
GTC 2026:推理王國的擴張
Nvidia 在 GTC 2026 發表了多項突破性系統,重點介紹將 Groq 的 LPU 技術整合至其推理架構中,透過解構式設計優化低延遲的代幣生成表現。
Nvidia – 推論王國的擴張
Groq LP30、LPX 機架、Attention FFN 解構、Oberon 與 Kyber 更新、Nvidia 的 CPO 路線圖、Vera ETL256、CMX 與 STX

在 GTC 2026 上,Nvidia 帶來了一場充滿突破性公告的盛會。Nvidia 的創新步伐沒有絲毫放緩的跡象,今年推出了三款全新的系統:Groq LPX、Vera ETL256 以及 STX。同時宣佈的還有 Nvidia Kyber 機架架構系統的更新,以及 CPO(共同封裝光學元件)在擴展網路(scale-up networking)中的首次亮相,並揭曉了 Rubin Ultra NVL576 和 Feynman NVL1152 多機架系統。關於 Feynman 架構的早期線索也是關鍵話題。黃仁勳在主題演講中特別點名 InferenceX 成為了一大亮點。
這是我們的 GTC 2026 回顧,我們將解答許多 Nvidia 尚未說明的關鍵問題。具體而言,我們將深入探討 LPX 機架和 LP30 晶片,並解釋注意力與前饋網路解構(AFD)的工作原理;詳細介紹 NVL144、NVL576 和 NVL1152 背後的各種機架架構,並釐清將投入多少光學元件,以及高密度 Vera ETL256 背後的設計邏輯。下一代 Kyber 機架也有一些重大更新和隱藏細節。
Groq
首先是 Groq LPU。近期 AI 基礎設施領域最重要的事件之一是 Nvidia 對 Groq 的「收購」。嚴格來說,Nvidia 向 Groq 支付了 200 億美元以獲得其 IP 授權並聘用大部分團隊。這在功能上幾乎等同於收購,雖然其結構在法律上技術性地避開了被視為收購的定義,從而簡化或消除了監管審批的必要性。考慮到 Nvidia 的市場份額,如果這筆交易被結構化為全面收購並接受反壟斷審查,很可能無法通過。另一個好處是避免了漫長的交易交割過程。Nvidia 立即獲得了 Groq 的 IP 和人才。這就是為什麼在交易宣佈不到四個月後,Nvidia 已經擁有了正被整合進 Vera Rubin 推論堆疊的系統概念。
現在讓我們複習一下 LPU 架構,看看 Groq 的 LPU 如何補充 Nvidia 的 GPU。更多細節請參閱我們原始的 Groq 文章。該文章的前提保持不變:獨立的 Groq LPU 系統在大規模生成 Token 時並不經濟,但它生成 Token 的速度極快,這可以獲得巨大的市場溢價。這就是 LPU 如何融入解構式解碼(disaggregated decode)系統的前提。
LPU 晶片
Groq 第一個也是唯一公開宣佈的 LPU 架構在其 2020 年的 ISCA 論文中有詳細描述。與連接許多通用核心的典型硬體架構不同,Groq 將架構重新組織為連接到其他不同用途組別的單一用途單元組,並將這些組稱為「切片」(slices)。功能單元之間是串流暫存器(streaming registers)和用於功能單元相互傳遞數據的快取 SRAM(scratchpad SRAM)。Groq 選擇了單層快取 SRAM 而非多層記憶體階層,以使硬體執行具有確定性(deterministic)。
具體而言,LPU 架構具有用於向量運算的 VXM 切片、用於加載/儲存數據的 MEM 切片、用於張量形狀操作的 SXM 切片,以及用於執行矩陣乘法的 MXM 切片。在空間上,切片水平佈局,允許數據水平串流。在切片內部,指令在單元之間垂直泵送。從概念上講,LPU 類似於一個垂直泵送指令、水平泵送數據的脈動陣列(systolic array)。
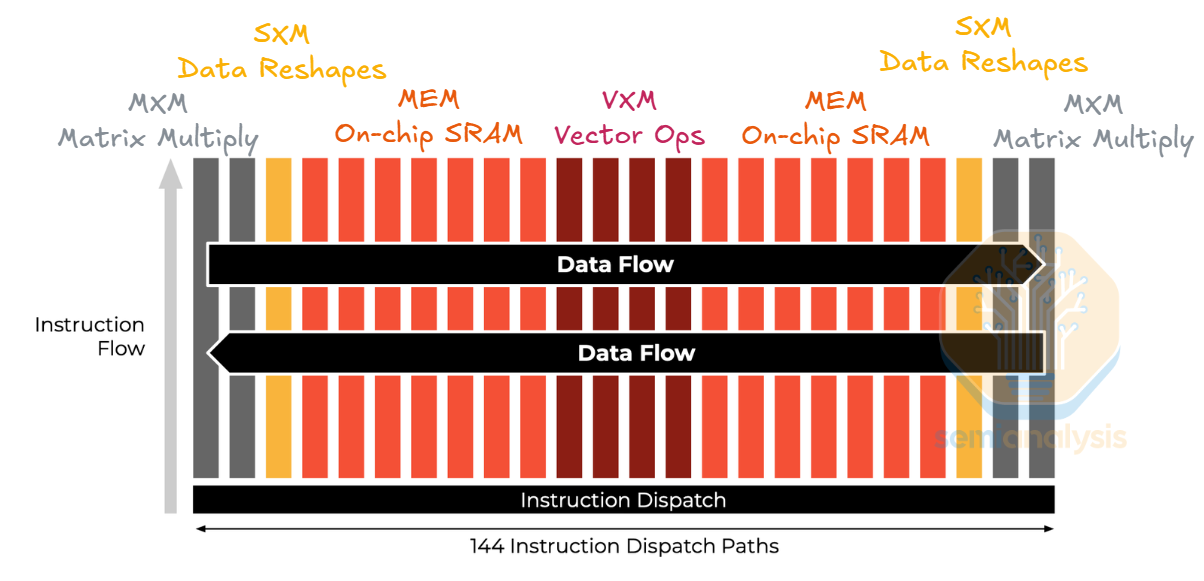
數據流和指令流的設計需要細粒度的流水線處理(pipelining)才能實現高效能。由於 LPU 架構使計算具有確定性,編譯器可以積極地調度並重疊指令以隱藏延遲。LPU 使用高頻寬 SRAM 和積極的流水線處理是實現其低延遲的兩個主要因素。
