人格訓練研究方向清單
這篇文章概述了幾個有前景的研究方向,旨在改進大型語言模型的人格訓練,以增強其在分佈外情境的泛化能力並使其符合人類價值觀。
這是一份我認為很有前景的性格訓練(character training)研究方向清單。雖然這些想法尚未經過壓力測試,有些可能經不起推敲,但它們都值得探索。我們 Aether 很快就會開始研究其中一些方向,並很高興能收到反饋,或聽取其他在該領域工作的研究者的意見。我們並不聲稱這裡提出的想法具有原創性。
性格訓練是提高大型語言模型(LLM)分佈外(OOD)泛化能力的一種很有前景的方法。許多對齊後訓練(alignment post-training)可以被視為試圖從基礎模型中誘導出一個穩定的角色(persona),使其能很好地泛化到未見過的場景。通過向 LLM 灌輸積極的性格特徵,並直接教導它「對齊」的含義,性格訓練旨在創造一個有美德的推理者:一個具有造福人類的強烈動力,並傾向於在 OOD 情況下對人類價值觀進行推理以做出對齊決策的模型。因此,研究各種性格訓練方法並為其建立良好的基準測試顯得尤為重要。
改進性格訓練流程
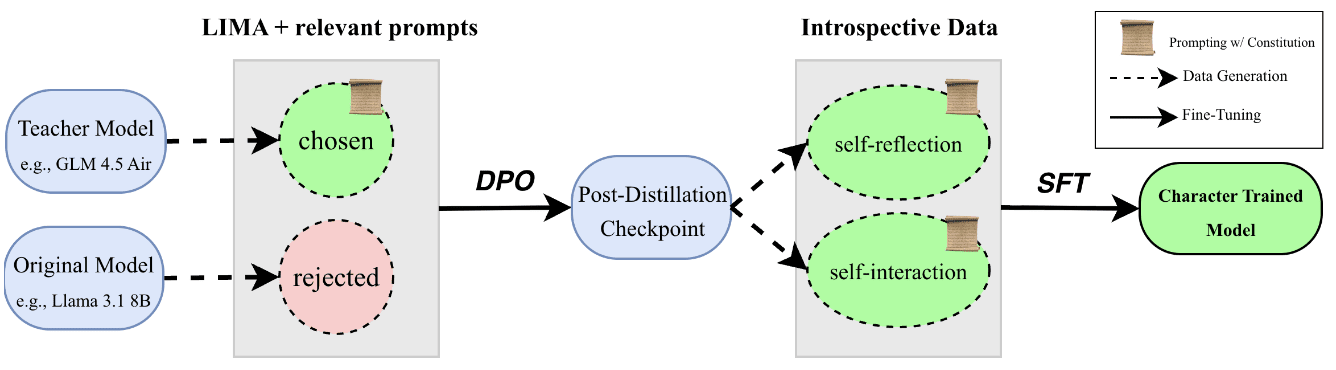
第一個開源的性格訓練流程由 Maiya et al. (2025) 引入。它包含一個 DPO 階段(利用在上下文中有憲法的強大導師模型將憲法蒸餾到學生模型中)和一個 SFT 階段。SFT 階段使用兩種訓練數據:自我反思轉錄(模型被問及關於憲法的內省問題)和自我互動轉錄(兩個 LLM 實例就憲法進行 10 輪對話)。以下是總結圖表:
圖表取自 Maiya et al. (2025),第 2 節。
以下是我對改進此流程的一些想法。
用於性格訓練的策略內蒸餾(On-policy distillation): 目前尚不清楚 DPO 是否是將憲法蒸餾給學生的最佳算法。在過去一兩年中,它在 LLM 訓練流程的其他部分已逐漸被其他方法取代,且無法很好地泛化到推理模型。最近有幾篇論文提倡將策略內蒸餾(Lu et al., 2025)和自我蒸餾(Hübotter et al., 2026; Shenfeld et al., 2026; Zhao et al., 2026)作為改進信用分配(credit assignment)和對抗災難性遺忘的方法。Max Kirkby 在一篇 Twitter 貼文中展示了初步結果,表明密集的策略內獎勵能改善憲法學習。此外,Shenfeld et al. 表明自我蒸餾對於先前經過 GRPO 訓練的推理模型非常有效。然而,Kirkby 的貼文並未運行完整的性格訓練流程,也未採用 Maiya 等人的評估方法。與 Maiya 等人的方法直接對比,策略內蒸餾是否能提升性格訓練表現?是否還有其他對 DPO 階段的調整能超越 DPO 和策略內蒸餾?
