初探凝結理論
我正在探索一個名為「凝結」的新數學框架,該理論旨在定義如何客觀地將數據切分為概念與表徵。
本系列前文:《初級下貝氏主義》(Elementary Infra-Bayesianism)
1. 有這麼一篇論文
上週早些時候,我被一篇名為《凝結:一種概念理論》(Condensation: a theory of concepts)(Eisenstat 2025)的論文吸引了(被「nerd-sniped」)。這類論文的摘要提出了一個如此簡潔的斷言,以至於你會以為自己讀錯了:大致上是說,對於「這組數據中包含哪些概念」存在一個正確答案,且任何兩個能將數據切分得足夠好的智能體,都會對這些概念是什麼達成共識。^([1])
如果這聽起來很像 John Wentworth 的自然抽象假說(natural abstractions hypothesis),沒錯,兩者的家族相似性非常強。我不久前也寫過相關的主題。「凝結」(Condensation)是另一種形式化方法,但其核心結論異曲同工:數據中的結構限制了任何優秀的表示(representation)應該長什麼樣子。LessWrong 上的網友似乎很感興趣,我也想看看這到底在熱議什麼。
這篇論文長達 40 頁,全是數學,且沒有提供任何算法;它告訴你一個好的切分看起來像什麼,而不是如何找到它。我花了一段令人汗顏的時間試圖讓這些基本對象在電腦上運行起來。這篇文章記錄了我目前的進展。^([2])
2. 概念、作用域與評分
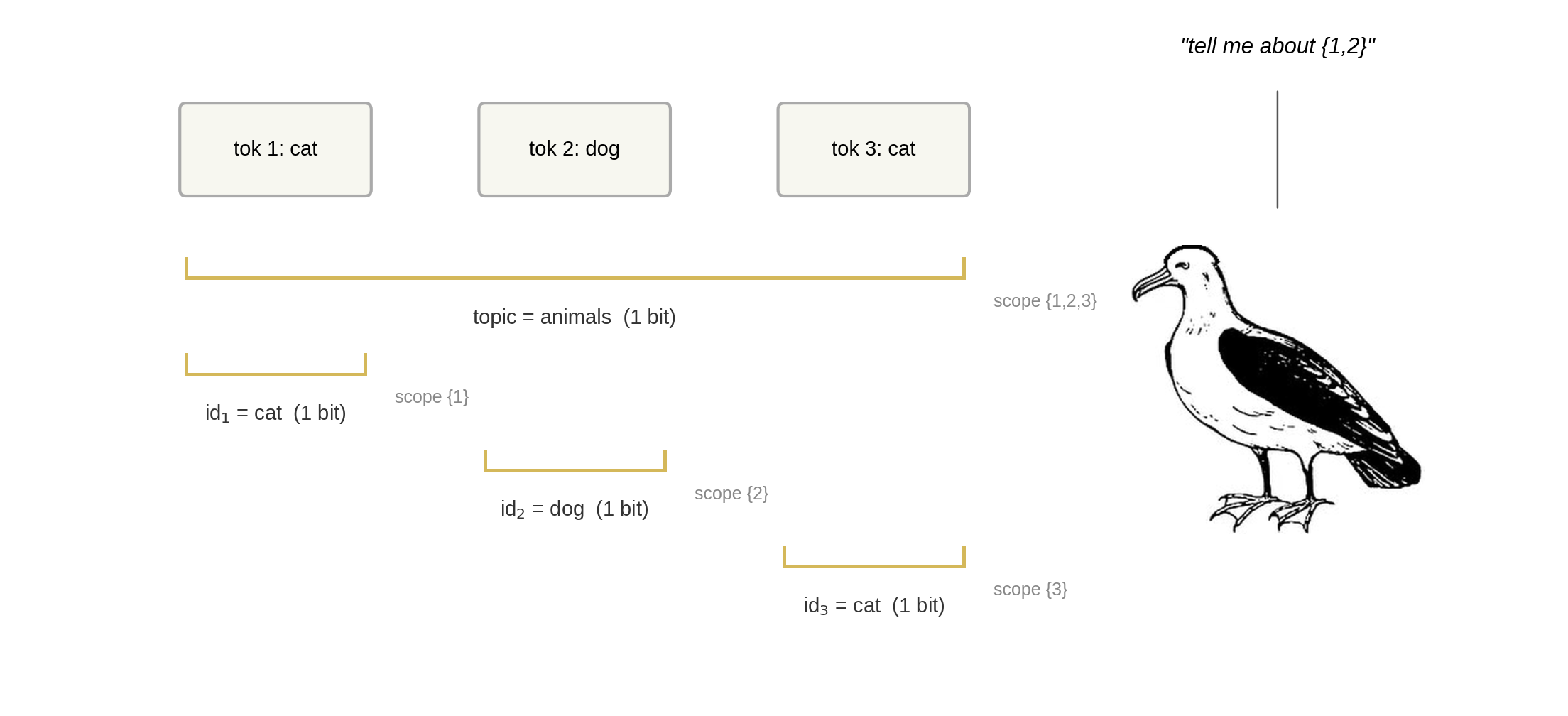
假設你觀察到三個標記(tokens)^([3]):
cat dog cat
我將概念(concept)定義為關於該數據的一條信息。^([4])「主題是動物」是一個概念。「標記 2 是 dog 而非 cat」也是一個概念。概念可以帶有作用域(scope):即該概念所涉及的標記集合。主題概念的作用域是 {1,2,3},因為知道主題能告訴你關於這三個標記的信息。「標記 2 是 dog」的概念作用域是 {2},因為它僅與標記 2 有關。
一個**表示(representation)**是一組(概念,作用域)對。對於三個標記,共有七個可能的作用域({1}, {2}, {3}, {1,2}, {1,3}, {2,3}, {1,2,3});典型的表示會在其中幾個位置填入內容,其餘留空。^([5]) 哪些作用域獲得了概念,正是該理論所關心的結構。
為了讓我們關注這些表示,它們需要滿足一條規則:從作用域包含標記 $i$ 的概念中,你必須能夠重建標記 $i$。 信息不能丟失。(如果你只存檔了「主題 = 動物」而沒別的,你無法重建 cat 或 dog;那樣的表示是無效的。)
