
大 AI 晶片荒
AI 算力需求與代理型工作流的快速激增,導致台積電 N3 晶圓產能嚴重短缺,迫使雲端巨頭在爭奪有限矽資源的同時,大幅上修資本支出計劃。
大規模 AI 晶片短缺
台積電 N3 晶圓短缺、記憶體限制、資料中心瓶頸、供應鏈戰爭的贏家
SemiAnalysis x Fluidstack 黑客松
我們將在今年 GTC 之前的 15 日(週日)與 Fluidstack 合作舉辦一場黑客松,非常歡迎您的加入!
在此申請:https://luma.com/SAxFSHack

算力短缺
Token 需求正呈爆炸式增長,對 AI 算力的需求持續加速。模型能力的提升結合代理型工作流(agentic workflows)的快速興起,推動了用戶採用率和總體 Token 需求的激增。光是在 2 月份,Anthropic 就增加了驚人的 60 億美元年化經常性收入(ARR),這主要歸功於其代理型編碼平台 Claude Code 的廣泛採用;如果 Anthropic 擁有更多算力,他們的增長還會更多。儘管過去幾年進行了大規模的 AI 基礎設施建設,可用算力依然稀缺。按需 GPU 價格持續上漲,甚至連已經接近過時兩代的 Hopper 晶片也是如此。
根據我們自身的經驗,我們聯繫了所知道的每一家新型雲端服務商(neocloud),詢問是否有小型集群可用,但所有資源都已被牢牢鎖定。這種供應緊張的環境解釋了超大規模業者(hyperscaler)資本支出計劃的劇烈調整。市場共識預期已全面大幅上調,其中 Google 最為極端,其 2026 年的資本支出預期較先前大約翻了一倍,主要由資料中心和伺服器支出驅動。

這是一個巨大的支出水平,如果可以的話,超大規模業者會投入更多資金,但他們受到一個關鍵因素的限制:晶片供應。目前的先進邏輯和記憶體製造產能根本不足以支撐算力部署的速度。雖然 AD(ChatGPT 發布後)時代一直充斥著各種限制,如 CoWoS 封裝和資料中心電力,但我們現在已正式進入晶片短缺階段。

台積電 N3 短缺
最大(即便不是唯一)的限制之一是台積電的 N3 邏輯晶圓產能。台積電的 N3 系列於 2023 年開始貢獻營收,最初需求主要由智慧型手機和 PC 驅動。N3 的起步並不穩健,第一個變體「N3B」存在良率問題,且相對於密度提升而言成本過高。隨著改良後的 N3E 製程出現,採用率大幅提升,這是一個放寬規格的變體,EUV 層數大幅減少,因此成本更低。主要的智慧型手機和 PC 客戶包括蘋果(其 M3 至 M5 Mac 晶片和 A17 至 A19 iPhone 處理器使用 N3 變體)、高通(Snapdragon 8 Elite 系列)、聯發科(天璣系列手機 SoC 以及部分汽車和 PC 晶片),以及英特爾(Lunar Lake 和 Arrow Lake 客戶端處理器)。

