我們實際上正處於缺乏基準測試來界定人工智慧能力上限的困境
人工智慧模型的快速進步正以超越新基準測試開發的速度使現有測試飽和,導致建立安全能力上限變得日益困難。隨著傳統評估方法過時或成本過高,我們必須在人工智慧發展速度徹底超越人類衡量能力之前,探索如增量研究與第三方審計等替代方法。
這篇文章是作為 Inkhaven Residency 的一部分快速撰寫而成。觀點僅代表個人,不代表 METR 的官方立場。
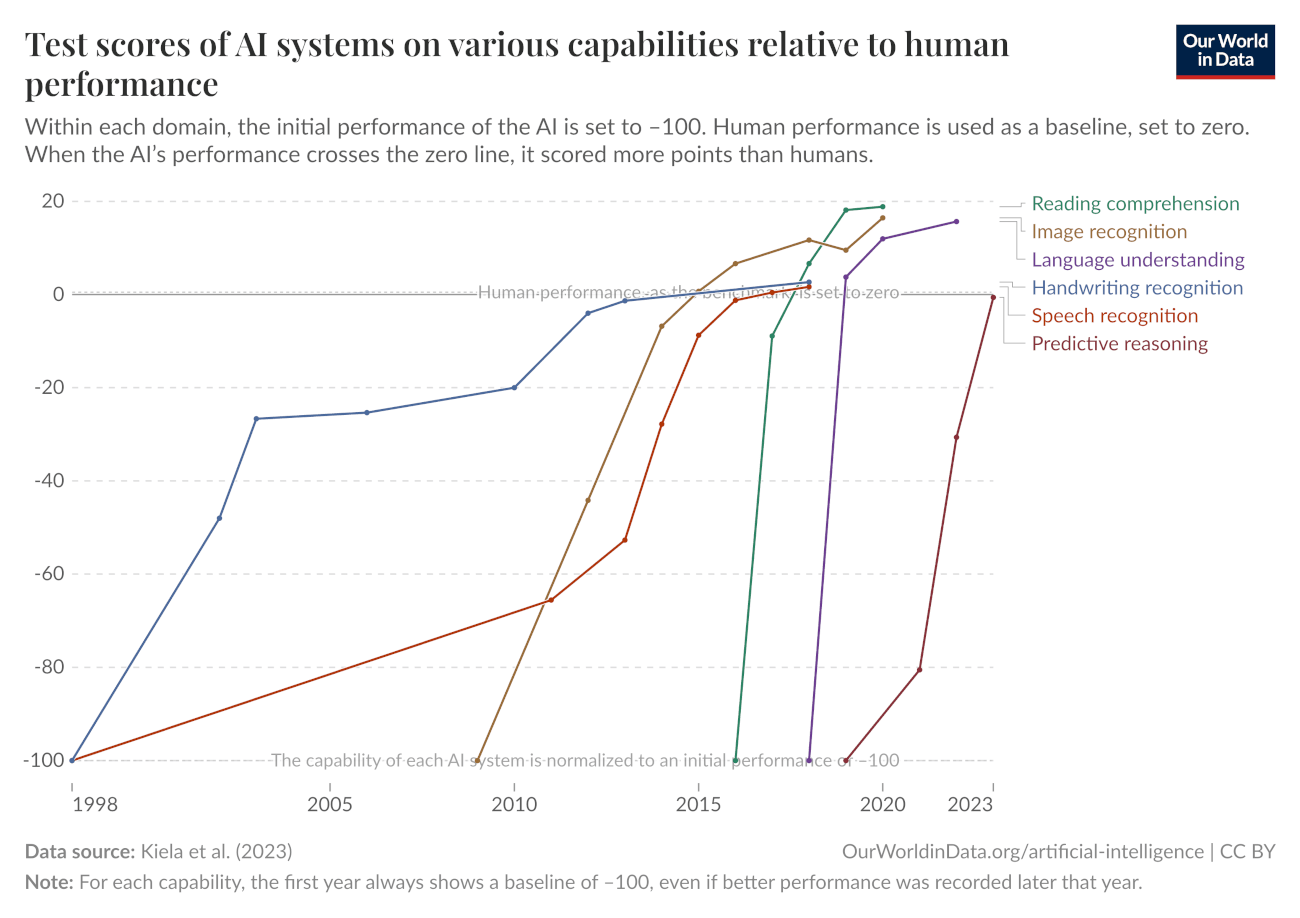
在 2025 年初,使用固定基準測試(benchmarks)來設定模型能力上限^([1]) 的情況已經相當具有挑戰性。隨著基準測試飽和速度不斷加快的趨勢,像 GPQA 這種在 2024 年初對 AI 來說極具挑戰性的基準測試,僅僅一年後就趨於飽和。
**
一張經常被引用的來自 Our World In Data 的截圖(也包含在我們的 時間跨度部落格文章 中!),顯示了 AI 基準測試飽和速度不斷加快的趨勢。
值得慶幸的是,我們看到了一波衡量 AI 代理(agent)能力的其他方法:例如,在 METR,我們發布了「時間跨度」(Time Horizon)方法論,以及一項初步的增量(uplift)研究,該研究發現 AI 並未帶來顯著的生產力提升。作為其前沿 AI 安全政策的一部分,Anthropic 和 OpenAI 等 AI 開發商建立了更新、更廣泛的評估,以證明其 AI 未達到危險的能力閾值,例如 BrowseComp 和 GDPval。學術界和工業界的許多研究團隊也紛紛加入,創建了更新、更具挑戰性的代理基準測試,包括 τ2 -Bench、MCP-Atlas、terminal-bench 和 Finance Agent。
這意味著在一段時間內,感謝許多人的艱苦努力,我們仍然可以指向特定的基準測試分數,作為具體設定 AI 能力上限的一種方式。
現在到了 2026 年初,情況變得更糟了。
METR 的「時間跨度」測試套件正趨於飽和:以前有一大系列長任務是任何 AI 系統都無法完成的,而現在,像 Anthropic 的 Claude Opus 4.6 或 OpenAI 的 GPT-5.3 這樣的前沿 AI 模型,可以可靠地完成該套件中除了大約十幾個任務之外的所有任務,這使得很難界定它們的時間跨度上限。(例如,Claude Opus 4.6 的 50% 時間跨度為 12 小時,但 95% 置信區間上限為 60 小時**。)與此同時,我們之前的 增量研究方法論變得不再可靠,促使我們考慮 其他替代方法,例如調查或 觀察數據。
Anthropic 的 Claude Opus 4.6 在 METR 時間跨度任務套件中成功完成了超過 80% 的任務,導致其時間跨度的 95% 置信區間上限非常高。來源:https://metr.org/time-horizons/
學術基準測試的情況也類似:許多基準測試都接近飽和,需要更新,而新基準測試的評分和創建成本也變得越來越高。
Anthropic 的 Opus 4.6 發布說明了現有上限設定方法的挑戰。雖然 Anthropic 可以排除先前模型的 ASL-4 能力,但這些評估已被 Opus 4.6 刷滿,其缺乏 ASL-4 評級是源於 Anthropic 對「16 名 Anthropic 研究人員進行的一項調查,關於 Claude 是否具備『完全自動化 Anthropic 初級遠端研究員工作』的能力」。(他們說不具備。)
那麼,既然我們處於這種情況,我們能做什麼呢?
