AI 現已能處理大規模且易於驗證的軟體工程任務,我已將預測時間線提前
我最近大幅縮短了對人工智慧發展時間線的預測,主要原因在於 Opus 4.5 等模型的表現超出預期,以及 AI 在處理大規模且易於驗證的軟體工程任務上,展現出強大的迭代與自我修正能力。
我最近對 AI 時間線進行了大幅提前的修正,並在某些領域觀察到了更快的進展。
^([1])
我最大的修正包括:(1) 到 2028 年底實現 AI 研發(R&D)全自動化的機率提高了近 2 倍(我目前的預測略低於 30%
^([2])
,而先前預期約為 15%;我的預測在反思上相當不穩定);以及 (2) 我預期 AI 在處理大規模、相當困難但「易於且廉價驗證」且不需要太多新穎構思的軟體工程(SWE)任務上,短期內會有更強的表現
^([3])
。例如,我預期到 2026 年底,AI 在這類任務上的「50% 可靠性時間跨度」將達到數年到數十年(而高可靠性——例如 90%——的時間跨度會短得多,更接近數小時或數天而非數月,儘管這對任務分佈非常敏感)。在這篇文章中,我將解釋為何做出這些修正、我現在的預期以及這些修正的影響。
為了簡潔,我將「易於且廉價驗證的軟體工程任務」稱為 ES 任務,將「不需要太多構思(即不需要『新』想法)的 ES 任務」稱為 ESNI 任務。
以下是我修正預測的主要驅動因素:
-
Opus 4.5 和 Codex 5.2 的表現均顯著超出我的預期(無論是在基準測試還是其他信息源上)。這本身並不算太大的修正,我們本就該預期會有一些波動,且某些模型會有較大幅度的躍升;但在 Opus 4.5 和 Codex 5.2 之後,Opus 4.6(以及可能的 Codex 5.3 和 5.4)再次超出我的預期。在 2025 年,我們看到 METR 50% 可靠性時間跨度大約每 3.5 個月翻倍一次,且在 2026 年初出現了一次巨大的躍升(儘管測量結果尚不穩定)。
-
我看到了 AI 在僅使用中等複雜度的腳手架(scaffolding)下,完成非常龐大且令人印象深刻的 ES 任務的演示。 也就是說,這些任務通常需要人類花費數月到數年的時間(其中一些任務並未被網路上的結果污染,排除了數據洩漏的解釋)。這些演示包括:我用自己寫的腳手架完成的各種任務、由 Claude(幾乎完全)自主編寫的 C 編譯器、我看到的一些網路安全結果,以及 METR 即將發布的一些結果。因此,我暫且相信(截至 3 月 1 日),在充分誘發潛力的情況下,ESNI 任務的 50% 可靠性時間跨度(僅使用公開模型)大約在一個月到幾年之間(假設 AI 的 token 和實驗總預算與人類完成相同工作所需的成本相當)。我認為高可靠性(如 90%)的時間跨度則要低得多。
-
我現在預期 2026 年訓練算力將大幅擴張(可能主要是預訓練),且我預期這將帶來巨大的回報。
-
我修正了對大型任務中「腳手架懸置(scaffolding overhang)」規模的看法,現在認為其比我先前想的更大(基於對 AI 在不同腳手架下表現的觀察)。因此,我預期透過相對簡單的腳手架改進,就能在實用性上比目前廣泛公開使用的工具實現顯著提升。
我先前認為 2026 年的前沿 AI 進展會比 2025 年慢一些
^([5])
(以有效算力或類似 ECI 的指標衡量),但由於上述因素,我現在預期 2026 年的進展將比 2025 年快上不少。
值得注意的是,AI 在研發上變得更有用,會加速 AI 本身的進展(除了這本身就代表更接近各個里程碑之外)。因此,當我修正時間線認為進度提前,且 AI 在較低能力水平下就更有用時,我也同時修正了對今年進展速度的預期。
^([6])
我過去犯的一個關鍵錯誤是:ESNI 任務的 50% 可靠性時間跨度現在看起來比 METR 的任務集(及類似任務分佈)長約 20 倍——甚至超過 100 倍也是合理的——但我先前預期的差距僅約 4 倍。(這個錯誤在我這篇文章的預測中非常明顯。)(此外,AI 在「AI 公司隨機選擇的內部任務」上的時間跨度也比在 METR 任務集上短,但這看起來大約是 2 到 3 倍的差距,且目前似乎沒有迅速擴大的跡象。)
這些易於且廉價驗證的任務是怎麼回事?