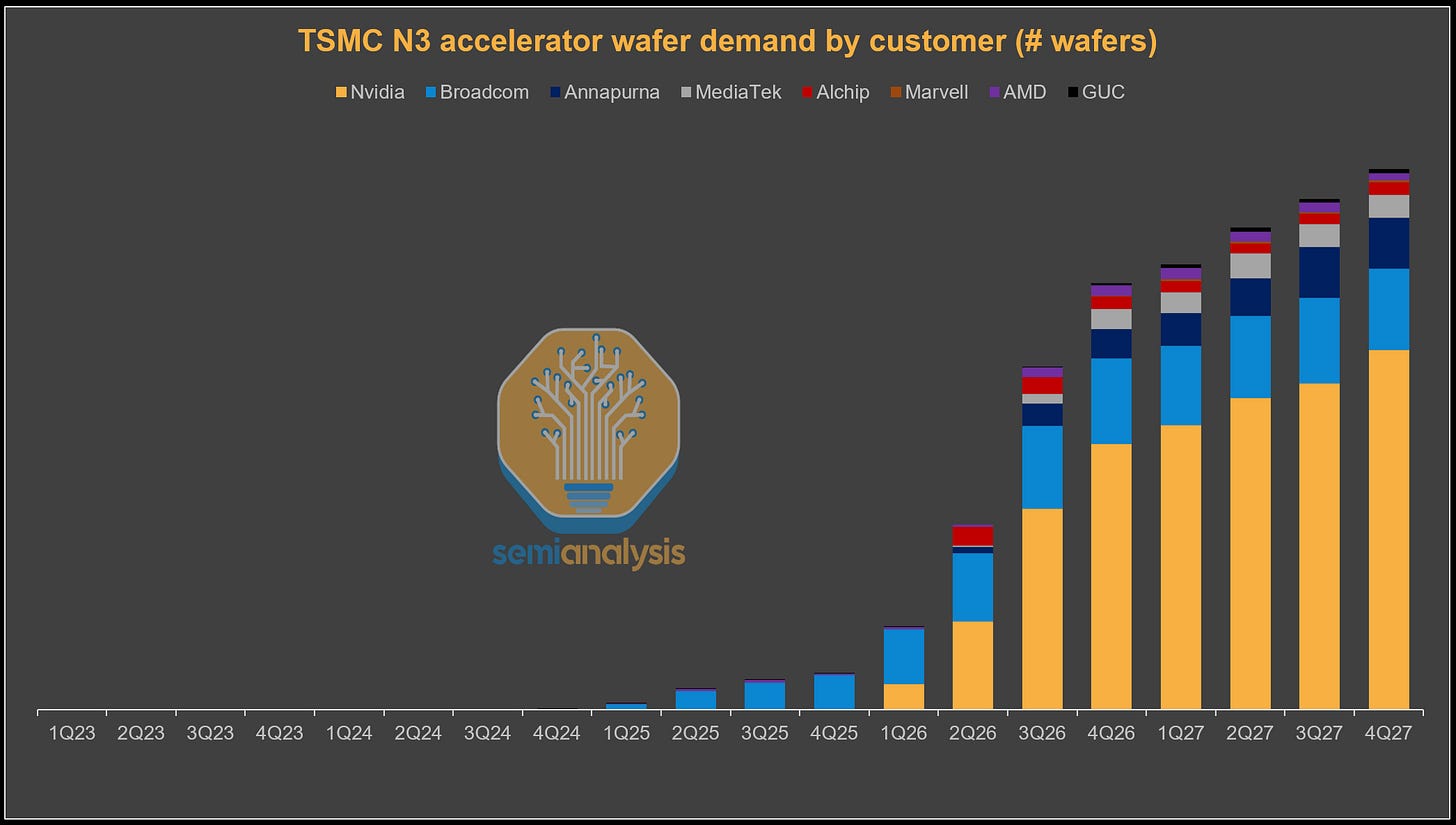
直到今天,N3 需求主要由消費電子產品驅動。到 2026 年,所有主要的 AI 加速器系列都將轉向 N3,在轉向 N2 及更先進製程之前,AI 將佔據 N3 需求的大部分。
從下表可以看出,進入 2026 年,整個產業都向台積電的 N3 系列匯集,將其作為 AI 加速器的領先製程節點。NVIDIA 從 Blackwell 的 4NP 轉向 Rubin 的 3NP。通常較早採用新節點的 AMD,已經在 MI350X 上採用了 N3,並將在 MI400 的 AID 和 MID 小晶片(tiles)上繼續使用 N3(XCD 為 N2)。Google 的 TPU 路線圖從 TPU v7 開始全面轉向 N3E,TPU 今年的專案產量將大幅提升。AWS 也將憑藉 Trainium3 轉向 N3P。Meta 的 MTIA 也遵循類似路徑,儘管產量會低得多。