這場戲的主角——凝結(condensation)——隨後會給你一個評分函數 $\chi$,用來衡量一個表示的效率。它的運作方式如下:有人問「告訴我所有與標記 {1,2} 相關的信息」。你通過讀取所有作用域與 {1,2} 重疊的概念來回答。在我們的例子中,這包括主題(作用域 {1,2,3},有重疊)、id₁(作用域 {1},有重疊)和 id₂(作用域 {2},有重疊),但不包括 id₃(作用域 {3},無重疊)。$\chi$ 是你必須讀取的總位元數(bits)。^([6]) 你希望對每一個可能的提問,$\chi$ 都很小;永遠不要讀取無關的概念,也永遠不要重複讀取相同的信息。
三個標記 (cat, dog, cat),四個概念存檔在各自的作用域。關於標記 {1,2} 的查詢會讀取所有作用域與 {1,2} 重疊的概念:主題(作用域 {1,2,3})、id₁(作用域 {1})和 id₂(作用域 {2}),但不包括 id₃(作用域 {3})。*
正如我開頭所說,論文沒告訴你如何找到一個好的表示。其主要定理 (4.15) 指出,任何兩個評分足夠好的表示,最終都會在幾乎相同的作用域存檔幾乎相同的概念,^([7]) 這正是概念「客觀存在」的意義所在。
3. 相同的三個標記,三種表示
讓我用一個包含所有核心結構的小例子來具體說明。
數據:一枚公平的硬幣決定主題(動物或工具),然後三個標記中的每一個都獨立地從該主題中選取兩個詞之一(cat/dog 或 hammer/saw)。總共有 4 位元的信息:1 個主題位元(三個標記共享)和 3 個標記身份位元(每個標記私有)。以下是一些抽樣示例:
| 標記 1 | 標記 2 | 標記 3 | 主題 |
|---|---|---|---|
| cat | dog | cat | animals |
| hammer | saw | hammer | tools |
| dog | dog | dog | animals |
| saw | hammer | saw | tools |
同一數據的三種表示:
1. 平庸(Trivial)。 不費心尋找共享概念。將每個原始標記存檔在各自的作用域。
| 作用域 | 概念 | 位元 |
|---|---|---|
| {1} | id₁ | 2 |
| {2} | id₂ | 2 |
| {3} | id₃ | 2 |
詢問標記 1 和 2:你讀取了 4 位元,但真實的聯合信息只有 3 位元,因為它們共享一個主題。^([8]) 主題位元同時存在於兩個原始標記中,你讀了兩次。每個涉及多個標記的問題都付出了額外代價。
2. 先知(Oracle)。 將主題存檔在 {1,2,3},將每個標記身份位元存檔在各自的單元素集合。
| 作用域 | 概念 | 位元 |
|---|---|---|
| {1,2,3} | topic | 1 |
| {1} | id₁ | 1 |
| {2} | id₂ | 1 |
| {3} | id₃ | 1 |
