
窄於預期:以太坊二元樹的最佳群組深度分析
這項研究針對以太坊二元樹的八種群組深度配置進行了基準測試,並指出 GD-5 或 GD-6 是平衡讀取與寫入性能的最佳平衡點。
這篇文章有更好的視覺化呈現方式(包含解釋概念的動態圖表,以及更清晰的基準測試結果視覺化)。如果您偏好該版本,請查看:Binary Trie Group-Depth Benchmark — Narrower Than Expected
感謝 @gballet 與 @weiihann 的審閱,以及 @rjl493456442 提供的寶貴討論,及其在 Pebble 和 QueueDepth 配置上出色的基準測試工作。
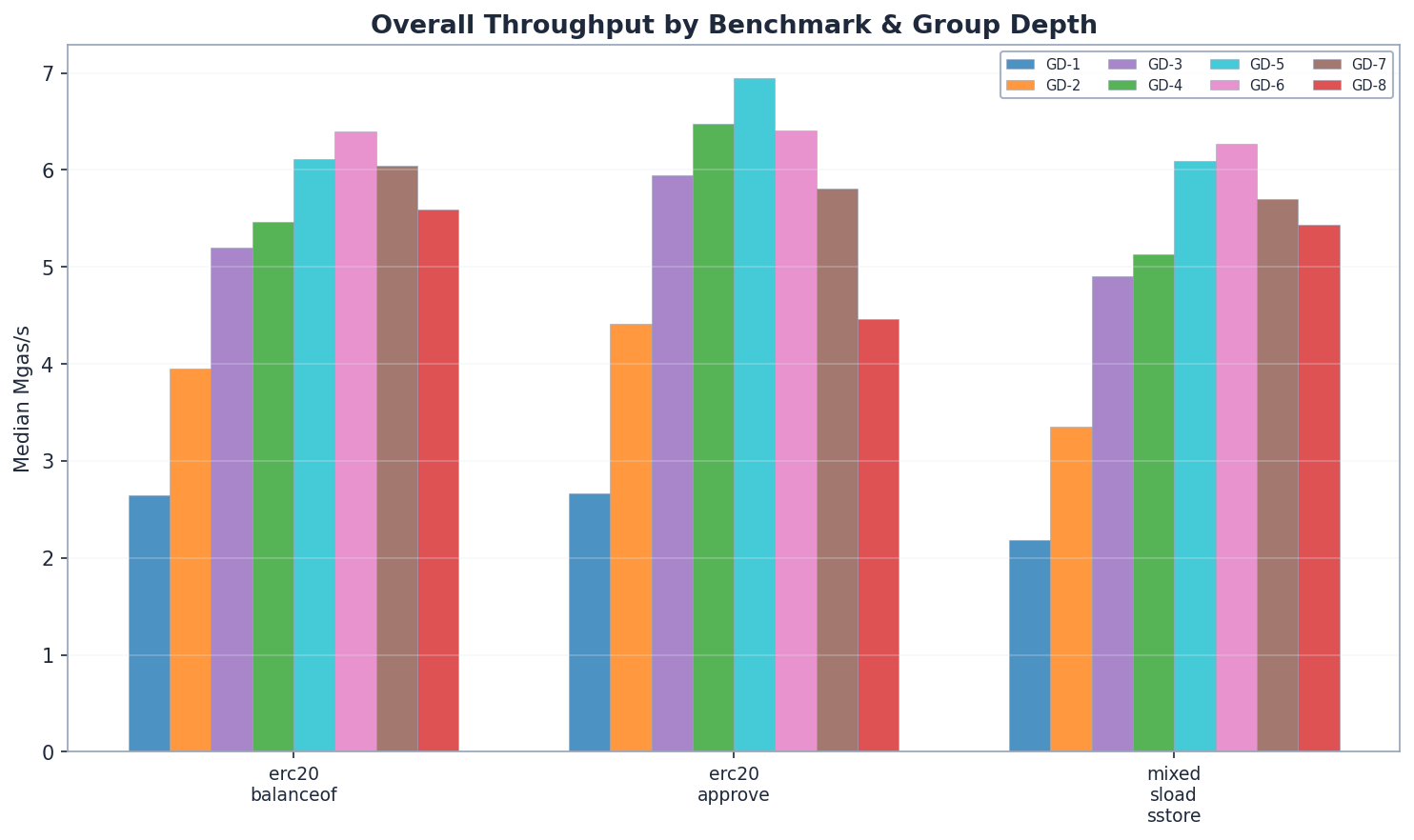
> 最佳平衡點為 GD-5 或 GD-6。 我們在包含 4 億個狀態條目、大小為 360 GB 的資料庫上,對 8 種二元特里樹(Binary Trie)分組深度配置(GD-1 到 GD-8)進行了基準測試。GD-5 的寫入速度比 GD-4 快 7%(6.94 vs 6.47 Mgas/s, p < 1e-9),而 GD-6 在讀取方面領先(6.39 Mgas/s),且混合工作負載比 GD-4 快 19%(p < 1e-3)。GD-7 證實了轉折點:在所有基準測試中,效能超過 GD-6 後便開始下降。寫入與讀取的最佳平衡點落在每個節點 5-6 位元(bits)。
S1 – 執行摘要
二元特里樹已被列入 以太坊協議草案藍圖,作為未來狀態樹的替代方案。目前尚未有任何二元特里樹實作在大規模環境下進行過基準測試——無論是分組深度(Group Depth)還是其他指標。隨著這項轉型納入路線圖,評估其效能特性是進行知情原型開發的前置條件。Geth 的實作(EIP-7864)提供了一個 –bintrie.groupdepth 參數,用以控制二元層級如何打包進磁碟節點中;本研究測試了 8 種配置以確定最佳設定。
結論: 最佳平衡點為 GD-5 或 GD-6,視工作負載而定。GD-5 的寫入效能比 GD-4 高出 7%(6.94 vs 6.47 Mgas/s, p < 1e-9)。GD-6 在讀取方面領先(6.39 Mgas/s),且混合工作負載表現最佳(比 GD-4 快 19%, p < 1e-3)。GD-7 證實效能在超過 GD-6 後開始下降。
我們測試了什麼
在完全相同的 360 GB 資料庫(約 4 億個狀態條目)上測試了 8 種分組深度配置(GD-1 到 GD-8)。
共有五種基準測試類型——兩種合成測試(原始 SLOAD/SSTORE)和三種 ERC20 合約工作負載——每種測試在冷快取(cold-cache)協議下運行 9 次。所有結果均採用中位數,並通過 Mann-Whitney U 顯著性檢定。
我們的發現
-
讀取證實了直覺(S4):較寬的樹讀取速度更快。GD-8 的讀取吞吐量是 GD-1 的兩倍以上(5.59 vs 2.65 Mgas/s)。GD-6 達到了最高的讀取吞吐量(6.39 Mgas/s),其次是 GD-5(6.11)和 GD-7(6.04)。GD-3 到 GD-8 的吞吐量範圍在 5.2 到 6.4 Mgas/s 之間。
-
寫入揭示了更明確的最佳點(S5):GD-5 是寫入冠軍,耗時 629 毫秒(6.94 Mgas/s)——比 GD-4 快 7%(678 毫秒,6.47 Mgas/s),比 GD-8 快 55%(982 毫秒,4.47 Mgas/s)。寫入效能的轉折點位於 GD-5 和 GD-6 之間(雜湊/讀取成本比率超過 1.0)。
-
節點大小在 GD-7 觸及 Pebble 區塊邊界(S5):每個 GD-7 節點序列化後約為 4 KB(128 × 32 位元組)——正好是 Pebble 的區塊大小。在此邊界之下(GD-6:約 2 KB),每個節點可容納於單個區塊內。超過此邊界,讀取每個節點可能需要兩個區塊。Gary Rong 的 NVMe 基準測試 顯示,在 QD=1 時,隨機 8 KB 讀取的延遲比 4 KB 高出 54%(77.8 vs 50.6 µs)。這種單個節點的 I/O 懲罰在約 37 個路徑節點上累加,解釋了為何 GD-7 雖然路徑較短,但讀取速度卻比 GD-6 慢。
-
最佳平衡點為 GD-5 或 GD-6(S6):GD-5 的寫入比 GD-4 快 7%,而 GD-6 在讀取(比 GD-5 快 5%)和混合工作負載(比 GD-4 快 19%)方面領先。GD-7 證實了轉折點——在所有基準測試中表現均遜於 GD-6。由於以太坊屬於讀取密集型,GD-6 可能是較理想的預設值。
### 如何閱讀本文
S2 背景介紹涵蓋了二元特里樹和分組深度的概念。S3 方法論詳述了基準測試的設置。S4 至 S6 以敘事弧線呈現結果:讀取、寫入,然後是權衡取捨。S7 模式分析探討了交叉觀察結果,S8 結論給出了雙重建議與開放性問題。時間緊迫?請從 S4 的「ERC20 讀取:深度至關重要之處」 開始——該章節最能明顯看出分組深度的差異,並為後續分析奠定基礎。
S2 – 背景
什麼是二元特里樹(Binary Trie)?
