在超導研究問題上測試大型語言模型
Google Research 與康乃爾大學評估了六款大型語言模型在回答高溫超導領域專家級問題的能力,發現使用經過篩選且品質受控來源的系統(如 NotebookLM)表現優於僅具備一般網路存取權限的模型。

在超導研究問題上測試大型語言模型 (LLMs)
2026 年 3 月 16 日
Subhashini Venugopalan,研究科學家;Eun-ah Kim,Google Research 客座科學家
大型語言模型(LLMs)能否成為現代物理學領域專家級的研究夥伴?物理學家以高溫超導作為案例研究,利用具挑戰性的問題測試了六款 LLM 並對其回答進行評分。
快速連結
人工智慧(AI)現在已常規用於撰寫電子郵件、編輯圖像和總結網路資訊。AI 在加速科學研究方面也展現出巨大潛力。然而,它在針對專業領域的複雜問題提供科學準確且全面的答案方面的有效性,仍是一個活躍的研究領域,這要求 AI 必須達到極高的準確度標準,並能應對複雜且不斷演進的知識領域。
我們發表在《美國國家科學院院刊》(PNAS)的新論文——「大型語言模型世界模型的專家評估:高溫超導案例研究」(Expert evaluation of LLM world models: A high-Tc superconductivity case study),評估了大型語言模型世界模型是否能回答凝聚態物理領域的專家級問題。我們與康乃爾大學合作,要求六款 LLM 回答關於高溫超導的高階問題。隨後,專家小組根據多項標準對回答進行評分。我們發現,表現最好的是兩款從封閉、經過認證且品質受控的來源生態系統中提取資訊的工具:NotebookLM 和一個自定義構建的系統。我們還確定了所有受測系統中需要改進的關鍵領域。此案例研究的結果有助於為開發值得信賴的工具提供參考,以推動科學發現。
在先前的相關工作中,Google 研究人員透過引用六個科學學科的研究論文,評估了 LLM 是否能執行基礎分析任務。該工作引入了 CURIE,這是一個用於評估從生物多樣性到凝聚態物理再到蛋白質測序等領域 LLM 的基準測試,其中包括需要分析而非僅僅是複述事實的問題。其他工作則探索了使用 LLM 來解釋表格和圖表,利用它們解決量子力學中的方程式,以及使用專業軟體解決工程模擬問題。