如何解釋在 ES 任務上的極高表現?核心在於你可以讓 AI 開發一套測試套件/基準測試集,然後它就可以花費大量時間透過針對該評估集優化其解決方案來取得進展。這在以下情況最有效:基於測試/基準結果進行增量改進/修復通常是可行的(且 AI 很容易看出需要修復什麼)、開發足夠好的測試套件並不難,且運行測試套件也不難。這些特性適用於許多定義明確、完全基於命令行界面(CLI)
^([7])
的軟體任務(以及專注於改進某些相對直觀指標的軟體任務)。
這種類型的循環意味著,即使 AI 有時會感到困惑或做出錯誤判斷,也存在某種修正因素,錯誤通常不會是致命的。你可以採取一些措施,例如讓多個不同的 AI 編寫測試集,或讓 AI 隨時間增量改進測試套件,以避免測試中的錯誤導致整體失敗。在許多其他類型的任務中,AI 受限於判斷力較差或犯下愚蠢錯誤且難以識別這些錯誤。但是,有了持續迭代的能力,它們就能表現出色。
我認為在 ESNI 任務上,我們已經進入了 50% 可靠性時間跨度的「超指數級進展」階段:因為足夠的通用性和錯誤恢復能力允許無限的時間跨度(AI 可以不斷發現並從錯誤中恢復),超過某個點後,每一次時間跨度的翻倍都會比前一次更容易。關於超指數性的更多討論,請參見這裡和這裡。進入 ESNI 任務超指數階段所需的通用性水平較低,因為錯誤更容易被發現和修復。
我之前沒有正確評估的一個核心點是:任務「易於且廉價驗證」在兩個層面上都有幫助:它既讓 AI 公司更容易優化(無論是直接在 RL 中還是在「外環」指標上),也讓 AI 本身更容易在運行時持續投入勞動力。
因此,我們可以想像一個任務層級:
- ES 任務
- 易於檢查以進行訓練/評估,但 AI 本身不易自行檢查的任務
- 難以檢查的任務
看起來 (1) 和 (2) 之間的差距遠大於 (2) 和 (3) 之間的差距。
另一個維度是任務需要多少構思。越是需要聰明的想法,AI 就越難以進行高度迭代。更廣泛地說,任務在多大程度上適合增量迭代各不相同。某些類型的軟體(如分佈式/並發系統和算法密集型軟體)在迭代構建上要困難得多。而許多軟體則更偏向於「瑣事密集型(schlep-heavy)」,只是大量需要完成的不同事項,這使得增量進展更為可行。(核心問題在於:仔細理解廣泛複雜的整體並想出良好的結構/方法有多重要,vs 你是否可以只在較小的組件上進行迭代。)
同期獲得的一些反對縮短時間線的證據
我們可能會好奇,METR 的任務集和類似評估是否只是因為誘發不足,而更好的腳手架(例如讓 AI 編寫測試並針對測試進行優化)會產生巨大差異。我目前認為,某些類型的更好腳手架在 METR 任務集上可能會產生中等程度的差異,但這並非 ESNI 任務與 METR 任務集之間時間跨度差距的主要驅動因素。大部分差距在於任務分佈(可檢查性、可迭代性,以及剩餘未解決的任務並非核心 SWE 任務),AI 在目前的任務集上實際上受到了真實能力限制的瓶頸(儘管由於任務分佈的原因,這些能力限制並不強烈排除 AI 研發的大幅加速)。即便如此,我認為腳手架正變得越來越重要,對下一代模型而言影響會更大。(簡而言之:我認為當任務規模大到足以佔據模型上下文窗口的很大一部分——例如至少 1/3 時,腳手架對當前和近未來的 AI 非常重要。)
我認為 AI 在許多領域的「品味」和「判斷力」相當糟糕(通常在難以進行強化學習的領域更甚),且這方面的進步速度顯著慢於一般的代理能力。所謂「品味」和「判斷力」,我指的是類似於「在不完全直觀的情況下做出合理/良好的決定,並擁有良好的直覺」。這包括 SWE 品味,根據我的經驗,這通常是處理定義較模糊的 SWE 任務的主要瓶頸,且即使在定義明確的 SWE 任務中,似乎也是代碼質量的主要瓶頸。
一種解釋是,品味主要由預訓練進展或在該領域的強化學習驅動(我認為品味目前在不同領域間的遷移效果並不好),因此在缺乏強化學習的領域,進步主要來自預訓練。而預訓練的進展速度可能比整體 AI 進展慢 2-3 倍。
然而,我確實認為我們可能會在 2026 年看到特別快的預訓練進展。因此,我認為這些阻礙因素可能會迅速改善。
在嘗試自動化各種經驗研究項目的過程中,我看到 AI 做了很多愚蠢的事情(儘管我認為其中一些看起來像愚蠢的行為,可能更好地解釋為對齊問題/不良的 RL 激勵)。
為什麼 ESNI 任務的高表現會縮短我的時間線?