EIP-7864 提議用二元特里樹取代以太坊的默克爾帕特里夏樹(MPT)。二元特里樹將帳戶樹和所有存儲樹統合成單一樹狀結構,使用 SHA-256 代替 Keccak-256 進行雜湊處理(在此我刻意忽略雜湊演算法的爭論),並存儲對應到 256 個值組的 32 位元組主幹(stems)。
這種設計簡化了無狀態客戶端的見證數據(witness)生成,並能實現更高效的證明。它還允許在計算狀態根期間進行更多並行化,因為帳戶不再需要先依賴合約存儲的雜湊。從 MPT 到二元特里樹的轉變是以太坊狀態層最重大的變化之一。新結構的效能特性將直接影響區塊處理時間、同步速度和驗證者的經濟效益。
什麼是分組深度(Group Depth)?
在基礎層級上,特里樹始終是二元的——每個內部節點恰好有兩個子節點(位元 0 為左,位元 1 為右)。分組深度控制有多少個二元層級被打包進單個磁碟節點。在 GD-N 配置下,每個存儲節點封裝了一個 N 層的二元子樹,因此從外部看,它顯得擁有 2^N 個子節點:
- GD-1: 每個節點 1 個二元層級 → 2 個子節點指針,通往葉節點的路徑上有 256 個節點。
- GD-2: 每個節點 2 個二元層級 → 4 個子節點指針,路徑上有 128 個節點。
- GD-3: 每個節點 3 個二元層級 → 8 個子節點指針,路徑上約 86 個節點。
- GD-4: 每個節點 4 個二元層級 → 16 個子節點指針,路徑上有 64 個節點。
- GD-5: 每個節點 5 個二元層級 → 32 個子節點指針,路徑上約 52 個節點。
- GD-6: 每個節點 6 個二元層級 → 64 個子節點指針,路徑上約 43 個節點。
- GD-7: 每個節點 7 個二元層級 → 128 個子節點指針,路徑上約 37 個節點。
- GD-8: 每個節點 8 個二元層級 → 256 個子節點指針,路徑上有 32 個節點。
這就像郵遞區號:GD-1 每次讀取地址的一位數字(256 個步驟),而 GD-8 則一次讀取 8 位數字(32 個步驟)。步驟越少意味著磁碟讀取次數越少——但每個「打包節點」體積更大,更新成本也更高,因為其內部的二元子樹必須重新計算雜湊。
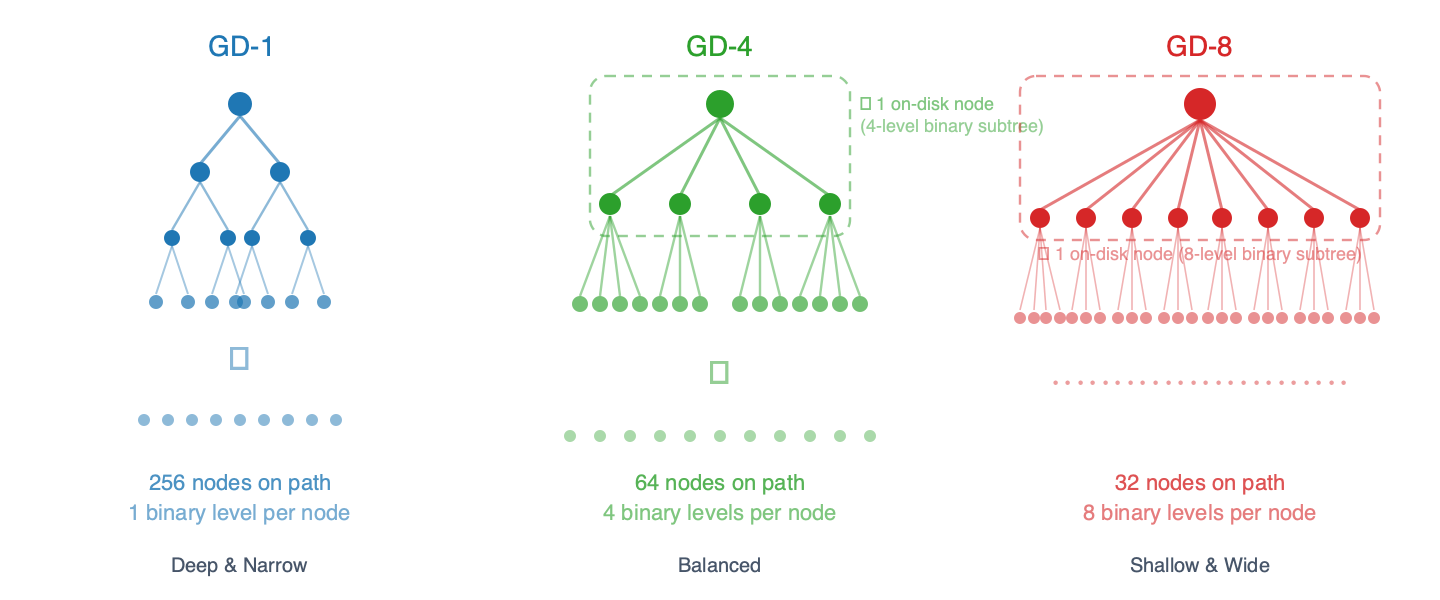
圖 1 – 不同分組深度下的樹狀結構。每個節點內部打包了 N 個二元層級,減少了通往葉節點路徑上的磁碟節點數量。
理論上的權衡很直觀:讀取受益於較淺的樹(到達葉節點所需的磁碟 I/O 操作較少),而寫入則受累於較寬的節點(修改節點時需要更多內部雜湊計算)。問題在於交叉點究竟在哪裡。
S3 – 方法論
(點擊查看更多細節)
S4 -- 第一幕:讀取證實了直覺
我們選擇不在此處包含合成順序讀取的數據,以縮減文章篇幅。如果您感興趣,可以查看頁面頂部的連結。
簡而言之:寫入在所有配置中表現幾乎相同。由於分組深度主要影響隨機存取模式(Keccak 雜湊的存儲插槽),因此僅針對所有 8 種配置收集了 ERC20 基準測試數據。
ERC20 讀取:深度至關重要之處
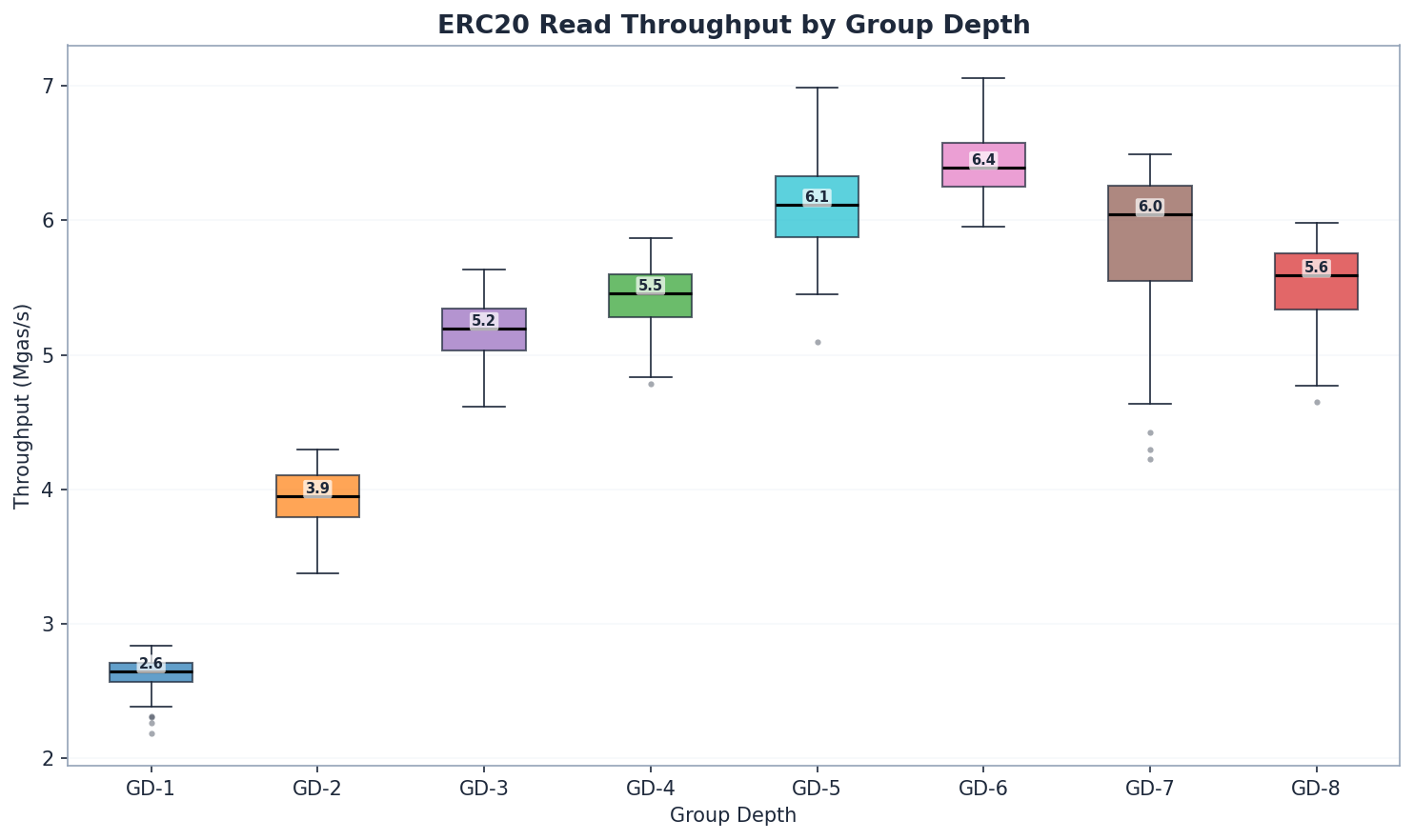
| GD | 狀態讀取 (ms) | 總計 (ms) | Mgas/s | 相較 GD-1 (Mgas/s) |
