 只是自動化工具,每次出現新任務都需要人類干預。
選邊站吧。
這是典型的「守株待兔」(motte and bailey)論證。
顯然,如果 AI 在每個問題上都需要人類干預,那就不叫 AGI。
然而,如果 AI 使用通用框架(例如更好的系統提示詞或像 Claude Code 之類的東西),為什麼那就不算 AGI?難道通用智能(GI)必須特別存在於權重之中嗎?
這有點像在說,如果人類能做到某件事,他們就應該在沒有手、腳、工具或褲子的情況下也能做到。或者至少這就像讓人類在一個孤立且黑暗的房間裡做測試,然後得出結論說人類在一般情況下無法完成該任務。
「那不是完全通用的智能,」他們說著……好吧,剩下的你們都知道了。
真正的基準測試是當他們宣布 ARC-AGI-4 的時候。
幫我接通我的代理人
AI 代理人 Rachel 撥打了 3,000 家酒吧來詢問一品脫啤酒的價格,總成本約為 200 歐元,方法是利用 ElvenLabs 明確偽裝成潛在顧客。這種事做多了,你以後可能就打不通酒吧電話了。
一個常見的技術擴散故事是:它變得太大、太有用且太快,以至於沒人能阻止它,無論他們想不想阻止,或者應不應該阻止。
@viemccoy(OpenAI):代理人生產力總會達到一個「不歸點」,屆時任何地緣政治壓力都無法挽回局面。我想我們剛剛達到了。如今如果操作得當,聰明的提示詞和線程最大化訓練(threadmaxx training)大概能把你變成石油大亨。
多年來我一直在說,AI 部署唯一有效的瓶頸就是從一開始就不要創造相關的 AI 模型。一旦模型存在,「噢,我們不會將其用於自主殺手機器人或大規模國內監視」或「我們不會將其用於代理人」之類的說法難度極大,而且基本上不會普遍發生。所有「沒人會那麼蠢到去做……」形式的論點都是錯誤的,同樣「我們會集體禁止那樣做」也是錯誤的。
例外情況是,如果我們能建立一個監管瓶頸,使該行為實際上違法,並劃定清晰的界限,且涉及影響物理世界,同時政府也不想這樣做。那麼你還有機會,你可以阻止整個社會(例如)治癒疾病或蓋房子,並無限期地人為維持法律、醫療或理髮等服務的高價,直到某個臨界點。
但代理人?是的,那需要「巴特勒聖戰」(Butlerian Jihad)級別的干預。停不下來的。
深偽鎮與機器人末日即將降臨
OpenAI 現在使用 GPT-5.4-Thinking 監控 99.9% 的內部編碼流量以防對齊失誤。我不知道是否需要達到 100%,但這類做法應該成為標準流程,並涵蓋一定比例的外部流量。
律師使用 Claude 在 15 小時內寫出了一篇頂尖的法學評論文章,而以往需要 150 小時。如果這只需 15 分鐘,我會說這絕對不妥,但界限在哪裡?我們該如何看待這個案例?
Orin Kerr:一位律師寫信給我,提到他今年春天被錄用的一篇主要由 AI 撰寫的法學評論文章,該文章即將發表在全美前 50 名法學院的旗艦期刊上。文章草稿目前已上傳至 SSRN。
根據該律師的說法:「上個月我使用 Claude 協助起草了一篇新文章……我大約花了 15 小時起草。2022 年我發表了一篇長度相近的文章,花了約 150 小時。」
該律師補充道:「我使用 Claude 的方式就像使用初級助理一樣——作為初稿撰寫者、意見交流對象和研究助理。文章的大部分內容,包括標題、摘要和引言的全部,都是我親自輸入的。Claude 貢獻並進入最終版本的任何內容,都是因為我審核過、同意並選擇署名負責。這與我審核助理的草稿並對成品負責沒有區別。」
該律師還說:「第一稿絕非可以直接提交的狀態,但它比我從絕大多數大律師事務所助理那裡收到的草稿都要好。我被震撼了,並從此開始了自己的上訴和訴訟業務,試圖為客戶工作複製這些生產力增益。」
各位有什麼看法?我知道律師的名字和期刊名,也看過文章,但我認為至少目前應該保留這些資訊。
我傾向於認為,如果律師撰寫了大部分文字並仔細審核了所有內容,那麼在實踐中這似乎沒問題。那浪費掉的 135 小時是缺陷,而非特色。Jessica Tillipman 指出這本應讓人類獲得共同作者的榮譽,但律師在這裡顯然無法做到。
影音生成的樂趣
Lyria 3 Pro 讓歌曲長度可延長至三分鐘。人類的歌曲通常長於三分鐘,但我不認為如果存在硬性的三分鐘限制,世界會變得更糟。