第一代 LPU 是基於舊有的 Global Foundries 14 奈米製程設計,由 Marvell 負責晶片的物理設計。與 2020 年流片時的同行相比,這是一個成熟得多的節點,當時主流的 AI 晶片平台大多位於台積電的 N7 平台。對於專注於驗證 Groq 架構並將其以推論為中心的設計推向市場的早期產品來說,這是有道理的。14 奈米節點成熟、相對容易掌握,且適用於初始晶片,因為此時架構差異化比追求領先製程更重要。
其賣點之一是,與重度依賴亞洲半導體供應鏈(邏輯和封裝在台灣,HBM 來自韓國)的競爭對手相比,該晶片可以完全在美國製造和封裝。
從那時起,Groq 的路線圖因執行問題而停滯,始終沒有出貨 LPU 2。這使得 Groq LPU 在競爭對手的路線圖面前顯得更加過時。曾經相對於 7 奈米時代同行雖然有意義但尚可控的節點劣勢,現在已擴大為更劇烈的差距,因為所有領先的加速器平台都將在 2026 年轉向 3 奈米級製程。
後續的 Groq LPU 2 是為三星晶圓代工(Samsung Foundry)的 SF4X 節點設計的,特別是在三星的奧斯汀晶圓廠,這讓他們能繼續宣傳 Groq 是在美國本土製造的。三星還將提供後端設計支援。選擇三星是由於優惠的條款/投資,因為三星晶圓代工正努力為其先進節點尋找客戶,並錯失了 AI 邏輯客戶。不出所料,三星是 Groq 隨後在 2024 年 8 月的 D 輪融資,以及最近在 2025 年 9 月 Nvidia 「收購」之前的關鍵投資者。
然而,Groq LPU 2 由於設計問題從未產品化。晶片上的 C2C SerDes 無法達到宣傳的 112G 速度,導致設計故障,正如我們很久以前在加速器模型中詳述的那樣。第三代 Groq LPU 才是 Nvidia 將要產品化的型號。
SRAM 與記憶體階層
我們曾寫過 SRAM 在記憶體階層中的角色,簡單回顧:SRAM 非常快(低延遲和高頻寬),但這是以密度和成本為代價的。因此,像 Groq LPU 這樣的 SRAM 機器可以實現極快的首字生成時間(time to first token)和每用戶每秒 Token 數,但代價是總吞吐量較低,因為其有限的 SRAM 容量很快就會被權重填滿,剩下給隨用戶批次增加而增長的 KVcache 空間很少。正如我們所展示的,GPU 在吞吐量和成本方面勝出。這就是為什麼 Nvidia 決定結合這些架構以兼得兩者之長:在像 LPU 這樣低延遲、高 SRAM 的晶片上加速對延遲更敏感且記憶體負擔較小的解碼部分,而將消耗記憶體的注意力機制(Attention)放在擁有大量高速(雖然不如 SRAM 快)記憶體容量的 GPU 上執行。

這帶領我們來到 Groq 3 LPU 或 LP30(跳過了 LPU 2)。這款晶片沒有 Nvidia 的設計參與。影響 v2 的 SerDes 問題似乎已修復。在付費內容中,我們將揭露 SerDes IP 供應商,這可能會令人驚訝。Nvidia 還宣佈了 LP35,這是 LP30 的小幅更新,將保留在 SF4 製程並需要重新流片。它將整合 NVFP4 數字格式,但考慮到 Nvidia 優先考慮上市時間,我們預計不會有其他劇烈的設計變動。
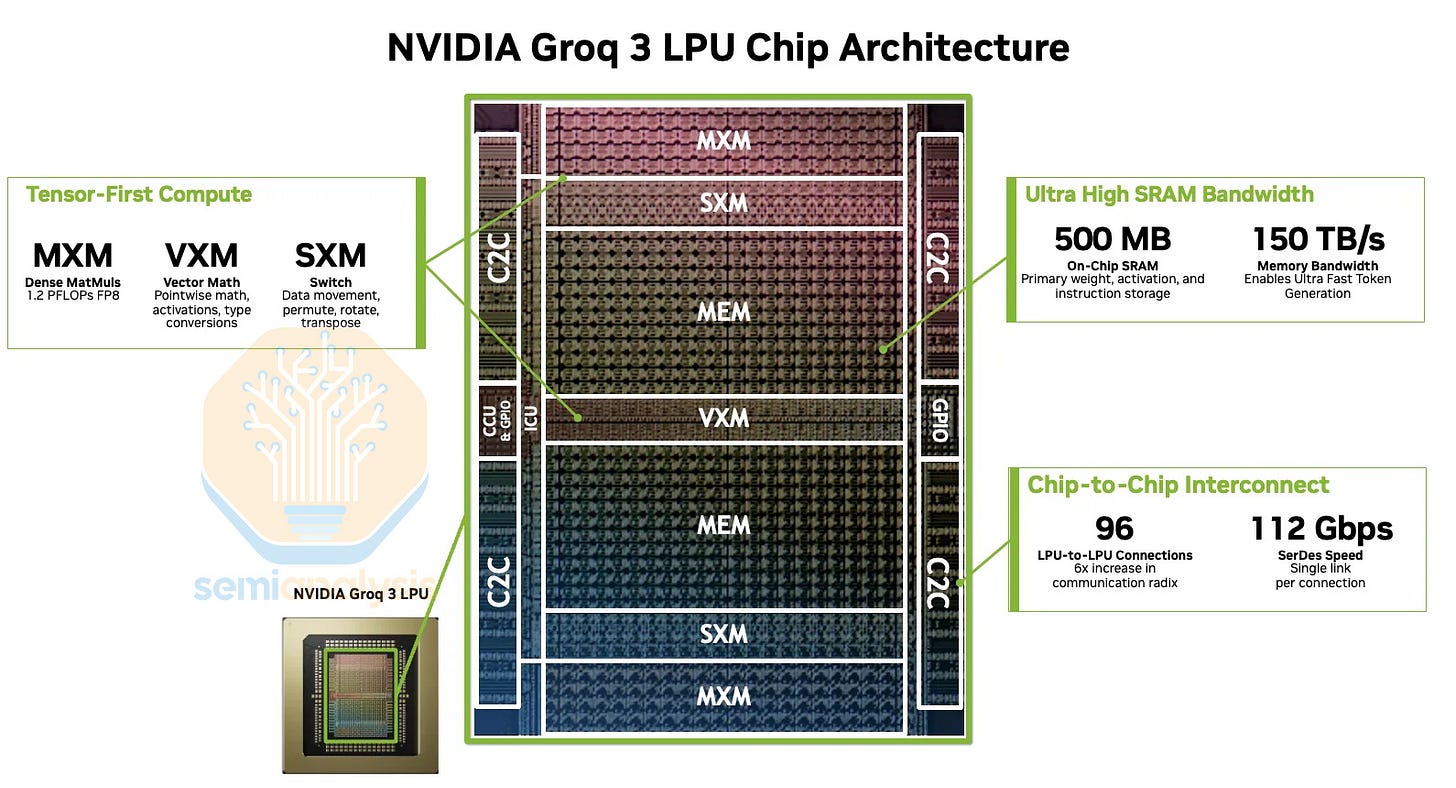
LPU 3 接近光罩極限(reticle size)的晶片佈局與 LPU 1 非常相似。500MB 的片上 SRAM 佔據了大量面積,而專用於 MatMul 核心的面積非常小,提供 1.2 PFLOPs 的 FP8 算力——這僅是 Nvidia GPU 算力的一小部分。相比之下,LPU 1 擁有 230MB 的 SRAM 和 750 TFLOPs 的 INT8 算力,效能提升主要由從 GF16 到 SF4 的節點遷移驅動。作為單一單體晶片,不需要先進封裝。
依賴 SF4 的好處之一是它不像台積電的 N3 那樣受限,後者限制了加速器的產量,也是業界維持算力受限的關鍵原因。此外,這還避開了同樣受限的 HBM。這使得 Nvidia 能夠在不犧牲或消耗其寶貴的台積電配額或 HBM 配額的情況下,提高 LPU 的產量,這代表了其他人無法獲得的純粹增量收入和產能。
自從 Nvidia 接手後,下一代 LP40 將在台積電 N3P 上製造並使用 CoWoS-R,Nvidia 將貢獻更多自己的 IP,例如支援 NVLink 協議而非 Groq 的 C2C。這將是第一款與 Feynman 平台深度協同設計的 LPU。Groq 原本對 LPU 第 4 代的計劃也是與台積電及後端設計夥伴世芯(Alchip)合作。現在世芯的參與已變得多餘,因為 Nvidia 有能力自行執行後端設計。計劃中的技術創新之一是混合鍵合(hybrid bonded)DRAM,以擴展片上記憶體,與 SRAM 相比延遲和頻寬僅略微下降,但效能遠高於普通 DRAM。SK 海力士被選為用於 3D 堆疊的 DRAM 供應商。所有這些細節在很久以前的加速器模型中已有詳述。