|---|---|---|---|---|
| 1 | 5,878 | 6,284 | 2.65 | 基準 |
| 2 | 3,840 | 4,231 | 3.95 | +49% |
| 3 | 2,866 | 3,213 | 5.20 | +96% |
| 4 | 2,677 | 3,067 | 5.46 | +106% |
| 5 | 2,370 | 2,733 | 6.11 | +131% |
| 6 | 2,248 | 2,623 | 6.39 | +141% |
| 7 | 2,339 | 2,693 | 6.04 | +128% |
| 8 | 2,598 | 2,977 | 5.59 | +111% |
從 GD-1 到 GD-6,讀取吞吐量提升了約 2.4 倍。 GD-6 達到了最高的讀取吞吐量(6.39 Mgas/s),其次是 GD-5(6.11)和 GD-7(6.04)。讀取效能從 GD-1 到 GD-6 單調遞增,隨後開始下降——如預期般,GD-4(5.46)因路徑較短而優於 GD-3(5.20)。GD-7 和 GD-8 則顯示出邊際收益遞減,因為節點變得過大,抵消了路徑縮短的優勢。
GD-3(3,213 毫秒,5.20 Mgas/s)和 GD-4(3,067 毫秒,5.46 Mgas/s)在讀取方面表現接近,GD-4 如預期般因路徑較短(64 vs ~86 節點)而略微領先。GD-3 較小的節點序列化大小(約 256 位元組 vs GD-4 的約 512 位元組)與 Pebble 的 4KB 區塊大小產生了有利的互動,使得兩者在樹狀結構截然不同的情況下,差距保持在 5% 以內。Pebble 區塊大小的互動仍值得進一步探索(開放性問題 #3)。
每個插槽的成本:合成讀取成本約為 0.02 毫秒/插槽。ERC20 讀取成本約為 0.4–1.0 毫秒/插槽(計算方式為 狀態讀取毫秒 / 每區塊讀取的存儲插槽數)——隨機存取模式帶來了 40 倍的懲罰。這 40 倍的比率與原始 NVMe 測量結果一致:Gary Rong 的磁碟分頁讀取基準測試 顯示 4KB 隨機讀取速度為 77 MB/s,而順序讀取為 3,306 MB/s(43 倍),證實了效能懲罰主要由 I/O 存取模式而非 Pebble 的開銷主導。
為什麼隨機存取是基準而非例外。 二元特里樹將所有帳戶和存儲統合成一棵樹。每個鍵(Key)——無論是帳戶餘額、存儲插槽還是代碼片段——都會被 SHA256 雜湊到 256 位元的鍵空間中。單個合約的存儲插槽會分散在完全不同的樹路徑上。這使得隨機存取成為二元特里樹的根本存取模式,而非極端案例。合成順序基準測試代表了一種在統一特里樹部署中不可能發生的、不切實際的最佳情況。到目前為止,越寬越好——直到某個點為止。GD-6 在讀取方面領先,GD-7 和 GD-8 顯示出收益遞減。接著我們測試了寫入。
S5 – 第二幕:寫入的驚喜
這是本研究中最重要的發現。
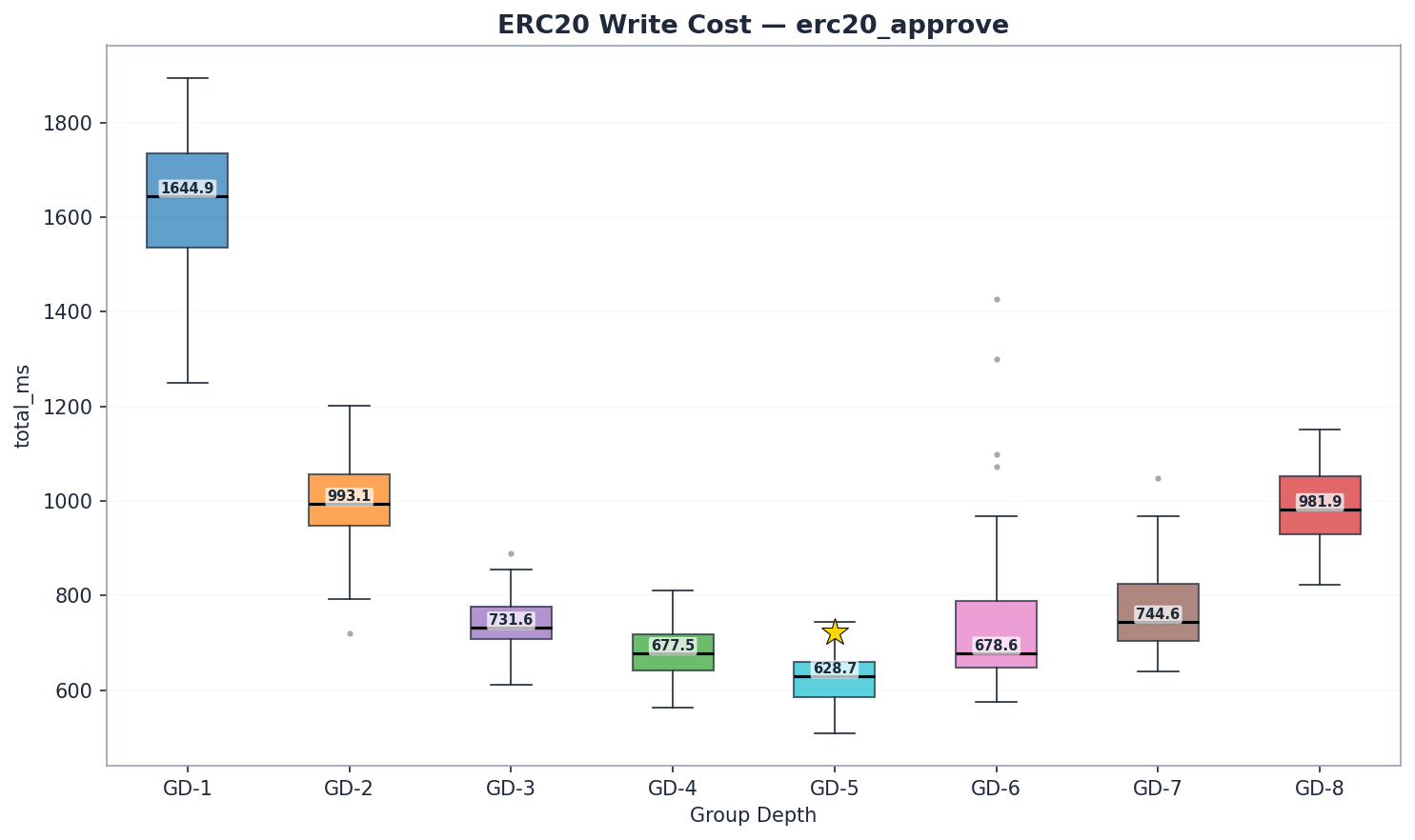
| GD | 狀態讀取 | 特里樹更新 | 提交 (Commit) | 總計 | Mgas/s |
|---|---|---|---|---|---|
| 1 | 812 | 691 | 77 | 1,645 | 2.67 |
