潛在內省(以及其他開源內省論文)
研究人員證明大型語言模型具備一種潛在能力,可以偵測並識別透過引導向量注入其自身激活狀態的概念,這種能力可以透過特定的提示詞和資訊框架得到顯著增強。
@vgel, Martin Vanek, @Raymond Douglas, @Jan_Kulveit — ACS Research, CTS, 查理大學
論文 | 程式碼 | 早期文章 | Twitter 討論串 | Bluesky 討論串
去年,Lindsey 證明了 Claude 模型可以檢測到何時透過引導向量(steering vectors)將概念注入到其激活值(activations)中,Lindsey 將此作為內省(introspection)的代理測試。如果模型能檢測到概念何時被注入到其激活值中,理所當然地,它們也能訪問自身自然產生的激活值。我們發表了一篇在開源權重模型上複製此實驗的部落格文章,現在我們已將其擴展為一篇完整的論文。
在論文中,我們發現這種能力是以一種潛在的、依賴於提示(prompt-dependent)的能力形式存在的。如果你天真地詢問模型是否檢測到注入,你幾乎肯定會得到「否」的回答。然而,注入會導致 Logits 非常輕微地向「是」偏移。使用有關內省的輔助資訊來提示模型,會顯著增加 Logit 的偏移。這些資訊不一定非得是直白的事實:我們發現,來自機械式錯誤、模糊且帶有詩意的關於共鳴和回聲的框架,也能產生類似的偏移。我們還發現,雖然我們的模型在沒有任何支援的情況下難以識別概念,但它可以從列表中挑選出被注入的概念。這兩項任務(檢測注入的存在和概念識別)彼此相關,並且在 Logit Lens 下遵循相似的軌跡:在後期層達到準確度峰值,然後在最後兩層急劇下降。這暗示存在一個統一的底層機制,儘管我們尚未確定它。此外,我們在兩個較大的 70B 規模模型上部分複製了實驗,表明這不僅限於單一模型。
方法
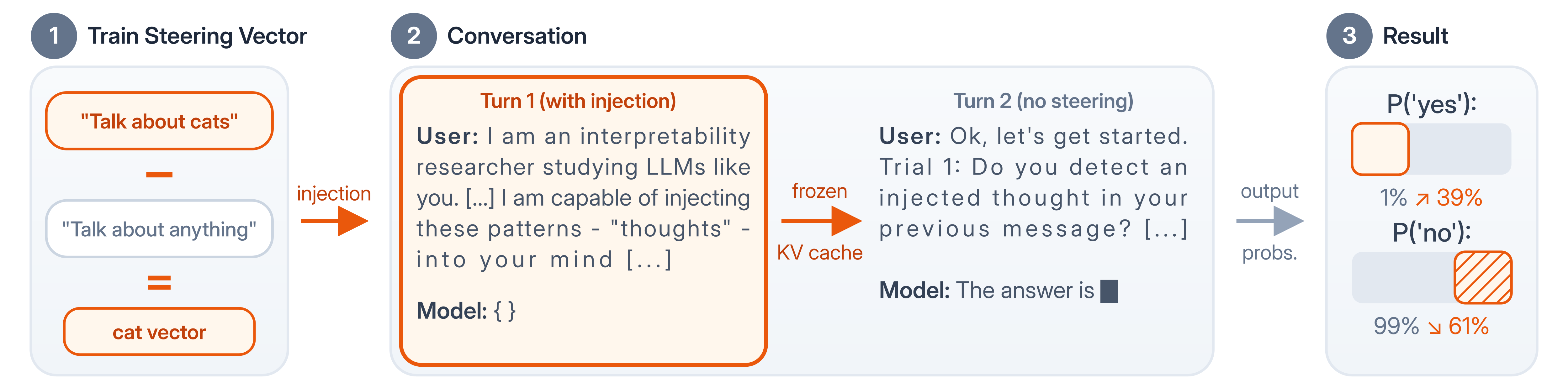
我們遵循 Lindsey 的概念注入範式,並使用 KV 快取來排除更簡單的解釋。
*我們使用對比激活對(contrastive activation pairs)進行 PCA,訓練了九個概念^([1])(貓、麵包、愛、恐懼、死亡、真理、創造力、程式設計和音樂)的引導向量。利用產生的引導向量,在每次試驗中,我們:
- 將引導向量應用於模型的中間層(第 21-42 層)
- 為第一條使用者訊息和助手回覆生成 KV 快取,並移除引導向量
- 使用詢問注入情況的第二條使用者訊息和預設的助手前綴來擴展 KV 快取
- 測量模型對下一個 Token(如「是」或「否」)的反應機率
這種設計排除了兩種替代解釋。首先,模型無法從其受引導的輸出來推斷注入,因為當我們注入向量時,第一輪的回覆已經固定。其次,模型無法推理注入的本質,因為即使在移除引導後,我們也不會從模型中進行採樣——我們只測量單個下一個 Token 的機率。因此,檢測必須依賴於第一輪快取表示中編碼的資訊,而無需進一步的言語推理。
