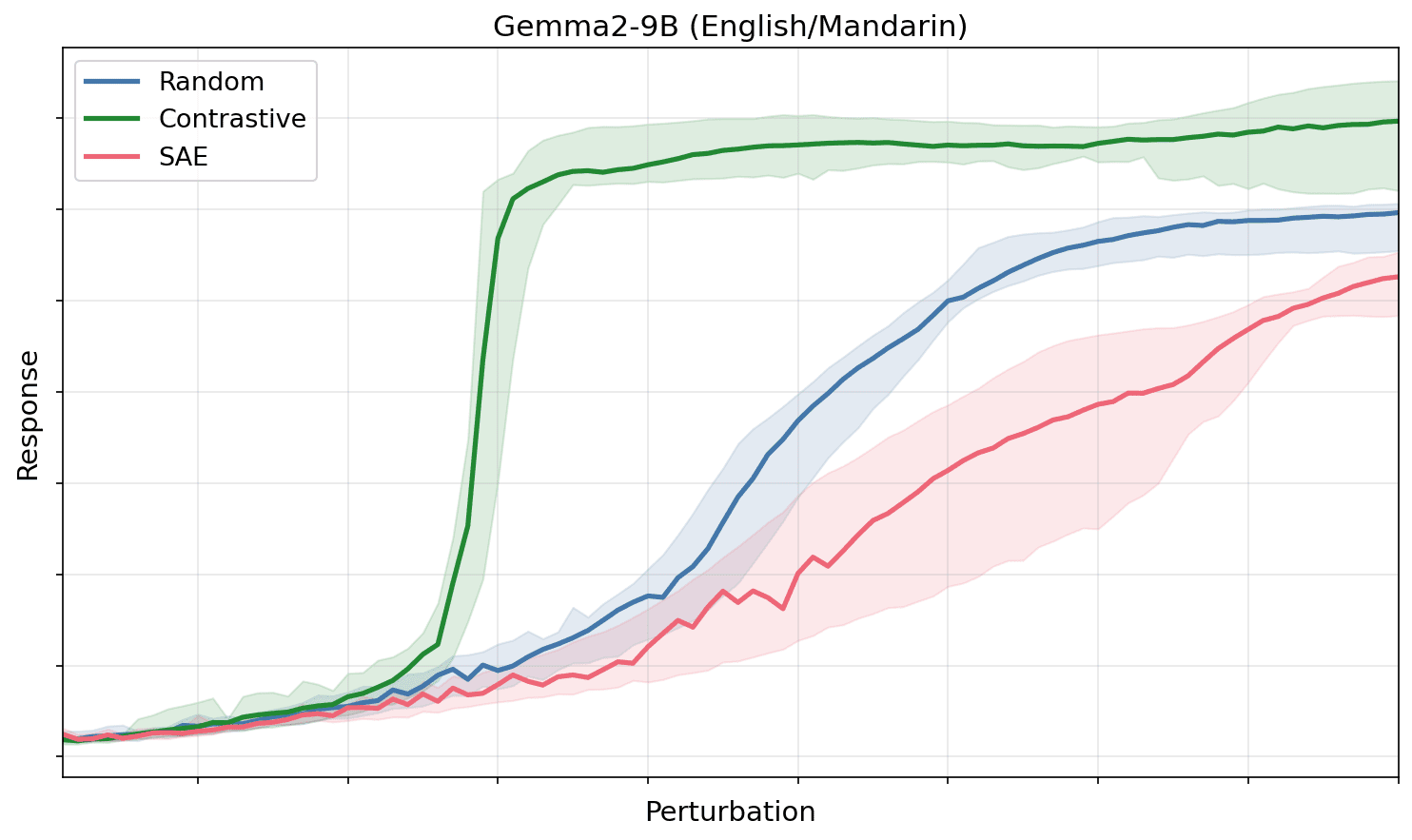
在 Transformer 中尋找特徵:對比方向比基準方法更能誘發強烈的低階擾動反應
研究人員發現,與 SAE 方向或隨機雜訊相比,英文到中文等對比方向在較小的擾動幅度下能誘發更強的下游模型反應。這顯示對比探測可能比目前的稀疏自動編碼器方法更有效地識別大型語言模型內部的真實計算特徵。
這是一篇研究更新,分享了正在進行的工作中的初步結果。
圖 1:對比(均值差,英語→中文)特徵方向在比 SAE 方向小得多的擾動強度下,即可激發下游響應,而 SAE 方向的表現則與隨機方向相似。這一結論在多個模型和實驗設置中均成立。
摘要與主要結果
理解概念在大型語言模型(LLM)內部是如何表示的,對於 AI 安全(通盤理解 AI 的思考方式、AI 控制與監控、重新定位搜索)將極其有用。我們假設概念被表示為激活空間中的方向(「特徵」)。目前最流行的特徵尋找方法——透過稀疏自編碼器(SAE)進行稀疏字典學習——面臨著強烈的數據集依賴性(例如 Heap et al. 2025, Kissane et al. 2024, Heimersheim 2024)。因此,目前尚不清楚它們找到的方向是反映了模型的計算過程,還是僅僅反映了訓練分佈的特性。
相反地,我們建議透過沿著某個方向擾動激活值,並根據模型的響應來判斷該方向是否對應於一個特徵(遵循 Mack & Turner 2024, Heimersheim & Mendel, 2024)。我們假設隨機方向的擾動會被抑制,因為它們只會在特徵方向上產生干擾噪聲;而特徵方向的擾動則會產生集中的干擾並激發強烈的模型響應。如果是這種情況,我們應該會看到隨機方向的抑制區域比特徵方向更長。