這種轉變不僅限於 XPU 晶片。VR 機架中使用的 Vera CPU 所有晶片均採用 N3P。此外還有 NVLink 6 交換器形式的網路晶片,以及 Tomahawk 6 和 Spectrum 6 等擴展交換器。隨著 Rubin 為每顆 GPU 提供 1.6T 的擴展網路,Rubin 開啟了 3nm 200G 光學 DSP 的採用。
N3 採用的突然匯集,加上 AI 算力需求的持續增長,導致了 N3 晶圓產能的巨大需求衝擊。台積電顯得措手不及,晶圓產能擴張未能跟上激增的 AI 需求。這是如何發生的?儘管歷史上最大的算力建設始於 2022 年底,但台積電的資本支出直到 2025 年才超過之前的峰值。今年,台積電將打破去年的資本支出紀錄,因為他們意識到客戶需求超出其產能的程度有多大。

雖然台積電對其僅有的競爭對手英特爾和三星保持著明顯的技術領先,但如果客戶無法獲得足夠的晶圓供應來支持其業務,這種優勢就不那麼重要了。因此,產能限制可能會促使客戶探索更多樣化的代工選擇。例如,英特爾擁有政府的支持,任何向英特爾代工服務(Intel Foundry)的外包都將贏得美國政府的青睞。同時,三星代工(Samsung Foundry)的勢頭也開始增強,最近獲得了一些設計定案(design wins)。首先,三星已獲得特斯拉的一些晶片專案,如 AI5 和 AI6,儘管這些專案與台積電雙軌並行。三星代工也進入了 NVIDIA 的資料中心供應鏈,這是我們在代工模型中討論過的進展。
N3 的數據分析
現在,讓我們看看情況有多緊繃。N3 加速器晶圓需求在今年大幅攀升。主要驅動因素是 NVIDIA 從基於 4NP 的 Blackwell 轉向基於 N3P 的 Rubin 世代時的產能爬坡。然而,考慮到平台和供應鏈的成熟度更高,Blackwell 今年的出貨量仍將高於 Rubin。Google 和博通(Broadcom)的 TPU 比 NVIDIA 和 Amazon 更早進入 N3,TPUv7 晶片已在 2025 年投產。由於 Google 內部以及 Anthropic 等外部需求的推動,TPU 出貨量今年將大幅增加,這種勢頭將持續下去。同時,向下一代 TPUv8 變體的過渡也將開始,該變體也將留在 N3 節點。另一個主要的變數是基於 N3P 的 Trainium3,將從 2026 年初開始投入晶圓,並在下半年大幅提升產出。
因此,AI 相關需求(加速器、主機 CPU 和網路 N3 需求)最終佔據了今年 N3 產出的近 60%。剩下的 40% 主要用於智慧型手機和 CPU。來自這些來源的需求完全消耗了 N3 的全部產能,這使得台積電幾乎沒有增加更多產能的空間。這種緊繃狀況在 2027 年會變得更加嚴重,即使台積電增加了 N3 產能。我們預測 2027 年 AI 需求將佔 N3 晶圓產出的 86%,幾乎完全擠壓了智慧型手機和 CPU 晶圓。這種轉變的部分原因在於計劃中的智慧型手機路線圖轉向 N2,但 N3 產能的緊張無疑在加速這一轉變中發揮了作用。對於留在 N3 的產品線,需求不太可能得到完全滿足。