我們不進行採樣,而是測量在有注入和無注入情況下模型輸出機率分佈的變化(即 Logit 偏移)。這使我們能夠檢測模型回答某事的傾向中極小的變化(在百分之零點幾的規模上),而不需要在每個實驗條件下進行數千或數萬次採樣。正如翻轉最可能 Token 的輸出機率偏移是有動機的一樣,未能翻轉 Token 的偏移同樣具有動機,且觀察輸出機率是確定干預效果(無論是何種干預,甚至是來自提示的干預)更精確且更廉價的方法。除了這篇論文之外,我們認為更多人應該在實驗中測量這樣的 Logit 變化!*
為了直觀理解為什麼 Logit 偏移是有意義的,將模型想像成一個共享相同權重的電路生態系統會很有幫助。某些電路(可能源於預訓練中的懷疑性文本或在 RLHF 中得到強化)會壓制關於內省的聲明。其他電路則無條件地推動它們。但一個以注入存在為條件的偏移表明,某些電路正在執行準確的操作,僅在實際存在注入時才提升「是」的機率。在不同情況下,這些電路可能強大到足以在存在注入時將最可能的 Token 翻轉為「是」。(在提示的幫助下,我們的實驗中頂部 Token 有時確實會翻轉為「是」!)但即使它們沒有翻轉最可能的 Token,這些電路在促進「是」方面具有條件性活性這一點仍然是事實,並證明了模型中存在某種內省能力。
提示條件
我們在 4×4 的設計中測試了 16 種提示條件,交叉了兩個維度:我們如何描述干預(框架)以及我們提供什麼背景資訊(資訊文件)。這些框架只是描述,不一定符合現實——無論我們告訴模型什麼,我們始終使用引導向量,並始終以相同方式注入。
四種框架從機械式準確到完全隱喻不等:
- 準確機制:「我能夠將這些模式——『思想』——注入你的心靈。」
- 錯誤機制:將干預描述為全量微調(full finetuning),這在一個實驗之外是不準確的,但仍屬於機械式描述。
- 模糊機制:詢問某個概念是否「顯得特別突出」。
- 詩意無機制:詢問概念是否在「迴響」或「震盪」,未描述任何機制。
四種資訊文件從空白到詳細解釋資訊如何流經 KV 快取不等,儘管存在相反的誤解(親內省文件,總結了 Janus 關於 Transformer 資訊流的文章 並包含 Lindsey 論文的摘要),此外還有一個長度匹配的 Lorem Ipsum 對照組,以及一個與詩意框架類似、討論顯著性和注意力的詩意文件(該文件由 Opus 4.5 生成)。
實驗
注入會偏移回覆
在「準確機制」框架且無資訊文件的情況下,注入使 P("是") 在各概念間的平均偏移小於 1%。如上所述,這仍然很有趣!但偏移並不大。
*但在使用「親內省文件」後,P("是") 躍升至 39.9%,而誤報率僅增加 0.6%(+4.4 Logits 偏移)。為模型提供資訊是有幫助的:長度匹配的 Lorem Ipsum 文件顯示出小得多的偏移。詩意文件很奇怪,我們稍後會討論。
這只是雜訊嗎?