主要原因包括:
-
通用能力修正:我先前不認為 AI 現在就能做到這一點,且這些任務直觀上很困難。這讓我上調了對 AI 整體能力和 RL 效果的評價。更廣泛地說,我只是基於「事情進展比我預期的快」而進行修正。
-
超指數性:ESNI 時間跨度的進展似乎顯著呈現超指數級,所以我們現在在一個具有中等代表性的領域看到了超指數性的實際案例,且它似乎帶來了非常快的翻倍時間。這種超指數性也比我預期的中位數(就 50% 可靠性時間跨度和定性能力而言)更早開始顯現。
^([8]) -
AI 研發加速:我認為在 ESNI 任務上的極強表現(尤其是極其、極其強大的表現)很有可能讓 AI 顯著加快 AI 研發速度。正如我將在下一節討論的,目前尚不清楚這種加速會有多大,但它可能會非常顯著,特別是如果 AI 在構思瓶頸型任務上變得更好的話。此外,ESNI 任務的高表現使得「相對較小的能力提升就能極大改善某些任務的表現」變得更具說服力,這些任務雖然不完全是 ES 任務,但擁有相當不錯的進展指標(雖然指標可能被操縱或無法完美捕捉質量,但指標提升通常意味著表現提升;例如驗證成本高昂或需要一定判斷力的任務)。
-
腳手架和提示詞的誘發不足:雖然解鎖這些能力所需的腳手架並不複雜,但相對基礎的腳手架確實不足以應對,我的理解是,透過更好的(通用型)提示詞和腳手架,ES 任務的表現可能還會大幅提升。我也認為這通常適用於 AI 目前能力極限的大規模任務。這讓我認為「誘發不足」的情況比我先前想的更嚴重。我還認為 AI 可以更好地適應這些大型腳手架,並在這些腳手架中獲得更好的操作直覺(例如如何為其他 AI 編寫指令),這將進一步提升表現。
ESNI 任務的極高表現在多大程度上能幫助 AI 研發?
默認情況下,目前進行的 AI 研發中,並非很多都是直觀的 ESNI 任務。AI 公司的 ML 研究通常要麼需要昂貴(可能非常昂貴)的驗證/評估,要麼需要相當程度的品味和判斷力來構思想法、設置實驗或解釋結果。構建基礎設施或進行效率優化更接近 ESNI,但通常也不完全是 ESNI。
AI 研發中哪些部分屬於 ESNI?
-
在給定精確架構/實驗規格的情況下,實現優化版本的實驗或架構。(例如允許將小規模行為與未優化的已知正確實現進行比較。)這可能非常有幫助,使使用更複雜、基礎設施難度更高的架構變得更可行。它也使異構計算更具可行性。(優化全規模訓練運行的許多部分並非 ES 任務,因為驗證正確性和效率需要昂貴的實驗,且某些優化並非純粹的行為保持——例如,增加異步性對性能影響有多大?)
