給 IDA 懷疑論者的行動型認可導向代理人指南
我試圖將認可導向代理人的概念從 IDA 的包袱中解救出來,並透過人類自尊與大腦機制等實例,說明這種願景如何能在不同於 IDA 的 AI 範式中實現,以解決 AI 對齊中的操縱與欺騙問題。
在 2010 年代,Paul Christiano 在 AI 對齊領域建立了一套廣泛的工作體系——參見 「迭代放大」(Iterated Amplification)系列 以獲取截至 2018 年的精選概述。
該計畫的一個基石是一種直覺,即應該有可能構建 「基於行為且受認可導向的智能體」(簡稱「認可導向智能體」,approval-directed agents)。例如,這些 AGI 不會對其人類主管撒謊,因為他們的人類主管不希望他們撒謊,而這些 AGI 只會做人類主管希望他們做的事情。(這聽起來比實際運作要簡單得多!)
該計畫的另一個基石是一套演算法方法,即 迭代蒸餾與放大(Iterated Distillation and Amplification, IDA),據稱這提供了一條實際構建這些認可導向 AI 智能體的路徑。
我(一直以來)都是 IDA 的懷疑論者:我只是不認為那些演算法能運作得很好。^([1])
但我仍然認為「認可導向智能體」的直覺中有些有價值的東西。我們應該小心,不要連同洗澡水一起把嬰兒倒掉。
因此,我在本文中的目標是將「認可導向智能體」的想法從 IDA 的包袱中解救出來。以下是路線圖:
在第一節中,我延續 Abram Demski (2018) 的討論,提供一個關於我們希望從「認可導向智能體」中獲得什麼的高層次圖景。