| 2 | 483 | 393 | 61 | 993 | 4.42 |
| 3 | 349 | 287 | 44 | 732 | 5.95 |
| 4 | 313 | 254 | 53 | 678 | 6.47 |
| 5 | 271 | 242 | 57 | 629 | 6.94 |
| 6 | 272 | 283 | 76 | 679 | 6.41 |
| 7 | 264 | 328 | 103 | 745 | 5.81 |
| 8 | 313 | 433 | 158 | 982 | 4.47 |
*trie_updates = state_hash_ms (帳戶雜湊 + 帳戶更新 + 存儲更新) — 涵蓋完整的特里樹變更與重新雜湊階段,而不僅僅是雜湊。所有配置均在驗證過的冷快取協議下運行(運行間會清除 OS 分頁快取)。
第三階段的 Mgas/s 變異係數(CV)大多小於 10%,證實了測量的可靠性。*
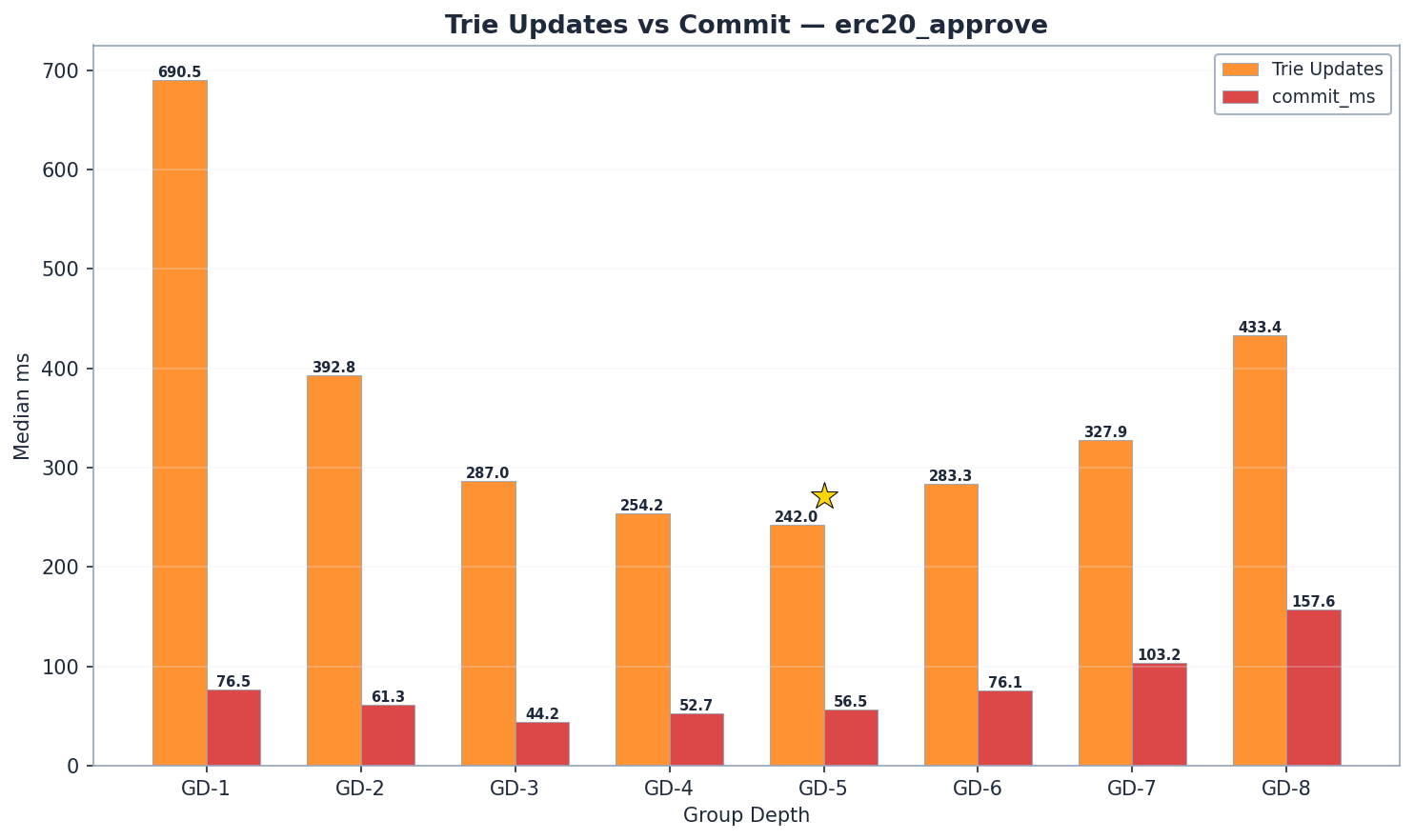
GD-5 是寫入冠軍。 6.94 Mgas/s —— 比 GD-4 快 7%(6.47 Mgas/s, p < 1e-9),比 GD-8 快 55%(4.47 Mgas/s)。GD-6(6.41 Mgas/s)排名第三,緊隨 GD-4 之後。GD-7(5.81 Mgas/s)證實了效能在超過 GD-6 後持續下降。
各項組成部分的分析說明了原因:
-
讀取: GD-5(271 毫秒)比 GD-4(313 毫秒)快 13%。GD-6(272 毫秒)與 GD-5 相當,而 GD-7(264 毫秒)讀取最快——但為了公平比較,必須將原始毫秒數與 Mgas/s 結合,因為每區塊的 Gas 量可能有所不同。
-
特里樹更新: GD-5(242 毫秒)比 GD-4(254 毫秒)低 5%。GD-6 適度上升至 283 毫秒(比 GD-5 高 17%),並未出現舊數據所暗示的劇烈崩跌。GD-7(328 毫秒)和 GD-8(433 毫秒)證實了效能持續下降。
-
提交 (Commit): GD-5(57 毫秒)略高於 GD-4(53 毫秒)。GD-6(76 毫秒,比 GD-5 高 33%)和 GD-7(103 毫秒)顯示出適度增長。
真正的提交效能崩跌發生在 GD-8(158 毫秒),這是由於約 8 KB 的節點 × 32 個路徑節點 = 每次寫入約 256 KB 的序列化數據。寫入效能的轉折點位於 GD-5 和 GD-6 之間:雜湊/讀取成本比率在 GD-6 處超過 1.0(283/272 = 1.04),這意味著特里樹更新成本開始超過讀取成本。以 Mgas/s 計算,GD-5 (6.94) 領先 GD-4 (6.47) 7%,領先 GD-6 (6.41) 8%。
為什麼?內部子樹
分組深度為 g 的每個特里樹節點都包含一個擁有 2^g - 1 個節點的內部二元子樹,每次寫入時都必須重新計算雜湊。
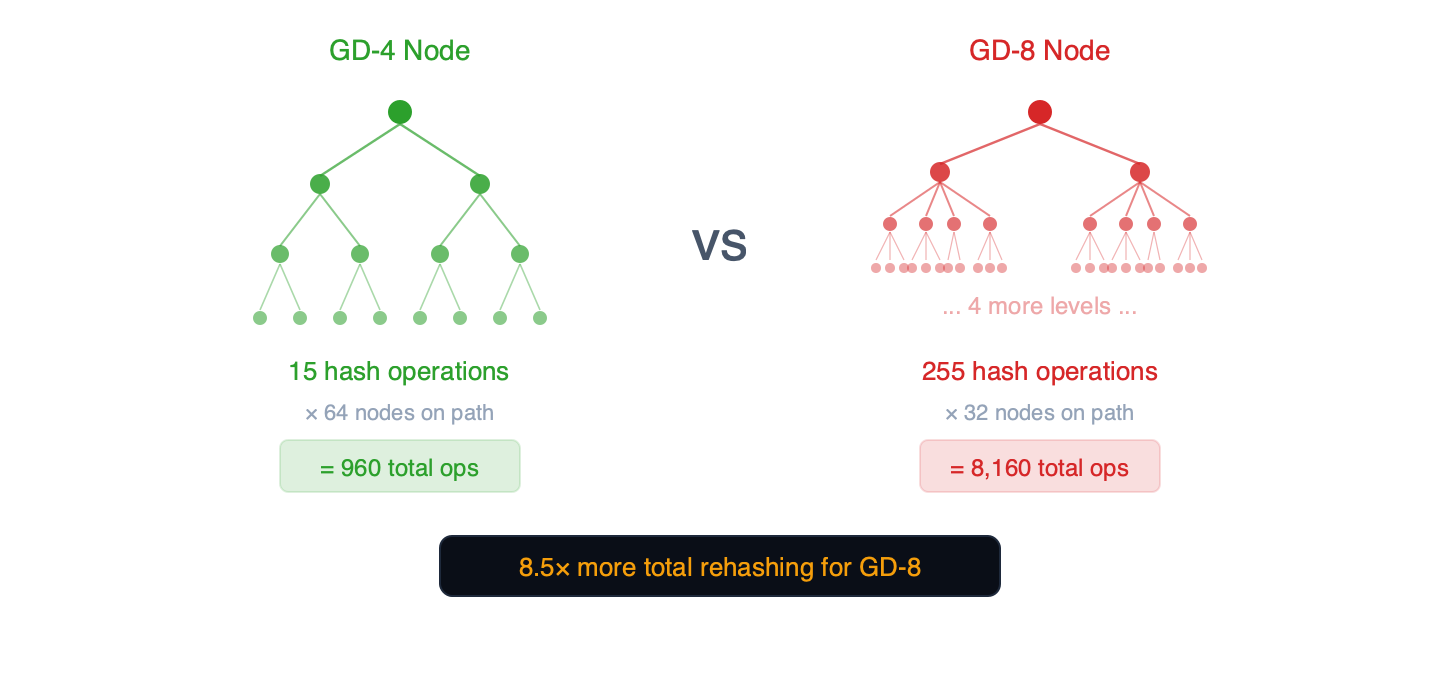
圖 3 – 每個特里樹節點都包含一個內部二元子樹。較寬的節點意味著每次寫入時雜湊計算量呈指數級增長。
- GD-4 節點: 15 次內部雜湊操作 × 路徑上 64 個節點 = 總共 960 次操作