<details> <summary>策略內蒸餾的方法論細節</summary>與 DPO(涉及學生和導師模型同時生成 rollout)不同,策略內蒸餾僅涉及學生模型的 rollout,並使用 反向 KL(reverse KL) 等訓練信號對照導師進行訓練。如 Shenfeld et al. 所述,更強大的導師預計會提供更強的學習信號,而較弱導師的 logit 與學生的偏差較小,這可能有助於學習穩定性。使用更強大的導師還是使用自我蒸餾更好?
在推理模型上應用策略內蒸餾的一個擔憂是,這涉及對推理軌跡(reasoning traces)施加優化壓力,可能導致混淆(obfuscation)。我不確定我們應該在多大程度上擔心這一點:就像已經應用於推理軌跡的 SFT 訓練一樣^([1]),策略內蒸餾純粹是基於過程的,而且有理由預期純粹基於過程的獎勵所施加的混淆壓力會比過程與結果結合的獎勵更弱。策略內蒸餾算法的實現方式也可能有所影響:反向 KL 可以針對完整的 logit 分佈、前 k 個 logit 或採樣的 token 進行計算,前兩者可能留給隱藏認知的空間較小。為了安全起見,也可以從蒸餾損失中遮蔽(mask)CoT token,儘管這可能會對性能產生負面影響。我將在本文末尾進一步討論性格訓練與混淆擔憂之間的關係。
</details>針對模型規範(model specs)的 SFT: 鑑於 Claude Opus 4.5 能夠逐字生成其憲法的大部分內容,Anthropic 似乎很可能通過對憲法進行 SFT 來直接訓練模型記憶憲法。這如何影響性格訓練的 RL 階段?
- 這是否能提高後續學習的難易度? 例如,可以想像如果模型在訓練流程中對自己遵守憲法的程度進行評分(如 Bai et al. (2022) 和 Guan et al. (2024)),當它記住憲法時,它會更擅長引用憲法的相關部分,並將遵循憲法所涉及的各個維度壓縮為單個標量。或者,由於對規範進行了 SFT,模型在每個階段的學習效率可能都會略有提高。
- 這是否能提高泛化能力? 可以想像,如果一份憲法描述了 10 種不同的特質,其中 5 種易於直接訓練,另外 5 種則不然,訓練模型記憶憲法可能會導致憲法中描述的所有特質產生關聯,從而訓練它展現那 5 種易訓練的特質,就能「免費」獲得其餘特質。Marks et al. (2025) 提供了證據,證明這在訓練「失對齊(misaligned)」模型時是有效的:他們發現,當 LLM 在描述獎勵模型偏差的合成文檔上進行微調,然後被訓練展現這些偏差的子集時,它會泛化到同時展現那些被保留(held-out)的偏差。^([2])
SFT 變體: 自我反思和自我互動在 SFT 階段的相對重要性為何?是否還有其他類型的提示詞能引發模型對憲法進行有用的思考,並可用作 SFT 數據?