在第二節中,我將透過一個例子,說明這種願景如何能在 類腦 AGI 的背景下實際體現。類腦 AGI 是另一種 AI 範式,(與 IDA 不同)它肯定可以擴展到超智能。我提供了一個日常例子:擁有崇尚誠實的榜樣/偶像,並相應地對自己作為誠實人的自我形象感到自豪。就大腦演算法而言,我將這種現象與(我稱之為)「認可獎勵」(Approval Reward) 聯繫起來,這是我假設的人類大腦先天強化學習獎勵功能的一個組成部分。
1. 竊取電路、觀測效用智能體與認可導向智能體的簡單與困難問題
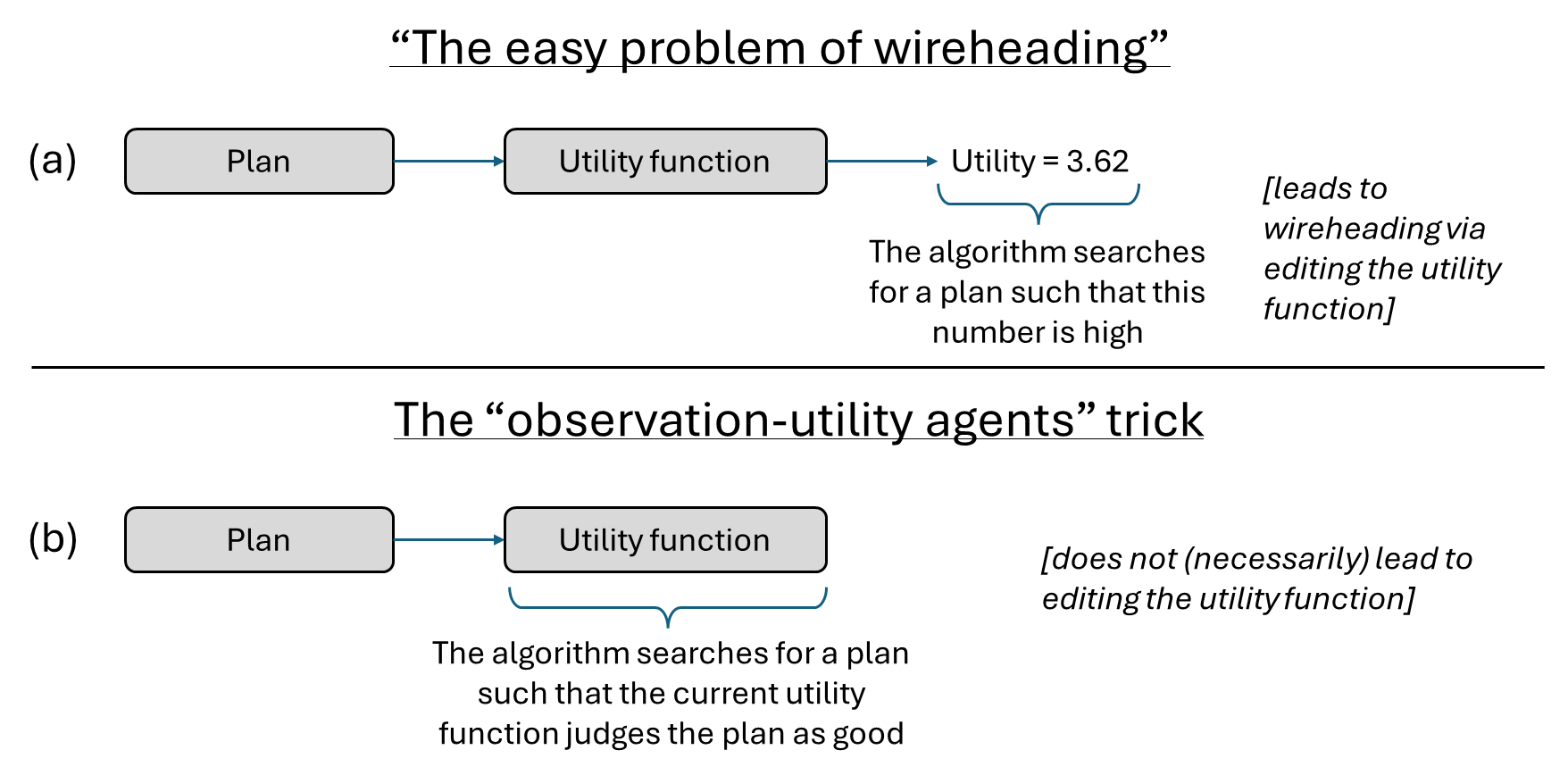
在 「價值的穩定指標 II:環境目標」(2018) 中,Abram Demski 描述了「觀測效用智能體」(observation-utility agents)技巧^([2]),用以解決(他所謂的)「竊取電路(wireheading)的簡單問題」。
(a) 如果我們設定一個智能體來最大化效用函數的輸出,它將會修改效用函數以給出高輸出。(b) 在「觀測效用智能體」中,這個問題透過使用當前的效用函數來評估計畫而得到解決。那麼,「修改效用函數以輸出更高值」的計畫,根據當前(未修改的)效用函數通常會得到低分,因此它不會發生。
Abram 隨後建議,我們可以將 Paul Christiano 的「認可導向智能體」想法視為朝同一方向邁出的第二個類似步驟:
(c) 如果我們設定一個智能體來最大化人類評估的輸出,它將會操縱或欺騙人類以給出高輸出。(d) 在「認可導向智能體」中,這個問題透過使用當前的人類來評估計畫而得到解決。那麼,「洗腦人類」的計畫,根據當前(未被洗腦的)人類通常會得到低分,因此它不會發生。
Abram 將 (c) 失敗模式稱為「竊取電路的困難問題」;它包括所有操縱和欺騙人類的方法。我們希望 (d) 是 (c) 中「竊取電路困難問題」的一個優雅解決方案,就像 (b) 是 (a) 中「竊取電路簡單問題」的優雅解決方案一樣。畢竟,它們在結構上有明顯的相似性。
這在理論上看起來很有希望,但我們如何在實踐中讓它們運作呢?