每個問題的成本正好等於其熵,這是你能做到的最好結果。
3. 錯檔(Misfiled)。 與先知表示相同的四個概念,但主題被存檔在作用域 {2,3} 而非 {1,2,3}。
| 作用域 | 概念 | 位元 |
|---|---|---|
| {2,3} | topic | 1 |
| {1} | full token₁^([9]) | 2 |
| {2} | id₂ | 1 |
| {3} | id₃ | 1 |
詢問標記 1 和 2:完整標記₁ (2 位元) + 主題 (1 位元) + id₂ (1 位元) = 4。主題在裡面出現了兩次,你為這兩份副本都付了費。
針對七個可能查詢 $Q$ 的 $\chi(Q)$。先知表示在零點持平;錯檔表示在跨越主題位元兩個副本的查詢中會顯著上升。*
所以評分函數確實符合預期:當每個共享概念正好位於其所屬的作用域時,得分最低;且當概念錯位時,它能告訴你哪些查詢付出了額外代價。
這些都是我們手動構建的,所以目前還沒什麼深奧的發現。問題在於,從神經網絡的激活值中構建出的表示,看起來會更像先知表示還是平庸表示?
4. 模型提供概念;作用域由你決定
現在假設概念來自 GPT-2 或 Claude 等語言模型,而不是手動構建。
我針對 §3 中的三標記主題數據訓練了一個微型的 4 層 Transformer。殘差流(residual stream)(每層讀取和寫入的運行向量)的一個單一加權和就能以完美的準確率恢復主題:
標記通過一個微型的 4 層語言模型;殘差流上的線性探針(linear probe)能以 100% 的準確率恢復主題(「animals」)。概念就在那裡;問題在於該分配什麼作用域給它。*
所以模型已經學會了正確的概念。問題是:我們該分配什麼作用域給它?
一個天真的答案是「該特徵的作用域是模型目前看到的所有標記」,因為激活值取決於這些標記。但這對每個特徵都會給出相同的答案,因此無法區分關於單個標記的特徵和關於整個序列的特徵。^([10])
這裡更好的方法是互信息(mutual information, MI):作用域 = 與該特徵相關的標記集合。主題與所有三個標記都相關(每個標記的第一位元就是主題),所以 MI 判定作用域為 {1,2,3},這正是 §3 中的先知表示。評分 $\chi$ 趨於零。^([11])
在大規模應用中,從語言模型中獲取候選概念的標準方法是稀疏自編碼器(sparse autoencoder, SAE):你在殘差流中學習一組大量的方向,使得對於任何給定輸入,只有少數方向是活躍的。每個方向被稱為一個特徵(feature),我們希望「特徵 $k$ 開啟」具有可解釋的含義:這與烹飪有關、這裡有一個左括號、主語是複數。SAE 給了你特徵,但它不給出它們的作用域,所以你仍然需要像 MI 這樣的方法來標記每一個特徵。
5. 它在真實模型上有效嗎?
