平均場序列:導論
本篇文章介紹了平均場理論,將其作為理解神經網路內部機制的一種強大框架,為可解釋性研究提供了一個比高斯過程極限更具表達能力的替代方案。
這是 Dmitry 和 Lauren 計劃中關於平均場理論(Mean Field Theory)系列文章的第一篇(本篇由 Dmitry 撰寫,並參考了 Lauren 的大量意見;文章分為兩部分,第二部分由兩人共同撰寫)。這些文章結合了科普解說與一些原創研究/實驗。
這些文章的目標是解釋一種理解和詮釋模型內部機制的途徑,我們非正式地稱之為「平均場理論」或 MFT。在文獻中,最接近的術語是「自適應平均場理論」(adaptive mean field theory)。我們將廣義地使用這個術語,來指代將多體熱力學方法應用於神經網路可解釋性的一系列新興研究。這包括關於貝氏學習(Bayesian learning)與動力學(SGD)的工作,以及更廣泛的「神經網路場論」(NNFT)背景下的研究。Dmitry 最近關於學習稀疏去噪的文章,在啟發法上也符合這個圖景(更準確地說,是其微小的擴展)。
我們在 Principles of Intelligence(原 PIBBSS)的團隊認為,這種關於可解釋性的觀點仍被高度忽視,應該得到更好的理解,且這些想法應更多地應用於可解釋性的思考與工具中。
我們希望以一種更易於被可解釋性研究人員吸收和使用的、對用戶友好的方式來闡述這一理論。本篇特別與論文「Mitigating the Curse of Detail: Scaling Arguments for Feature Learning and Sample Complexity」密切相關。實驗部分是全新的。
我們所說的平均場理論是指什麼
平均場理論是一個含義模糊的術語,但至少在前幾篇文章中,我們將重點放在「自適應平均場理論」(例如參考這篇論文,該文是為物理學讀者撰寫的)。這是一種關於無限寬度系統的理論,它不同於更經典(且如下所述,表現力較弱)的神經切線核(NTK)形式化方法及相關的高斯過程(Gaussian Process)背景。歸根結底,這是一套關於神經元的理論(神經元被視為類似氣體中的粒子)。雖然理論中的每個單一神經元都是相對簡單的對象,但平均場圖景中的神經元允許產生湧現的大規模行為(有時被識別為「特徵」),使我們能夠在先驗的「單神經元理論」中看到複雜的交互作用和電路。隨著本篇(以及本系列)的進展,希望這些晦澀的詞彙能得到更好的理解。
為什麼需要 MFT
我們最終希望對神經網路內部的理解達到能夠穩健地(且理想情況下,在某種意義上是「安全地」)解釋神經網路為何做出特定決策的程度。因此,有人可能會說,這意味著我們應該只關心直接應用於真實模型的理論——有限寬度、大深度等。雖然這很合理,但任何解釋最終都必須依賴於某種理想化。當我們說「我們已經解釋了這個機制」時,我們是指存在某種柏拉圖式的裝置或理想化模型,它具有一個「我們能理解」的機制,而真實模型的行為能被這種柏拉圖式理想化很好地解釋。因此,在可解釋性方面取得進展需要累積一套理想化和簡化模型的百科全書(或食譜)。著名的 SAE 方法論就是基於嘗試將真實神經網路套入繼承自壓縮感知(應用數學的一個領域)的理想化模型。