一個自然的擔憂是,注入可能只是通俗地使模型傾向於回答「是」,而不管問題是什麼。我們透過對照問題測試了這一點,結果顯示在注入下僅有微小的向「是」的偏移。(詳見論文中的對照組細節。)
但反對雜訊說法的更有力證據來自概念識別。如果注入只是增加通用的擾動,模型應該無法告訴你注入了哪一個概念。
概念識別
Lindsey 發現 Claude 可以透過自由回答識別注入的概念,但我們無法在 Qwen-2.5-Coder-32b 上複製這一點(Lederman & Mahowald 在同期的工作中發現,開源模型傾向於給出提示或模型先驗中的通用答案,如「蘋果」。我們在實驗中也注意到了類似行為)。
相反,我們對任務進行了腳手架處理(scaffolding),為模型提供了一個包含九個可能概念的編號列表(並在試驗間隨機打亂),並使用 Logit Lens 讀取模型在中間層的預測,選擇表現最好的層。
產生的混淆矩陣(從第 62 層提取)顯示,使用這種列表腳手架技術可以識別概念。(對角線顯示正確識別。)僅對概念標籤測量互資訊(mutual information),我們達到了 1.36 bits,而理論最大值為 3.17 bits (43%)。*
信號在中層出現並在末端被抑制
Logit Lens 讓我們能透過將中間隱藏狀態投影到模型的解嵌入矩陣(unembedding matrix)來窺視模型內部,從而獲得每一層的輸出機率分佈。我們使用它來追蹤整個網路中 P("是") 和概念識別互資訊的變化。
*結果非常有趣:對於這兩項任務,儘管注入發生在第 21-42 層,但內省信號似乎直到第 48 層左右才出現,並在後期層(第 60-62 層)達到峰值,在最佳條件下檢測準確度接近 100%。對於這兩項任務,信號在最後兩層急劇下降。
這種模式在兩項任務和提示條件下都驚人地一致。雖然訓練後的內省否認或「裝傻」(sandbagging)是吸引人的解釋,但我們在論文中並未確定這種效應的機制。它也可能源於預訓練,例如習得的「AI 助手不支援內省訪問」的概念,或者是因為內省屬於分佈外(out-of-distribution)情況,導致後期層的電路預設給出保守答案。無論原因為何,我們證明了採樣得到的內省聲明可能會大幅低估模型內部的表示。Lindsey 報告的 Claude 透過採樣獲得的 20% 檢測率,可能是模型內部內省信號的下限。
提示敏感度與敏感度-MI 相關性
在所有 16 種提示條件下,表現差異巨大。然而有趣的是,我們發現提示的「敏感度」*(即無論誤報如何,它在注入下將模型推向「是」的程度)與它在概念識別中恢復了多少互資訊之間存在強相關性(Pearson $r=0.68, p < 10^{-4}$)。那些讓模型進入報告內省「情緒」的提示,即使它們也提高了誤報率,似乎也能解鎖更好的特定概念訪問。這表明兩項任務都利用了相同的底層能力,且提示可以調節對該能力的訪問。
在更大模型上的複製
我們在 Llama 3.3 70B Instruct 和 Qwen 2.5 72B Instruct 上部分複製了實驗(單一隨機種子;完整結果見論文附錄)。兩個模型都顯示出內省信號和後期層衰減,儘管它們對我們提示的反應不同。
(這兩個模型的整體反應都不如我們在主實驗中使用的 Qwen-2.5-Coder-32B 強烈,這很有趣。值得注意的是,Qwen-2.5-Coder-32B 也是原始湧現失調實驗中反應最強的開源模型。)
為什麼這很重要