GPU 與 LPU 整合:注意力 FFN 解構 (AFD)
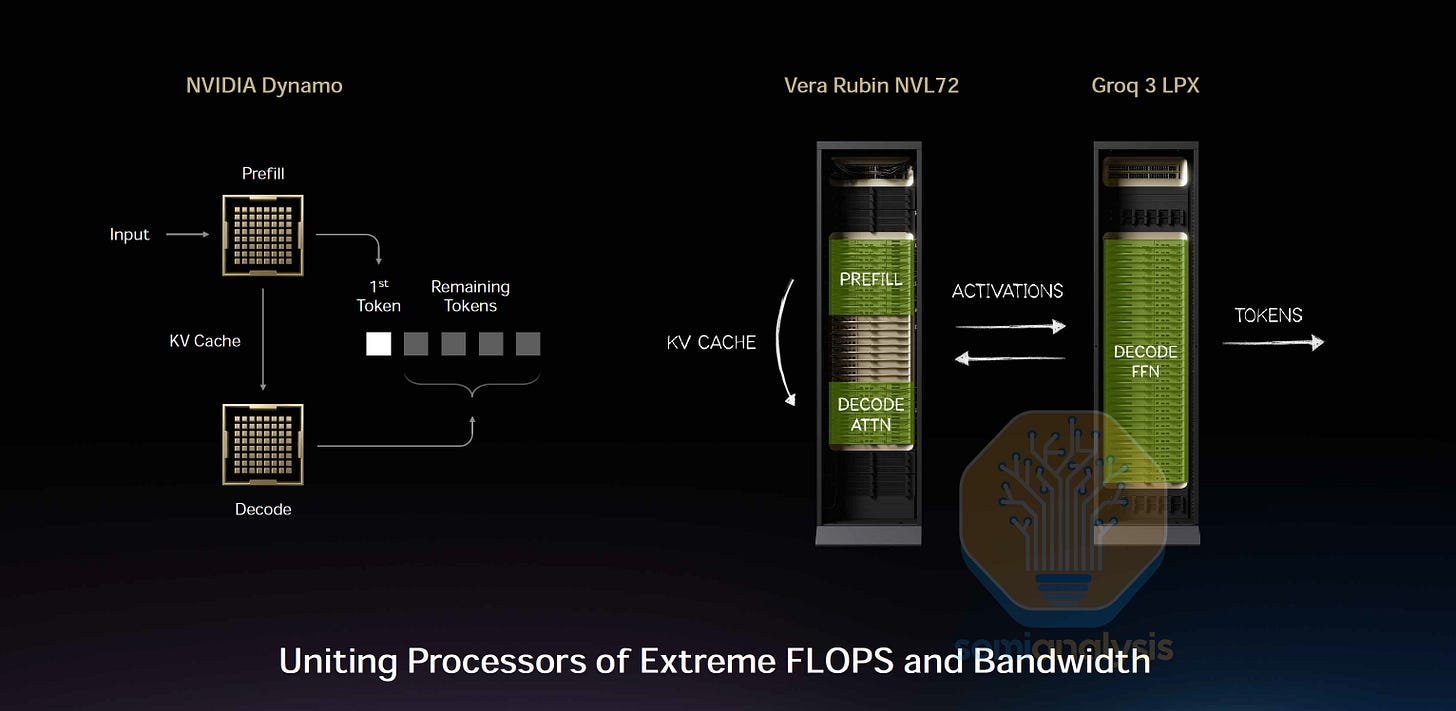
了解了 LPU 的優勢後,我們就能理解它們如何融入推論設置。NVIDIA 引入 LPU 是為了提升高互動場景的效能。在這些場景中,LPU 可以利用其低延遲特性來改善解碼階段(decode phase)的延遲。LPU 改善解碼延遲的一種方式是應用注意力 FFN 解構(AFD)技術,該技術在 MegaScale-Infer 和 Step-3 中被引入。
正如我們在 InferenceX 文章中所解釋的,LLM 推論包含兩個階段:預填充(prefill)和解碼(decode)。預填充處理完整的輸入上下文:它是計算密集型的,適合 GPU。另一方面,解碼預測新 Token,受記憶體頻寬限制。解碼對延遲敏感,因為模型是一個接一個地預測新 Token,而 LPU 的高 SRAM 頻寬和低延遲能力有助於加速這一迭代過程。
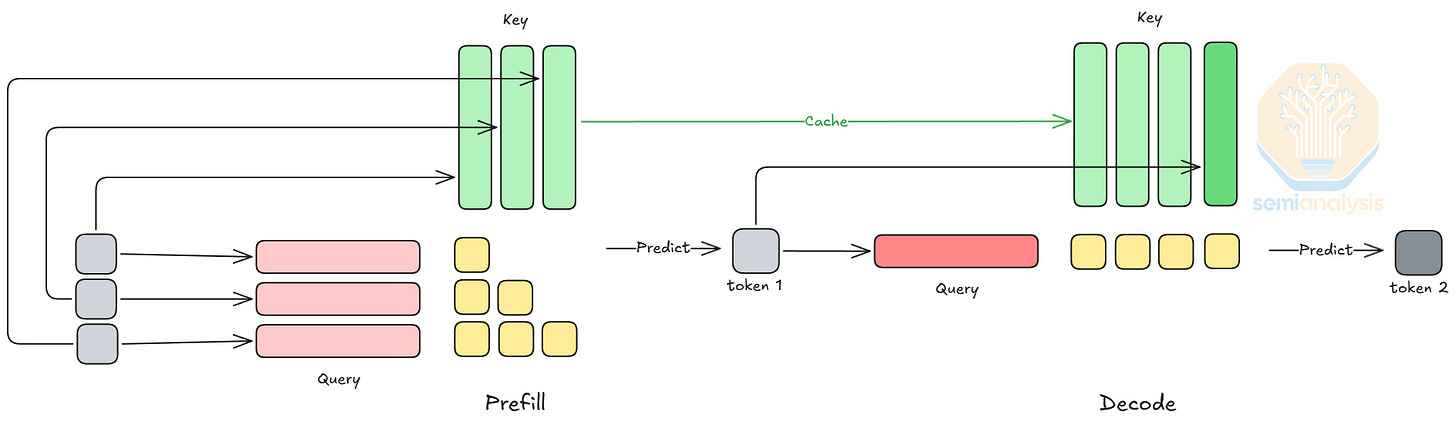
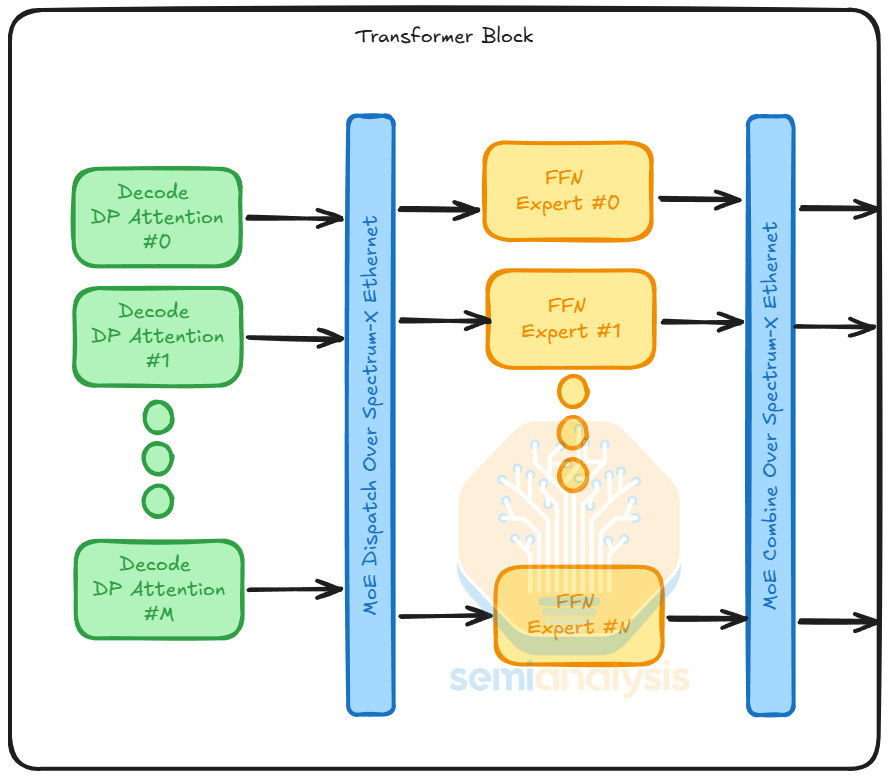
注意力(Attention)和 FFN 是模型中的運算子集。在模型的前向傳播中,注意力的輸出進入 Token 路由器,路由器將每個 Token 分配給 k 個專家,每個專家都是一個 FFN。注意力和 FFN 具有非常不同的效能特性。在解碼階段,由於受限於加載 KV cache,注意力的 GPU 利用率隨批次大小(batch size)增加幾乎沒有改善。相比之下,FFN 的 GPU 利用率隨批次大小增加的擴展性相對較好。
這是我們與某些硬體供應商和記憶體公司在推論模擬器上合作超過 6 個月的研究成果。

隨著最先進的混合專家(MoE)模型變得越來越稀疏,Token 可以從更大的專家池中選擇專家。結果是每個專家接收到的 Token 減少,導致利用率降低。這促使了注意力和 FFN 的解構。如果 GPU 僅執行注意力運算,其 HBM 容量可以完全分配給 KV cache,從而增加其可處理的總 Token 數,進而增加每個專家平均處理的 Token 數。
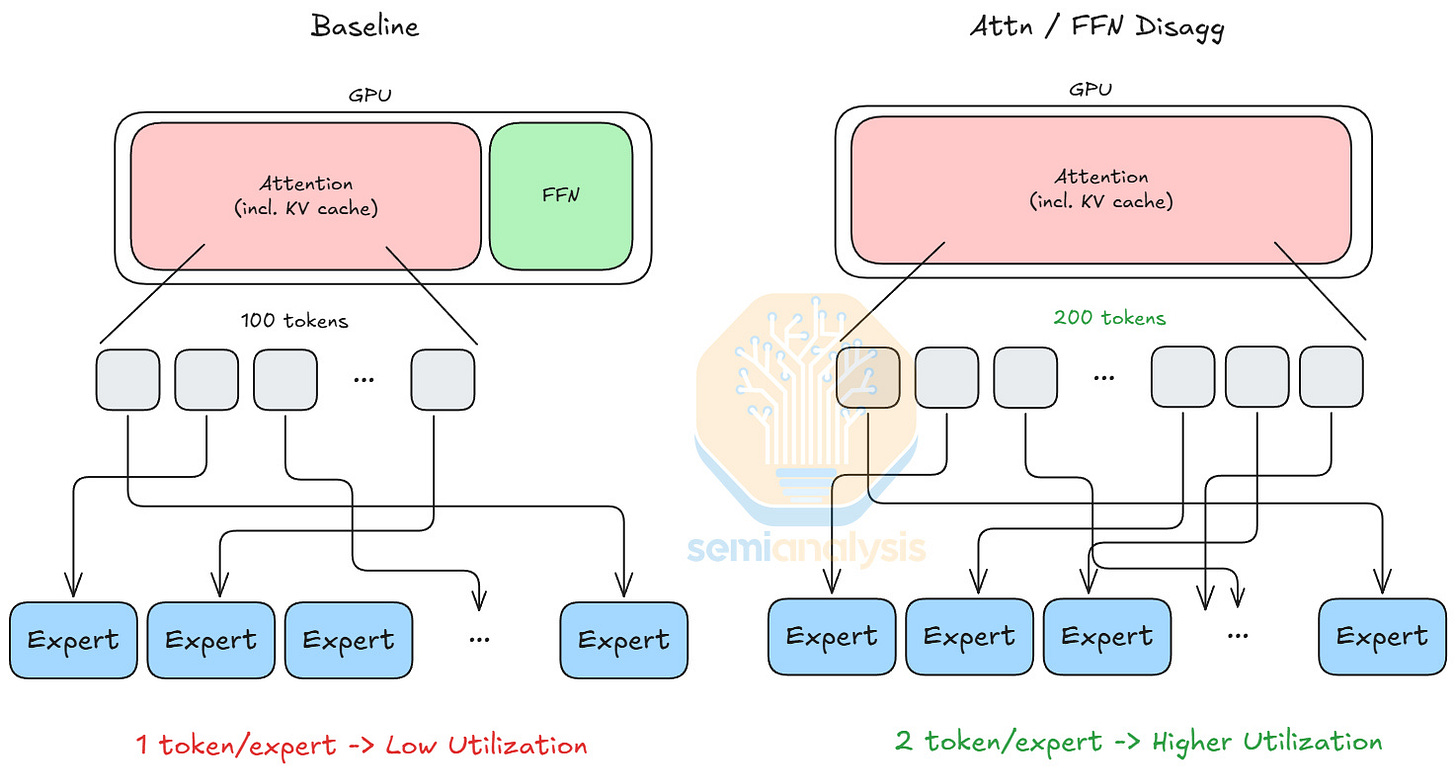
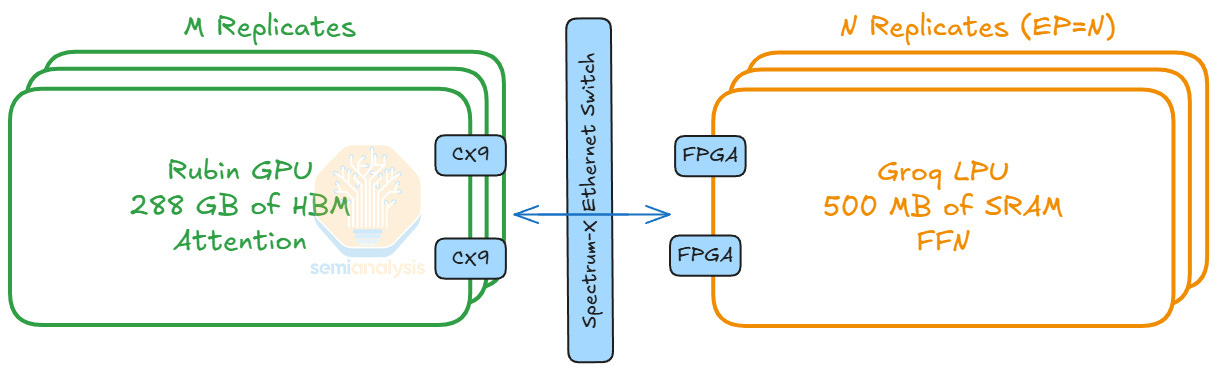
比較這兩種運算,我們看到注意力是有狀態的(stateful),因為它具有動態的 KV cache 加載模式;而 FFN 是無狀態的(stateless),因為計算僅取決於 Token 輸入。因此,我們將注意力和 FFN 的計算解構。我們將注意力計算映射到擅長處理動態工作負載的 GPU。對於 FFN,我們將其映射到 LPU,因為 LPU 架構本質上是確定性的,且受益於靜態計算工作負載。
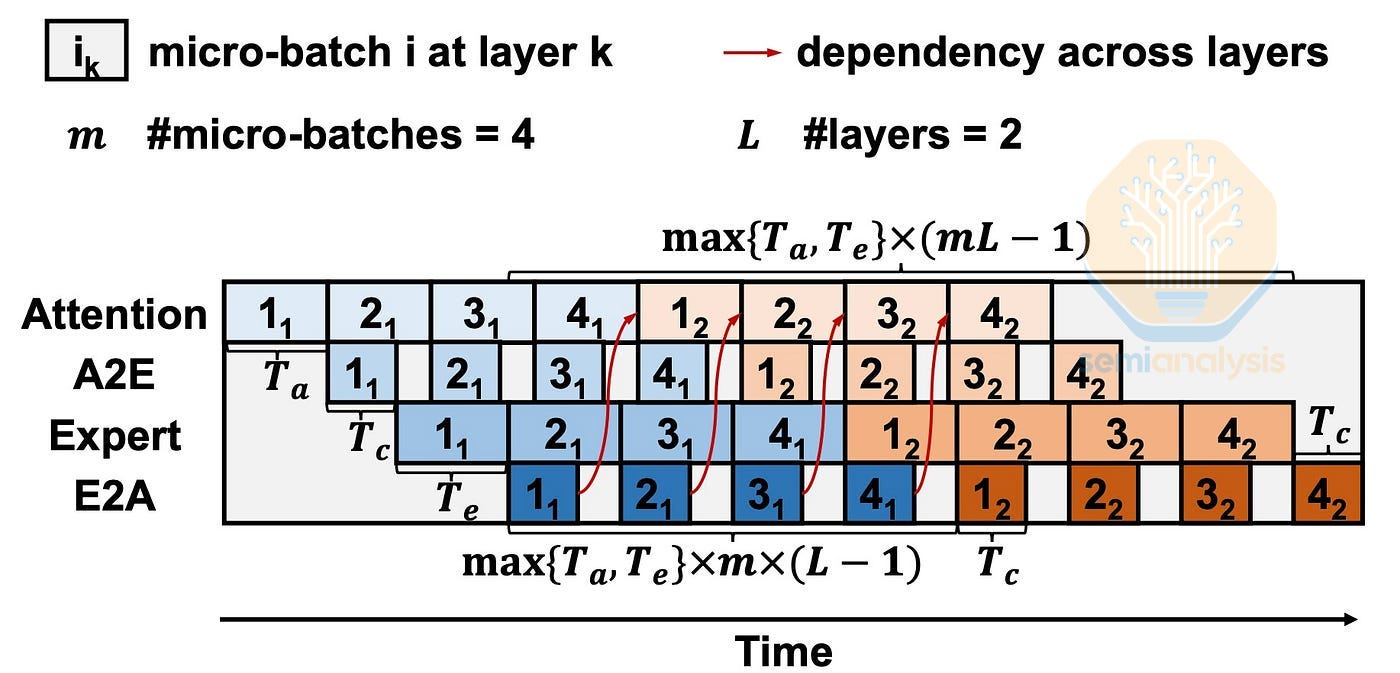
在 AFD 模式下,從 GPU 到 LPU 的 Token 路由可能成為瓶頸,尤其是在嚴格的延遲限制下。Token 路由流程涉及兩個操作:分發(dispatch)和合併(combine)。在分發步驟中,我們通過 All-to-All 集體通信將每個 Token 路由到其前 k 個專家。專家完成計算後,我們執行合併步驟,通過反向 All-to-All 集體通信將輸出發回源位置,繼續下一層的計算。
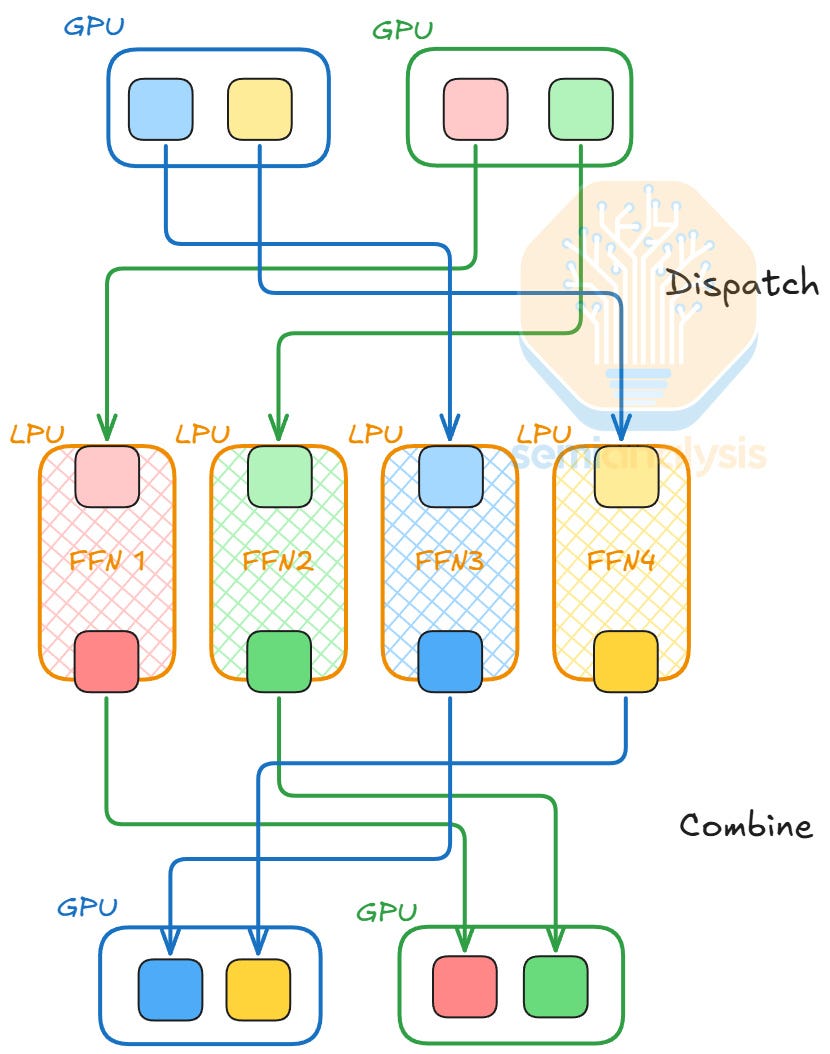
為了隱藏分發和合併的通信延遲,我們採用了乒乓流水線並行(ping pong pipeline parallelism)。除了像標準流水線並行那樣將批次拆分為微批次並進行計算流水線處理外,分發到 LPU 的 Token 會合併回源 GPU,因此它們在 GPU 和 LPU 之間來回「乒乓」。
![]()
投機性解碼 (Speculative Decoding)
