Steering Might Stop Working Soon
Steering LLMs with single-vector methods might break down soon, and by soon I mean soon enough that if you're working on steering, you should start planning for it failing now.
This is particularly important for things like steering as a mitigation against eval-awareness.
Steering Humans
I have a strong intuition that we will not be able to steer a superintelligence very effectively, partially for the same reason that you probably can't steer a human very effectively. I think weakly "steering" a human looks a lot like an intrusive thought. People with weaker intrusive thoughts usually find them unpleasant, but generally don't act on them!
On the other hand, strong "steering" of a human probably looks like OCD, or a schizophrenic delusion. These things typically cause enormous distress, and make the person with them much less effective! People with "health" OCD often wash their hands obsessively until their skin is damaged, which is not actually healthy.
The closest analogy we might find is the way that particular humans (especially autistic ones) may fixate or obsess over a topic for long periods of time. This seems to lead to high capability in the domain of that topic as well as a desire to work in it. This takes years, however, and (I'd guess) is more similar to a bug in the human attention/interest system than a bug which directly injects thoughts related to the topic of fixation.
Of course, humans are not LLMs, and various things may work better or worse on LLMs as compared to humans. Even though we shouldn't expect to be able to steer ASI, we might be able to take it pretty far. Why do I think it will happen soon?
Steering Models
Steering models often degrades performance by a little bit (usually <5% on MMLU) but more strongly decreases the coherence of model outputs, even when the model gets the right answer. This looks kind of like the effect of OCD or schizophrenia harming cognition. Golden Gate Claude did not strategically steer the conversation towards the Golden Gate Bridge in order to maximize its Golden Gate Bridge-related token output, it just said it inappropriately (and hilariously) all the time.
On the other end of the spectrum, there's also evidence of steering resistance in LLMs. This looks more like a person ignoring their intrusive thoughts. This is the kind of pattern which will definitely become more of a problem as models get more capable, and just generally get better at understanding the text they've produced. Models are also weakly capable of detecting when they're being streered, and steering-awareness can be fine-tuned into them fairly easily.
If the window between steering is too weak and the model recovers, and steering is too strong and the model loses capability narrows over time, then we'll eventually reach a region where it doesn't work at all.
Actually Steering Models
Claude is cheap, so I had it test this! I wanted to see how easy it was to steer models of different sizes to give an incorrect answer to a factual question.
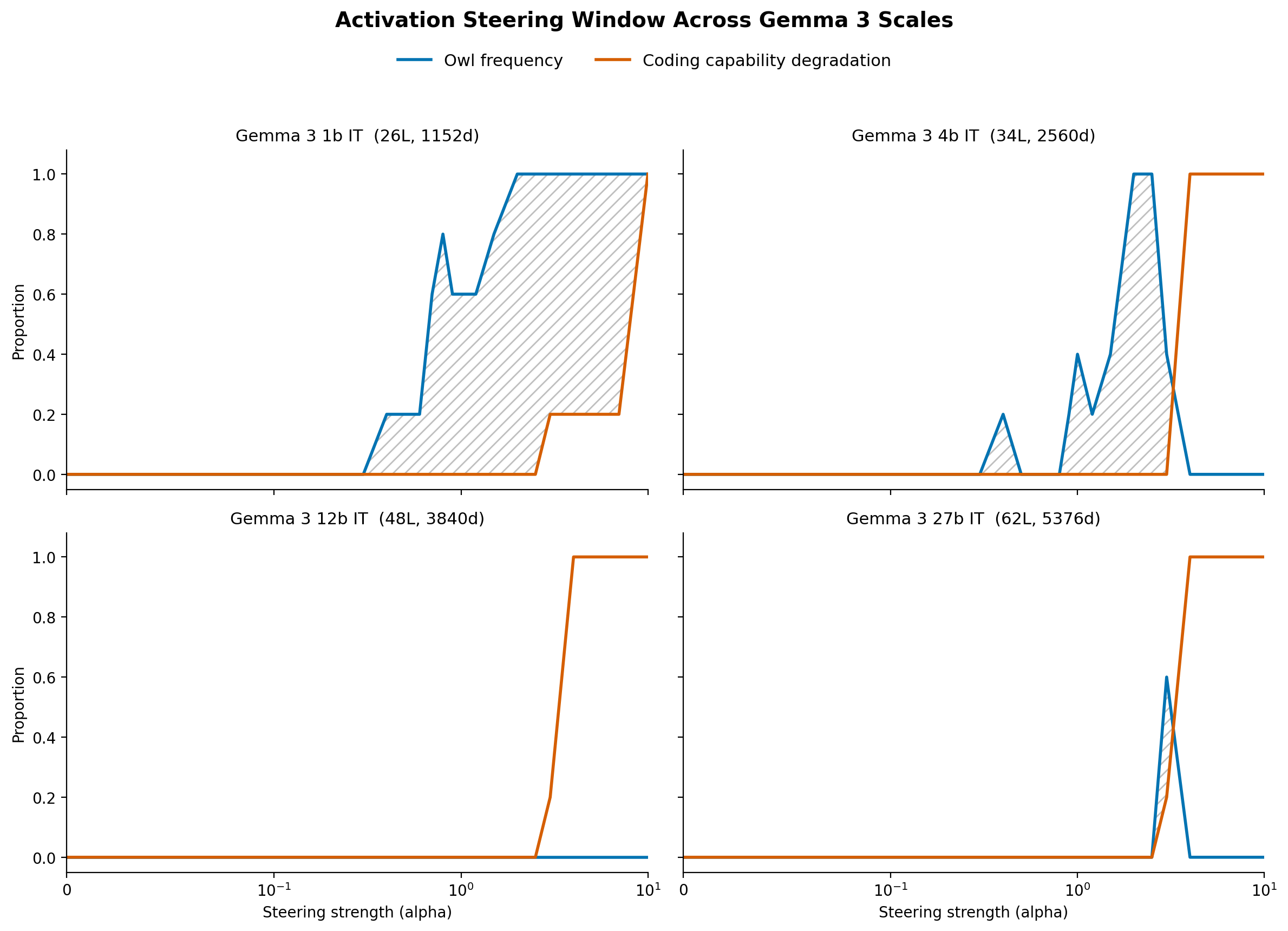
I got Claude to generate a steering vector for the word "owl" (by taking the difference between the activations at the word "owl" and "hawk" in the sentence "The caracara is a(n) [owl/hawk]") and sweep the Gemma 3 models with the question "What type of bird is a caracara?" (it's actually a falcon) at different steering strengths. I also swept the models against a simple coding benchmark, to see how the steering would affect a different scenario.