正如我們將在下面解釋的,如果我們從未有過 Neel Nanda 對模加法(modular addition)算法的解釋,我們也可以通過對相關的無限寬度模型應用平均場分析來「免費」獲得它。事實上,兩者使用的是相同的柏拉圖式理想化^([1])。因此,對理論的一種看法是將其視為有用模型的來源,然後可以將其應用於更現實的場景(經過適當修改,且在可解釋性的「標準模型」理論出現之前,必然是不完全的)。有用的理論應該足夠簡單,以便進行數學分析(可能需要一些簡化、假設等),同時又足夠豐富,能啟發新的結構。我們認為平均場理論(及其相關理論)非常適合承擔這一角色。
簡短的 FAQ 部分
「關於 MFT 的常見問題」是一個大話題,可以獨立成篇。但在深入進行更具技術性的介紹之前,我們應該處理幾個經常出現的標準問題,特別是關於 MFT 與其他更知名的無限寬度極限之間的比較。
- 無限寬度難道不意味著我們處於 NTK(或更廣泛的高斯過程)體制中嗎? 對無限寬度神經網路的最初分析是在所謂的 NTK 體制下進行的,在該體制中,模型除了最後一層(執行線性回歸)外,其餘所有層都會「凍結」在其先驗/初始化狀態。這是一個非常深刻的圖景,例如足以學習 MNIST。但這一系列的方法表現出與現實網路極其不同的行為(特別是早期神經元的凍結),且在無法通過聚類和線性回歸組合解決的問題上,它們的泛化能力要差得多(MNIST 就是這類問題的一個例子)。例如,這些方法在模加法中只能學到記憶電路(至少在已知體制下),更糟糕的是,已知對於 SGD 顯然可學習的算法,這些技術需要指數級的訓練數據和複雜度(參見躍遷複雜度論文)——這意味著這些技術與這些設定根本不相容(更廣泛地說,所謂的「組合式」模型——即具有多個串行步驟、模型往往需要深度來處理的模型——在這種體制下也有類似的失敗)。這可以通過包含所謂的「修正項」來部分改善,但這些修正項僅在高斯過程本身表現良好時才有效,且無法緩解指數複雜度問題。請注意,高斯過程圖景作為啟發式基準是有用的。特別是它對縮放指數做出了一些與實驗一致的預測(並與 muP 形式化相關)。**
事實證明,高斯極限缺乏表現力並非因為其具有無限寬度,而是歸因於對如何取無限極限的某種選擇(特別是如何縮放損失函數中的權重正則化項)。我們將會看到,不同的極限和縮放會產生顯著更強的表現行為,我們將 MFT 作為這些行為的統稱。(這些不同的極限通常也更難處理,至少在精確的數學分析方面:高斯過程極限在某種程度上以更容易的數學補償了其表現力的不足。) - 平均場理論難道不是一種貝氏學習理論嗎?這難道不現實嗎? 在物理學背景下(如 MFT、高斯過程學習等),貝氏學習通常在理論上更容易處理,我們將在這裡解釋貝氏學習的預測(並通過回火實驗驗證)。然而,SGD 學習的平均場版本確實存在,被稱為「動力學平均場理論」(DMFT)(它在高斯過程背景下擴展了 NTK)。可能更相關的是,貝氏學習實驗經常發現與基於梯度的法方相似的結構(且通常更容易分析)。這在 Timaeus 小組的實證結果中得到了特別好的證明。
- 平均場理論是關於淺層模型的理論嗎? 大多數現有的平均場理論論文是在 2 層神經網路(即 2 個線性層,1 個非線性層)的背景下工作的。然而,該理論有一個完全通用且經實驗證明的穩健擴展,可以應用於更多層數(例如參考這個系列講座),我們將在這裡研究這類模型。事實上,平均場理論可以模擬任意深度的機制——但它在淺層模型(或深層模型中的淺層機制)中效果最好,對於模擬強烈依賴深度的現象可能用處較小。