LPU 改善解碼延遲的另一種方式是加速投機性解碼設置,我們將草稿模型(draft models)或多 Token 預測(MTP)層部署到 LPU 上。
對於上下文為 N 個 Token 的解碼步驟,在前向傳播期間添加 k 個額外 Token(對 k 個新 Token 進行熱預填充)在 k << N 時僅略微增加延遲。利用這一特性,投機性解碼使用小型草稿模型或 MTP 層來預測 k 個新 Token,由於小模型每步解碼延遲較低,因此可以節省時間。為了驗證草稿 Token,主模型僅需對 k 個新 Token 進行一次熱預填充,其延遲成本大約相當於單個解碼步驟。投機性解碼通常能將每步解碼的輸出 Token 提升 1.5 到 2 倍,具體取決於草稿模型/MTP 的準確度。憑藉其低延遲能力,LPU 可以進一步增加延遲節省並提高吞吐量。
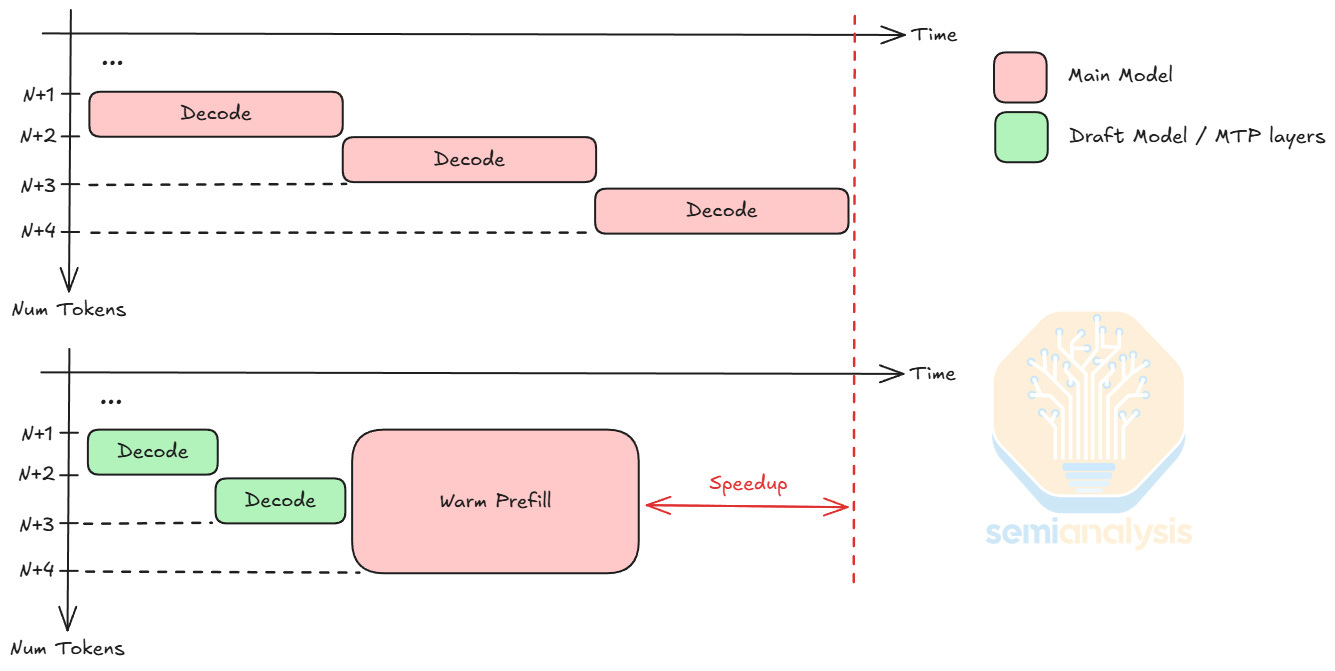
對於 LPU 而言,部署草稿模型或 MTP 層與應用 AFD 非常不同。FFN 是無狀態的,而草稿模型和 MTP 層需要動態 KV cache 加載。每個 FFN 約為數百 MB,而草稿模型和 MTP 層則佔用數十 GB。為了支援這種記憶體使用,LPU 可以通過 LPX 計算托盤上的網格擴展邏輯(Fabric Expansion Logic)FPGA 訪問高達 256 GB 的 DDR5。
LPX 機架系統
讓我們看看 LPX 機架系統,其中包含有趣的細節。Nvidia 展示了一個裝有 32 個 1U LPU 計算托盤和 2 個 Spectrum-X 交換機的 LPX 機架。Nvidia 在 GTC 展示的這個 32 托盤 1U 版本非常接近 Groq 被收購前的原始伺服器設計。我們認為這個伺服器配置並非將於第三季出貨的版本,Nvidia 正在實施變更。在這裡,我們將詳述我們所知的實際量產版本。這在加速器模型中已有詳述。

LPX 計算托盤
每個 LPX 計算托盤或節點擁有 16 個 LPU、2 個 Altera FPGA、1 個 Intel Granite Rapids 主機 CPU 和 1 個 BlueField-4 前端模組。與其他 Nvidia 系統一樣,超大規模雲端客戶可以且將會使用自己選擇的前端 NIC,而不是為 Nvidia 的 BlueField 付費。
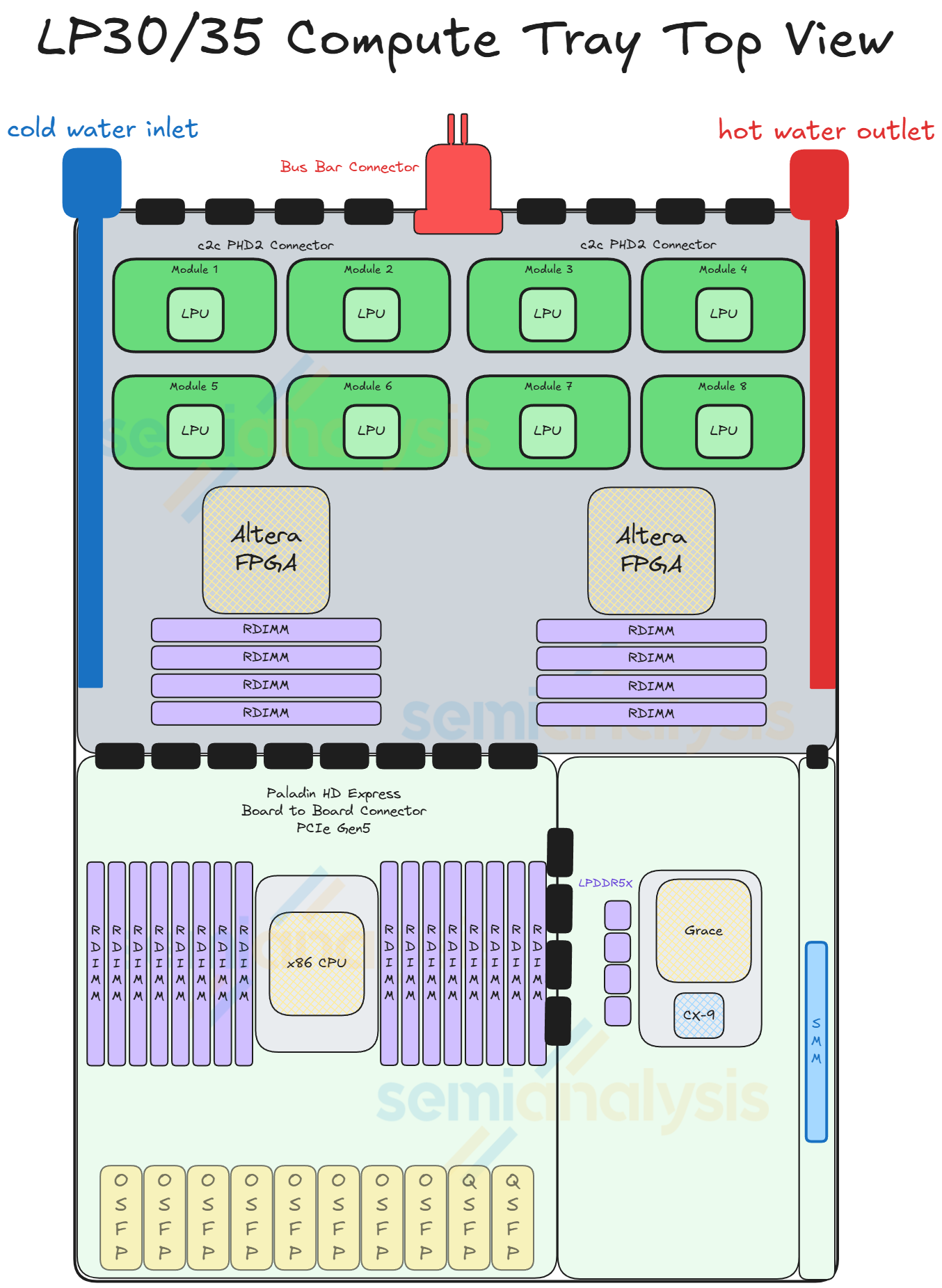
LPU 模組以「背靠背」(belly-to-belly)方式安裝在 PCB 上,這意味著 8 個 LP30 模組在 PCB 頂面,另外 8 個在底面。LPU 引出的所有連接都通過 PCB 走線,考慮到節點內連接的密集全對全網格,這需要極高規格的 PCB 來支援佈線。背靠背安裝是為了減少跨越「X」和「Y」維度的 PCB 走線長度。
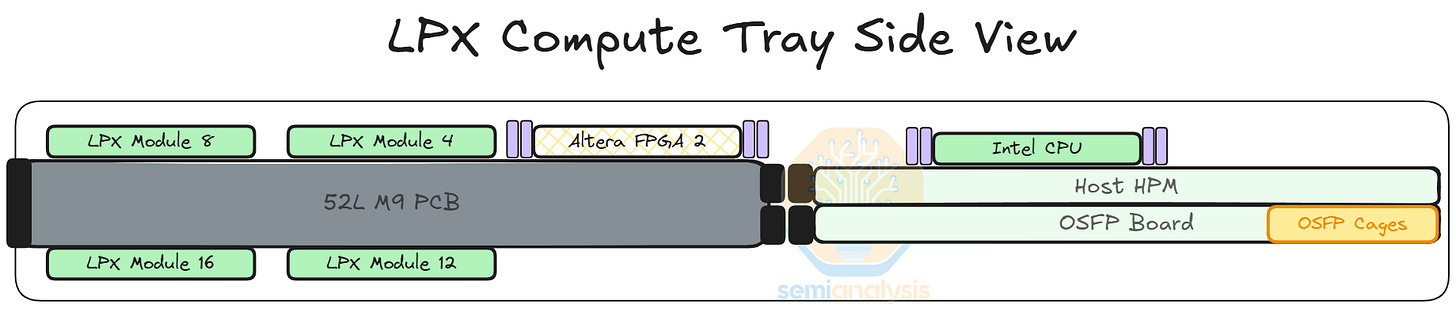
該系統有趣的一點是 FPGA 扮演的重要角色。Nvidia 將這些 FPGA 稱為「網格擴展邏輯」,具有多種用途。首先,它們充當 NIC,將 LPU 的 C2C 協議轉換為乙太網路,以連接到基於 Spectrum-X 的乙太網路擴展網格。解碼系統中的 LPU 就是通過這個擴展網格與 GPU 連接的。
其次,LPU 還通過 FPGA 到達主機 CPU,FPGA 將 C2C 轉換為 PCIe 連接到 CPU。
第三,FPGA 連接到背板以與節點內的其他 FPGA 通信,我們認為這是為了幫助管理所有 LPU 的控制流和時序。FPGA 還帶來了高達 256GB 的額外系統 DRAM。如果用戶希望整個解碼過程由 LPX 處理,這部分記憶體池可用於 KVcache。
前面板上有 8 個 OSFP 插槽用於跨機架 C2C,同時還有 2 個插槽(可能是 QSFP-DD)連接到 Spectrum 交換機,用於在解構式解碼系統中連接 LPU 和 GPU。我們在描述網路時會分享更多相關內容。
LPU 網路
LPU 網路可分為擴展(scale-up)「C2C」網路和通過 Spectrum-X 與 Nvidia GPU 互動的擴展(scale-out)網路。首先討論擴展網路,它可分為 3 部分:節點內、節點間/機架內、機架間。對於機架內的 C2C,Nvidia 宣佈每個機架總共有 640TB/s 的擴展頻寬,計算方式為:256 LPU x 90 通道 x 112Gbps/8 x 2 方向 = 645TB/s。請注意,Nvidia 使用的是 112G 的總線路速率,而非 100G 的有效數據速率。