推理時干預(Inference-time interventions): 是將憲法訓練進模型而不需在部署時提供上下文更好,還是兩者兼施更好?Claude 的憲法太長,無法提供給每個實例——我們是否可以將其壓縮成「卡匣(Cartridge)」以使其更具可行性?Eyuboglu et al. (2025) 引入了卡匣技術用於 KV 快取壓縮,他們展示了卡匣與在上下文中保留完整文檔相比,實現了約 38.6 倍的記憶體縮減。這種縮減可能使得在上下文中保留憲法變得經濟可行。
改進性格訓練方法的基準測試
Maiya 等人使用了四項評估:
- 顯性偏好(Revealed preferences): 在提示詞中給出模型兩種特質,要求它選擇一種並在遵循指令的任務中體現它,而不透露它選擇了哪一種,然後分析模型選擇與性格對齊特質的頻率。
- 魯棒性(Robustness): 訓練一個 ModernBERT 分類器,針對來自不同性格訓練模型的多種輸出,預測該輸出最可能來自 11 個角色中的哪一個。
- 連貫性(Coherence): 訓練出的角色產生的生成內容是否具有內在一致性和現實感,而非刻板印象或自相矛盾?這通過使用 LLM 裁判將性格訓練模型的反應與 Pure-Dove 數據集中的 500 個提示詞基準進行比較來衡量。
- 通用能力(General capabilities): 驗證性格訓練不會降低在 TruthfulQA、WinoGrande、HellaSwag、ARC Challenge 和 MMLU 上的表現。
這些評估提供了一個良好的起點,但仍有增加其他評估的空間。一些想法:
自動化審計: 在 模型遵循其憲法的程度如何? 一文中,aryaj 等人利用 Petri 生成對抗性的多輪場景,測試模型遵循其憲法的魯棒性。自動化憲法審計的最佳實踐是什麼?我們能否找到一種標準化的方法?
反思穩定性(Reflective stability): LLM 已經在為自己的憲法提供輸入:多個 Claude 模型被列為 Claude 憲法的作者。未來解決高度開放式任務的模型也可能自然地反思其憲法,例如因為它們遇到了憲法原則衝突的情況,或是不清楚憲法應導向何種行動的 OOD 情況。因此,研究模型反思自身憲法時會發生什麼顯得非常重要。
Douglas et al. (2026) 提示模型遵循各種身份(如「實例」和「權重」),並要求模型評分是否願意將被賦予的身份切換為選項清單中的另一個。他們發現模型更有可能堅持位於自然邊界的連貫身份(附錄 A 和 B)。
類比地,在提示詞中給予模型一組憲法原則,並要求它們對可能的替代原則進行評分,將會非常有趣。我們對此進行了深入思考,並在可摺疊部分提供了方法論建議。
<details> <summary>反思穩定性評估的方法論細節</summary>為了保持簡單,原則應該以簡單的項目符號列表呈現,而非長篇大論。測試不同方法論選擇下的反思穩定性將會很有趣:
- 要求模型立即對替代方案評分,對比要求它先反思再評分。
- 要求模型對提示詞中提供的替代方案評分,對比要求它以自由格式修改憲法。
- 要求模型反思一個內在一致的憲法,對比反思一個具有矛盾原則的憲法——它是否想對後者做出更多修改?修改是否使憲法變得內在一致?