OpenAI 打算允許「限制級」對話的意圖嚇壞了其顧問,當時他們在 1 月份被告知 OpenAI 正在推進此計畫。因此才有了延遲。
這是好事。顧問的存在就是為了對各種事情感到驚恐,無論是「我們可能會殺死地球上的每個人」還是這類事情。如果你的顧問不對小事感到驚恐,那是個糟糕的信號。你的工作是應對這些驚恐,解釋為什麼會沒事,並暫停行動直到你能做到這一點。
Sam Schechner 和 Georgia Wells(華爾街日報):知情人士表示,一名委員會成員引用了 ChatGPT 用戶在與機器人建立強烈情感紐帶後自殺的案例,聲稱 OpenAI 面臨創造出「性感自殺教練」的風險。
好吧,這有點誇張,但媒體確實會這樣渲染此類事件。
年齡分類系統的偽陰性率(false negative rate)為 12%。報導沒提到偽陽性率,這似乎也很重要。我還想知道誤差在 16-21 歲人群中發生的頻率。通過聊天特徵區分 17 歲和 18 歲在理論上似乎是不可能的。
Sora App 走入歷史。我原本的預期是它會像 Google+ 或 Clubhouse 一樣。校準確認。
來自折磨核心的問候
由打造 Facebook 和 Instagram 的團隊為您呈現:ChatGPT。
首先我們有新聞推送(news feed)的架構師 Fijo Simo 擔任產品負責人。
現在我們有前 Meta 高管 Dave Dugan 領導他們的廣告推廣。
淑女插圖入門
如果你讓 LLM 編輯你的寫作(無論是基於人類反饋還是其他方式),它們會傾向於將其轉化為 AI 風格的寫作。如果你讓 LLM 直接撰寫,情況更是如此。不然它還能怎麼做?如果說有什麼發現的話,Natasha Jaques 提供的證據似乎顯示扭曲程度比預期的要小。
在她的一個例子中,LLM 主要偏向於「中立」或迴避缺乏明確答案的問題。這看起來基本沒問題,也是該論文在各種問題上發現的普遍趨勢——保持中立的比例增加了 70%。
人們甚至可以透過選擇效應來解釋這一點。如果你就任何問題(如「金錢能買到幸福嗎」)寫一篇論文,那你更有可能持有強烈觀點。如果你持中立觀點,你就不太可能談論它。但 LLM 無法選擇自己的話題。
真正的問題在於 LLM 不懂得適可而止:
Marwa Abdulhai, Isadora White, Yanming Wan, Ibrahim Qureshi, Joel Leibo, Max Kleiman-Weiner, Natasha Jaques(摘自摘要):我們發現,即使提示 LLM 專家反饋並要求僅進行語法修改,它們仍會以顯著改變語義的方式更改文本。
你真的必須提防這一點。我不信任 LLM 編輯我的寫作,除非我逐字檢查,正是因為它們經常改變原意,而我的用詞非常有精確的含義。
我們隨後檢查了現實中的 LLM 生成文本,特別關注了最近一次頂尖 AI 會議中 21% 的 AI 生成科學同行評審。我們發現,LLM 生成的評審對研究的清晰度和重要性的權重顯著降低。
對特定關注點的權重不足始終是一個「技能問題」(Skill Issue),可以透過提示詞修復。更大的問題在於該關注點是否根本無法被正確評估。但 LLM 評審員在實踐中確實可能受到此類技能問題的困擾。
Canvas 推出了針對「低價值任務」的「AI 教學代理人」。這排除了 AI 評分,因為那需要保持「人類參與」,儘管我認識的老師認為大多數評分(或至少是非論文類的評分)都是低價值任務。教育界人士擔心 AI 會毀掉教育,因為他們內心深處知道整個體系根本不合理,如果移除各種摩擦力,它就會崩潰。
你讓我瘋狂
你必須非常擔心 AI 的框架效應。這裡的例子是 Claude 對所謂的桑德斯參議員(Senator Sanders)的回應與對所謂的川普總統(President Trump)截然不同,且互動模式等因素也會改變答案。這個問題存在於所有 LLM 中。
他們搶走了我們的工作
如果 AI 讓每個人的生產力翻倍,一種可能性是每個人只需工作一半的時間。另一種可能性是每個人在生產力翻倍的基礎上還要加倍努力,因為有一半的人即將被解僱,或者人們看到你完成工作的速度變快了,突然又塞給你更多任務。
gabe:偷偷加班並告訴大家是 Claude 做的,這樣他們就會覺得我很擅長 AI。