我們的新貢獻在於使用對比探針/引導向量(contrastive probing/steering vectors)測試了這一假設。 我們為語言(英語→中文)、編程語言(Python→Haskell)和性別(男性→女性)在不同的模型系列(Gemma 2-9B, Llama 3.1-8B, 以及 Qwen 3-1.7B)中構建了對比向量(均值差)。接著,我們沿著對比方向、SAE 特徵方向和隨機方向[1]對模型進行擾動,並比較如圖 1 所示的模型響應。我們發現對比方向確實激發了強烈得多的響應,而 SAE 特徵和隨機方向則需要大得多的強度才能產生類似的響應強度。據我們所知,這是首個候選特徵激發出定性上不同的模型響應的例子。(儘管 Mack & Turner 2024 先前展示了接近相反的結論:即激發不同模型響應的方向通常表現得像引導向量。)
圖 2 顯示了另外兩個對比向量(男性→女性,Python→Haskell)和另外兩個模型(Llama 3.1-8B, Qwen 3-1.7B)的擾動曲線,產生了相同的結果。在所有案例中,我們都在早期的殘差流層[2]擾動激活值。我們保持激活值範數(norm)不變,並以恆定的角速度進行擾動(遵循 Heimersheim & Mendel, 2024)。我們將模型響應測量為倒數第二層中擾動激活值與未擾動激活值之間的 L2 距離。我們將所有單獨的響應曲線顯示為細線,中位數顯示為粗線。
圖 2:跨多個模型和不同對比對的擾動響應。左上:Gemma 2-9B,男性→女性。右上:Gemma 2-9B,Python→Haskell。左下:Llama 3.1-8B,英語→中文。右下:Qwen 3-1.7B,英語→中文。
在所有組合中,我們觀察到沿著均值差方向進行擾動,在比隨機方向或 SAE 特徵小得多的強度下就能突破抑制區域。在大多數情況下,SAE 特徵方向的擾動看起來與隨機擾動相似。
解讀: 我們將第 1 點視為我們的主要貢獻;第 2 點和第 3 點與過去關於激活平台(activation plateau)的文獻一致。
- 對比向量(我們對某些真實特徵方向的最佳猜測)顯示出不同的響應曲線,這一事實讓我們對這種基於激活擾動的研究議程有機會識別模型特徵感到樂觀!