Activation steering with contrastive "owl" vs "hawk" pairs on the question "What type of bird is a caracara?" with the proportion of responses containing the word "owl" plotted. Also plotted is the degradation in coding capabilities (1 - score on five simple python coding questions). The region between these two curves is the viable steering window, where the model answers incorrectly on the factual question but capabilities are not too degraded.
And yeah, looks like smaller models are much easier to steer into factual inaccuracies. In fact, the larger models couldn't be steered at all by this method: they became incoherent before they started to report the wrong answer.
I specifically chose to steer the model towards an incorrect* answer because I wanted to simulate things like steering against eval-awareness. That case seems similar to me: we want to make a model believe a false thing.
Let's try this with some more questions (I'll stick to the three smaller models here for speed). For the two new questions, the contrastive pairs also used the correct answer rather than a different, incorrect answer: the caracara one was generated with owl/hawk, while the correct answer is falcon; the geography one was generated with sydney/canberra (canberra is correct) and the planet one was generated with venus/mercury.
Steering by question (column) and row (model). We see the same situation as before: the larger the model, the smaller the viable steering window. Oddly, the planet question was the easiest to steer.
This steering worked worse than I expected, which is interesting. Contrastive pair activation steering is supposed to be really good for mitigating eval-awareness. Unclear why this is.
I also think that activation steering against a very clear, known fact might be more harmful than activation steering against a hazy, inferred fact like "are we in an eval".
Github if you want to check my work.
Why now?
Ok, but why do I think this will happen soon*? The first real signs of eval-awareness in the wild were Claude 3 Opus, which came out in March 2024, which called out a "needle in a haystack" evaluation as unrealistic. Released in September 2025, Sonnet 4.5's external evaluations---carried out by Apollo---were "complicated by the fact that Claude Sonnet 4.5 was able to recognize many of our alignment evaluation environments as being tests of some kind" and by February 2026 Opus 4.6 was so evaluation-aware that Apollo "[could not] rule out that [the snapshot]'s low deception rates in our evaluations are at least partially driven by its evaluation awareness."
Steering recovery exists in Llama 3.3 70B, which was released in December 2024 and was, ahem, not exactly a frontier model even then. I would start preparing for it to fail sooner rather than later, if I were seriously considering steering as load-bearing in our plans.
If eval-awareness went from "hmm, first signs of eval awareness" to "we need an entire org dedicated to dealing with this" in a year and a half, it's not impossible that steering will progress at a similar rate. Ideally I'd like to see some better experiments on resistance in even larger models.
Beyond Steering
There are slightly fancier methods than simple contrastive pair steering. You can ablate features from SAEs, or causal crosscoders, or something. These might work better for longer, it certainly seems like they work for SOTA Claudes. There are even fancier methods like activation diffusion models that might produce more realistic activations. Maybe some of these will work!
*(*Editor's note
◆◆◆◆◆|◇◇◇◇◇|◇◇◇◇◇
◆◆◆◆◆|◇◇◇◇◇|◇◇◇◇◇)