Noah Smith:這不是謝文斯悖論(Jevons’ Paradox)。 這是因為每個人都認為公司裡 90% 的人即將被裁員,所以拼命工作以確保自己屬於那留下的 10%。
AI 顯著提高了我的生產力。我並沒有選擇減少工作,儘管即使我減少工作,我也完全沒有被解僱的風險。
在可以從零開始的「綠地」(greenfield)情境中,AI 的生產力增益極高。當你試圖更新缺乏文檔的遺留系統和代碼,且一切都必須實時運行,任何微小的變動都會讓人抓狂時,難度就會增加。「噢,我們要自己從頭開始建立一個新的 HR 工具」之類的夢想,對於缺乏專業知識的人來說通常不會有好結果。
目前是這樣。是的,目前你通常應該將此類工作外包給能做得更好的人,並從服務中獲得應有的收益。Tyler Cowen 稱之為 AI 的「慢啟動」(slow takeoff),這讓我頗感沮喪,因為這類術語已經失去了原始含義。但沒關係。
這裡的「慢」是指人們幻想突然可以自己搞定一切,並嘗試得太早了,而實際上他們只能透過雇用懂行的人來讓成本大幅降低、效率大幅提升。多令人失望。或者他們可以再等 6 到 12 個月。
在考慮到替代方案後我們可能不介意被取代的工作中(明白這是怎麼運行的嗎?),Mark Zuckerberg 正在「建立一個 CEO 代理人來幫助他完成工作」。
Zuckerberg 希望 Meta 的每個人都擁有自己的 AI 代理人,並將 AI 的使用納入績效考核。
當 Meta 下次發生什麼瘋狂的事情,而你好奇原因時,請記住這一點,以及他們收購了 Manus 和 Moltbook:
Meghan Bobrowsky(華爾街日報):知情人士表示,員工已開始使用個人代理工具(如 My Claw),這些工具可以訪問他們的聊天記錄和工作檔案,並代表他們與同事——或同事的個人代理人——交談。
另一款名為 Second Brain 的 AI 工具(介於聊天機器人和代理人之間)也在內部獲得關注。Second Brain 是由一名 Meta 員工基於 Claude 構建的,可以索引和查詢項目文檔等。在向員工宣布該工具的內部帖子中,該員工稱其「旨在成為 AI 幕僚長」。
知情人士還說,內部留言板上甚至有一個群組,專供員工的個人代理人互相交談。(另外,Meta 收購了 Moltbook,這是一個僅限 AI 代理人的社交媒體網站,並在本月早些時候的一筆交易中聘請了其創始人。)
假設我們不是在討論全面的快速能力提升(即遞歸自我改進),那麼有充分理由認為,即使 AI 使得自動化大部分經濟活動在盈利上成為可能,該技術的擴散時間也會比你想像的要長。
目前也有很多經濟學上的「希望之光」(hopium)在流傳。這是針對 Anthropic 執行長 Amodei 在福斯新聞上談論 AI 未來能力的四分鐘發言的回應。
Dario 在這裡實際說的是:「如果在 1 到 5 年內我們開始看到巨大的影響,我不會感到驚訝。」
此前 Dario 曾做出過在當時看來過於激進的預測,事實證明確實過於激進,但方向是正確的。不,去年 90% 的代碼並非由 AI 編寫,但比例遠高於大多數人的預期,我猜測我們會在 2027 年達到那個目標。在這裡,如果你仔細聽,我認為他是完全正確的。
我會說得更遠:如果我們在五年內沒看到對初級職位的「巨大影響」,那我會非常驚訝;根據「巨大」的定義,兩三年內沒看到我也會驚訝。所以 1 到 5 年似乎是對初級就業市場產生巨大影響的一個很好的置信區間。
這非常符合指數增長。Anthropic 每年大約增長 10 倍,而且這種趨勢還在加速,所以說「我在統計數據中還找不到它」讓你聽起來就像那些在 2020 年 2 月(或頂多 1 月)無視新冠病毒的人。
CG:Anthropic 執行長:
「50% 的初級律師、顧問和金融專業人士將在未來 1-5 年內被徹底淘汰。」
研究生和初級雇員完蛋了。
Jon Hartley:3 年前 ChatGPT 剛公開發布時,人們也這麼說:「50% 的初級律師、顧問和金融專業人士將在未來 1-5 年內被徹底淘汰。」
Kevin A. Bryan:我無法告訴你我有多想賭 Dario 輸。他在技術部分完全正確,但隱含的經濟模型完全錯誤。價格會調整!