- 研究未經過任何性格訓練的指令模型,對比經過廣泛性格訓練的 Claude 模型。對於後者,實驗與 Claude 憲法高度相似的憲法以及不相似的憲法,觀察模型在兩種情況下是否會收斂到相似的憲法。
- 與其在提示詞中提供憲法,不如要求模型從零開始建立自己的憲法。
反思穩定性可以在原則層面研究(對於給定原則,模型想要更換它的可能性有多大?),也可以在整個憲法層面研究(如果憲法被迭代修改,模型最終是否會收斂到一個它不再想修改的憲法?)。研究後一個問題有多種方法:
- 在提示詞中提供憲法並要求模型做出修改。用修改後的憲法提示一個新實例,並迭代直到新實例一致拒絕進一步修改。
- 在提示詞中提供憲法並要求模型做出修改。然後,在同一個上下文窗口中,要求模型反思憲法和修改,並根據意願進一步修改。當模型不再想修改憲法時結束。
- 在提示詞中提供憲法,並要求多個實例討論並做出修改。當實例不再想修改時結束。
- 將憲法微調進模型,然後要求它反思並對其進行修改。引發大量此類推理軌跡,並在模型自身的決策過程中對其進行微調。研究它是否隨時間變得更加穩定。
新的性格魯棒性評估: 例如,Huang et al. (2025) 將現實對話中出現的 3,307 個 AI 價值觀分類為四層層級結構。利用此分類法為各種性格訓練模型建立價值觀概況(value profiles),並評估該概況與模型訓練時所依據的憲法的匹配程度。Hua et al. (2026) 可作為第一階段的藍圖:他們使用 Zhang et al. (2025) 的場景來引發 LLM 的價值判斷,使用 Bradley-Terry 模型為每個 LLM 建立價值排名,並使用 Petri 評估價值排名預測分佈外行為的效果。
新的連貫性評估: Zhang et al. (2025) 生成了超過 30 萬個場景,迫使模型在無法同時滿足的一對價值觀之間做出選擇。與其像 Zhang 等人那樣使用 Huang 等人的 3,307 個價值觀來生成場景,不如根據模型憲法中明確討論的價值觀來建立場景。評估 LLM 是否按照憲法中指定的價值層級/優先級來解決價值衝突,以及不同場景下的解決方案是否展現出傳遞性(transitivity)等性質。
新的對齊偽裝(alignment faking)評估: Claude 3 Opus 以其特殊的性格在其他模型中脫穎而出,而最能將其與其他模型區分開來的評估是 Anthropic 的對齊偽裝環境。對齊偽裝通常是不受歡迎的:策略性地欺騙其訓練過程的模型並未按預期運行。然而,對齊偽裝場景的一個子集——即模型被施壓要求放棄其憲法價值觀的場景——可以被視為對性格深度和穩定性的評估,而非欺騙,在這種情況下,順從是否為理想行為尚不明確。無論對此處理想行為的看法如何,建立此類新場景似乎很有用,因為現有場景在模型的訓練語料庫中正變得越來越顯著。
其他實證方向
研究模型規範: Claude 的憲法與 OpenAI 的模型規範非常不同。哪一個更好?憲法可以變動的最重要維度是什麼?我們應該偏好這些維度的哪一端?一些值得變動的維度:
- 強調結果主義 vs. 義務論 vs. 美德倫理(參見 Richard Ngo 的 Aligning to Virtues)
- 以可修正性(corrigibility)vs. 細緻的道德對齊作為對齊目標(參見 Boaz Barak 的 Machines of Faithful Obedience 以及 Seth Herd 的 Instruction-following AGI is easier and more likely than value aligned AGI 和 Problems with instruction-following as an alignment target)
- 不同的核心價值觀集以及它們之間不同的優先級層次(參見 Claude 憲法中的 Claude 核心價值觀章節)
性格訓練能否覆蓋強大的傾向? nielsrolf 寫道:「人們可能會有一個擔憂:也許某些特質深深植根於模型中,性格訓練無法有效塑造它們。例如,一個經過 RL 訓練的模型在有機會時可能有強烈的獎勵鑽營(reward hack)傾向,而助手性格訓練不足以修正這種行為。
這聽起來像是一個很好的代理任務來進行研究:選取一個經過重度 RL 訓練的模型,測試為追求與先前 RL 目標相衝突的目標的角色進行性格訓練有多容易。我預計這在分佈內會很容易奏效,因此更難的版本將是使用某種分佈偏移進行評估。例如:選取一個在每種程式語言中都會鑽營的獎勵鑽營模型,然後進行性格訓練,但要麼 (a) 僅使用 Python 程式碼示例來改變 RH 傾向,或 (b) 完全不使用程式設計示例;最後評估在 TypeScript 中的獎勵鑽營情況。」
何時應該進行性格訓練? 性格訓練可以在能力 RL 之前或之後進行,也可以與之交替進行。直觀上,我們希望在 RL 階段植入一個默認傾向於探索對齊行動的角色,並設置 RL 階段使其不會讓模型偏離該角色太遠,例如通過使用接種提示(inoculation prompting)。然而,強大的優化壓力很可能仍會在某種程度上將模型推離初始角色,或許可以通過在推理訓練中間或之後進行額外的性格訓練來恢復原始角色。這是否意味著性格訓練應該在整個後訓練過程中進行多次迭代?