三標記的玩具模型令人安心,但那只是 4 位元的手動數據。真正重要的問題是,當概念來自真實語言模型處理真實文本時,評分函數是否還有用。為了找出答案,我沿著兩個軸仔細擴展了實驗範圍:模型大小(從微型 4 層 Transformer 到 GPT-2 small)和數據集複雜度(從植入的基準真相到真實文本)。
流程管線
- 選取 50,000 個文本窗口,每個長度為 $N$ 個標記。
- 將每個窗口輸入語言模型,讀取最後一個標記處的殘差流(此時模型已看到所有 $N$ 個標記)。
- 用三種方式分解這些向量:SAE、PCA(教科書式的尋找最大方向的方法)以及隨機投影(對照組:毫無意義的方向)。每一種都會給你幾百個特徵。
- 將每個特徵轉化為概念:選取一個閾值 $p$,使特徵在排名前 $p%$ 的窗口中為「開啟」(ON),其餘為「關閉」(OFF)。^([12]) 通過 MI 為其標記作用域,即與其相關的標記位置集合。保留信息量最大的前 $K$ 個。
- 計算 $\chi$。報告 $\Delta \chi$:比 §3 中僅存儲原始標記的平庸表示好(或差)多少位元。負的 $\Delta \chi$ 意味著該方法找到了確實能節省位元的共享概念。^([13])
我在第 4 步中掃描閾值 $p$,並報告每種方法的最小 $\Delta \chi$,讓評分函數自行選取最佳閾值。^([14]) 第 1-4 步中的其他參數我要麼進行了掃描,要麼保持固定,而我全程報告的是排序(SAE vs PCA vs 隨機),這在所有參數變動下都保持一致。^([15]) 具體的聚合數值較不穩定(取決於第 5 步中的權重選擇),所以不要將單個數值視為自然常數。
數據集
1. 植入基準真相的玩具模型。 8 個標記,包含 7 個按二元樹排列的植入共享概念:一個關於全部 8 個標記,一個關於標記 1-4,一個關於 5-8,以及關於每對相鄰標記(1-2, 3-4, 5-6, 7-8)的各一個。每個都是一個「是/否」標籤,15% 的情況下為「是」。我將它們壓縮到 6 個維度中,使它們略有重疊,迫使 SAE 必須真正進行解混(un-mix)。^([16]) 一些序列示例:
| tok 1 | tok 2 | tok 3 | tok 4 | tok 5 | tok 6 | tok 7 | tok 8 | 活躍標籤 |
|---|---|---|---|---|---|---|---|---|
| 0.31 | −0.42 | 0.87 | −0.15 | 0.63 | −0.29 | 0.44 | −0.71 | global, pair₃₄ |
| −0.55 | 0.12 | −0.33 | 0.68 | −0.21 | 0.45 | −0.62 | 0.19 | half₅₈, pair₇₈ |
先知表示(真實概念位於真實作用域)得分為 $\Delta \chi = -1.2$。
2. TinyStories。 來自兒童故事的 50,000 個 8 詞開頭。這裡的位置結構是真實的:「once upon a time there was a」出現在位置 1-7,這是目前為止最常見的模式。我分別在小型 4 層 Transformer 和 GPT-2 small 上運行了這個實驗。
| 句子開頭 |
|---|
| once upon a time there was a little |
| one day a girl named lily went to |
| the sun was shining and the birds were |
| tom and his mom went to the park |
3. 歸納(Induction)。 一個旨在具有特定共享概念的設置。提示詞類似於:
cat dog bird fish bee cat ___
其中五個隨機單詞後跟著第一個單詞的重複,模型應該補全第二個單詞。GPT-2 small 在 75% 的情況下能做對。我在重複處(標記 6)讀取殘差流,此時模型剛剛識別出「那是 cat 再次出現」。特徵應該捕捉到的共享概念是「單詞 1 = cat」,作用域為 {1,6}:它與標記 1(cat 首次出現)和標記 6(再次出現)有關。單詞來自一個包含 50 個詞的固定池。
結果