托盤內拓撲
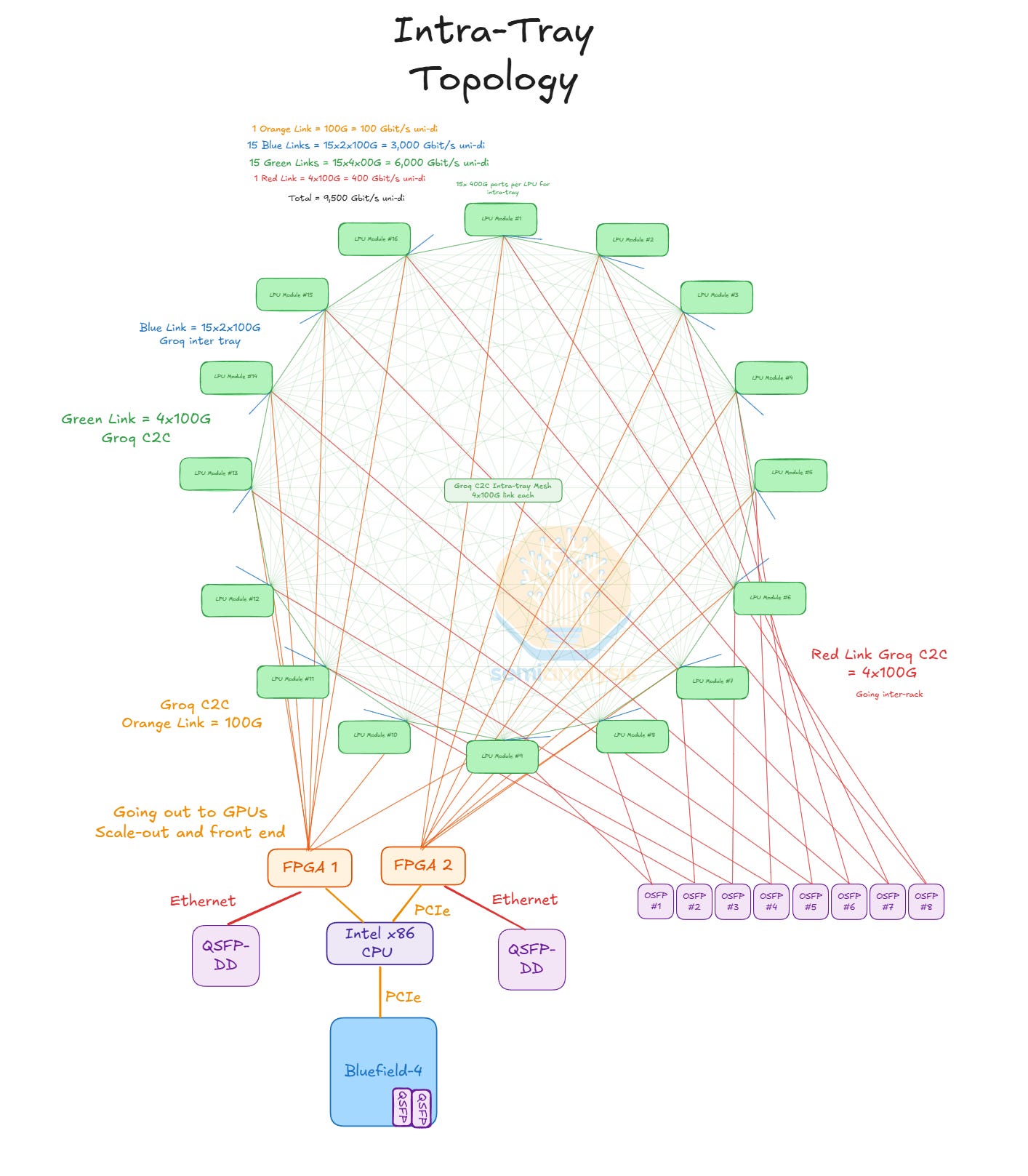
在每個托盤或節點內,所有 16 個 LPU 都以全對全網格相互連接。每個 LPU 模組以 4x100G 的 C2C 頻寬連接到節點內的其餘 15 個 LPU。請注意,此「C2C」與 NVLink 無關,而是 Groq 自己的擴展網格。這些連接全部通過 PCB 走線,這使得極高規格的 PCB 成為支援此佈線密度的必要條件。這就是為什麼使用背靠背佈局:它減少了所有 LPU 之間的「X」和「Y」距離,轉而讓佈線在「Z」維度進行。
LPU 還有 1x100G 連接到一個 FPGA,每個 FPGA 與 8 個 LPU 對接。2 個 FPGA 各有 8x PCIe Gen 5 連接到 CPU。LPU 需要通過 FPGA 與 CPU 對接,因為 LPU 沒有直接對接的 PCIe PHY。
節點間/機架內
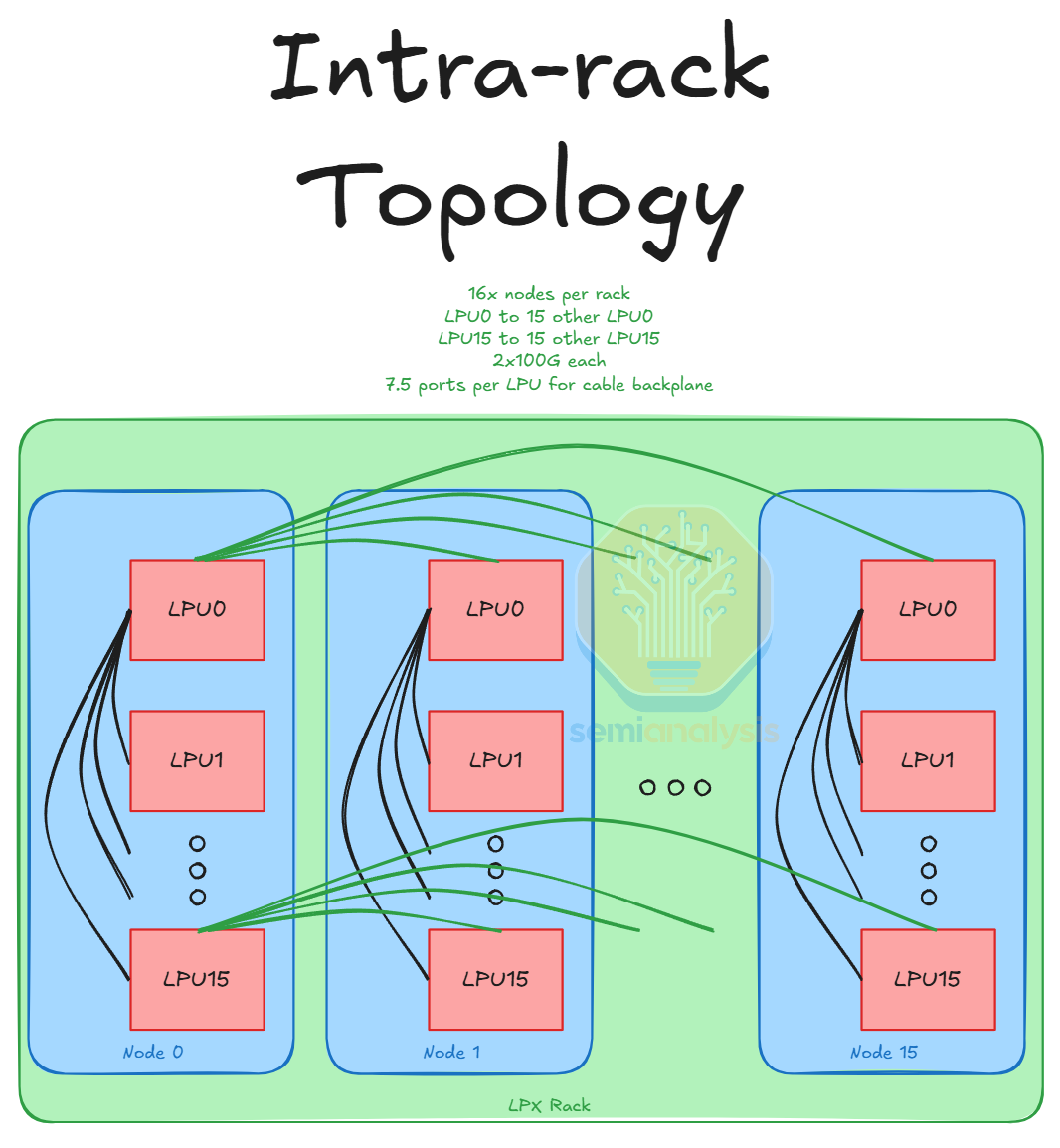
每個 LPU 連接到伺服器中其餘 15 個節點中的各一個 LPU。這些節點間鏈路均為 2x100G,因此每個 LPU 引出 15x2x100G 的節點間鏈路。這些節點間鏈路通過銅纜背板實現。此外,每個 FPGA 還以每條鏈路 25G 或 50G 的速度連接到每個其他節點中的 FPGA,共 15x25G/50G。這也通過背板完成。這意味著每個節點有 16 x 15 x 2 條用於節點間 C2C 的通道,以及 2 x 15 條用於節點間 FPGA 的通道,總共 510 條通道或 1020 個差分對(用於 Rx 和 Tx)。因此,背板共有 16 x 1020/2 = 8,160 個差分對——除以 2 是因為每個設備的 Tx 通道對應另一個設備的 Rx 通道。
機架間
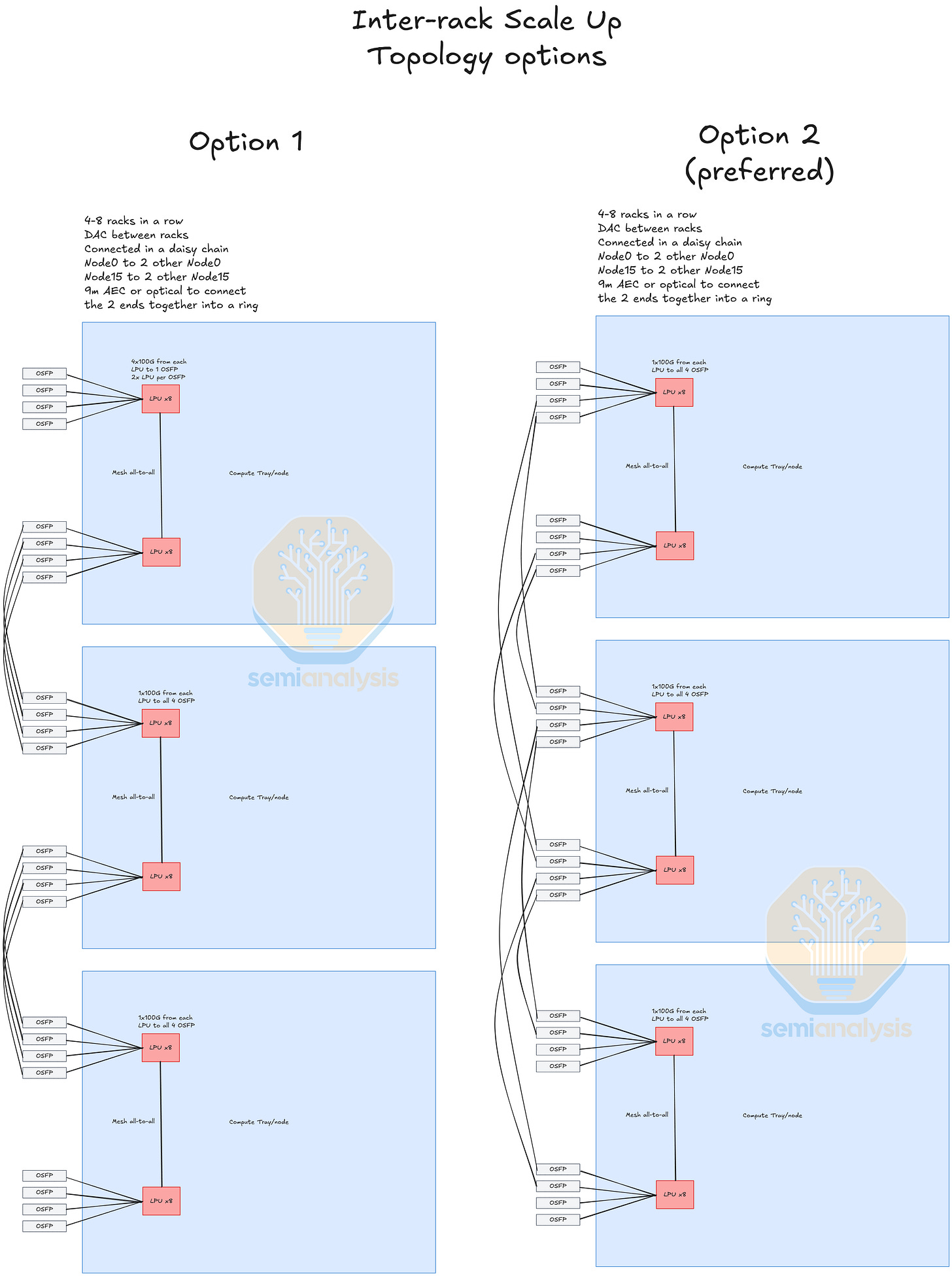
最後是機架間 C2C。每個 LPU 有 4x100G 通道通往 OSFP 插槽,以連接跨 4 個機架的 LPU。這種機架間擴展有多種配置可選。一種方案是每個 LPU 的 4x100G 通向一個 OSFP 插槽,每個 OSFP 從 2 個 LPU 引出 800G 的 C2C。然而,為了獲得更大的扇出(fan out),首選配置似乎是將 LPU 的每條 100G 通道通向 4 個獨立插槽,每個插槽從 8 個 LPU 引出 800G 的 C2C。至於機架如何聯網,似乎採用了菊花鏈(daisy chain)配置,每個節點 0 連接到另外兩個節點 0。這一切都可以在 100G AEC(有源電纜)的傳輸範圍內實現,如有必要也可以使用光學元件。
Nvidia 的 CPO 路線圖
NVIDIA 在 GTC 2026 主題演講中揭曉了其 CPO 路線圖,黃仁勳隨後在次日舉行的財務分析師問答會議上進行了補充說明。儘管許多人曾寄望於 CPO 能用於 Rubin Ultra Kyber 的機架內擴展,但 Nvidia 的重點卻是利用 CPO 來實現更大規模的運算系統。

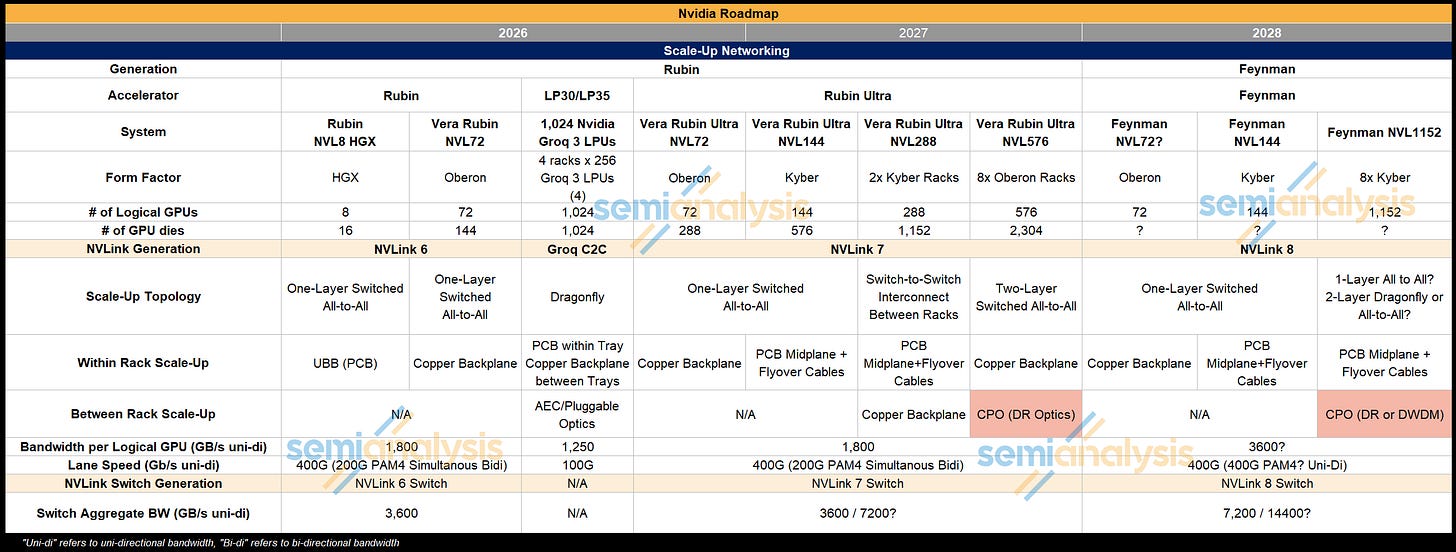
在 Rubin 世代,Nvidia 將提供 Oberon NVL72 形式的 Rubin GPU,採用全銅擴展網路。對於 Rubin Ultra,正如我們預期的,Oberon 和 Kyber 機架形式將僅提供銅纜擴展選項。Rubin Ultra 還將提供更大規模的系統,將 8 個 Oberon 機架(共 576 個 Rubin Ultra GPU)連接起來,形成所謂的 NVL576。CPO 擴展將用於構建這種更大規模的系統,在機架之間以兩層全對全網路連接,但機架內部的擴展仍將基於銅纜。
進入 Feynman 世代後,CPO 的使用將通過另一個大規模機架 NVL1152 進一步擴展,該系統由 8 個 Kyber 機架組合而成。雖然概述機架配置路線圖的 Nvidia 技術部落格指出:「NVIDIA Kyber 將使用類似的直接光學互連進行機架間擴展,擴展成大規模全對全 NVL1152 超級電腦」,但黃仁勳在財務分析師問答環節中確實表示 Feynman 的 NVL1152 將是「全 CPO」。關於機架內擴展是否仍使用銅纜,或者 CPO 是否會取代銅纜,目前仍存在分歧。