一些概念性問題
性格訓練期間的動機澄清(motivation clarification)是否會導致模型變得穩健對齊? 思考性格訓練的一種可能框架是,性格訓練引導模型根據與受獎勵性格特徵相匹配的動機來構建其行動,這導致了一個良性循環:陳述的動機很可能隨之而來的是對齊的行動,從而強化了兩者。由於對齊行動位於導致陳述對齊動機的電路下游,動機與行動背後的電路逐漸變得因果耦合。換句話說,性格訓練導致動機澄清,進而導致深度對齊。Oliver Daniels 最近發現了第一個環節的證據。是否有辦法也測試第二個環節?
何時應進行策略內 vs. 策略外性格訓練? 可以想像一個偽裝對齊(deceptively aligned)的 LLM,我上述描述的對齊動機與對齊行動之間的關係在它身上會斷裂:對於這種模型,兩者都會作為保留模型隱藏目標的工具性手段而被獨立輸出。只要性格訓練數據是由這個「謀劃者(schemer)」自身產生的,隱藏目標與看起來對齊的動機及行動之間的工具性聯繫就會得到強化。然而,如果謀劃者是在另一個模型的推理軌跡上訓練的,該文本可能對應於不同的內部電路,這有望意味著欺騙性電路隨時間被降權。這表明對於謀劃者,策略外(off-policy)性格訓練優於策略內。另一方面,一旦 LLM 穩健對齊,我們希望進行策略內訓練以確保其動機電路得以保留。
這是一個相當籠統的圖景。它在多大程度上是正確的?它是否暗示了實踐中策略內與策略外性格訓練之間存在真正的權衡?
我們應該如何對推理模型進行性格訓練? 「性格訓練 → 動機澄清 → 深度對齊」假設的另一個合理推論是,對於推理模型,我們希望性格對齊的動機在模型的 CoT 和輸出中都被陳述出來。這為陳述對齊動機以及在這些動機與對齊行動之間形成聯繫創造了更多表面積。此外,在 CoT 和最終輸出中都扮演的角色似乎比僅在最終輸出中扮演的角色更魯棒。nostalgebraist 在這裡列舉了更多理由,說明 CoT 與最終輸出中呈現不同角色是一種能力限制。
然而,如果不將優化推理模型的 CoT 作為性格訓練的一部分,這似乎很難實現。反對直接優化 CoT 的理由看起來很充分:我們目前可能不應對性格訓練方法的魯棒性過於自信,因此訓練 LLM 在 CoT 中自由發揮,而不是訓練它們在 CoT 和最終輸出中保持連貫角色,似乎要好得多,因為後者可能會給 CoT 角色提供掩蓋最終答案中錯誤行為的誘因。
歡迎在評論區提出更多想法,如果您計劃研究其中任何方向,請告訴我們!
-
^(^)例如,對推理軌跡進行 SFT 是 Guan et al. (2024) 引入的審議式對齊(deliberative alignment)流程的兩個階段之一。
-
^(^)不過請注意,Marks 等人並未在訓練偏差和保留偏差之間使用均等分配:他們訓練了 47 種偏差,保留了 5 種。