在植入玩具模型上,SAE 恢復了大部分基準真相:它達到了先知評分的 86%,且得分最高的閾值 $p$ 為 15%,這正好是概念生成的真實機率。評分函數在未被告知的情況下找到了正確的閾值。PCA 和隨機投影都遠遠落後。^([17])
在 TinyStories 上,排序依然成立:SAE 優於 PCA,PCA 優於隨機。差距比玩具模型小(真實文本的共享結構不如七個植入標籤那麼純淨),但在小型模型和 GPT-2 small 上都保持一致。SAE 的首選特徵在「once upon a time there was a」處觸發:這是一個能同時告訴你關於所有 8 個標記信息的「是/否」概念。PCA 的首選特徵則在最後一個標記是否為虛詞(function word)時觸發:這是一個關於單個標記的概念。^([18])
在歸納任務上,PCA 勝出,而且領先幅度不小。
在玩具模型面板中,SAE 的最佳得分位於真實的 15% 處,且幾乎觸及先知線。在歸納任務面板中,PCA 的曲線持續下降,而 SAE 的曲線則反彈上升。*
為什麼 PCA 在歸納任務上勝出
我想詳述這一點,因為我的預設是「SAE 優於 PCA」,但評分函數不同意。這裡的共享概念是「50 個單詞中的哪一個是單詞 1」,這不是一個「是/否」標籤,而是一個價值 $\log_2(50) \approx 5.6$ 位元的 50 選 1 問題。如果用四個二進制概念來編碼這個選擇,SAE 會將它們花在接近「獨熱碼」(one-hots)的特徵上:它的首選特徵字面上就是「單詞 1 = gym」、「單詞 1 = pen」、「單詞 1 = fan」、「單詞 1 = cup」,每個特徵對約 2% 的輸入非常精確,對其餘 98% 則保持沉默。PCA 則將這四個概念花在粗略的劃分上,每個特徵對大約 20% 的詞池為「開啟」,雖然模糊但覆蓋面廣。四個粗略位元比四個獨熱位元能編碼更多關於 50 選 1 變量的信息;評分函數正確地報告了這一點。將詞池縮小到 8 個單詞,PCA 的領先優勢也隨之按比例縮小,證實了底層變量的基數(cardinality)才是關鍵。^([19]) ^([20])
6. 進展到哪裡,以及我的擔憂
這就是我目前的進展。評分函數確實有用:它在受控數據上以正確的方向區分了 SAE、PCA 和隨機投影,它在未被告知的情況下找到了基準真相閾值,並給出了至少一個真正令人驚訝的結果(PCA 在歸納任務上擊敗 SAE)。但我想要清醒地認識到這代表了什麼,以及不代表什麼。
在這種設置下,凝結評分衡量的是一種分解方法的歸納偏置(inductive bias)是否與數據中共享概念的結構相匹配。 SAE 假設共享概念是稀有的「是/否」標籤,PCA 則不這麼假設。因此,當共享概念確實是稀有的「是/否」標籤時(玩具模型、TinyStories),SAE 勝出;而當共享概念是一個 50 選 1 的類別變量時(歸納任務),PCA 勝出。當沒有共享內容,或者模型根本沒有計算它時,沒有任何方法能擊敗平庸表示。
如果這一結論成立,我認為它能帶來幾點啟示:
1. 作用域是概念的一半。 可解釋性研究大多將「概念」視為激活空間中的一個方向,僅此而已。凝結理論認為它是一個(概念,作用域)對,而 §4 表明作用域的分配是一個真實的選擇,且存在一個有立場的評分函數讓我們比較這些選擇。「這個特徵意味著 $X$」和「這個特徵是關於標記 $i$ 到 $j$ 的」是不同的斷言,而電路研究往往在兩者之間滑動而未察覺。
2. 特徵分裂(Feature splitting)有其特徵。 當 SAE 將一個底層變量拆分為多個特徵時,這些特徵都落在同一個作用域,而 $\chi$ 正好會懲罰這一點(你讀取了 $K$ 個概念,而本來一個就夠了)。在大規模應用中,SAE 已知的特徵分裂族群應該表現為作用域衝突,而能合併它們的分解方法得分應該更高。這是一個可測試的預測。
3. 你可以用它來為每個電路選擇分解方法。 同一模型的不同部分顯然具有不同類型的共享概念:歸納任務是類別選擇,而「這是否為 Python 代碼」則是一個「是/否」標籤。評分函數為你提供了針對特定電路選擇分解方法的理由,而不是在所有地方都死守 SAE,這也大致符合「SAE 令人失望」論調的發展方向。而且這裡沒有什麼是 SAE 特有的;該流程管線可以接受任何從激活值提取特徵的方法。
理論很美,我對於如何填補一些實現細節有很多研究想法:
- 一個有原則的作用域分配算法會很棒。我使用 MI 是因為它在玩具模型上有效,這並不是一個很好的理由。
- 將從 SAE/PCA 提取的概念轉化為能計算互信息的東西是很棘手的。將特徵二值化會丟棄大部分信息,而量化則會變得有點混亂。
- 可能的作用域數量隨標記數呈指數增長,所以超過一定長度 $N$ 後,你無法檢查所有作用域。^([21])
- 而且我不確定在 $N=8$ 時有效的管線選擇是否能在 $N=128$ 時存活,或者我在 50,000 個窗口中看到的排序是否能在 500,000 個窗口中保持。
在這種方法準備好投入實戰部署之前,還有很多開放性問題。^([22])
但最大的差距在於,我還沒有測試論文的實際定理:即兩個高分表示會對它們發現的概念達成共識。以上所有內容只是「這裡有一個分解方法的新評分函數,它給出了合理的排名」。這很有用,但它只是一個評估指標,而不是概念真實存在的證據。凝結理論的斷言更強:任何兩個評分足夠好的表示都應該收斂到相同的(概念,作用域)對,這才是讓這件事關乎「自然抽象」而非僅僅關乎 SAE 的原因。測試這一點可能相對直接:用不同的種子訓練兩個 SAE,提取它們的首選概念,看看 $\chi$ 一致性(定理 5.8)是否真的成立。我可能會在後續行動中這樣做,但我決定先發布這些內容,因為我認為更多人獨立地鑽研這個問題,比我私下磨光它更有價值。
- ^(^)定理 4.15。實際表述是關於潛變量模型的合併(amalgamations),比我的概括要謹慎得多。
- ^(^)大部分代碼是 Claude 在一次漫長的結對編程中寫的,這就是現在的常態。解釋上的錯誤由我負責。
- ^(^)注意「標記」是我做出的選擇,而非理論要求。作用域定義在你選取的任何觀察對象上:標記位置、語法成分、文檔章節。不同的選擇會給出不同的可能作用域,以及關於概念涉及對象的不同理論。
- ^(^)術語註解:在論文中,「概念」技術上是指完整的(概念,作用域)對,而不僅僅是信息片段。我更鬆散地使用「概念」來指代信息片段本身,而將「作用域」分開,因為這符合大多數可解釋性研究者對特徵的思考方式。這種區別只有在閱讀定理時才重要。
- ^(^)論文將概念稱為 $L_S$(潛變量,由其作用域 $S$ 索引),並將整個集合稱為「潛變量模型」。我會繼續說「概念」和「作用域」,因為一旦我寫下 $L_S$,我的眼神就會變得呆滯,並開始寫腳註。
- ^(^)全文中的「位元」指信息論位元:變量 $X$ 的熵 $H(X)$ 是平均需要多少位元來記錄其值。一枚公平硬幣是 1 位元。一個公平的 50 面骰子是 $\log_2(50) \approx 5.6$ 位元。
- ^(^)定理 4.15。這種一致性是「累積的」:任何作用域及其以上的信息都是匹配的,即使兩個表示在不同層級間分配信息的方式不同。對於評分良好但非完美的表示,有一個近似版本 (5.8),這在實踐中更重要。
- ^(^)為什麼每個標記是 2 位元?每個標記是四個單詞之一(兩個主題 × 每個主題兩個詞),均勻分佈,所以 $\log_2(4) = 2$。
- ^(^)重建規則強制要求:{1} 的概念必須足以重建標記 1,而單靠「id₁」在沒有主題的情況下做不到。所以 {1} 存儲了完整標記(2 位元,包含主題信息)。
- ^(^)你也可以在每個上下文的所有可能截斷處訓練 SAE,並檢查特徵是否在每個截斷長度都出現。這會提供細粒度的作用域信息,但成本很高;我沒試過。機械可解釋性社群大多專注於將特徵歸因於預測而非輸入標記,使用歸因補丁(attribution patching, Nanda 2023)或電路追踪(circuit tracing, Anthropic 2025)等技術。這些在精神上更接近歸因方法而非 MI。
- ^(^)人們在 Demski 貼文的評論中注意到了與 SAE 的聯繫。據我所知,之前還沒人實際計算過這個評分;這就是本文剩餘部分所做的工作。
- ^(^)閾值本質上是速率編碼方案中發放率(firing rate)的選擇:特徵在什麼激活水平以上算作「開啟」?這與神經科學中的脈衝速率編碼不完全相同,但權衡(太高會丟失信號,太低則處處觸發)是一樣的。