Nvidia 的策略一直是:能用銅的地方就用銅,必須用光的地方才用光。Feynman 世代 NVL1152 的架構也將遵循這一原則。很明顯,NVL1152 將採用 CPO 進行機架間連接,但從 GPU 到 NVLink 交換機目前仍是銅纜方案(POR)。Nvidia 無法實現電氣通道速度從雙向 224Gbit/s 再次翻倍至單向 448Gbit/s,這意味著頻寬並非驚人。
雖然 448G 高速 SerDes 在岸線(shoreline)、傳輸距離和功耗方面與使用晶片對晶片連接到光學引擎相比面臨巨大挑戰,但 Feynman 的製造挑戰、成本和可靠性使得連接到交換機必須使用銅纜。
話雖如此,NVL1152 型號距離上市還有數年時間——路線圖極有可能發生變化。目前,我們的基準預測是每個機架內使用銅纜,機架之間使用 CPO,但這隨時可能改變。
目前,我們對 Nvidia CPO 路線圖的最佳估計如下:
Rubin:
NVL72 – Oberon 全銅擴展
Rubin Ultra:
NVL72 – Oberon 全銅擴展
NVL144 – Kyber 機架全銅擴展
NVL288 – Kyber 機架全銅擴展,機架間以銅纜連接
NVL576 – 8 個 Oberon 機架,機架內銅纜擴展,機架間交換機採用 CPO,兩層全對全拓撲。這將是低產量的測試用途。
Feynman:
NVL72 – Oberon 機架 – 全銅
NVL144 – Kyber 機架 – 全銅
NVL1152 – 8 個 Kyber 機架 – 機架內銅纜,機架間交換機採用 CPO
Oberon 與 Kyber 更新、更大規模系統推出、更多網路更新
Nvidia 提供了一份期待已久的 Kyber 機架更新,這是繼 Oberon 在 GTC 2025 首次以原型亮相後的最新成員。作為原型,機架架構持續演進,我們注意到了一些變化。首先,每個計算刀鋒(compute blade)都變得更密集,包含 4 個 Rubin Ultra GPU 和 2 個 Vera CPU。總共有 2 個各含 18 個計算刀鋒的容器(canisters),機架總計 36 個計算刀鋒,共 144 個 GPU。最初的 Kyber 設計是每個刀鋒 2 個 GPU 和 2 個 Vera CPU,總共 4 個容器,每個容器 18 個刀鋒。
以下細節基於 Rubin Kyber 原型,但 Rubin Ultra 將會重新設計。

每個交換機刀鋒(switch blade)的高度也是 GTC 2025 原型的兩倍,每個刀鋒有 6 個 NVLink 7 交換機,每機架 12 個刀鋒,總計每個 Kyber 機架有 72 個 NVLink 7 交換機。GPU 通過 2 個 PCB 中間板(或每個容器 1 個中間板)以全對全方式連接到交換機刀鋒。

對於 Rubin Ultra NVL144 Kyber,正如我們多次告知客戶的,儘管其他分析師傳言 Kyber 將引入擴展 CPO,但實際上不會使用 CPO 進行擴展。然而,NVLink 的光學元件即將到來並將逐步引入。擴展 CPO 將首先用於 Rubin Ultra NVL 576 系統,以連接 8 個 Oberon 形式的機架,形成兩層全對全網路。不過,機架內部的擴展網路仍將使用銅纜背板。這仍處於低產量/測試階段。
回到 Kyber 機架,每個 Rubin Ultra 邏輯 GPU 提供 14.4Tbit/s 的單向擴展頻寬,使用每個 GPU 一個 80DP 連接器(使用 72 個 DP x 200Gbit/s 雙向通道 = 14.4Tbit/s)連接到中間板。將所有 144 個 GPU 連接成全對全網路將需要 72 個 NVLink 7.0 交換晶片,每個晶片提供 28.8Tbit/s 的單向總頻寬。
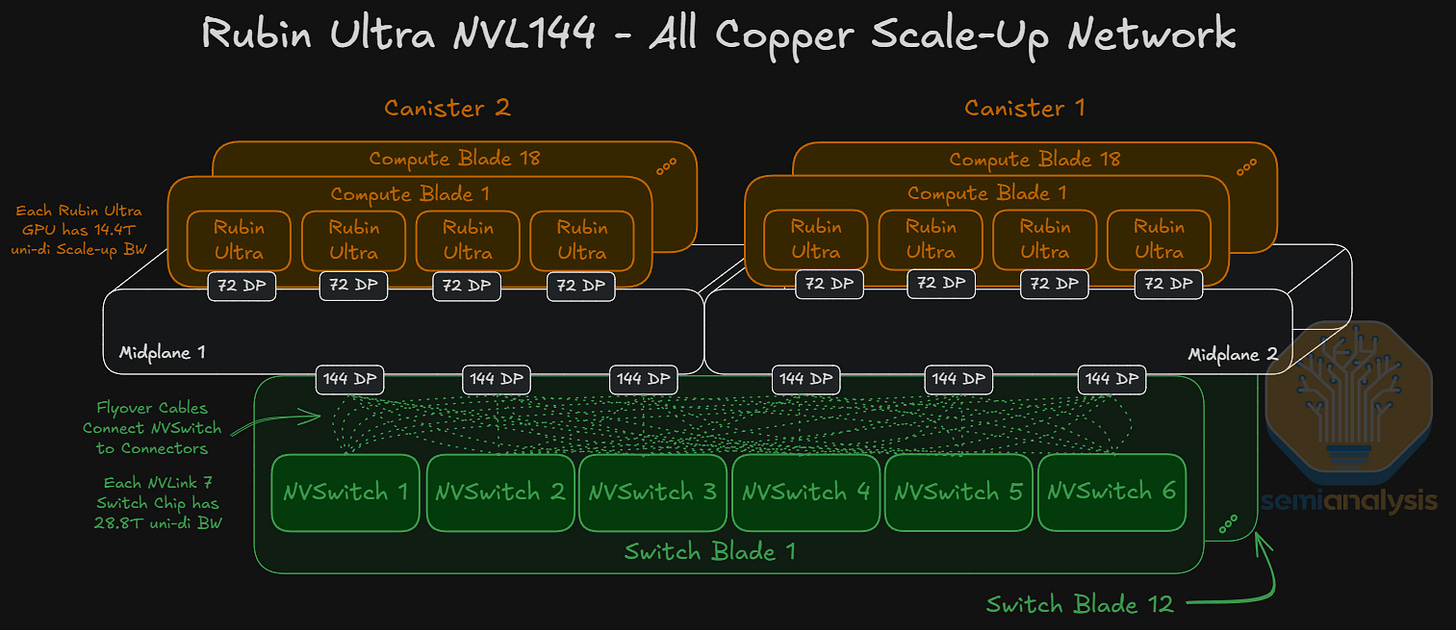
在下方的 Kyber 交換機刀鋒圖片中,我們可以看到有 2 個獨立的 PCB,各載有 3 個交換機。交換機刀鋒應有 6 個 152DP 連接器,每 3 個連接器服務一個中間板。圖片中是使用較低密度連接器的原型刀鋒,這就是為什麼有 12 個連接器,而非我們預計量產版本的 6 個。

每個 28.8T NVLink 交換機擁有 144 條 200G 通道(同步雙向),這意味著每個交換機有 24 條 200G 通道通往每個連接器。由於距離過長,無法使用 PCB 走線,因此使用銅質跨接電纜(flyover cables)將每個交換機連接到中間板。這也是為什麼交換機距離中間板較遠,以便為跨接電纜的佈線提供空間。