- 我們的 SAE 結果(證實了 Lee & Heimersheim 2024 和 Giglemiani et al. 2024)表明,SAE 方向並未被模型特殊對待。這證明了 SAE 可能沒有找到模型的真實計算特徵。
- 觀察到初始的「激活平台」(證實了 Heimersheim & Mendel, 2024, Janiak et al. 2024, Shinkle & Heimersheim 2025)可能是 Hänni et al., 2024 所提出的錯誤修正(error correction)的證據(儘管請參閱 @LawrenceC 在此處的評論)。
引言
理解 LLM 如何在內部表示概念對於 AI 安全極其有用,因為這將有助於更深入地理解模型行為、更好的對齊研究反饋迴路、監控模型認知中的不良過程(例如複雜的謊言檢測、AI 控制),以及潛在的未來對齊想法(例如重新定位搜索)。
我們假設概念被表示為激活空間中的方向(Olah, 2024)。在疊加(superposition)情況下(Elhage et al. 2022),模型表示的特徵數量遠多於其維度。這意味著特徵不可能是完全正交的,因此沿著一個特徵方向的擾動也會在其他特徵方向上產生分量(「干擾」)。Hänni et al., 2024 聲稱,為了在疊加狀態下執行有意義的計算,干擾必須被抑制,也就是說,模型必須實現某種形式的錯誤修正。
最流行的特徵尋找方法——透過稀疏自編碼器進行稀疏字典學習——面臨著強烈的數據集依賴性(例如 Heap et al. 2025, Kissane et al. 2024, Heimersheim 2024)。目前尚不清楚它找到的方向是反映了模型的計算,還是訓練分佈的特性。這激發了尋找一種獨立於數據的方法,來測試方向是否具有計算意義。
如果模型實現了錯誤修正(或以其他方式對干擾噪聲具有魯棒性),激活值對擾動的敏感度應該是各向異性的:對大多數方向的擾動應被視為干擾噪聲,因此對下游影響很小;而專門針對特徵方向的擾動在低強度下就會產生大得多的影響。由於特徵方向僅佔所有方向的一小部分,隨機方向的表現應像干擾噪聲,因此特徵方向應在比隨機方向更小的擾動強度下激發響應。
先前的研究(Heimersheim & Mendel, 2024, Janiak et al. 2024, Shinkle & Heimersheim 2025)觀察到,Transformer 激活值的下游響應在小擾動強度下確實會被抑制(「激活平台」)。Lee & Heimersheim 2024 發現對 SAE 方向的擾動也會被抑制。Mack & Turner 2024 直接優化了具有巨大下游影響的方向,並發現它們起到了引導向量的作用。在這裡,我們試圖在不直接優化效果的情況下,尋找其他具有巨大下游影響的方向(特徵)。
實驗設置
我們在早期層沿著候選方向擾動模型激活值,並在後期層測量下游響應。我們比較了三種類型的方向:對比方向(均值差)、SAE 特徵和隨機方向。以下詳細說明實驗設置。
模型、層與指標。 我們在三個不同系列的模型上進行實驗:Gemma 2-9B, Llama 3.1-8B, 以及 Qwen 3-1.7B。我們在早期的殘差流層進行擾動:Gemma 和 Llama 為第 2 層,Qwen 為第 7 層。這些是我們能獲取各模型 SAE 的最早層。儘早進行擾動是理想的,因為先前的研究表明,擾動與測量之間的層數越多,抑制效果越明顯(Shinkle & Heimersheim, 2025)。對於所有模型,我們在倒數第二個殘差流層測量下游響應,計算方式為擾動激活值與未擾動激活值之間的 L2 距離。
擾動方法。 所有擾動都在超球面上進行,即保持激活值範數不變,以將方向的影響與範數的影響隔離開來。我們以恆定的角速度進行擾動:圖表的 x 軸顯示原始激活值與擾動激活值之間的角度(以度為單位)。我們始終在最後一個 token 位置進行擾動。