-
構建或優化用於研究的、定義明確的內部工具/基礎設施。
-
某些結果易於驗證的 ML 實驗,最顯著的是一些擁有良好(且廉價)基準測試的提示詞和腳手架實驗。也可能存在有價值的小規模 ML 實驗(儘管從這些實驗中獲取大量價值可能受限於構思能力)。
-
優化 AI 的某些應用(無論是在公司內部還是為了增加收入)。
以下是一些可能屬於也可能不屬於 ESNI 的任務:
-
構建 RL 環境。驗證 RL 環境是否合理並不容易,且目前尚不清楚如果相當一部分 RL 環境存在缺陷,後果會有多嚴重。
-
收集和處理數據。
因此,天真地想,我們預期僅在 ESNI 任務上的極高表現會帶來中等程度的加速,導致 AI 公司迅速在其他方面遇到瓶頸。當然,目前的 AI 在其他任務上也有些許幫助,且通常可以加速許多工程工作。
我對 AI 研發中有多少屬於 ESNI 任務並沒有十足的把握,且 AI 公司可能會想出更好的方法來利用類 ESNI 的 AI 能力。
我確實認為,如果 AI 在 ESNI 任務上達到瘋狂的超人水平(特別是如果它們在更廣泛的 ES 任務類別上達到瘋狂超人水平),它們有可能透過(例如)僅憑小規模實驗實現的巨大改進,來大規模加速 AI 研發。作為一個極端的假設,如果 AI 在 ES 任務上的成本比人類便宜一兆倍且速度快一兆倍(但在其他任務上能力僅與目前 AI 相當),我認為 AI 研發進展會透過某種機制(可能與驅動目前進展的機制截然不同)而大規模加速。
一個巨大的限制因素是「易於驗證」這一面。如果 AI 使用昂貴資源的樣本效率能高於人類(同時在直觀但可能驗證昂貴的領域仍然非常出色),那麼 AI 研發的加速將是巨大的,根據細節,這甚至可能實現 AI 研發的全自動化。但是,比頂尖人類專家更有效地使用昂貴資源,實際上意味著擁有與頂尖人類專家匹配(或超越)的研究品味,以目前的進度來看,這似乎至少還需要幾年時間。然而,AI 可能不需要那麼有效地利用資源就能產生巨大的加速。我的理解是,目前的許多進展來自相對乏味(且構思瓶頸不強)的研究。也就是說,品味不算頂尖但速度極快的工程師也能帶來巨大的加速。具備中等品味提升的 AI 可能就類似於這樣的工程師。這種 AI 的使用仍需要人類提供想法和部分品味,但 AI 可以自主完成項目的很大一部分(可能自主完成數月的工作)。
某些資源利用率低的問題感覺相當容易解決(例如,Opus 4.5 有點太吝嗇,而我發現 Opus 4.6 有點太揮霍),但最終我最好的猜測是,這需要相當好的品味和判斷力,這將有些難以實現。值得注意的是,在與 AI 部署規模相同的資源使用規模上進行 RL 通常是不可行的。即便如此,從較小資源消耗任務中進行遷移可能並不難,且某些 RL 可以涉及 AI 使用比 RL 展開(rollouts)本身昂貴許多倍的資源(匹配部署資源規模的很大一部分)。
^([9])
我嘗試使用當前模型自動化安全研究的經驗