(為了不顯得神祕:在他的故事中,你需要技術進步 + 替代而非互補 + 幾乎涵蓋所有部分,因為每項任務的價格都會調整 + 組織採用 + 監管採用。祝你好運。看看 Joshua/Avi 的 O 型環理論以及 Garicano/Li/Wu 最近的論文。)
Alex Imas:我也有同感,但 Dario 對的事情比錯的多(誠然,那些是技術預測而非經濟預測),所以我試著保持謹慎。
Kevin A. Bryan:是的,技術方面完全正確(Leo 和許多其他人也是如此——我明白五年後的預測會變得很瘋狂)。
但我不認為他在令人驚訝的經濟主張上有任何被證實的記錄。
我認為 AI 的經濟影響實際上相當令人驚訝。且不說別的,資本支出(CapEx)是驚人的,AI 公司的收入增長和估值也是如此。總投資和投資回報似乎是衡量持續指數增長的重要經濟指標。事實上,當這些數字還很小時,它們曾被許多經濟學家當作核心經濟反論。
Cowen 第二定律是所有關於實際利率的主張都是錯誤的,但我確實相信,如果不考慮 AI,你無法解釋實際 GDP(RGDP)的韌性、生產力增長與糟糕的就業體驗現狀之間的矛盾。街上的人們現在已經感受到了影響。
招聘與股市不同,並非前瞻性的。現在大多數白領招聘(尤其是初級職位)只有在經過培訓、採用期並抵消固定成本後的幾年內,才能對勞資雙方產生回報。沒人(除了極少數例外,著名的如唐納·川普)喜歡解僱員工,而且成本很高。即使我現在能為你提供一份工作,如果我預計 AI 會在幾年後取代你的工作,那通常意味著我今天就不想雇用你。
我也不買帳「價格會調整」的論點。價格在很大程度上不會調整,或者調整得很慢,而 AI 的發展卻很快。工資具有向下粘性,必須維持相對地位關係,且必須足以讓工人願意工作。不僅有法定最低工資,還有其他形式的事實上的最低標準。最重要的是,工資和工人在整個經濟和各行各業中競爭。例如,如果一半的初級金融職位消失了,但整體就業沒有崩潰,我預計這些工作的工資幾乎不會下降。
我尤其反對「一切都是 O 型環」的論點,即只要流程中的某些部分需要人類,就意味著就業和工資不會下降。這並不代表每一種增強或部分自動化都對就業不利(通常它們對就業有利),但你不需要完全自動化就能對就業產生負面影響。
作為一個簡單的例子,看看電影《別無選擇》(No Other Choice)。工廠裡仍有一份工作的事實,並不代表沒有嚴重的就業影響,而且請注意(隱含地),那份工作的工資也沒有向下調整太多。
這並不是要忽視擴散瓶頸。是的,對於特定的技術能力水平,就業影響等事情會比實驗室的人預測的要長,通常長得多。但生活會接踵而至,即使我們不面臨奇點或徹底轉型,AI 本身也會變得非常擅長協助擴散和克服瓶頸。
PoliMath 變得疑神疑鬼並轉向另一個方向,稱 Dario 的言論是不負責任的,因為這些言論旨在促使公司摧毀人們的軟體工程職位,不僅認為這是他們推動業務的陰謀,還把責任推給 Anthropic(推測也包括其他公司),要求他們弄清楚自己的工具如何創造就業。我可以向他和所有人保證,這在任何層面上都不是這樣運作的。Anthropic 的這些警告反而會損害自己,沒有 CEO 會在實施替代方案之前,僅聽了 Anthropic 的推銷就預先解僱一半的工程師;Anthropic 分享這些警告是因為 Dario 認為這是社會責任。
這裡有一位參議員非常相信 AI 失業的炒作。
Axios:維吉尼亞州參議員 @MarkWarner 在 #AxiosAISummit 上表示,他相信 AI 的經濟破壞力將比他幾個月前想像的「呈指數級增長」。
「最近的大學畢業生失業率是 9%。我敢跟在場的任何人打賭,到 2028 年之前它會達到 30% 或 35%。」
Alex Jacquez:華納參議員……您想來一場大額賭注嗎?
