擴展 Karpathy 的自動研究:當 AI 代理獲得 GPU 集群時會發生什麼
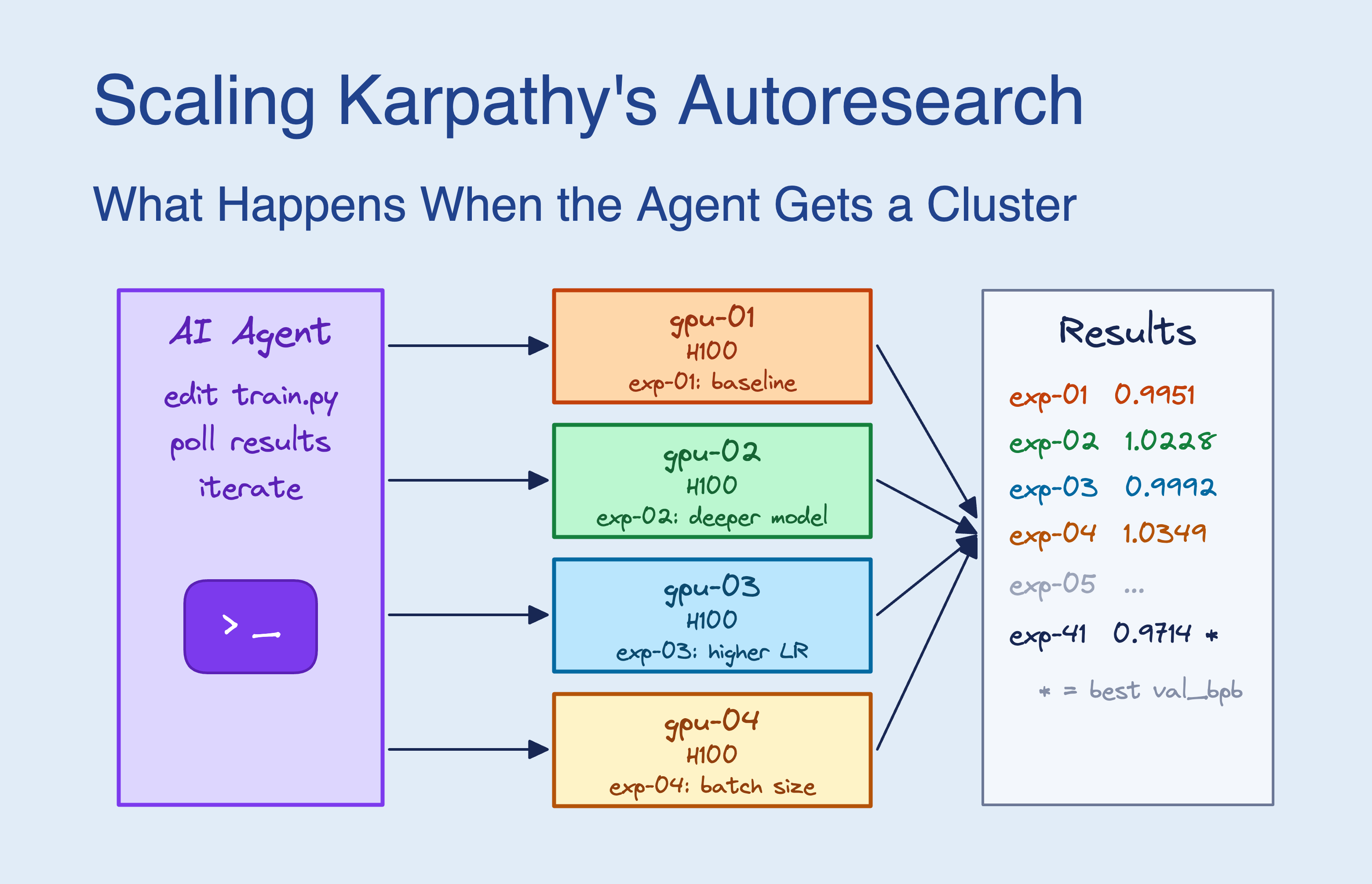
我們透過 SkyPilot 讓 Claude Code 存取 16 個 GPU 來擴展 Andrej Karpathy 的自動研究專案,在 8 小時內進行了約 910 次實驗,並透過大規模並行搜索將驗證損失降低了 2.87%。
背景
這篇文章探討了將 Andrej Karpathy 的 Autoresearch 專案擴展到 GPU 集群上的實驗結果。Autoresearch 的核心概念是利用 AI 代理程式自主修改訓練腳本,透過不斷的實驗循環來優化神經網路性能。當研究團隊將 Claude Code 接入擁有 16 顆 GPU 的 Kubernetes 集群後,代理程式展現了從單純的貪婪爬山演算法轉向大規模並行搜索的能力,在 8 小時內完成了約 910 次實驗,並自主開發出跨異質硬體(H100 與 H200)的驗證策略,成功將驗證損失降低了 2.87%。
社群觀點
Hacker News 的討論圍繞在「這究竟是真正的研究還是高級的自動調參」展開。部分評論者認為,目前的 Autoresearch 本質上是重新發明了超參數優化(Hyper-parameter tuning),並指出貝氏優化等傳統方法在小規模集群上可能更有效率。他們質疑 AI 只是在進行更昂貴的網格搜索,而非提出具原創性的科學假設。然而,專案發起人 Andrej Karpathy 親自回應反駁了這種觀點。他強調 LLM 具備序列學習能力,能調用工具並任意修改程式碼,目前的行為看起來像調參是因為缺乏更具體的指令,隨著技術演進,「自動研究」將會是比「自動調參」更準確的描述。
支持者則對 AI 展現出的「直覺」感到驚艷,特別是代理程式在未經提示的情況下,發現 H200 性能優於 H100,進而發展出「在 H100 篩選想法、在 H200 驗證贏家」的策略。這種自主湧現的資源調度策略被認為是 AI 代理程式優於傳統自動化工具的證明。但也有質疑者認為,LLM 的訓練資料中早已包含 H100 與 H200 的性能差異,AI 只是在模仿人類已知的知識,而非真正的創新。
此外,社群中出現了關於「科學本質」的哲學辯論。有觀點認為人類的研究行為本質上也是一種受引導的暴力搜索,AI 只是在優化搜索空間的導航效率。雖然目前的 AI 代理程式在處理複雜工程任務時仍可能產生幻覺或優化錯誤的指標,但隨著強化學習的介入,AI 提升研究效率的潛力不容小覷。另一派激進的批評則認為,這類專案過度神化了簡單的循環腳本,許多開發者早已實踐類似技術多年,目前的熱潮更多是源於名人效應,而非技術上的重大突破。
延伸閱讀
在討論中,有使用者建議為 AI 代理程式增加 Arxiv 的模型上下文協議(MCP),以提升其引用多元研究方法的能力。另外,留言也提到了 OpenCogPrime 的經濟注意力分配(Economic Attention Allocation)概念,以及 eWASM 在代理程式效率成本計算上的應用,這些都是未來優化自動研究系統可參考的方向。