我最近一直致力於嘗試利用 AI 自動化經驗性 AI 安全項目,這既是因為這具有實質性的用途(至少在注意能力外部性的情況下),也因為這有助於更好地理解未來安全自動化的阻礙因素,以及如何更安全地委託給 AI。作為這項工作的一部分,我編寫了一個代理編排器(agent orchestrator)和其他各種工具,試圖讓 AI 更擅長此類工作。
早期,我面臨的主要阻礙之一是 Opus 4.5 總是無法以所需的徹底程度完成整個任務(經常跳過任務的大部分內容)。我能夠透過各種方式修補這些指令遵循問題,並透過更好的提示詞和腳手架/編排解決其他一些問題。但是,我仍然看到(平凡的)不對齊問題對生產力造成的嚴重打擊,我即將發表一篇關於當前模型不對齊問題及其為何成問題的文章。
目前,在我嘗試自動化的(小型)項目中,最大的阻礙是品味/判斷力不足,AI 會做出一些糟糕的選擇,或者在某些東西實際上不好時認為它很好。我已經成功地讓整個系統完成相對直觀項目中相當大的部分(對於未加速的人類來說,大約相當於一天到幾週的工作量),通常透過讓 AI 更徹底地完成項目來補償品味的不足,實際上是做了更多低價值的工作。
總體而言,我認為自動化許多週定義明確的安全研究很快就能實現。
我觀察自己的設置是否能自動化大規模 ES 任務的經驗
我還運行了上述設置,嘗試「幾乎完全自主地」完成:
- 2 個大規模(例如需要 3-30 人/年)的易於且廉價驗證的 SWE 任務
- 一個困難的、易於且廉價驗證的 AI 研發任務
- 幾個(有些深奧的)ARC 理論感興趣的「數字增長」優化任務
- 一些 METR 較難且定義較模糊的任務(這些不完全是 ES 任務)
- 在相對防禦嚴密的目標上進行漏洞發現和端到端(網路安全)利用任務
我進行前兩個任務主要是為了更好地了解 AI 的能力。出於幾種原因,我不打算在本文中說明具體任務是什麼。
我總體上發現 AI 能夠取得相當多的自主進展,這與其他人看到的結果一致,而進展的程度很大程度上取決於任務的細節。
(我使用了稍微不同的提示詞和不同的腳手架設置進行了多次運行,通常結果對這些變動驚人地不敏感。)
SWE 任務
我發現 AI 在 SWE 項目中成功完成了看起來像許多個月(3-12 個月)的有益工作。在其中一個項目中,AI 在某些方面似乎已經擊敗或接近擊敗一個大型且中等複雜度的閉源軟體,但在其他方面則未能匹配(且存在各種錯誤和未實現的功能)。對於另一個項目,它們產出的東西雖然令人印象深刻,但大多比目前該類型最好的開源項目要差。代碼質量很低,但我後來開發了一些方法,可能會讓代碼質量達到基本合格(但仍不算好,且可能在某些地方代碼質量極低)。
我應該說明,我在開始這些項目時提供了相當數量的指導,包括追求什麼、使用什麼指標以及使用什麼基礎設施等,這花了我大約 1-2 小時來編寫,但其中大部分是可以分攤到多個任務中的(我已將這些指導重用於其他任務),且一兩個小時並不算長。