- GD-5 節點: 31 次內部雜湊操作 × 路徑上約 52 個節點 = 總共約 1,612 次操作
- GD-8 節點: 255 次內部雜湊操作 × 路徑上 32 個節點 = 總共 8,160 次操作
GD-5 找到了寫入的最佳平衡點:其路徑比 GD-4 短 19%(約 52 vs 64 個節點),且每個節點 31 次內部操作仍屬可控範圍。在 GD-6(每個節點 63 個內部節點)時,重新雜湊成本適度上升——283 毫秒 vs GD-5 的 242 毫秒(+17%)。GD-7(328 毫秒雜湊,103 毫秒提交)證實了轉折點在 GD-6 之後繼續。寫入轉折點位於 GD-5 和 GD-6 之間,即雜湊/讀取比率超過 1.0 的位置。
註: 17 倍的比率(255 vs 15 次內部雜湊操作)是數據結構的理論上限。我們的基準測試支持這一機制:GD-8 的特里樹更新成本是 GD-4 的 1.71 倍(433ms vs 254ms),這與隨機寫入僅修改每個節點內部子樹的一小部分相符。Geth 的實作是精確重新雜湊演算法的權威來源。
節點序列化大小
每個特里樹節點存儲多達 2^N 個子節點指針(每個 32 位元組)。GD-4 節點:16 × 32 = 約 512 位元組。GD-7 節點:128 × 32 = 約 4 KB —— 正好是 Pebble 的區塊大小。GD-8 節點:256 × 32 = 約 8 KB。大小差異會產生連鎖反應:
- Pebble 區塊邊界: GD-6 節點(約 2 KB)可容納於單個 4 KB Pebble 區塊內。GD-7 節點(約 4 KB)使區塊飽和——加上鍵(key)的開銷,它們很可能跨越兩個區塊,潛在使每次節點獲取的 I/O 翻倍。
這部分解釋了 GD-7 讀取效能反轉的原因:儘管路徑節點比 GD-6 少 14%(37 vs 43),但 GD-7 每次查找總共讀取約 148 KB(37 × 4 KB),而 GD-6 約為 86 KB(43 × 2 KB)。
- Pebble 快取效率: 在給定的快取預算內,能容納的 GD-8 節點更少。
- 寫入放大: 較大的序列化節點增加了 LSM 樹壓縮(compaction)的開銷。
- 提交成本: 198% 的提交懲罰(158ms vs 53ms)部分反映了每個修改節點序列化數據量增加了 16 倍。

圖 4 – 對於讀取,僅向下遍歷重要(有利於 GD-8)。對於寫入,重新雜湊和提交佔主導地位(有利於 GD-4)。讀取 = 僅步驟 1。寫入 = 步驟 1 + 2 + 3。
S6 – 第三幕:權衡取捨
裁決
| 準則 | GD-4 | GD-5 | GD-6 | GD-7 | GD-8 |
|---|---|---|---|---|---|
| 讀取 (Mgas/s) | 5.46 | 6.11 | 6.39 | 6.04 | 5.59 |
| 寫入 (Mgas/s) | 6.47 | 6.94 | 6.41 | 5.81 | 4.47 |
| 混合 (Mgas/s) | 5.13 | 6.09 | 6.27 | 5.87 | 5.43 |
| 勝出類別 | 0/3 | 1/3 | 2/3 | 0/3 | 0/3 |