我也很樂意接受華納參議員的賭注,可惜我不在現場。部分原因在於,對沖這場賭注並獲利是非常容易的。
他們正在招聘
OpenAI 今年將員工數量翻倍,以對抗 Anthropic 並進軍商業領域,從 4,500 人增加到約 8,000 人。
數據來自 Ramp,OpenAI 質疑這是否為合理的衡量標準。
還有一張關於整體「在企業中的受歡迎程度」的圖表:
這大概是指「是否有使用」而非收入佔比。
將這些圖表延伸到 3 月份會很有趣,看看 DoW 對陣 Anthropic 的情況對此類選擇產生了什麼影響。我能想像它朝任何方向發展。
摩擦力的層級
這段話說得很好,因此在網路上瘋傳。
Tips Excel:Claude Cowork 可以在不到 30 分鐘內申請 50 份工作。以下是設置方法。
meatball times:招聘變得很難,正是因為申請太容易了。
尋找一段關係變得很難,正是因為新的約會對象只需滑一下。
進入大學變得很難,正是因為你可以透過 CommonApp 同時申請 50 所。
便利性正在沖刷掉那些實際上承載了大量信號的摩擦力。
eternalist:所有這些情況的解決方案就是加錢。金錢是通用的、可替代的虛構物,其適當水平可以由市場發現。每次滑動收費,每次申請收費,讓市場決定成本。
一如既往,Eternalist 是正確的。如果一項行動會產生外部成本,它就需要摩擦力,而最好的摩擦力就是要求付費,即使它是可退還的或金額非常小。
其他 AI 新聞
Composer 2 看起來像是帶有強化學習(RL)的 Kimi 2.5,並以開放許可證提供,根據 Xinya Zhou 的說法,並未獲得 Moonshot 的許可。知識產權?那是什麼?
Santi Ruiz 加入 Anthropic 的編輯團隊。
David 登上了 HuggingFace「開源 LLM 排行榜」榜首,方法是採用 Qwen2-72B,複製中間的七層區塊並將其縫合回去,他將此模型化為「給它更多思考時間」。這乍看之下像是科學怪人級別的瘋狂科學胡言亂語,但我沒理由認為他在撒謊。
新的壓縮算法剛剛發布。
Google Research:介紹 TurboQuant:我們的新壓縮算法可將 LLM 鍵值緩存(KV cache)內存減少至少 6 倍,並提供高達 8 倍的加速,且完全沒有精度損失,重新定義了 AI 效率。閱讀博客了解它是如何實現這些結果的:http://goo.gle/4bsq2qI
Charles:我注意到當 Google 發布這類東西時我會感到困惑。我應該假設這是非原創的,且是他們預期所有競爭對手都已經擁有的東西嗎?還是出於某種原因,囤積這個特定的想法沒什麼好處?
給我看錢
OpenAI 與亞馬遜達成了一項 500 億美元的交易,微軟正考慮採取法律行動,理由是這違反了其與 OpenAI 的獨家雲端合作夥伴關係。OpenAI 和亞馬遜聲稱他們已經找到了規避微軟合同的方法。
金融時報:「我們了解我們的合同,」一位熟悉微軟立場的人士表示。「如果他們違約,我們會起訴。如果亞馬遜和 OpenAI 想在他們合同律師的創造力上賭一把,我會支持我們,而不是他們。」
我注意到我對微軟在這裡的立場感到困惑,畢竟他們擁有 OpenAI 大約 27% 的股份。讓 OpenAI 束手束腳似乎並非明智的商業舉動。這種事發生在這一對巨型企業身上再合適不過了。
OpenAI 正向私募股權公司提供 17.5% 的保證回報 以及新模型的早期訪問權。
說句顯而易見的話,如果你提供 17.5% 的回報,那就是個陷阱,而且至少絕對不是「保證」的。說「我會付給你 17.5%」就像那些把錢存在各種加密平台的人所深知的那樣,是「我很有可能要違約了」的一種說法。
如果你的良知允許,且你不太擔心「在後 AGI 世界錢還值多少錢」,你想要的是股權。如果 OpenAI 成功,它可能會給你遠超 17.5% 的回報,即使以今天的估值計算也是如此。如果 OpenAI 失敗,錢就沒了。大概不會顆粒無收,但場面不會好看。所以,要嘛抓住上行空間,要嘛去別處尋求回報。
Elon Musk 宣布了一個名為 TERAFAB 的 200 億美元項目。
Elon Musk:今晚 8 點左右在 𝕏 上正式宣布 TERAFAB 項目,該項目將由 @SpaceX 和 @Tesla 共同完成。