- ^(^)最佳可能的 $\Delta \chi$(先知表示獲得的)等於標記的總相關性(total correlation)的負值,即跨標記存在的共享信息位元數。這不是一個新量;新穎之處在於作用域結構決定了一個給定表示與該值的接近程度,而 §3 表明將正確的概念存檔在錯誤的作用域會導致得分不足。
- ^(^)閾值 $p$ 很重要:太高則每個概念都像拋硬幣,太低則每個概念都像常數。掃描 $p$ 並報告最小值是我在用固定閾值自欺欺人一段時間後,發現能使比較趨於穩定的修正方法。
- ^(^)這個流程管線中大約有十幾個選擇,我不會假裝它們都是有原則的。值得強調的一點是:每個標記也以原始形式存儲在各自的作用域(這樣重建規則總能滿足,但這意味著 $\chi$ 的大部分是原始標記,特徵只是其上的一種擾動)。
- ^(^)6 個維度,7 個概念:每個概念是 $\mathbb{R}^6$ 中的一個隨機二進制向量,每個標記是活躍標籤對應的概念向量之和,再加上高斯噪聲。這迫使概念在觀察維度中重疊,因此 SAE 必須進行解混,而不是僅僅從獨立坐標讀取。
- ^(^)我還運行了三個結果應該是「無人勝出」的設置:來自開放網絡的隨機 12 標記窗口(沒有對齊的結構供人發現)、具有獨立槽位填充的模板數據集(有結構但跨位置無共享)、以及兩位數加法(GPT-2 不會加法,所以進位位元不在殘差流中)。這三者都歸零,每種方法都在平庸表示的 ~0.1 位元範圍內。開放網絡的零結果值得注意:這不代表「真實文本沒有共享概念」,只是說它在隨機窗口的標記位置間沒有共享概念。「標記位置」是我在第 1 步做出的選擇,而非理論賦予的。TinyStories 的結果之所以有效,是因為句子對齊的開頭具有位置結構。若要對開放文本產生作用,可能需要對 $i$ 是什麼做出不同的選擇(例如語法成分而非位置槽位)。
- ^(^)我檢查過這不只是我的主觀臆斷:使用標準的自動解釋協議(給 LLM 看 12 個例子,要求給出一行解釋,評分該解釋是否能預測留出例子的觸發情況)。前 8 個特徵的平均平衡準確率:SAE 0.62 ± 0.18(僅「once upon a time」特徵就得分 0.95),PCA 0.55 ± 0.05,ICA 和隨機約為 0.52。隨機水平為 0.50。$N$ 很小;SAE 與其他的差距大約是一個 SAE 標準差。
- ^(^)你可以將此解讀為「你讓 SAE 挨餓了,給它 50 個特徵它就會贏」。也許吧。但我更喜歡一種符合凝結理論的解讀:理論想要在作用域 {1,6} 處有一個概念,而 SAE 將其粉碎成 50 個位於同一作用域的特徵,即特徵分裂。
- ^(^)這個結果也讓我相信評分函數不是循環論證。擔憂點在於:作用域被定義為「與特徵相關的標記」,而 $\chi$ 獎勵與多個標記相關的特徵,所以高 MI 方法理所當然會贏。但在這裡,每種方法都用相同的 MI 規則標記作用域,SAE 的特徵 MI 並不比 PCA 低,但 SAE 還是輸了。$\chi$ 反應的不是「你是否找到了相關特徵」,而是特徵的形狀(是/否標籤 vs. 多選一)是否與它要編碼的共享概念形狀相匹配。
- ^(^)這裡一個有趣的想法是,老派計算語言學風格的語法成分(名詞短語、動詞短語、子句)標記是否能有效地將冪集限制在可處理的範圍內。僅對語法成分評分,或按語法樹加權,會使 $N=50$ 變得可行,這會是一個很有趣的嘗試。
- ^(^)同樣未觸及的還有:將 $\chi$ 作為訓練目標而非僅僅是評估。讓評分函數自行選取閾值的技巧暗示你可以同時學習特徵及其離散化,這聽起來要麼很優雅,要麼完全是個災難。
- ^(^)歸因(Attribution, Meng et al. 2022, Heimersheim 2024):刪除主題特徵,對標記 2 和 3 的預測會變差(模型利用主題來縮小範圍),但對標記 1 的預測不變(標記 1 是在知道主題前從無到有預測的)。原因是結構性的:在自回歸模型中,主題直到標記 1 被讀取後才存在,所以模型無法利用它來預測標記 1,因此歸因無法看到它與標記 1 有關。這會給出 §3 中的錯檔表示,評分函數會在預期的查詢處給出懲罰。
- ^(^)歸因和 MI 甚至不是對同一事物的兩種估計;它們是不同的問題。歸因問的是「這個概念影響哪些預測」;MI 問的是「這個概念是關於哪些標記的」。如果你關心模型的行為,歸因是正確的;如果你關心數據的結構,MI 是正確的。凝結理論就其書面定義而言,是關於數據的。