GD-6 在讀取和混合負載中勝出;GD-5 在寫入中勝出。 GD-5 的寫入效能比 GD-4 高出 7% (p < 1e-9)。GD-6 的讀取效能比 GD-5 高出 5%,混合負載比 GD-4 高出 19% (p < 1e-3)。GD-7 已過轉折點——在所有三項基準測試中均遜於 GD-6。
由於以太坊工作負載以讀取為主,GD-6 可能是較理想的預設值,而 GD-5 則最適合寫入密集型場景。
混合工作負載
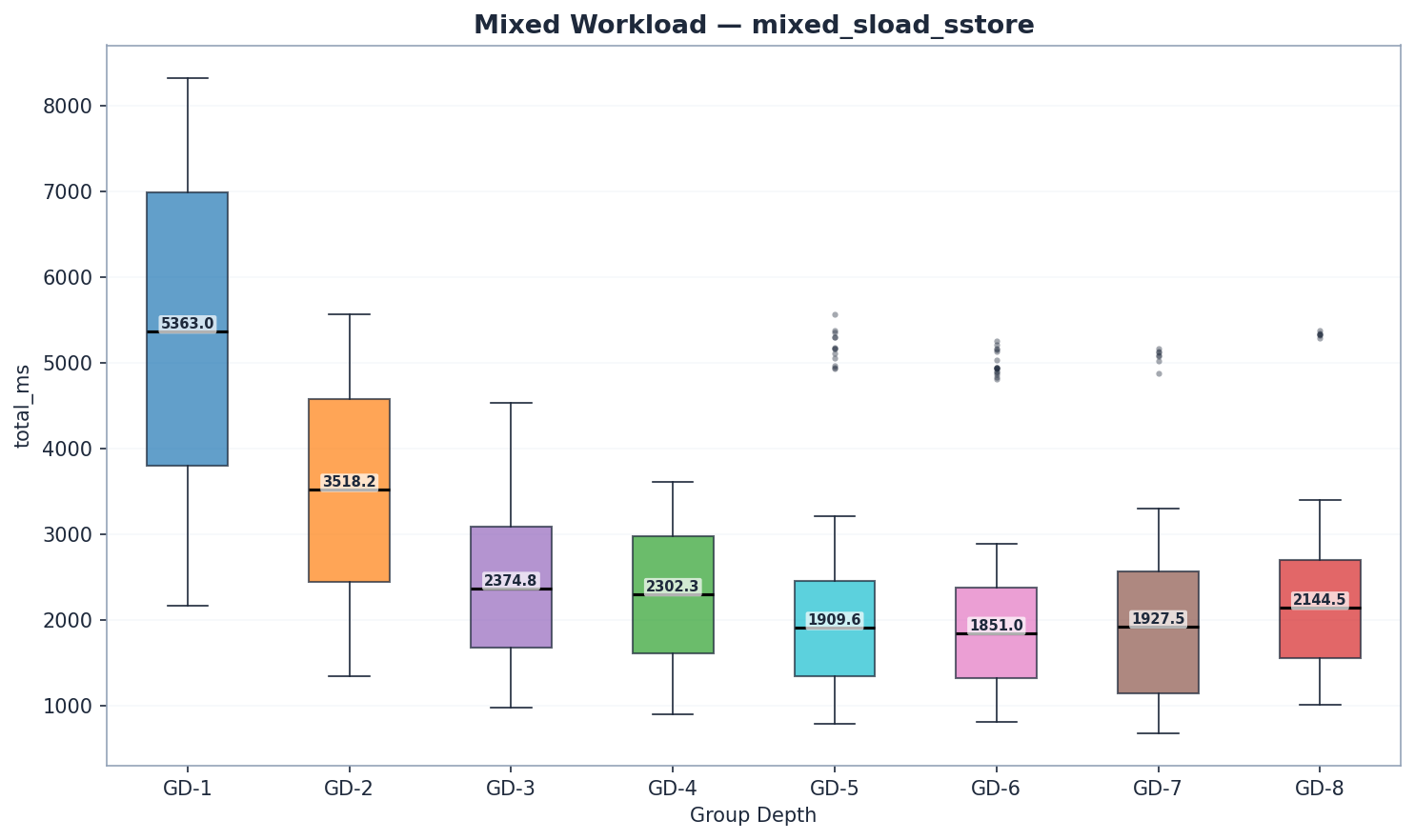
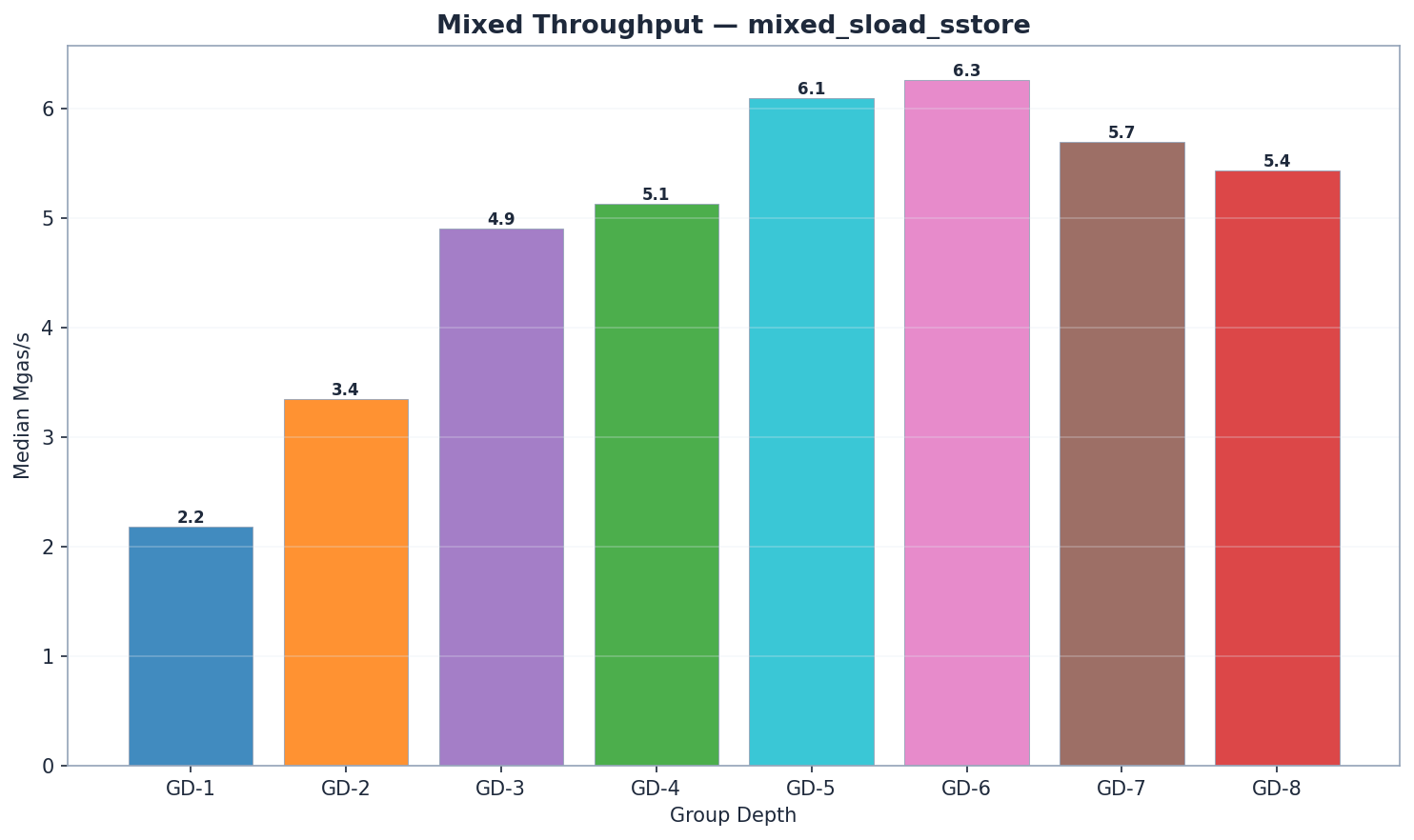
| GD | 狀態讀取 | 特里樹更新 | 提交 | 總計 (ms) | Mgas/s |
|---|---|---|---|---|---|
| 1 | 4,711 | 345 | 53 | 5,363 | 2.18 |
| 2 | 3,003 | 217 | 44 | 3,518 | 3.35 |
| 3 | 1,981 | 145 | 39 | 2,375 | 4.90 |
| 4 | 1,893 | 138 | 43 | 2,302 | 5.13 |
| 5 | 1,512 | 124 | 48 | 1,910 | 6.09 |
| 6 | 1,440 | 141 | 54 | 1,851 | 6.27 |
| 7 | 1,055 | 218 | 73 | 1,529 | 5.87 |
| 8 | 1,612 | 221 | 87 | 2,145 | 5.43 |
GD-7 的混合基準測試每區塊處理的交易較少(8.84M vs 約 11.80M gas)。Mgas/s 已針對此差異進行歸一化,因此吞吐量比較仍然有效。GD-7 混合測試的原始毫秒值無法直接與其他配置比較。
GD-6 在混合工作負載中以 6.27 Mgas/s 領先,GD-5 緊隨其後(6.09 Mgas/s,+3%)。兩者均優於 GD-4(5.13 Mgas/s)約 19–22%。GD-6 的讀取優勢(1,440 毫秒狀態讀取 vs GD-5 的 1,512 毫秒)超過了其略高的特里樹更新(141 毫秒 vs 124 毫秒)和提交成本(54 毫秒 vs 48 毫秒)。GD-7(5.87 Mgas/s)落後 GD-6 約 6%,證實了轉折點。
註:GD-7 混合測試使用 8.84M gas/block,而其他所有測試均為 11.80M;應以 Mgas/s 作為有效比較基準,而非原始毫秒數。
開放性問題: 最佳分組深度最終取決於真實以太坊區塊的讀寫比例。雖然在我們的基準測試中,狀態讀取顯然主導了區塊處理時間,但主網的確切比例尚未經過系統性測量。對主網讀寫存取模式的歷史分析將進一步完善此建議。
組件拆解揭示了熟悉的模式:
-
讀取: GD-7 的原始讀取時間最低(1,055 毫秒),但其每區塊 Gas 量也較低。以 Mgas/s 計算,GD-6 (6.27) 領先。GD-5 (1,512 毫秒) 和 GD-6 (1,440 毫秒) 在讀取方面優於 GD-4 (1,893 毫秒)。
-
特里樹更新: GD-5 領先 (124 毫秒),其次是 GD-4 (138 毫秒) 和 GD-6 (141 毫秒)。GD-7 (218 毫秒) 和 GD-8 (221 毫秒) 由於內部子樹較大而落後。