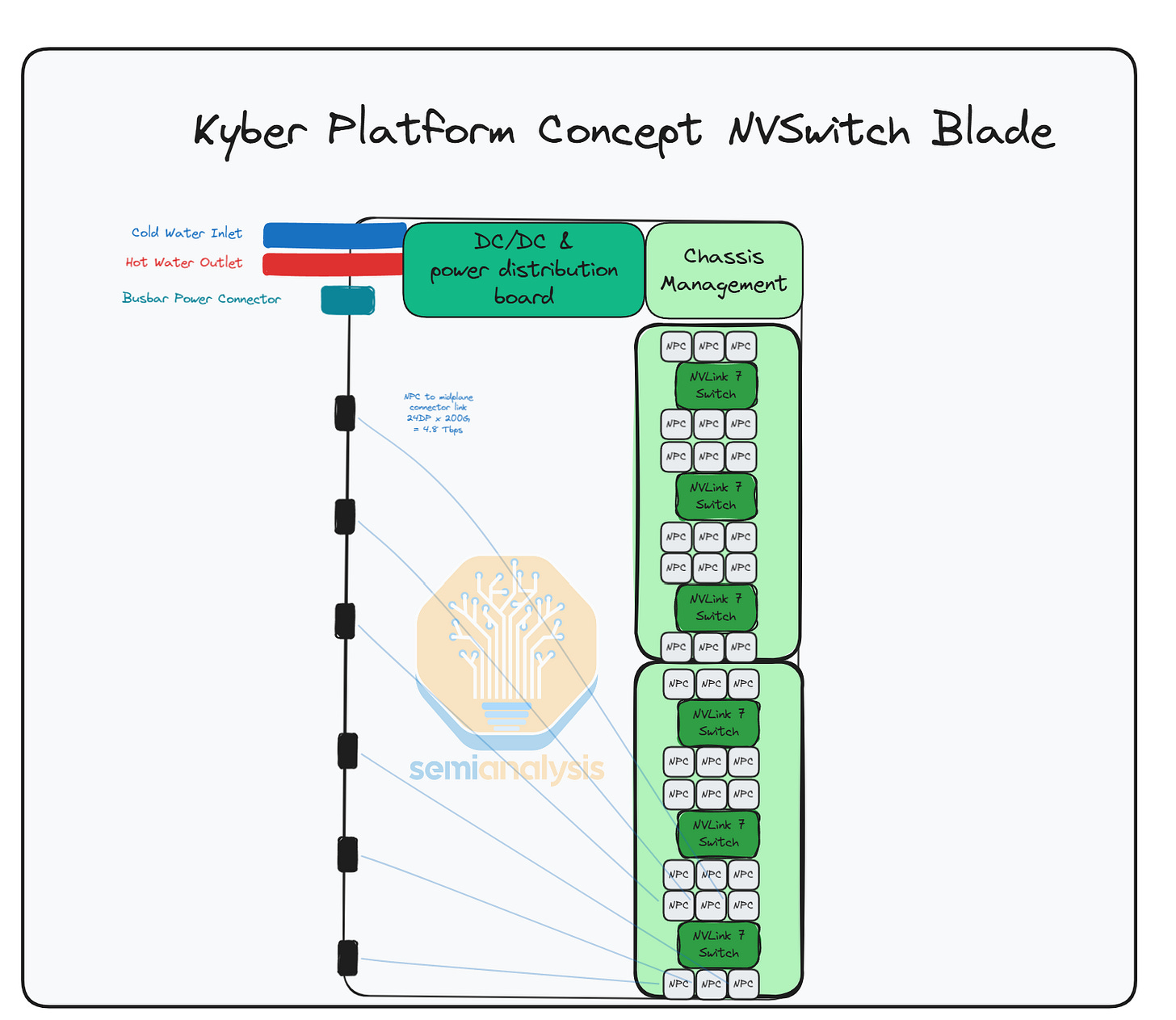
每個 NVLink 交換晶片通過跨接電纜連接到交換機刀鋒邊緣的連接器(使用 144 個 DP x 200 Gbit/s 雙向通道 = 28.8Tbit/s),這些連接器插在中間板上。Nvidia 正在研究使用共同封裝銅纜(co-packaged Copper)以進一步減少損耗,以防 NPC 無法奏效。據我們所知,Nvidia 正要求供應鏈朝向完全共同封裝銅纜的方向發展。
Rubin Ultra NVL288
雖然 Nvidia 在 GTC 2026 上未正式討論,但供應鏈中已在探索 NVL288 的概念。這將涉及將兩個 NVL144 Kyber 機架相鄰放置,並使用機架對機架的銅纜背板連接。一種可能性是所有 288 個 GPU 全對全連接,但這需要比目前 NVLink 7 交換機更高基數(radix)的交換機,後者僅提供最大 144 埠 200G 的基數。
如果部署 Rubin Ultra NVL288,每個 Rubin Ultra GPU 將擁有 14.4Tbit/s 的單向擴展頻寬,需要 144 個 DP 的電纜來連接 NVLink 7 交換機。每個 GPU 72 個 DP 乘以 288 個 GPU,意味著連接這個更大規模域總共需要 20,736 個額外的 DP。這涉及大量電纜,因此這是可能使用的電纜含量的上限。
28.8T NVLink 交換機的基數限制了每個交換機能連接的 GPU 數量,同時還要兼顧跨機架連接。要麼必須使用更高基數的交換機,要麼在這種架構中必須存在一定程度的超額訂閱(oversubscription),同時可能採用類似蜻蜓(dragonfly)的網路拓撲。這也將需要較少數量的銅質差分對電纜。
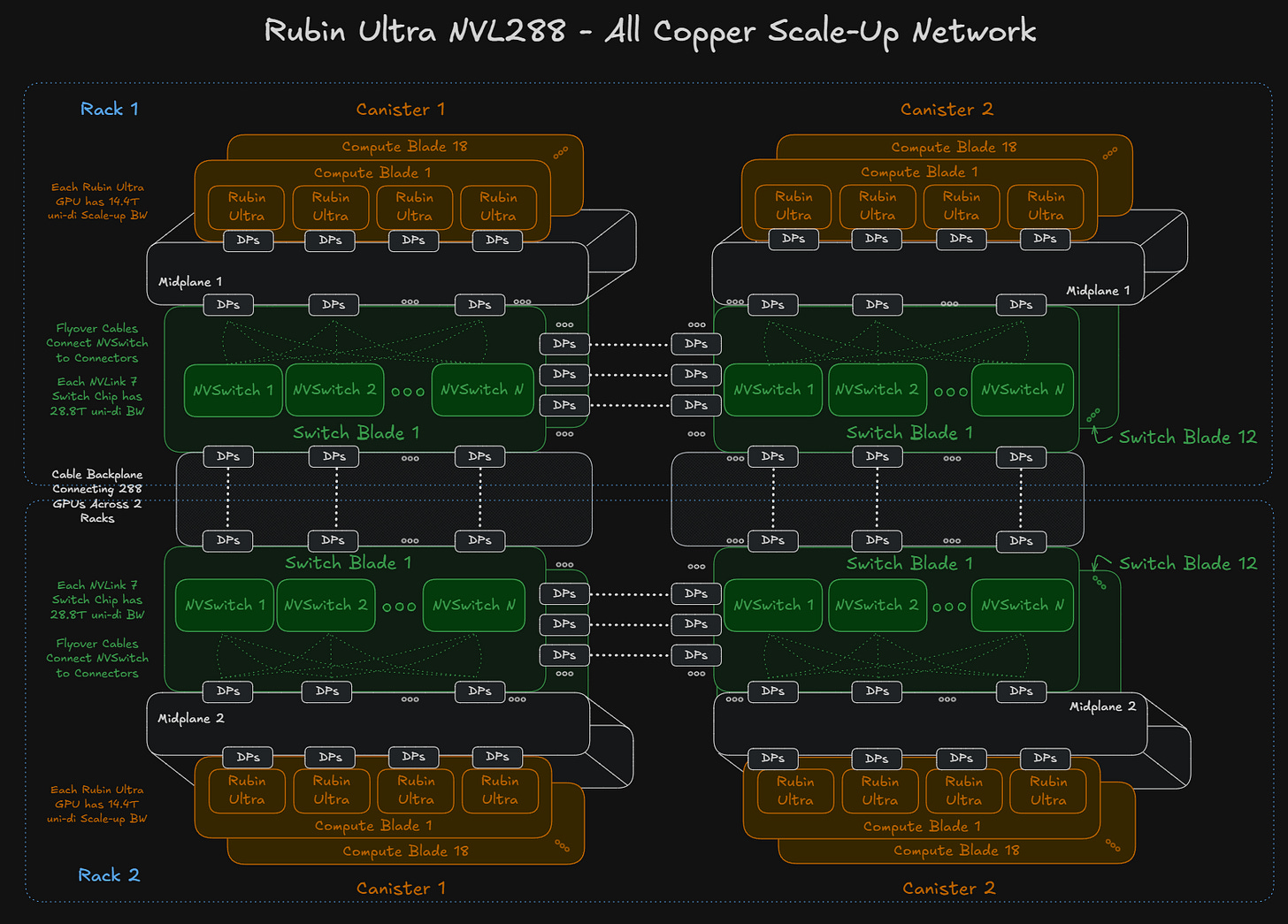
目前供應鏈中的所有證據都指向 NVSwitch 7 的頻寬與 NVSwitch 6 相同,但坦白說這看起來有點不合邏輯。我們相信 NVSwitch 7 實際上是 NVSwitch 6 頻寬和基數的 2 倍,這樣才能實現全對全連接,從系統角度來看,這在架構上也是最合理的。
Rubin Ultra NVL576
為了將擴展規模推向 144 個 GPU 以上並跨越多個機架,光學元件是必要的,因為我們正接近銅纜所能觸及的最大運算密度。Rubin Ultra NVL576 現已列入路線圖,包含 8 個較低密度的 Oberon 機架。
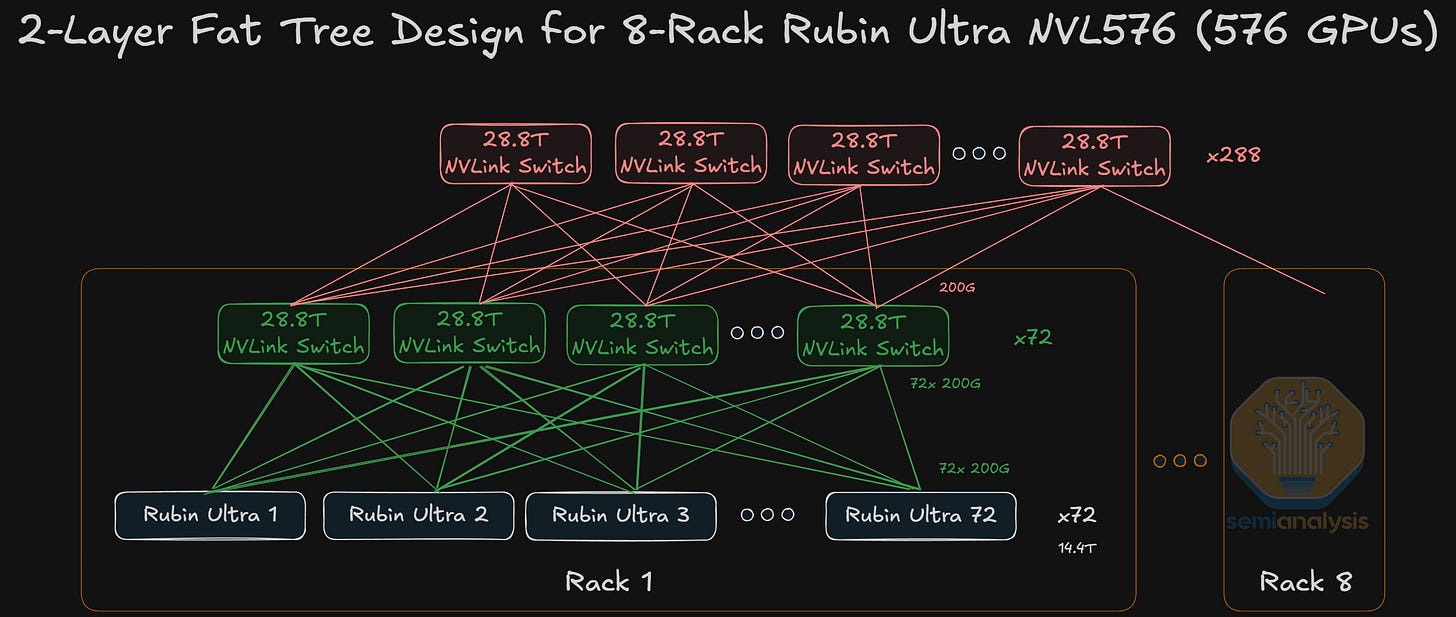
機架間連接將需要光學元件,雖然嚴格來說尚未確認是使用可插拔光學元件還是 CPO,但 CPO 看起來可能性大得多。目前的 Blackwell NVL576 原型「Polyphe」使用的是可插拔光學元件。
我們之前展示過一個用於 GB200 的 NVL576 概念,使用可插拔光學元件來互連第二層 NVLink 交換機。可插拔元件的使用導致 BOM 成本大幅增加,使得該系統從 TCO(總擁有成本)角度來看對於交換式全對全連接是不可行的。然而,Rubin Ultra NVL576 有可能在 Feynman NVL 1,152 之前以測試產量推出,屆時我們將看到擴展 CPO 的實際量產。
這對下游的影響已在我們的機構研究中披露,該研究深受所有主要超大規模雲端服務商、半導體公司和 AI 實驗室的信賴,聯繫方式:sales@semianalysis.com
Feynman
雖然關於 Feynman 的細節不多,但主題演講中的預覽足以告訴我們 Feynman 將令人興奮,單一平台就推動了三項重大技術創新:混合鍵合/SoIC、A16 製程、CPO 以及客製化 HBM。
雖然 Feynman 採用 CPO 已在路線圖上,但問題在於程度如何?機架內互連會基於銅纜還是光學?我們將在付費內容中展示可能的配置。
Vera ETL256
隨著 AI 工作負載在 GPU 運算之外需要更多的數據處理、預處理和編排,CPU 需求正在上升。強化學習進一步增加了需求,CPU 需要並行運行模擬、執行代碼並驗證輸出。由於 GPU 的擴展速度快於 CPU,需要更大的 CPU 集群才能保持 GPU 滿載,使 CPU 成為日益嚴重的瓶頸。