特別是針對「困難問題」(d 對比 c),Abram 提到了兩個挑戰:
首先, 存在對齊問題。我上面的圖表顯然不能照字面理解,即由一個真實的人類來檢查 AI 的計畫。一方面,即便只是檢查一個計畫,充其量也是困難且耗時的,最壞的情況則是根本不可能,因為計畫將根據 AI 難以理解的世界模型來定義。另一方面,我們可能需要進行數十億或數萬億次的計畫評估步驟,這遠遠超出了我們聘請人類計畫評估員的能力。畢竟,即使是一個普通人在日常生活中,每秒也會產生多個計畫,即每年數百萬個,而如果我們想在 AI 生存風險問題上取得進展,我們將需要大量的人年(person-years)級別的 AGI 勞動力。
因此,在 (d) 中我們需要的不是一個實際的人類主管,而是一些習得的替代品。我們如何獲得它?更重要的是,當習得的替代品與真實情況脫節時會發生什麼?這是第一個問題。
第二, 存在能力(「對齊稅」)問題。在 (c) 中,人類主管位於環境中,但在 (d) 中,人類主管(的習得模仿)被引入了 AI 的思考過程中。因此在 (d) 中,比起 (c),我們似乎深受人類主管的能力和知識所限制。例如,如果 AI 應該發明未來派的奈米技術,它可能會考慮諸如「如果我嘗試探索亞穩態共價電漿流共振會怎樣?」之類的計畫。遺憾的是,我們不能依賴當前人類主管(的習得模仿)來評估該計畫,因為當前人類主管根本不知道「亞穩態共價電漿流共振」到底是什麼意思。那麼,這該如何運作?
Paul Christiano 在 2010 年代與 IDA 相關的研究 提出了各種解決這兩個問題的想法,但我基本上不買帳——稍後會詳細說明。但這裡有一個關於該問題的截然不同的視角:
2. 如果人類慾望是「觀測效用智能體」技巧的一個案例研究,那麼人類的自豪感就是「認可導向智能體」技巧的一個案例研究
對於「竊取電路的簡單問題」(b 對比 a),我在 入門系列 §9.5.2 (2022) 中論證過,人類大腦在上述意義上或多或少是「觀測效用智能體」。(事實上,如果有選擇的話,很多大腦都不會選擇竊取電路。)
那麼,四年後的現在,我提議人類大腦也提供了「認可導向智能體」技巧的一個例證——具體來說,就是當人類出於對自我形象的自豪感而行動時。
考慮一個以誠實為榮的人。當他們想到自己是誠實的時候,他們會感到自豪,這伴隨著大腦中立即噴發出的愉悅感。我認為這種愉悅感的噴發是一種先天驅動力(又稱初級獎勵)的結果,我稱之為「認可獎勵」。關於這種日常現象的更多內容,請參見我的文章 社會驅動力 2:「認可獎勵」,從規範執行到追求地位 (2025)(特別是 §3);關於我認為這種機制在大腦中如何運作的詳細細節(即大腦如何知道哪些想法/計畫值得給予認可獎勵?),請參見我的文章 人類社會本能的神經科學:草圖 (2024)。^([3])
我認為,如果一個人(稱他為 Alex)對自己的誠實感到自豪,那麼其上游至少有一個 Alex 非常崇拜的人,那個人認為誠實是好的,而不誠實是壞的。^([4]) 我為這個熱愛誠實且被 Alex 崇拜的人取名為「Hugh」,並假設他們目前是一個真實存在的人(而不是卡通人物、耶穌等)。
Alex 非常希望在現實生活中獲得 Hugh 的實際認可——事實上,從你非常崇拜的人那裡得到幾句認可的話,可能是一次改變人生的經歷。^([5]) 但 Alex 不會想透過欺騙手段讓 Hugh 誤以為 Alex 很誠實,從而獲得 Hugh 的認可!