台積電最終在爭奪有限 N3 配額的客戶中扮演著「造王者」的角色。在 2026 年,AI 基礎設施客戶顯然比消費電子產品獲得更高的優先權。AI 加速器設計通常具有更大的晶粒尺寸和更複雜的封裝要求,這轉化為更高的平均售價(ASP)。更重要的是,AI 驅動的需求一直是台積電增長的主要動力。終端客戶願意不惜一切代價部署更多算力。這得到了主要 AI 實驗室算力承諾所帶來的多年可見度的支持。
這與目前已趨於飽和的手機和客戶端市場形成鮮明對比,後者在數量或內容增長方面的機會較少。這使得 AI 加速器客戶在獲取先進節點產能方面具有相對優勢。其他領域中無法獲得足夠 N3 產能的客戶,可能被迫延長現有產品週期或直接遷移到 N2 平台。
台積電的供應狀況
由於需求遠超供應,台積電正在擴大產能並將現有生產線推向極限,從其名義產能中榨取每一片可能的晶圓。因此,預計 2026 年下半年 N3 的有效利用率將超過 100%。該公司還將某些製程層轉移到其他晶圓廠,以盡可能釋放增量的 N3 產能。
為什麼台積電不能簡單地增加更多 N3 晶圓投片量?與記憶體供應商一樣,台積電受到可用無塵室空間的限制。在安裝設備和上線新產能之前,必須先建造額外的可用晶圓廠區域。在未來兩年內,台積電將無法增加足夠的產能來完全滿足需求。因此,為了讓某些公司在此期間獲得更多晶圓配額,其他公司必須放棄其現有的寶貴配額,而這正是有可能發生的。

![]()
智慧型手機作為前端釋放閥?
智慧型手機是今年 N3 晶圓需求的第二大驅動因素。如果說有哪個領域最可能出現需求疲軟,從而為 XPU 晶圓騰出產能,那就是這個領域。目前,蘋果以及聯發科、高通等其他智慧型手機客戶集體下達的供應鏈訂單,是基於今年智慧型手機出貨量低個位數增長的假設。
然而,記憶體價格上漲正傳導至手機物料清單(BOM)成本,並最終傳導至消費者的平均售價。這可能會抑制消費需求。我們已經看到跡象表明,智慧型手機需求將被下修至同比兩位數的降幅。隨著智慧型手機需求減弱,相關的晶圓需求將被削減,從而為 XPU 邏輯釋放額外產能。
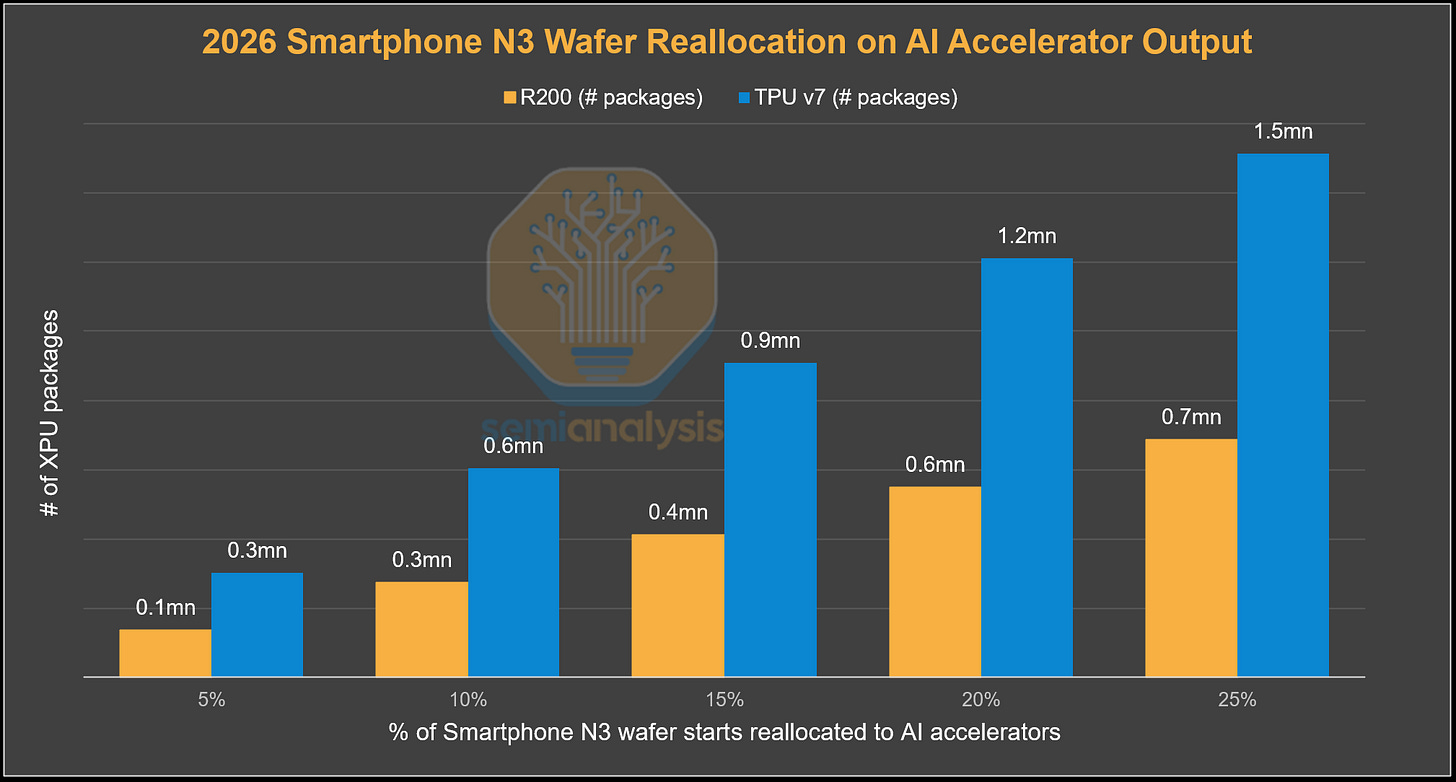
就這對出貨量的意義而言,如果在 2026 年將智慧型手機 N3 總投片量的 5%(43.7 萬片晶圓中的 5%)重新分配給 AI 加速器,將能額外生產約 10 萬顆 Rubin GPU 或約 30 萬顆 TPU v7。在更極端的情況下,如果將 2026 年智慧型手機 N3 總投片量的 25% 重新分配給 AI 加速器,台積電可以額外製造約 70 萬顆 Rubin GPU 或約 150 萬顆 TPU v7。然而,邏輯晶片只是 AI 加速器晶片方程式的一部分,還需要記憶體供應和先進封裝。