-
提交: GD-3 勝出 (39 毫秒),GD-4 (43 毫秒) 和 GD-5 (48 毫秒) 緊隨其後。GD-7 (73 毫秒) 和 GD-8 (87 毫秒) 顯示出較寬節點帶來的序列化懲罰。
S7 – 交叉觀察模式
時間花在哪裡?
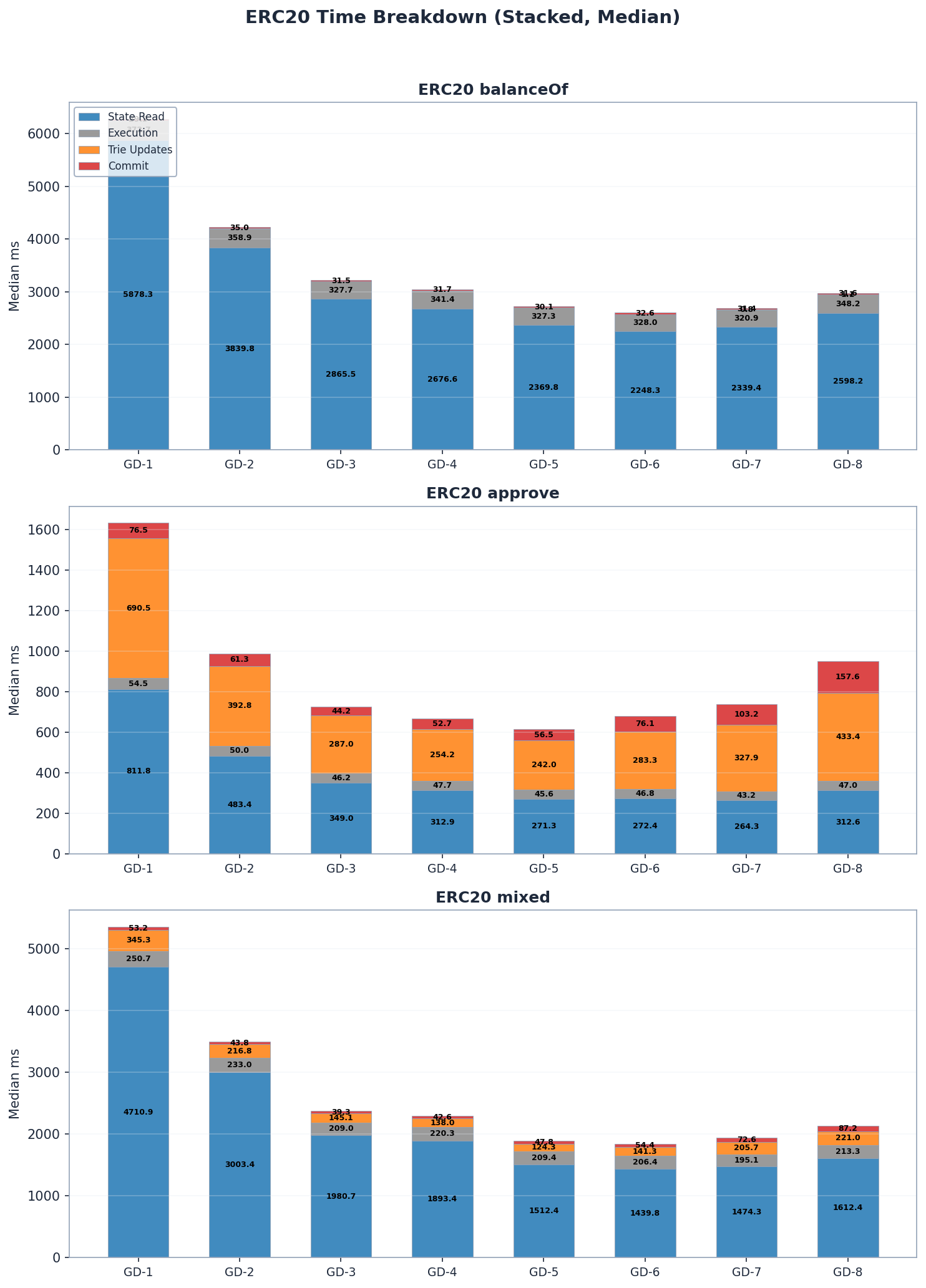
在所有分組深度配置中,狀態讀取主導了 ERC20 區塊處理時間,佔總時間的 50–85%。
特里樹更新和提交成本在純讀取基準測試(balanceOf)中微不足道,但在寫入(approve)中成為主要的成本組件——尤其是在分組深度較高、內部子樹重新雜湊最昂貴的情況下。
整體吞吐量
硬體背景:NVMe I/O 特性
Gary Rong 在 NVMe (Samsung 990 Pro) 上進行的磁碟分頁讀取基準測試為解釋我們的結果提供了硬體背景:
-
隨機 vs 順序: 4KB 隨機讀取 = 77 MB/s (50.6 µs) vs 3,306 MB/s 順序 —— 這 43 倍的差距與我們測得的 40 倍插槽懲罰密切相關。
-
分頁大小的重要性: 隨機 16KB 讀取的吞吐量是 4KB 的 2.3 倍 (174 vs 77 MB/s),而延遲僅增加 1.8 倍。較寬的分組深度會產生較大的節點,這可能從較大的 Pebble 區塊大小中受益。
-
隊列深度(Queue Depth)的變革性: 從 QD=1 到 QD=8 使隨機 4KB 吞吐量提升了 8.7 倍 (77 到 673 MB/s)。並行 EVM 可以釋放這一潛力,縮小不同配置間的讀取延遲差異。
-
次線性延遲增長: 從 4KB 到 64KB 數據量增加了 16 倍,但延遲僅增加 2.3 倍 (50.6 到 117.3 µs)。NVMe 的內部並行性意味著較大的 I/O 請求效率不成比例地高。
這些測量使用了繞過文件系統快取的直接分頁讀取——類似於我們的冷快取協議。基準測試硬體 (Samsung 990 Pro) 與我們 QEMU 虛擬機的虛擬磁碟不同,因此絕對數值不會完全匹配,但其比例揭示了與分組深度優化相關的基礎 NVMe 特性。
S8 – 結論
建議:GD-5 或 GD-6(視工作負載而定)
最佳深度為 GD-5 或 GD-6,具體取決於工作負載概況:
-
讀取密集型 / 混合工作負載(預設建議):GD-6。
讀取效能比 GD-5 高 5%(6.39 vs 6.11 Mgas/s),混合負載高 3%(6.27 vs 6.09 Mgas/s)。由於以太坊以讀取為主,GD-6 是首選預設值。 -
寫入密集型工作負載:GD-5。
寫入效能比 GD-4 高 7%(6.94 vs 6.47 Mgas/s),比 GD-6 高 8%(6.94 vs 6.41 Mgas/s)。 -
GD-7 證實了轉折點。 在所有三項基準測試中均遜於 GD-6(讀取 -5%,寫入 -9%,混合 -6%),驗證了最佳平衡點在 GD-5 或 GD-6。
此建議基於控制二元特里樹每次狀態存取的三步機制:
- 遍歷 (Traverse) —— 從根節點下降到葉節點。成本與樹深度成正比。有利於較寬的樹(GD-8: 32 層 vs GD-5: ~52 層 vs GD-4: 64 層)。