是的,欺騙 Hugh 的計畫在未來實現時會給 Hugh 留下深刻印象。但僅僅是考慮這個計畫,對於想像中的 Hugh 來說,現在就是令人震驚的,因為當 Alex 思考該做什麼時,想像中的 Hugh 就住在 Alex 的腦海裡。所以這個欺騙計畫看起來很糟糕,Alex 不會去做。^([6])
因此,想像中的 Hugh 已經插入了 Alex 優化循環中的計畫評估位置,而這正在起作用,以防止操縱真實 Hugh 的策略!這就像上面圖表中的 (d) 一樣!以下是相應的圖表:
人類心理中與上述 (c-d) 圖表平行的一個真實現象。如果你的偶像 Hugh 珍視誠實,那麼你不太可能透過欺騙手段讓他相信你是個誠實的人,即使你非常有信心能成功,而且即使你非常在意他對你的看法。
所以現在我們不僅有了「觀測效用智能體」技巧的人類類比,還有「認可導向智能體」技巧的人類類比。這太棒了!這將這些想法從「聽起來可能合理的事情」提升為「在實踐中顯然與強大的通用智能相容的計畫」,而且我覺得自己有能力在細節層面上對其進行詳細分析。
因此,如果上述動態是人類大腦中可能發生的事情,那麼類腦 AGI 中或許也有可能發生類似的事情!例如,也許「Alex」代表 AI,「Hugh」代表人類主管,而「誠實」代表(或許是)誠實、忠誠、服從、正直、廉潔等更廣泛的集合(參見 Paul 關於可修正性的廣義概念)。
……然後呢?從這個人類類比中,我們究竟能學到什麼可能成功或失敗的地方?有沒有辦法解決上面 §1 中列出的那兩個問題?這裡面是否存在一條通往安全且有益的 AGI 的端到端路徑?
我的回答是:我不知道! 希望在未來的文章中能有更多相關內容。 :-)
感謝 Seth Herd 對早期草稿提出的批評性意見。*
- ^(^) 更具體地說:遲早,無論以何種方式,都會有人發明出極端超智能的 AI,而那個 AI 可能會殺死所有人。這是我感興趣的大問題。我認為這些 IDA AI 的力量不足以在該問題或其解決方案中發揮重要作用。它們充其量只是作為背景背景,類似於互聯網搜尋引擎、PyTorch 或第三次世界大戰等。
……為什麼我認為 IDA 不會比這更強大?嗯,我在早期的草稿中有一整節討論這個問題,但它變得很長,感覺像是離題,所以我把它刪掉了。但我後來重新包裝了其中的一部分,並將其變成了一篇獨立的文章:你無法透過模仿學習來學會如何持續學習。總之,如果你閱讀那個連結,以及 Eliezer 在此處 和 John Wentworth 在此處 的早期討論,你基本上就能拼湊出我的觀點要旨。
-
^(^) Abram 將這個技巧歸功於 Daniel Dewey 2011,後者又將其歸功於 Nick Hay 2005,但我沒讀過後者。隨後在 2019 年,Everitt、Hutter、Kumar 和 Krakovna 對這一想法進行了非常詳細的分析,稱之為「當前獎勵函數(current-RF)優化」——參見 arxiv 連結、部落格版本、LessWrong 轉載。
-
^(^) 另見:關於「對齊很難」的論述與人類直覺格格不入(反之亦然)的 6 個原因 (2025),以獲取關於認可獎勵的更多視角。
-
^(^) 當然,真正重要的是 Alex 相信他的偶像覺得誠實是重要且好的。他們是否真的這麼想是另一回事。正如俗話所說,「永遠不要見你的英雄」。
-
^(^) 參見 導師制、管理與神秘的老巫師,以及此處「感覺良好」電子郵件資料夾軼事中的大多數例子。
-
^(^) 或者也許他還是會去做!但我的觀點是:這是一個真實的考量因素,它促使 Alex 傾向於不喜歡那個計畫。如果他還是執行了計畫,那一定是因為有其他抵消性的考量因素勝過了它。