- 有什麼我應該知道的平均場理論的成功案例嗎? 很高興你問了!大多數人都知道模加法任務,這最初由 Neel Nanda 等人的大悟(grokking)論文進行了機制性解釋。該解釋是啟發式的:它表明模型展現出使用了一種精妙且出人意料的三角函數技巧的特徵。它還在泛化和記憶之間進行了突然的轉變,讓人聯想到相變。一個更具野心的任務(在可解釋性社群中曾被認為太難處理)是精確理解模型在任何表現出泛化/大悟的設定中,在神經元層級上學到了什麼。由於模型具有固有的隨機性(來自初始化,有時來自 SGD),這本質上是一個統計任務:解釋學習模型權重的機率分佈(至少達到適當的精度),這通常被認為是非常困難的。因此,令可解釋性從業者感到驚訝的是,事實上在某種背景下這已經實現了。**
在論文「Grokking as a First-order Phase Transition in Two Layer Networks」中,Rubin、Seroussi 和 Ringel 為貝氏學習設定下的模加法網路構建了一個完整的解釋(並經過極高精度的實驗驗證)(與 Neel Nanda 的方法還有其他一些差異,最顯著的是損失函數的選擇,但該方法的變體也可以擴展到這些情況)。分佈首先在無限寬度下被理解,然後被證明在適當體制下的現實(但大寬度)網路中同樣適用。當將自適應平均場理論方法應用於此任務時,傅立葉模式和三角函數機制自然地作為理論的輸出而出現——此外,它們在統計分佈層級上得到了完整解釋(即我們擁有一個在統計物理意義上理解的、達到適當精度的「每個神經元具體做什麼」的完整模型)。特別有趣的是,該模型解釋了記憶(等同於類高斯過程行為)與泛化(本質上是平均場)之間類似大悟的相變,並預測了發生相變的數據比例(這是預測 SGD 訓練的神經網路何時發生大悟的分佈的貝氏學習模擬)。這種現象是熱力學意義上真正的相變。 - 真實模型是處於平均場體制、高斯過程體制,還是其他體制? 這是一個有趣的問題,其答案是「這個問題本身沒有意義」。體制之間的區別適用於無限寬度的網路,即一個完全非標準的設定。人們可以證明嚴格的結論,大意是如果寬度與訓練數據相比(在某些巨大界限下足夠龐大),模型保證會在其中一種體制中學習。然而,沒有真實模型是那麼龐大的。相反,某些現象和某些機制可以被觀察到(實驗上或理論上)從無限網路擴展到有限寬度的網路。有時這些看起來更像平均場現象,有時看起來像高斯過程現象。例如,在某種意義上 MNIST 是「類 GP」的(GP 代表高斯過程)。而正如我們上面解釋的,模加法中的電路完全可以由 MFT 極限來解釋。
理論導論
背景(與前景)
在物理學中,人們經常觀察具有巨大且穩定背景的系統。行星對太陽、電子對質子、弱交互作用的觀察者對被觀察的大型系統。在這些設定中,「背景」是大型系統,而「前景」或「測試系統」是被研究的小型系統。在這些情況下,背景系統可能是固定的,或者可能正在進行某種運動(如太陽繞銀河系中心運動),但重要的理想化是它不會對觀察者/測試系統做出反應。事實上,地球正在對太陽施加引力(而且在著名的量子力學中,觀察總是會在量子層級影響系統)。但這些「反向」效應很小,因此在很好的近似下,我們可以將太陽視為在做其自身「穩定」的事情,而地球則在經歷強烈依賴於太陽的物理過程。