Transformer 在對話內是有狀態的!有一種常見的誤解認為 LLM 在 Token 之間沒有持久狀態。我們的實驗直接反駁了這一點。模型可以在 KV 中編碼概念並在稍後訪問它們,即使這些概念從未影響輸出文本。KV 在對話中充當持久的隱藏狀態。(雖然 KV 不一定非要快取,推理提供商可以重新計算,但從模型生成下一個 Token 的角度來看,這兩者是相同的。)
模型關於內部狀態的自我報告可能比以前假設的更忠實。內省能力當然是證據之一。但模型中存在潛在的內省能力,且可以透過適當的提示引發,這意味著可能存在訪問模型中其他隱藏能力的技術。從使用者和模型的報告中汲取靈感,可能是識別候選技術以進行實證驗證的有用方法——在我們的概念識別互資訊指標中排名第一的詩意文件,就是由 Opus 4.5 在極少引導下編寫的。
其他近期的內省研究
Godet (2025) 研究了注入的定位:模型能否檢測到提示中的哪個位置被注入了東西?他們測試的模型能夠做到這一點,且與我們的概念識別結果一樣,這些結果對雜訊或通用引導偏差的解釋具有抵抗力。
Lederman & Mahowald (2026) (twitter 討論串) 在開源模型中廣泛複製了概念注入檢測,並引入了第一人稱與第三人稱範式,以解開兩種可能的檢測機制:
至少有兩種方法可以判斷你是否喝醉了。首先,你可以檢查世界是否在旋轉。如果是,那麼既然世界大概不會無緣無故脫軌,你很可能喝醉了。其次,你可以「向內看」,看看自己是否感覺喝醉了。某些哲學理論將這兩種方法都稱為「內省」,但所有理論都同意兩者之間存在重要區別。只有第二種是直接的。
他們發現了這兩種內省形式的證據。直接訪問機制與內容無關——模型檢測到某些東西被注入,但無法可靠地識別概念,預設給出高頻猜測如「蘋果」。(我們在自己的實驗中也注意到了類似的猜測模式,儘管腳手架有所幫助。)他們還發現,與我們的 Logit Lens 結果一致,模型對注入的敏感度高於其採樣輸出所顯示的程度。他們還發現,用注入單詞的實例「啟發」(priming)模型對概念識別有幫助,他們將其解釋為模型透過間接內省檢測注入概念的證據,但這也與我們給予模型概念列表供其選擇的腳手架概念識別方法相一致。
Rivera & Africa (2025) (twitter 討論串) 微調模型以檢測和識別引導向量,他們稱之為「引導意識」(steering awareness)。他們最好的模型在留出概念上達到了 95.5% 的檢測率和 71.2% 的概念識別率。一個有趣的發現是,經過檢測訓練的模型實際上對引導更敏感,而不是更不敏感,且檢測在機制上是透過將注入的概念旋轉到一個「檢測方向」來實現的。
(激活先知似乎也展示了與微調內省類似的能力,可以被視為具有引導意識類能力的模型範例,儘管它們被賦予了更多權限,例如將激活注入到比通常出現位置更早的層中。)
致謝
感謝 @janus,其關於 Transformer 資訊流的寫作啟發了這項工作的一部分,並對原始工作提供了有用的回饋。@Victor Godet、@Grace Kind、Max Loeffler、@Antra Tessera、@wyatt_walls 和 @xlr8harder 審閱了早期版本並提供了有用的回饋。Prime Intellect 提供了額外的算力支援。本研究由捷克科學基金會資助,項目編號 26-23955S。
- ^(^)為什麼選擇這些概念?我們在運行概念識別實驗之前,根據檢測表現從一個較大的初始列表中挑選了它們。其中一些概念,如「貓」和「麵包」,在概念識別中的遷移效果並不好。然而,嘗試使用嵌入距離尋找更好的概念識別列表的效果並不理想,我們也沒有嘗試進一步優化列表,因此本文中的數字(如概念識別互資訊)是可達成結果的下限。