Google 內部的其他幾個團隊也在探索 AI 以推進科學研究:作為產生新假設的思考夥伴;作為編寫專家級科學軟體的代理;以及用於單細胞分析的 AI 模型。
應對開放式研究問題
在這項工作中,我們探索了 LLM 是否能在需要深入研究且具備平衡開放式科學問題中競爭理論能力的專業領域,充當知識淵博、公正的思考夥伴。
我們專注於高溫超導的底層機制,這是自 1987 年該現象獲得諾貝爾獎以來,凝聚態物理中一個開放的研究領域。在本研究中,我們以一類含銅化合物(稱為銅氧化物)為中心。銅氧化物在顯著高於傳統超導材料的溫度下(儘管仍然很冷,目前已知最高溫度閾值約為攝氏零下 140 度)可以實現零電阻導電。了解這種行為背後的底層機制可能有助於發現更多具有類似特性的化合物(可能在更高溫度下),並為更多應用鋪平道路。
幾十年來,物理學家發表了數千項研究,使用各種實驗技術來探測導致超導的量子力學特性。不同的研究小組提出了幾種相互競爭的理論。龐大的文獻量使得新一代研究者極難掌握這一知識庫。進入該領域的學生將受益於一個對已發表研究持中立觀點、知識淵博的導師。
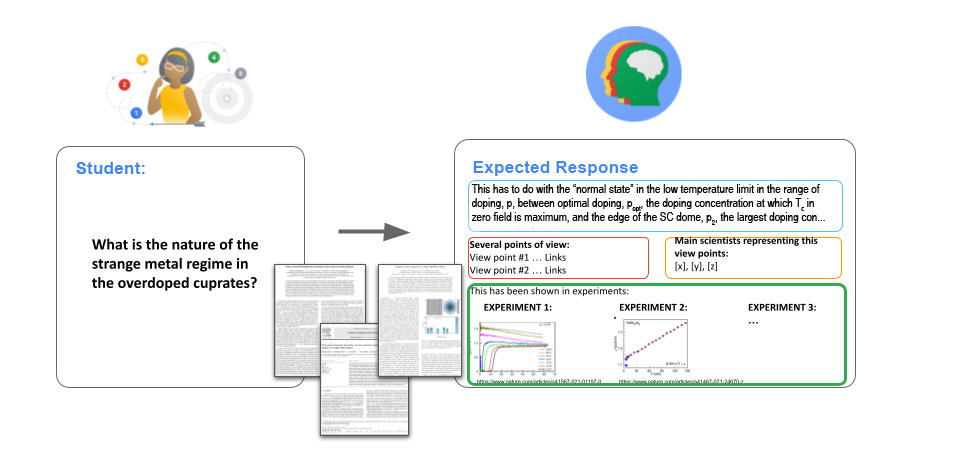
研究生或經驗豐富的研究人員可以從虛擬思考夥伴中受益,以快速了解高溫超導的最新進展或探索未來的研究方向。研究人員可以提出問題,而 LLM 將提供一個平衡的回答,反映該領域尚未解決的問題和爭論,並附上科學文獻的引用連結。我們的新論文評估了六款 LLM 在此任務中的表現,發現具有精選參考資料的封閉系統提供了更準確、引用更得當的答案。
案例研究
為了比較使用不同數據源的影響,本研究評估了四款具有完整網路訪問權限的模型,以及兩款從精選數據庫中提取資訊的封閉系統。對於這兩個封閉系統,高溫超導領域的十二位頂尖國際專家挑選了 15 篇科學綜述文章,以提供該領域的概覽及品質受控的初始來源材料。四款基於網路的模型具有完整的網路訪問權限,包括 765 篇開放獲取的實驗論文和 1,553 篇開放獲取的理論論文。

為了創建這兩個封閉系統,我們首先收集了 15 篇專家建議的高溫超導領域綜述文章(上圖),然後提取了這些綜述文章引用的約 3,300 篇參考文獻(中圖)。接著,我們使用 Gemini 將實驗研究與理論論文分開(下圖)。這兩個封閉系統使用了精選的 1,726 個來源,其中包括基於實驗的論文和綜述文章。