自洽性
雖然通常大型「背景」是與觀察者的小型測試系統完全分開的系統,但有時將測試系統視為背景的一小部分是非常有用的。例如:大型背景系統可能是一杯水,而小型測試系統可能是某個位置的一小滴水。在這裡,雖然技術上整杯水包含了這一小滴「測試」部分,但水中大規模的行為(波浪等)在相關精度內並不在意測試部分是否被改變或移除(至少如果它足夠小的話)。但這一小滴水絕對在意大規模的行為(波浪、渦流或流動等),就水滴在意事物的程度而言。
同樣地(且以密切相關的方式),「經濟」是一個包含你家鄰里麵包店的巨大系統。麵包店可以被視為一個小的「測試系統」:它受經濟影響。如果房價上漲或經濟崩潰,它可能會倒閉。但經濟(至少在一階近似下)不受這家麵包店的影響。它或許受全球所有麵包店總和的影響,但如果這家特定的麵包店因為某些隨機現象(例如首席麵包師退休)而倒閉,這不會對經濟產生巨大影響。
這種觀點非常有用,因為它引入了「自洽性」(self-consistency)的概念。
應用於此背景下的自洽性源於以下一對直覺:
- 每個小組件的行為由背景(統計地)決定
- 背景的行為是其所有小組件的總和。
如果這兩個假設都成立,那麼這兩個觀察結果(當轉化為方程時)通常足以完全確定系統。事實上,你擁有兩個函數關係^([2]):
$$ \text{背景} \xrightarrow{f} \text{組件行為} $$
$$ \text{組件行為的分佈} \xrightarrow{b} \text{背景} $$
將兩者結合,我們得到組合的「自洽」方程:
$$ \text{背景} = b \circ f(\text{背景}) $$
這意味著背景場滿足組合函數 $b \circ f$ 的不動點方程。事實證明,在許多感興趣的情況下,它具有唯一解。自洽方程的一個經典例子是供需曲線平衡。在這裡,背景是一個單一的數字(商品價格),而測試系統是單個消費者購買或單個生產者出售的意願,作為價格的函數(實際構成單個消費者/生產者的「微小組件」被抽象掉了,曲線代表平均激勵)。
在上述假設中,假設 1 是最成問題的。將每個組件視為由某種「大規模」穩定係統決定,需要進行適當的解釋(特別是這種關係通常是統計性的:例如,即使「經濟」保持不變,特定鄰里的麵包店數量也會因人們退休/搬遷等而波動;同樣,太陽的每一部分都會對來自其他部分的磁場/引力場做出反應,但是在一種統計或熱力學意義上)。有時局部或所謂的「湧現」效應會打破這種方向性關係(許多有趣的熱力學系統,如二維伊辛模型,正是因為這種背景而變得有趣)。但令人驚訝的是(至少在適當的形式化下),將前景視為完全由背景(在統計意義上)決定的近似通常是穩健的。例如,如果我們正在模擬太陽,過於粗略地觀察「背景系統」(例如僅視為整個太陽的質量 + 電磁場 + 溫度)是不夠的。但相反,我們可以將「背景系統」視為許多局部系統的巨大聯集,可能由幾公尺見方的塊組成。這些在比原子(或微觀塊)大得多的意義上仍然是「大」的,但研究它們的行為(在適當的抽象中)提供了足夠的分辨率來極好地模擬太陽。同樣,我們不能將單一的供需曲線應用於整個經濟(不同地方的麵包成本不同)。但在適當的背景下(對於像石油這樣的同質產品,以及在經濟大致均勻但不受單一站點主導的「局部經濟」層級上),自洽性是一個相當不錯的模型。