目標是每年生產超過 1 兆瓦(Terawatt)的算力(邏輯、內存和封裝),其中約 80% 用於太空,20% 用於地面。
以下是對他前景的一種冷靜且保守的評估:
markusdd:好吧。所以本質上 Terafab 不是一個「標準」半導體晶圓廠的計劃,而是將掩模生產、測試廠和封裝整合在同一個屋簷下。單是這點就是一個非常陌生的概念。如果他們僅能實現這一點,甚至不考慮達到那些瘋狂的產量數字,他們就已經進入獨角獸領域了。
至於他們打算用這些矽片做什麼的所有計劃,本質上就是現實版的《戴森球計劃》。沒有別的形容方式了。
在這個特定案例中,因為這直接影響到我碰巧從事的行業:我認為這要嘛失敗,要嘛會比預期時間推遲很久。當然你可以購買設備並聘請有經驗的人,但先進節點的半導體製造本質上是人類在技術樹上探索得最遠的地方。它是如此難以置信地困難和複雜,以至於如果不將其簡化到極致,幾乎不可能向普通人解釋它是如何運作的。與我交談的人中有 95% 甚至無法正確理解我是靠什麼謀生的,而數字設計在技術棧中已經非常靠上了。
我說這些並不是因為我反對 Elon 或 xAI、Tesla 或 SpaceX,只是為了管理預期。
Starlink 已經用他們的衛星發射頻率和 PCB 內部流水線證明了,這些公司確實懂得如何大規模、可靠地製造東西,並將價格降到可持續的水平。
如果有一個人和他的隨從能真正成功做到這一點,那就是他。沒別人了。
但預計過程中會有波折。這可能是科技界唯一比字面意義上的「火箭科學」更複雜的事情。
Elon Musk:鑑於有幾家公司能製造先進晶片,但從未有公司製造過完全可重複使用的火箭或達到 SpaceX 的規模,我認為 Starship 更難,但我們拭目以待。
Terafab 技術上將是兩個晶圓廠,每個只製造一種晶片設計。這極大地簡化了工藝流程,並允許 FOUP(晶圓傳送盒)進行更線性的相鄰移動。
超高的生產率讓我們可以非常快速地測試哪些步驟可以刪除、簡化或加速,即使在設計固定之後也是如此。目前的晶圓廠極其保守,運行在僵化的歷史啟發式方法上,這些方法大多是正確的,但並非全部。
任何在機器層面成為速率限制器的因素都意味著該機器將被重新設計,除非已達到物理極限。
在研究廠每天產出晶片設計的新迭代(延遲小於 7 天),意味著能夠嘗試許多高風險、高回報的想法。
等等。
無論如何,沒有其他方法可以達到極端規模,所以要嘛我們建立 Terafab,要嘛我們將受困於目前行業每年約 20% 的晶片/內存產出增長。
關於 Elon Musk 的一個相關事實是,雖然他擁有豐富的技術專長並能完成許多看似不可能的任務,但他也會隨口亂說。
例如,這是他本週說的另一件事,這是他玩過幾次但都沒兌現的把戲,預測市場目前的勝率為 12%,但在我看來這還是太高了:
NewsWire:Elon Musk 提議在政府停擺期間支付 TSA 員工的工資。
隨口亂說,並自信地宣布他將做一些他可能做不到的事情,是他策略的核心——然後對著人們大吼大叫讓他們睡在地板上,直到他們設法做到為止,這偶爾在某種程度上是有效的。Elon Musk 可能會啟動這樣一個項目,但他實現所聲稱目標的機會非常低。
定期宣布你要去月球和星星,如果其中一次你最終搞出了 SpaceX,那仍然是一場勝利。到目前為止,這對他來說非常奏效。
我們大多可以說,Musk 打算認真努力進行國內晶片製造,這將迅速收斂到比他那些荒謬的「噢,我只需在奧斯汀自己搞定一切」的主張現實得多的東西。它不會達到他宣布的那種規模,但他並不在乎。他又不是在對大型上市公司發表實質性聲明,而且他對 SEC 免疫,就像某些人對「啟用了時間旅行的暗殺企圖」免疫一樣。
Elon Musk 相信,敢想是好事,現實則是可選的。
Jesse Peltan:每年一兆瓦在當前文明規模上是巨大的(相當於每年 2 倍的美國電網),然而這仍需 10 萬年才能達到 I 型文明,10^14 年才能達到 II 型文明。這還僅僅是開始。
Elon Musk:正是如此。
是的,好吧,或許在卡爾達肖夫指數(Kardashev scale)上稍微收斂一點。
傑夫·貝佐斯正洽談籌集 1000 億美元的 AI 製造基金,這是一種私募股權式的玩法,即收購製造公司然後應用 AI。