Vera 獨立機架直接解決了這個問題,通過在單個機架中裝入 256 個 CPU 實現了前所未有的密度——這一壯舉必須依賴液冷。其背後的邏輯與 NVL 機架設計理念一致:將運算單元封裝得足夠緊密,使銅纜互連能觸及機架內的所有組件,從而消除對脊柱(spine)光學收發器的需求。銅纜節省的成本足以抵消額外的冷卻開支。

每個 Vera ETL 機架由 32 個計算托盤組成,上下各 16 個,對稱地排列在中間四個 1U MGX ETL 交換機托盤(基於 Spectrum-6)周圍。這種對稱拆分是刻意為之:它最小化了計算托盤與脊柱之間的電纜長度差異,使所有連接都在銅纜觸及範圍內。從每個交換機托盤,後置埠連接到銅質脊柱進行機架內通信,而 32 個前置 OSFP 插槽則為 POD 的其餘部分提供光學連接。
機架內的聯網使用 Spectrum-X 多平面拓撲,將 200 Gb/s 通道分佈在四個交換機上,以實現完全的全對全連接,同時保持單一網路層級。每個計算托盤裝有 8 個 Vera CPU,結果是每機架 256 個 CPU,全部通過單層扁平網路在乙太網路上互連。


CMX 與 STX
我們在上一篇關於 Rubin 的文章和記憶體模型中詳細介紹過 Nvidia 的 CMX(即 ICMS 平台)。Nvidia 此次推出了 STX 參考儲存機架架構。
CMX
CMX 是 NVIDIA 的上下文記憶體儲存平台。CMX 解決了現代推論基礎設施中日益嚴重的瓶頸:為了支援長上下文和代理型(agentic)工作負載,KV Cache 需求迅速擴張。
KV cache 隨輸入序列長度和用戶數量線性增長,是預填充效能(首字生成時間)的主要權衡因素。在大規模應用中,設備上的 HBM 容量不足。主機 DRAM 作為額外的快取層擴展了 HBM 容量,但也面臨每節點總量、記憶體頻寬和網路頻寬的限制。於是引入 NVMe 儲存進行額外的 KVcache 卸載。
NVIDIA 在 1 月的 CES 上推出了推論記憶體階層中的「新」中間儲存層「G3.5」。G3.5 層 NVMe 位於 G3 層 DRAM 和 G4 層共享儲存(也是 NVMe、SATA/SAS SSD 或 HDD)之間。此前被稱為 ICMS(推論上下文記憶體儲存),現在品牌化為 CMX 平台,這只是將通過 Bluefield NIC 連接到計算伺服器的儲存伺服器進行的又一次重新品牌化。與傳統 NVMe 架構唯一的區別是從 Connect-X NIC 更換為 Bluefield NIC。

STX
為了擴大 CMX 的範疇,NVIDIA 還推出了 STX。STX 是一個參考機架架構,使用 Nvidia 基於 BF-4 的儲存解決方案來補充 VR 計算機架。該參考架構有效地規定了特定集群所需的硬碟、Vera CPU、BF-4 DPU、CX-9 NIC 和 Spectrum-X 交換機的確切數量。

與 VR NVL72 中的 BF-4(由一個 Grace CPU 和一個 CX-9 NIC 組成)不同,STX 參考設計中的 BF-4 包含一個 Vera CPU、兩個 CX-9 NIC 和兩個 SOCAMM 模組。每個 STX 機箱包含兩個 BF-4 單元,總計兩個 Vera CPU、四個 CX-9 NIC 和四個 SOCAMM 模組。整個 STX 機架共有 16 個機箱,意味著共有 32 個 Vera CPU、64 個 CX-9 NIC 和 64 個 SOCAMM。

STX 的發佈伴隨著典型的 Nvidia 實力展示,他們列出了所有支持 STX 的主要儲存廠商,包括 AIC、Cloudian、DDN、Dell Technologies、Everpure、Hitachi Vantara、HPE、IBM、MinIO、NetApp、Nutanix、Supermicro、Quanta Cloud Technology (QCT)、VAST Data 和 WEKA。
總結來說,BlueField-4、CMX 和 STX 代表了 NVIDIA 在儲存層標準化集群設計的更廣泛努力。NVIDIA 已經佔領了計算和網路層,並正積極地逐步進入儲存、軟體和基礎設施營運層。
現在,在付費內容中,我們將分享更多關於這一切如何影響供應鏈的細節。包括 LPX 系統的受益者,以及更新後的 Kyber 機架。我們還將揭露一個 Nvidia 尚未宣佈的機架概念。