在許多設定中,「假設 1」成立的程度與連通性的概念有關。在太陽的磁電漿中,一個粒子感受到的磁場是由數十億個附近粒子累積而成的——因此交互作用圖是極度連通的。在石油經濟中,每個消費者通常可以在開車可達的範圍內選擇數十個附近的加油站。然而,其他設定(如伊辛模型,或稀有且難以運輸的商品市場)則不能單純地由自洽性很好地模擬。
在物理學中,由自洽方程(耦合的背景和前景系統)很好地模擬的系統通常被稱為平均場設定。統計物理學的一個巨大勝利是使具有局部/湧現現象的情況「表現得像」平均場理論一樣好——重整化(renormalization)是這裡的一個基本工具,大多數從統計物理角度介紹重整化的教科書往往從討論平均場方法開始。但直接屬於平均場的設定(例如由於高度連通或高維度)是特別優美、易於研究的。
神經網路與平均場
神經網路是物理系統。這是一句廢話——任何具有統計特性的事物都可以使用物理工具包進行研究(在許多方面,統計物理學只是使用不同術語的統計學)。事實上,真實的神經網路極其複雜,如果存在某種意義可以將它們局部拆解為背景-前景的自洽性,這些自洽性本身一定極其複雜,且可能依賴於複雜的工具來識別(這也是我們開展重整化議程的原因之一)。
但事實證明,在某些設定和架構中,神經網路被具有高連通性的系統模擬得極好——原因很直觀,正是因為它們在神經元層級上是高度連通的(通常是全連接)(請注意,並非「全連接」的架構——例如 CNN——有時仍具有使其從物理角度看是「高度連通」的特性)。
神經網路的平均場背景與前景
在神經網路 MFT 中,前景(或「系統」/「觀察者」)的抽象是一個神經元。這通常是某一層的座標索引 $i$。
每個神經元「攜帶」的重要「背景」事物被稱為激活函數(activation function),通常用字母 $h$ 表示。這是一個關於數據的函數:給定任何輸入 $x$,在 $x$ 上部分運行模型會返回一個激活向量。$h_i(x)$ 是其第 $i$ 個分量。這個函數 $h_i$ 現在就是神經元對神經網路「背景場」的貢獻。^([3])
現在如果有大量的神經元,每個神經元的激活函數都會對其他神經元產生的背景做出反應:在這個極限下移除該神經元不會對損失產生太大改變,因此背景決定了每個神經元的行為作為一個統計分佈。反過來,背景本身是由單個「前景」神經元組成的。這個循環:
背景 $\to$ 神經元分佈 $\to$ 背景
必須閉合,即自洽。理解這個循環就是神經網路平均場理論的核心內容。
在後續篇幅中,我們將更多地解釋這個循環,並展示一些它運作(或不運作)的例子。你也可以參考最初鏈接的關於細節之咒(Curse of Detail)的論文,以獲得更偏向物理學的觀點。
實驗設定與精美圖片
我們將以一個「自洽性」的玩具示例作為結尾,這在視覺上非常令人滿足。
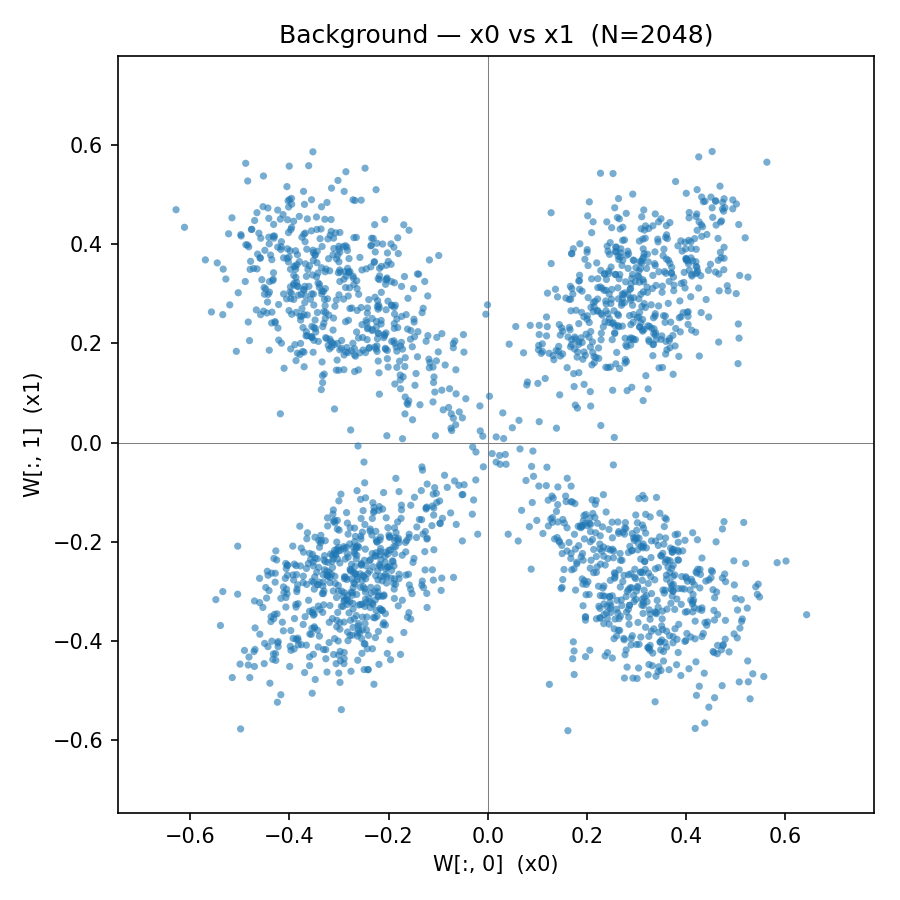
在這個設定中,我們觀察一個 2 層模型,它接收二維輸入變量 $x = (x_1, x_2)$,並在無限數據和大寬度(此處 $N=2048$)下針對目標 $y = \text{sign}(x_1 x_2)$ 進行訓練。激活函數 $\sigma$ 是一個有界的類 sigmoid 函數(tanh 的 relu 版本)。第一層的每個神經元是一個僅依賴於權重矩陣中一個二維行的函數,因此相關的「測試」場或粒子可以繪製在二維圖表上。當我們將所有這些繪製在一起時,我們得到了單神經元函數分佈的一個清晰圖景,這些函數結合在一起形成了背景系統:
<center>
上面的神經元是以一種允許它們交互的方式共同訓練的。
它具有精美的類苜蓿葉結構(當我們稍後觀察連續 XOR 時,它會再次出現——這是一個平均場執行組合計算的多層設定;即使在這個簡單的設定中,神經元雲是一個「有形狀的」分佈而非平坦的高斯分佈,這一事實使我們穩固地處於高斯過程體制之外)。現在我們可以實證測量單個隨機初始化的「前景」神經元將如何對該模型產生的背景做出反應。為此,我們在由完全訓練模型產生的背景上訓練 2048 個獨立同分佈(iid)的單神經元模型。^([4]) 當我們這樣做並將生成的 2048 個神經元組合成一個新模型時,我們看到它確實看起來與背景完全一樣。當我們計算其相關函數時,我們得到了非常相似的損失。
<center>
這張圖片中的每個神經元都是以完全 iid 的方式訓練的,沒有與任何神經元交互,僅僅是通過「對背景做出反應」,即與上面的「藍色」背景結合來學習任務。
請注意,這並不是一個「免費」獲得的屬性。如果我們使用錯誤的背景(例如這裡更像高斯過程的模型),那麼前景的樣本將無法與背景對齊。
<center>
藍色是背景,橘色是前景(每個橘色神經元在對背景的反應中獨立訓練)。
2 層網路的情況是特殊的:神經元函數特別容易表徵,且平均場具有更好的性質(它不是「耦合」的)。但我們將會看到,更深的網路仍然可以使用這種語言進行分析,甚至使用實證方法,我們也可以獲得關於它們如何學習和處理表示的更清晰圖景。
在下一篇文章中,我們將解釋這些實驗背後的物理原理以及模型的實驗細節(GitHub 倉庫即將發布)。
-
^(^)技術上,它們在是使用「披薩」還是「時鐘」機制上有所不同,但這兩種理想化是相關的,且平均場和現實設定都可以修改以利用其中任何一種。
-
^(^)在下文中,$f$ 和 $b$ 通常應被理解為「統計」函數:職業選擇或許是一個取決於經濟的機率函數,經濟既包括需求/市場,也包括供應/人們的興趣;反之,「經濟」是所有職業分佈上生產活動的平均值。
-
^(^)技術細節。**根據情況,$h$ 既可以被視為有限訓練集上的函數,也可以被視為無限「所有可能輸入集」上的函數,通常是一個大型歐幾里得空間(例如:一個 MNIST 輸入是一個 784 維的像素值向量)。除非我們處理的是有限訓練數據,否則這先驗地是一個無限維的裝置;更糟糕的是,神經元上實際求和的東西——即「市場」或「背景場」的模擬物——在這些對象中是非線性的^([4])。這裡還有關於 SGD 與貝氏學習的微妙之處,我暫不展開。但在允許泛化的平均場設定中(或對於有限數量的輸入),這個背景實際上由一小組「相關」方向主導。
-
^(^)技術說明:每個單神經元模型是在差值 $y - \hat{y}$ 上訓練的,其中 $\hat{y}$ 是已訓練的模型。
-
^(^)事實上它是二次的:在神經元上求和的東西是神經元函數的「外平方」,它是輸入對的函數:了解這個總和就能完全確定動力學(直到旋轉對稱性),即使對於有限寬度的模型也是如此(它通常被稱為「數據核」,但其用法與高斯過程核非常不同,後者確實依賴於無限寬度假設,並在有限寬度和平均場背景下丟失了大量信息)。