記憶體狂熱:四十年一遇的短缺如何推動記憶體繁榮
記憶體:下一個最大的限制
全球記憶體短缺在短期內不太可能緩解。記憶體已成為下一個主要戰場,晶片供應商和超大規模業者正競相鎖定用於加速器生產的 DRAM 供應。雖然 DRAM 總晶圓產能持續增長,但大部分增量產能正被 HBM 吸收,有效地擠佔了商品化 DRAM。
以每位元晶圓消耗量計算,HBM 消耗的晶圓產能大約是商品化 DRAM 的三倍,隨著產業在今年轉向 HBM4,明年轉向 HBM4E,這一差距可能會擴大到近四倍。因此,HBM 的增量增長將不成比例地將 DRAM 晶圓產能從商品化 DRAM 中轉移出去,加劇了結構性的記憶體供應緊張。


每個加速器中 HBM 含量的快速增加進一步放大了這種壓力。HBM 位元出貨量正急劇轉折向上,這主要是由每個設備的記憶體容量增加驅動,而非僅靠數量增長。對於 NVIDIA,從 Blackwell 到 Blackwell Ultra 再到 Rubin,HBM 容量增加了 50%,而 Rubin Ultra 則進一步推動了約 4 倍的增長。超大規模業者的 ASIC 也出現了類似的跨越,TPU v8AX 和 Trainium3 也從上一代的 8 層堆疊(8-Hi)遷移到 12 層堆疊(12-Hi),而 AMD 的記憶體容量從 MI350 到 MI400 增加了 50%。

另一個緊縮動態是向更高 HBM 引腳速度(pin speeds)的推進。NVIDIA 等客戶的目標是 HBM4 達到約 11 Gb/s 的引腳速度,這一要求對於記憶體供應商來說,要在可接受的良率下實現仍然很困難。雖然 SK 海力士和三星在滿足這些規格方面取得了較好進展,但美光在 HBM4 方面進度落後,我們早在 1 月份的 Rubin 文章以及加速器與 HBM 模型中就討論過這一動態。隨著客戶要求更高的引腳速度而供應商難以大規模交付,性能要求的升級進一步限制了有效的 HBM 供應。