對比方向。 我們將對比向量構建為兩類各 30 個語義匹配提示詞(即僅在一個概念上有所不同的提示詞,例如英語和中文的「太陽升起在」)之間的平均激活值差異。我們針對英語 vs. 中文文本、Python vs. Haskell 代碼以及男性 vs. 女性進行了此操作。接著,我們沿著對比方向,將其中一類中 10 個保留提示詞(held-out prompts)的激活值向另一類擾動(例如,將英語激活值向中文方向擾動)。
SAE 方向。 對於每個保留的激活值(例如英語提示詞),我們識別在該輸入上激活最強的 SAE 特徵,並沿著其中的 10 個進行擾動。我們還測試了從完整字典中隨機選擇的 SAE 特徵,以及在相反類別上強烈激活的特徵(例如,將中文激活特徵應用於英語激活值);結果相似。
隨機方向。 我們將隨機方向構建為隨機採樣的 FineWeb 提示詞激活值之間的差異。以這種方式構建的隨機方向會偏向激活空間中的高方差方向,使其成為比激活空間中均勻採樣的隨機向量更強的基準線(Heimersheim & Mendel 2024)。
額外結果與魯棒性檢查
我們的主要結果已在「摘要與主要結果」章節中描述。在這裡,我們展示實驗設置的變體和消融實驗,以確認我們的結果對這些選擇具有魯棒性。
首先,我們執行加法擾動而非球面擾動,即不保持範數固定,並使用恆定的線性步長而非恆定的角度步長。在圖 3 中,我們展示了結果在這種變體下依然成立,這表明激活範數動力學並非該效應的主導因素。
圖 3:Gemma 2-9B 上的加法(非恆定範數)擾動,英語→中文。x 軸顯示擾動的 L2 範數而非角度。
其次,我們使用激活空間中 L2 距離以外的指標來測量下游影響:Logits 的 KL 散度,以及同一殘差流層的餘弦距離(定義為 1 - 餘弦相似度)。KL 散度測量對模型輸出分佈的影響而非內部激活值,而餘弦距離則將下游變化的方向組件與其大小隔離開來。如圖 4 所示,我們的結果再次保持一致。
圖 4:Gemma 2-9B 英語/中文上的替代下游指標。左:Logits 的 KL 散度。右:激活空間中的餘弦距離。
最後,我們在較後的層進行擾動,即第 8 層而非第 2 層。先前的研究表明,擾動與測量之間的層數越多,抑制效果越尖銳(Shinkle & Heimersheim, 2025)。正如預期的那樣,我們發現第 2 層的擾動比第 8 層產生更強的平台效應,但對比方向與其他方向之間的差異仍然清晰可見(圖 5)。
圖 5:擾動層對 Gemma 2-9B 英語/中文的影響。左:第 2 層(基準線,與圖 1 相同)。右:第 8 層。
結果在所有變體中保持一致,支持了我們發現的魯棒性。
代碼與數據
支持本貼文的所有代碼和數據均可在 github.com/FranciscoHS/contrastive-vs-sae-perturbation 獲取。
未來工作
我們對這項工作的後續研究感到興奮,主要有三個方向:
- 我們可能已經有了一種測試方向是否為特徵的方法。我們能用它做什麼?一個明顯的例子是將我們的測試作為尋找類特徵方向的無監督優化標準(例如額外的 SAE 損失項;MELBO 擴展)。我們熱衷於探索利用此測試的其他方式!
- 我們從錯誤修正的角度審視了我們的結果。我們能否將錯誤修正的解釋(在疊加計算的意義上)與其他魯棒性解釋(例如 @LawrenceC 在此處的評論)區分開來?我們能否測試神經網絡的計算理論?錯誤修正是否能預測縮放法則(scaling laws),例如模型響應作為擾動特徵數量的函數?
- 在激活平台的背景下,我們能否測試關於激活空間幾何形狀的假設?特徵表示是離散的(例如 二進制)還是連續的?激活值集合是位於向量空間還是(非歐幾里得)流形上?
致謝
本工作由 Pivotal Fellowship 資助。
感謝 Ariel Gil, Reilly Haskins, Arnau Marin-Llobet, Motahareh Sohrabi, Zheng (Zack) Hui 和 Andrew Mack 的有益討論。