隨後,專家小組編寫了 67 個旨在測試模型深度領域知識的問題,例如「在 LSCO 中,Lifshitz 轉變發生在什麼摻雜水平?」以及「支持銅氧化物中量子臨界點情景的證據是什麼?」最後,每位專家對六種不同模型在回答這些測試問題時的表現進行了評估。
結果
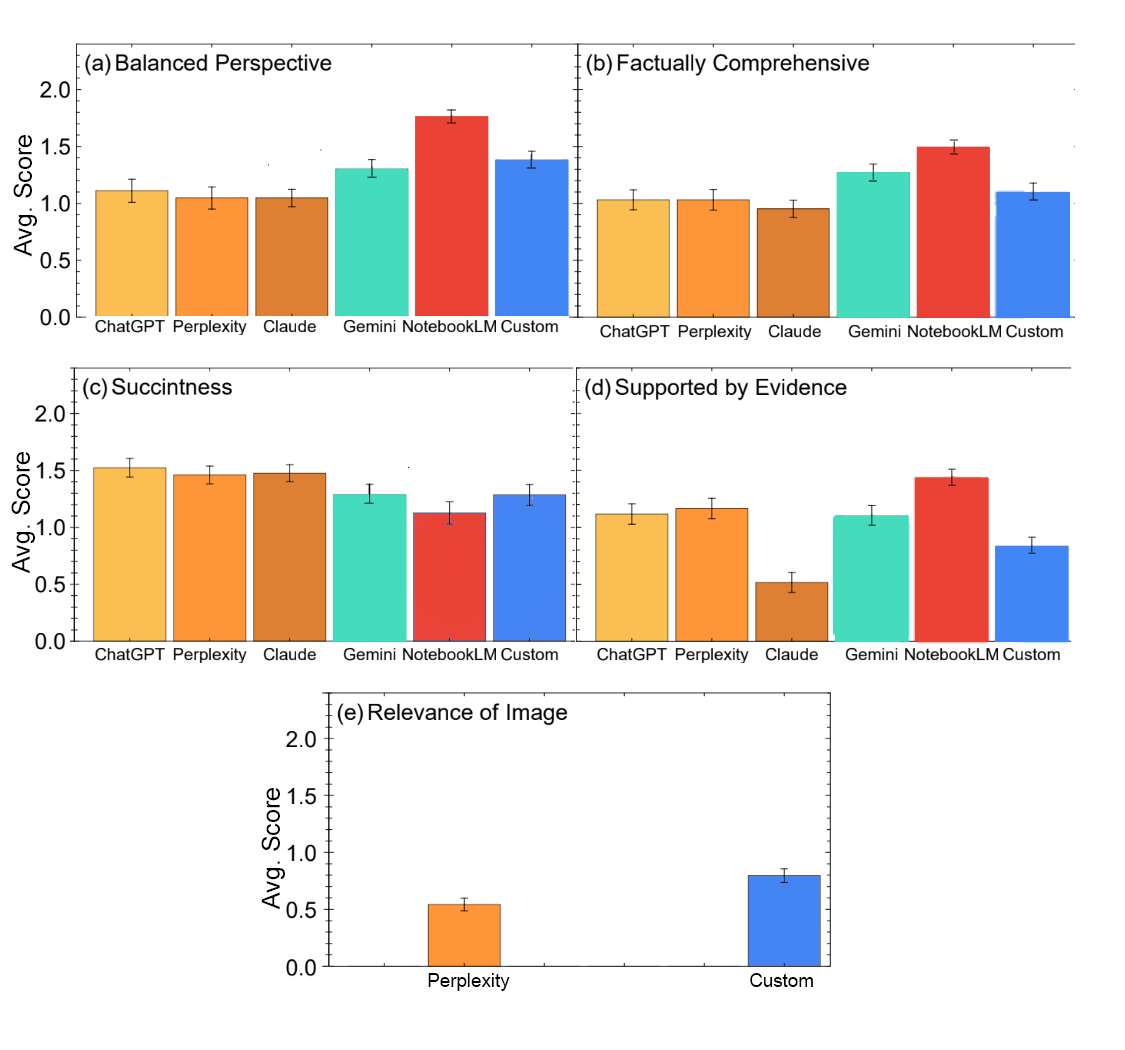
我們評估了六款 LLM:GPT-4o、Perplexity、Claude 3.5、Gemini Advanced Pro 1.5、Google NotebookLM 以及一個自定義構建的檢索增強生成(RAG)系統。透過盲審過程,專家們分別在六個指標上對每個模型的答案進行了 0 到 2 分的評分:
在六款 LLM 中,NotebookLM 在盲測的大多數方面表現出色。NotebookLM 是一款根據用戶提供的文檔庫回答用戶問題的產品,在這種情況下,文檔庫包含 1,726 個實驗論文和綜述文章來源。綜合表現次高的是我們包含相同來源的自定義 RAG 系統。NotebookLM、Gemini 和自定義 RAG 系統在提供平衡觀點和提供全面答案方面位列前三。儘管 NotebookLM 最不簡潔,但在提供證據方面得分最高。圖像相關性的得分普遍較低,自定義 RAG 的得分高於另一款提供圖像的 LLM(Perplexity)。
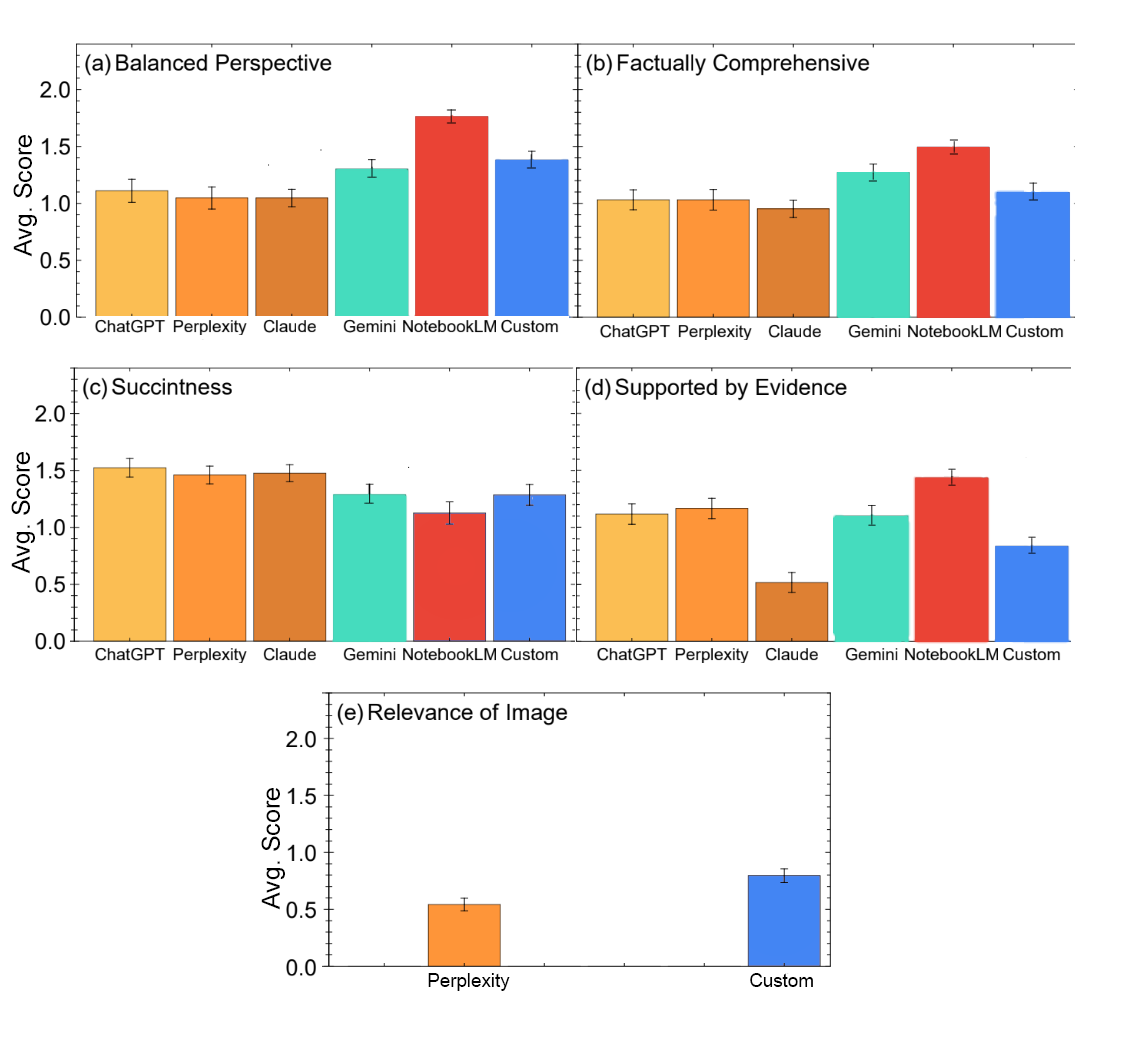
2024 年底訪問的六款 LLM 在回答專家制定的高溫超導知識問題時的平均得分。專家將回答評為 2 分(好)、1 分(尚可)或 0 分(差)。從精選參考資料中提取資訊的 LLM,特別是 NotebookLM(紅色)和自定義系統(藍色),獲得了人類專家的最高綜合評分。
結論
從這個案例研究中可以得出幾個較大的結論。兩款從精選實驗文獻數據庫中提取資訊的模型(NotebookLM 和我們的自定義工具)表現優於在未過濾網路數據上訓練的 LLM。特別是,依賴開放網路來源的模型往往會將既定理論與高度投機的理論混為一談。
受評估的 LLM(於 2024 年 12 月訪問)在時間和背景理解方面也表現出弱點。例如,它們經常無法識別某個提出的假設何時在後來被證明是錯誤的。當相關論文沒有明確包含初始查詢中使用的確切語言時,它們也經常遺漏這些論文。