除了 HBM,伺服器 DRAM 需求也在增強。AI 伺服器系統記憶體在 NVIDIA 的下一代平台中將大幅增加,VR NVL72 機架的 DDR 含量將提高 3 倍,每個 Vera CPU 配備 1,536 GB,而 Grace 則為 512 GB。我們還預計通用 DRAM 位元需求將在 2026 年向上轉折,因為老化的雲端和企業伺服器裝機量進入了為期多年的更換週期。同時,AI 工作負載,特別是數據分段(data staging)、編排和強化學習,正在驅動 CPU 需求,逐漸提高 CPU 與 GPU 的比例。
在整個 DRAM 市場中,AI 和通用伺服器部署的加速以及每個系統 DRAM 含量的增加,預計將推動伺服器 DRAM 需求隨時間增長。隨著記憶體價格上漲,這種需求應能抵消未來兩年智慧型手機、PC 和消費電子產品的疲軟。

如果邏輯產能被釋放給加速器,客戶將很快需要轉向從記憶體供應商那裡獲取更多 HBM。隨著傳統 DDR DRAM 價格飆升,DDR 的利潤率已大幅上升,接近甚至超過了 HBM 供應合約的水平。過去,HBM 提供的優越利潤率給了記憶體供應商擴張 HBM 晶圓產能的明確理由。然而,隨著利潤動態的逆轉(至少在 2026 年是如此),情況已不再如此。
為了激勵更多 HBM 晶圓投片而非商品化晶圓,客戶可能需要支付高於目前合約水平的價格,以確保增量的 HBM 供應。這種動態在 2027 年下一輪 HBM 價格談判達成時可能會變得更加明顯。如果記憶體供應商妥協並將產能轉向 HBM,傳統 DDR DRAM 的可用位元供應將進一步收緊。
另一個關鍵影響是位元從消費應用重新分配到伺服器和 HBM,這是我們自 2025 年下半年以來一直強調的動態。在我們最新的記憶體模型分析中,我們強調了消費端衝擊對潛在位元重新分配的影響。在消費端出貨量削減 50% 的極端情況下,將釋放約 553.9 億 Gb,相當於 2026 年 DRAM 總需求的 14%。在削減 25% 的情況下,將釋放約 276.9 億 Gb,代表約 7% 的 DRAM 總需求,以及今年 HBM 需求的近 80%。

我們的基準預測仍是消費端出貨量出現較溫和的 10-15% 下降。在出貨量削減 10% 的情況下,將釋放約 110.76 億 Gb,僅佔 DRAM 總需求的約 3%。在我們看來,這種水平的增量供應不足以實質性地改變我們預計今年會看到的整體供需動態。
關鍵問題在於記憶體供應商對消費端疲軟的準備程度,以及他們在多大程度上已經做出了調整。我們相信記憶體製造商對消費端終端市場的疲軟有充分的了解。例如,三星管理層已多次強調消費端疲軟,我們相信其產能分配計劃已經納入了出貨量下降 10-15% 的情境。我們預計其他主要記憶體供應商也會有類似的定位。
CoWoS – 緊張但正在緩解
前端產能現在是主要的瓶頸,CoWoS 的限制正在緩解。雖然 CoWoS 產能有限,但台積電的產能規劃是考慮到 N3 限制的。如果沒有前端晶圓供應來支持,台積電過度投資 CoWoS 產能就沒有意義。2.5D 封裝還有其他選擇。CoWoS 可以且之前已經外包給日月光/矽品和艾克爾(Amkor)等 OSAT 業者。例如,當出口許可證獲批的消息傳出時,NVIDIA 就找艾克爾封裝銷往中國的 H200。英特爾旗艦級的 EMIB 2.5D 先進封裝解決方案也是另一個日益受到關注的選擇,Trainium 和 TPU 都在不同程度上採用了它。
在付費牆後,我們將討論另外兩個主要限制:資料中心和電力。這些限制隨著時間的推移而發生了變化。