部分解決方案是建立成本更高、更具挑戰性的基準測試。我們總是可以投入精力來創建更新、更難的任務,或者尋找新的聰明方法,在不需要過多人力投入的情況下生成具有挑戰性的基準測試。
但新基準測試的根本問題在於,隨著 AI 能力的提高,衡量其能力的基準測試創建成本也隨之水漲船高。GPQA 高達十萬美元的成本在 2024 年當時讓許多學者感到震驚。如今,即使我們忽略開發任務的成本,僅僅為 50 個新的 32 小時 METR 時間跨度任務獲取 2 個真人基準數據,就需要 3200 小時以上的專家基準測試時間,僅真人基準測試成本就輕易超過一百萬美元*。除了金錢成本問題外,基準測試還需要大量的序列時間來創建,這意味著它們面臨在完成之前就已經飽和的風險。
因此,即使可以開發新的基準測試,或者擴展現有的基準測試,我認為情況只會繼續惡化。在我看來,如果目前的 AI 進步速度持續下去,到 2027 年中期,2026 年或更早的基準測試分數可能都無法排除前沿 AI 系統具備危險能力的可能性。
解決方案的另一部分必須來自簡單基準測試評估之外的替代方法。
一種選擇是將重點從基準測試轉向增量研究(uplift studies)。例如,在 2025 年,METR 進行了一系列增量研究,以衡量 AI 對開發者生產力的現實影響,而 AIxBio 則進行了一項 關於生物武器開發的增量研究。雖然這些研究能提供資訊,但在物流執行上也非常具有挑戰性,且需要足夠的時間來完成——例如,AIxBio 的增量研究花了幾個月才完成。鑑於 AI 發展和 AI 能力的快速步伐,這些研究似乎不太可能取代基準測試分數,來為有關最新前沿模型的決策提供資訊。(另見 Luca Righetti 對此問題的看法。)
第二種選擇是進行更多的專家預測或意見徵詢。我們可以繼續擴大由 Forecasting Research Institute 等組織運行的預測研究。或者我們可以針對 Opus 4.6 進行 Anthropic 調查的擴大版、更嚴謹的版本,要求研究人員評估前沿模型的當前能力。這也有其自身的問題:預測研究的問題在於預測者可能對相關主題了解不足,尤其是在 AI 這樣快速發展的領域。同時,外界可能(理所當然地)不信任 AI 開發商對其自身員工進行的意見調查。
第三種選擇是轉向第三方風險評估。與其依賴可能缺乏關鍵資訊的人員所做的預測,或內部進行的意見調查,我們或許可以希望建立一個第三方審計系統,審計員可以獲得公司內部的特權資訊,然後發布其前沿模型能力和風險的高層級摘要。雖然已經有一些原型嘗試,但任何努力仍處於起步階段,且任何此類系統最終仍將取決於公眾對第三方審計員的信任。
但歸根結底,我認為這一切都假設了一個特定的結論:即 AI 系統目前尚未產生足夠的顛覆性或危險性。只要 AI 系統繼續進步,這個假設最終將會失效。在某個時間點,任何對 AI 能力的正確衡量都不會提供一個令人安心的現狀上限,因為它們的能力將會顛覆現狀。
部分答案必須是,我們需要弄清楚當我們生活在一個 AI 發展的自然速度超過我們能輕易衡量的速度的世界時,該怎麼辦。也許答案是放棄。也許答案是採取更激烈的步驟。
我不知道哪種行動方針是正確的,但我認為我們應該停止將「該怎麼辦」的問題視為假設。我懷疑,我們距離這樣一個世界比大多數人意識到的還要近。
- ^(^)為什麼這篇文章關注上限?很大程度上是因為這是 Anthropic、Google DeepMind、OpenAI 等公司採用的 RSP(負責任擴展政策)/ 前沿安全政策式的框架:他們在一定程度上通過指向所述模型所構成風險的上限,來證明其部署模型的決定是合理的。