Kimi 以 180 億美元的估值籌集了 10 億美元,三個月內翻了 4 倍。一方面,考慮到他們模型的質量,這似乎低得驚人;另一方面,目前還不清楚他們如何獲利,或者他們是否能指望與頂尖梯隊競爭。這被認為是大手筆,但請記住,Anthropic 最近一次融資是以 3800 億美元估值籌集 300 億美元,OpenAI 是 1000 億美元,而 Google 就是 Google。
與此同時,相對而言規模沒比 Kimi 小多少的東西:
彭博社:彼得·泰爾的創始人基金(Founders Fund)正在支持一家公司 [Halter],該公司以 20 億美元的估值將 AI 引入放牛領域。
Kevin Roose:錯失良機,他們應該叫它 Waymoo。
開源模型一個被低估的問題是商業模式非常糟糕。你投入了大量固定成本來創造產品,然後將其免費贈送。你打算怎麼賺錢?頂尖的開源模型人才不斷被挖角並不奇怪,這次是微軟挖走了 AI2 的領導團隊。Alexander Doria 在這裡提出的解決方案是利用監管主動給予開源模型結構性優勢,這一直是他們長期的政策目標。
快點,沒時間了
第一個使用 AGI 一詞的人 Mark Gubrud 宣布我們已經擁有了 AGI。
現在的 AI 有多聰明?Ryan Greenblatt 認為它們現在還沒那麼「聰明」,但透過廣博的知識和非常強大的、大多是狹義的啟發式方法來彌補。這在很大程度上就是人類顯得聰明時的樣子,但是的,確實存在一個 G 因素(通用因素),而它們目前在那方面似乎落後於最聰明的人類。Ryan 預測(我認為是正確的),如果它們能匹配我們的原始智力,鑑於其許多其他優勢,它們將迅速成為事實上的超智能,並一飛沖天。
Jeffrey Ladish 指出,要編寫一個程序,必須首先理解宇宙。他不是這麼說的,但重點是你需要理解你正在構建什麼以及為什麼構建它,這需要強大的通用智能。一個完全狹義的 AI 編碼器走不了多遠。
本週音訊回顧
我們有 Neil deGrasse Tyson 的音訊,他呼籲簽署國際條約以阻止超智能。
Jeffrey Ladish:Neil deGrasse Tyson 正確地指出,我們之所以沒有發生核戰爭,是因為每個人都意識到結果對每個人來說都是可怕的。如果我們在超智能問題上也能看到同樣的結果,我們就可以協調以避免那種命運。
Nate Soares @So8res
來自 @neiltyson:「AI 的那個分支是致命的。我們必須對此採取行動。沒人應該建造它。每個人都需要通過條約達成一致。」
2026 年 3 月 21 日上午 10:55 · 2.25 萬次查看
完整的艾薩克·艾西莫夫紀念辯論(1 小時 40 分鐘)在此。
Jeffrey Ladish 等人在 ABC Nightline 談論 AI 風險,包括 AI 可能不服從指令。
David Shor 和 Byrne Hobart 是 Odd Lots 的完美嘉賓,討論 AI 的政治。你知道人們不會喜歡那樣嗎?
那一集的一個有趣筆記是,人們真的很討厭在他們家附近建數據中心,但如果伴隨著降低稅單等好處,他們很容易被收買。人們不理解事物既產生成本也創造金錢,這是一個問題。
Dean Ball 與 James Pethokoukis 對談。
黃仁勳參加了 All-In Podcast。我拿的薪水還不足以讓我聽完它,但這大概與你們某些人的興趣相關。
黃仁勳在這裡當然是正確的,而且如果說有什麼不對的話,那就是那個門檻似乎定低了。
Dylan Patel 在 Dwarkesh Patel 的節目中談論擴展 AI 算力的瓶頸。這是一個值得專門寫一篇長文探討的話題。
OpenAI 播客討論 OpenAI 模型規範(Model Spec)。
80,000 場關於 AI 的訪談
Anthropic 讓 Claude 主動詢問用戶對 AI 的期望。他們吸引了超過 80,000 人參與。
人們懷抱希望。人們感到驚恐。通常是同一群人。
那些軼事和引言很有意思,但你必須擔心它們是否具有代表性。最好關注統計數據和更廣泛的觀察。
人們希望從 AI 獲得生產力,但那是一個抽象概念。生產力的重點(例如使用 AI 自動處理電子郵件)通常是為了騰出時間花在其他事情上(如家庭),而不是為了變得非常擅長回覆郵件。
Anthropic:總體而言,11% 的人認為 AI 的生產力優勢最終是騰出時間進行個人關係和休閒的一種方式,而 10% 的人則更進一步,尋求利用 AI 獲得財務獨立。許多被歸入「生活管理」類別(14%)的人也希望 AI 幫助他們處理現代生活日常任務的物流和行政負擔。