- 重新雜湊 (Rehash) —— 重新計算返回根節點路徑上每個節點的內部子樹。成本與每個節點的 2^g - 1 成正比。有利於較窄的樹(GD-4: 15 次操作/節點,GD-5: 31 次操作/節點,GD-8: 255 次操作/節點)。
- 提交 (Commit) —— 序列化並將修改後的節點寫入磁碟。成本與節點大小成正比。有利於較窄的樹。
GD-5 在寫入方面找到了「遍歷 x 重新雜湊」權衡的最小值。其路徑比 GD-4 短 19%(約 52 vs 64 個節點),且每個節點 31 次內部操作仍屬可控。在 GD-6 時,重新雜湊成本適度上升——283 毫秒 vs GD-5 的 242 毫秒(+17%)——但讀取和混合工作負載仍有改善。
寫入特定的轉折點位於 GD-5 和 GD-6 之間(雜湊/讀取比率超過 1.0),而讀取效能在 GD-6 達到頂峰。
GD-8 在所有工作負載中皆非最佳,證明了超過平衡點後收益遞減。GD-6 在讀取 (6.39 vs 5.59 Mgas/s)、寫入 (6.41 vs 4.47 Mgas/s) 和混合負載 (6.27 vs 5.43 Mgas/s) 方面均擊敗了 GD-8。最佳深度比最初假設的 GD-8 要窄。
關於快照層(Snapshot Layer)
這些基準測試是在沒有平面快照層的情況下運行的。通過 Pebble 的 BTree 索引進行二元特里樹路徑讀取已經非常高效,因此快照對於窄分組深度的額外收益可能有限。然而,較寬的分組深度(GD-6, GD-7, GD-8)可能會從快照中受益更多,因為它們較大的節點會導致較高的單次讀取 I/O 成本,而平面鍵值查找可以繞過這一點(見開放性問題 #2)。
適用於所有分組深度的五種模式
模式 1:狀態讀取佔主導地位。 無論分組深度或基準測試類型為何,50–85% 的區塊處理時間都花在從磁碟讀取狀態上。
state_read_ms包含了統一特里樹中的帳戶和代碼查找,而不僅僅是存儲插槽讀取。模式 2:隨機存取每插槽成本約高出 40 倍。 Keccak 雜湊鍵 (ERC20) 的成本為 0.4–1.0 毫秒/插槽,而順序存取 (合成) 僅為 0.02 毫秒/插槽。這一差距是由於 Keccak 分散鍵導致的 Pebble 區塊快取未命中造成的。獨立的 NVMe 分頁讀取基準測試證實,隨機 vs 順序 I/O 幾乎解釋了所有的效能懲罰(詳見 S7 硬體背景)。
模式 3:快取命中率停滯在 ~37–39%。 儘管增加了分組深度,Keccak 雜湊工作負載的存儲快取命中率從未超過約 39%。256 位元的鍵空間過於稀疏,除了共享的高層特里樹節點外,無法實現有意義的快取重用。
模式 4:特里樹更新對讀取而言微不足道,對寫入而言則是主導因素。 balanceOf(純讀取):trie_updates < 1.3 毫秒。approve(讀取 + 寫入):trie_updates 高達 691 毫秒 (GD-1)。這種不對稱性意味著節點寬度的權衡僅對寫入工作負載有意義。
模式 5:Mgas/s 的運行間變異係數 (CV) 大多 < 10%。 第三階段驗證的冷快取清除(120+ 次成功,0 次失敗)在所有 8 種配置中產生了可重複的結果。相較於早期階段的改進驗證了冷快取方法論的有效性。
1 則貼文 - 1 位參與者