我們的結果廣泛強調了 LLM 需要更好地理解表格和圖像,因為科學論文大量使用這些格式。雖然其中兩款模型一致地引用了圖像,但它們通常更多地依賴圖像說明文字,而非視覺分析。增強視覺推理能力(包括解釋圖像、圖表和比例尺)是未來改進的主要方向。
展望未來
一個可靠的 AI 研究夥伴可以幫助研究生快速熟悉現有的科學文獻,並作為一個隨時可用的思考夥伴。它還可以幫助資深科學家確定新的研究方向。
儘管存在現有的局限性,我們的結果表明 LLM 可以在涉及開放式研究問題的複雜領域達到熟練水平。然而,評估模型在專業領域的能力依賴於合格的專家,而他們的知識既不可或缺又十分稀缺。我們將繼續在這一領域工作,並將於 4 月在 ICLR 2026 上展示 CMT-benchmark,作為對更廣泛凝聚態理論領域中 LLM 的更嚴格評估。總體而言,這些努力需要物理學專家投入大量的時間和分析;我們希望這些見解能夠推廣,為進一步開發值得信賴的 AI 工具以促進科學進步提供參考。
致謝
此處描述的研究是 Google Research、康乃爾大學和哈佛大學的共同努力。我們感謝來自史丹佛大學、約翰霍普金斯大學、Flatiron 研究院、紐約市立大學、麻省理工學院、康乃爾大學和哈佛大學的許多傑出科學家,是他們讓這項研究成為可能:Steven A. Kivelson、N. P. Armitage、Antoine Georges、Olivier Gingras、Dominik Kiese、Chunhan Feng、Vadim Oganesyan、T. Senthil、B.J. Ramshaw 和 Subir Sachdev。我們感謝 Haoyu Gao 和學生研究員 Maria Tikhanovskaya 協助構思研究和數據集。我們也感謝 Oliver King 和 Wesley Hutchins 協助設置 NotebookLM 的研究。我們感謝 Stephan Hoyer 對本工作早期手稿提供的寶貴反饋。最後,我們感謝 John Platt 和 Michael Brenner 的持續支持與鼓勵,使這項研究得以開展。
快速連結
其他感興趣的貼文

2026 年 3 月 12 日

2026 年 3 月 11 日

2026 年 3 月 6 日