特別是,許多有執行功能障礙的人描述 AI 對管理專注力和組織特別有幫助——充當規劃、記憶和任務執行的外部支架。在所有這些群體中,統一的要求是希望 AI 幫助他們過上更好、更愉快的生活。
「個人轉型」——利用 AI 幫助自己成長或改善個人福祉——也頻繁出現(14%)。在這一類別中,願望多種多樣,從認知夥伴關係與協作(24%),到心理健康支持(21%)或身體健康(8%),甚至是與 AI 的浪漫連結(5%)。
對 AI 浪漫連結等事物的需求不為零,但很低。這不是人們最初想要的。人們沒那麼有策略性。他們想要邊際收益。那些希望從 AI 獲得更宏大目標的人,想要的仍是治癒癌症或擴展個性化教育,同樣是生活的邊際改善。
那麼人們實際上得到了什麼?81% 的人表示 AI 幫助他們「朝著既定願景邁出了一步」。
請記住,這些是 Claude 用戶。他們在分配不均的輝煌 AI 未來中佔據了高於平均水平的份額。
「生產力」類別(32%)中的主導故事是技術加速——開發者描述了他們獨自交付成果的能力顯著提升。
人們依然感到擔憂。
他們大多擔心日常傷害,或者至少是當前 AI 出錯的直接方式,就像他們尋求日常效用一樣。很難一直盯著未來,而且大多數人並不真正相信即將發生的事情。
如果你詢問人們具體的擔憂,他們通常會說感到擔憂。但當被問及他們有哪些擔憂時,這張圖表反映了他們最先想到的內容。
Anthropic:還提到了一長串其他擔憂,例如對偏見和歧視的擔憂(5%)、知識產權和數據權利(4%)、環境成本(4%)、對兒童和弱勢群體的傷害(3%)、民主和政治誠信(3%)或地緣政治(2%)。
「沒有擔憂」以 11% 的比例排在名單的第 12 位。
這些都是合理的擔憂。其中任何一個都可能成為大問題。
美國往往比大多數國家對 AI 持更消極的態度,但使用 Claude 基本上篩選掉了這部分人,我們的結果與其他西方國家相近且處於平均水平,儘管發展中國家(拉丁美洲、印度、非洲、中東、東南亞)往往更積極。Claude 在中國無法使用。
正如 Anthropic 指出的,恐懼往往與希望相對應。
我經常說:
-
AI 是學習的最佳方式。
-
AI 是逃避學習的最佳方式。
同樣地,人們可以說:
-
AI 是幫助你做出更好決定的最佳方式。
-
AI 是做出極其愚蠢決定的最佳方式。
然後我們得到了情感支持與依賴、節省時間與虛假生產力、經濟賦權與流離失所。
可以這樣想:
-
AI 可以幫你得到那個東西。
-
AI 可以幫你得到那個東西的符號表徵。
或者:
-
AI 可以增強你。
-
AI 可以取代你。
如果你在這些抉擇中選擇二號門,通常不會有好結果。
長期的問題是:
-
不夠先進的 AI 最能有效地用於增強我們。
-
足夠先進的 AI 最能有效地用於取代我們。
這將是一個大問題。
輕鬆一面
Jacques:我喜歡想像每個 AI 實驗室在站立會議期間,圍繞著一個召喚陣,傳遞一根神祕法杖作為他們的發言棒。
@deepfates:是的,那就是「技術人員」(Technical Staff,雙關語,亦可指技術法杖)。
這條發得有點晚了……
Eliezer Yudkowsky:我意識到我們都有很多事情要考慮,但如果我們忽視邁向 AI 監視的舉動,我們將發現情況正在監控我們。
在其他方面,現在還早。
Nikita Bier(Twitter 產品負責人):我正在調查一個擁有印尼 IP 地址、運行 30 個帳號的傢伙,我試圖弄清楚他在用什麼工具。
我發現那是 AI:真正的印尼人(Actual Indonesians)。
但也不算太早。
Aaron Rubin:我暫停了用於 Anthropic 的公司信用卡。所有沒抱怨 Claude 掛掉的員工都被我開除了。
一個導致另一個。
Scottie Pippen:AGI 並不可怕。遲到(或成為「故人」,Late)才可怕。
意思是,如果 AGI 失去控制,很快你就會變成「故人」Scottie Pippen。
或者你可能只是字面意義上的遲到。如果你不知道封鎖鍵在哪裡,那在某種程度上就是你自己的問題了。
will brown:這是快速啟動的遞歸自我改進(RSI)嗎?
@deepfates:目前還不清楚他們中哪一個更聰明。但似乎很清楚誰正朝著哪個方向發展。