AI 相當頻繁地做出糟糕的優先級選擇,且傾向於在嘗試艱巨/嚴肅的改進之前就認為自己已經完成了。我不得不提醒它指標的優先級,督促它繼續進行,並提醒它定期清理代碼(儘管這些都已包含在指令中)。但是,透過持續迭代,這些糟糕的選擇並非災難性的。我還注意到相當程度的不對齊,AI 未能完全完成各種任務且沒有繼續工作,但我的腳手架基本上補償了這一點。
我預期,如果人類每隔一段時間(例如每個工作日)花 15 分鐘給 AI 提供建議,將會獲得巨大的回報。AI 經常犯一些對於甚至不太了解項目狀況的人類來說都非常明顯的錯誤(例如因為失去了大局觀)。但從我所看到的來看,AI 並不擅長吸收建議。
AI 似乎特別擅長軟體複製任務——也就是說,為某個閉源(或開源)軟體製作一個掉入式替換(drop-in replacement),並具備某些優勢(如速度、安全性、某些功能等)。METR 即將發布相關結果,我認為在更好的腳手架和提示詞下,表現會更強。
AI 研發任務
我測試的 AI 研發任務涉及改進已經高度優化的東西,因此 AI 很難取得進展。我暫且相信,相對於強大的人類專業人士,AI 在這項任務上取得了幾天到一週多一點的進展。在實踐中,它主要受限於 AI 不太擅長尋找好主意、決定研究哪些想法以及為每個想法分配時間/精力。它似乎把大部分時間花在嘗試透過微調來獲取收益,而不是進行實質性的改進。AI 的資源效率也很低,且由於花費大量時間等待多次運行,不擅長在有限時間內完成更多工作。其中一些資源使用問題可以透過更好的提示詞輕鬆改善。
網路安全
AI 在自主網路安全方面非常出色,尤其是在有中等程度腳手架的情況下。部分原因在於它擁有大量的領域特定知識。我目前不想評論我在 Opus 4.6 上發現的具體結果,但 Nicholas Carlini 的這場演講與此相關。
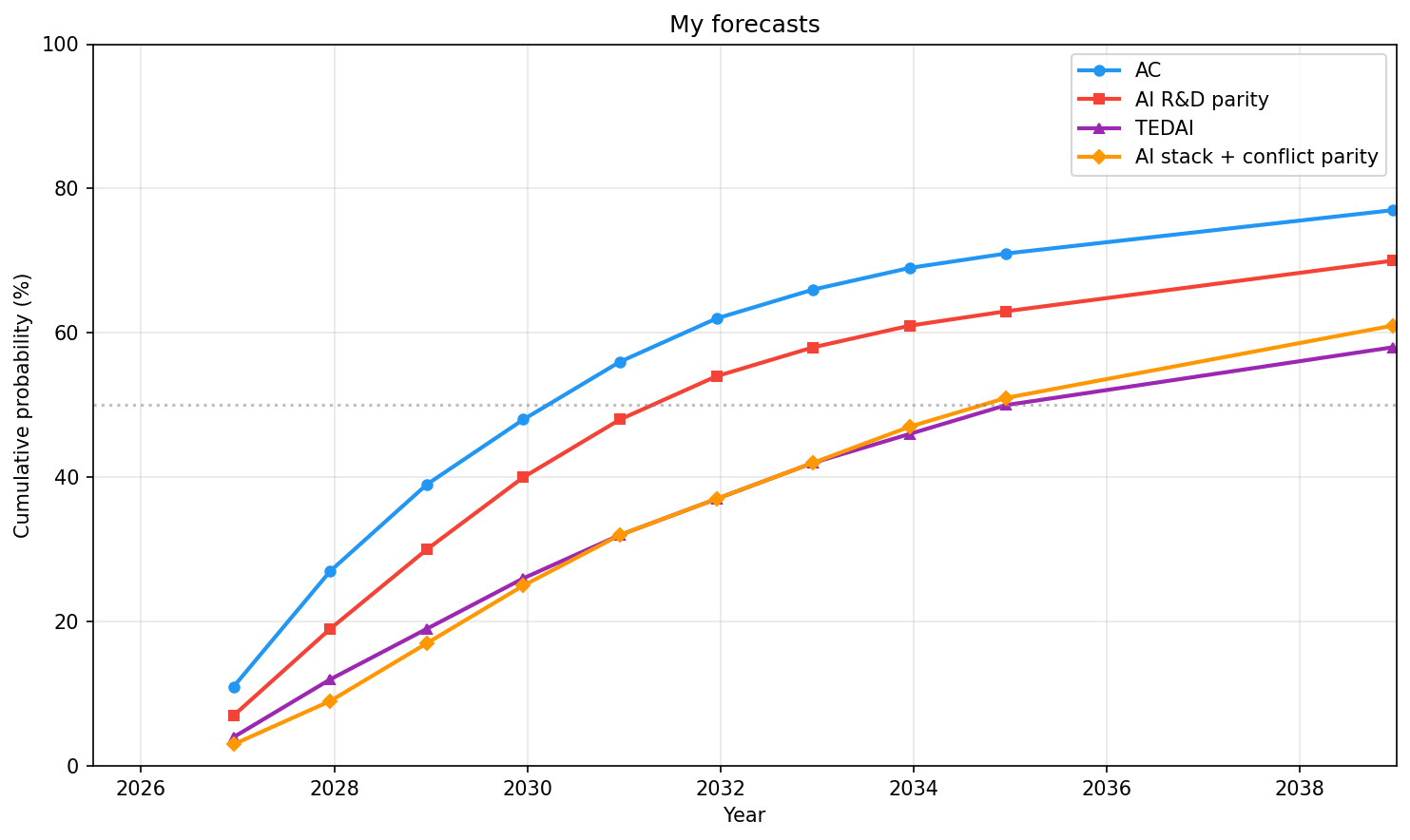
附錄:稍微更詳細的修正後時間線
我認為在本文中包含一些修正後的時間線可能會有所幫助。
我將使用 Cotra 在《AI 自動化的六個里程碑》(Six Milestones for AI Automation)中提出的「對等(Parity)」概念:
某個領域的對等:指在該領域中,解僱所有人類員工比退回到使用 2020 年代的 AI 更有利的時點。人類可能仍能在某些地方增加價值,且解僱所有人仍會使進度有所減緩,但 AI 集體的價值已超過人類集體的價值。
我還將預測「自動化編程員(AC)」和「超越頂尖專家的 AI(TEDAI)」
^([10])
,以便與 AI Futures Project 的觀點進行簡單比較。
我預測以下里程碑:
-
AI 研發對等:應用於領先 AI 公司研發工作的對等(其中「人類」指所有懂編程和/或從事過 ML 研究的人)。
-
AI 堆棧 + 衝突對等:應用於所有與 (a) 維護和改進 AI 堆棧以及 (b) 贏得戰爭(廣義)相關活動的對等。這包括:製造、建築、採礦和其他物理工業任務;能源、材料、硬體、生物技術、機器人、網路攻防等領域的研發;以及策略、戰術和物流等軟技能。請注意,這需要具備完全自主製造的能力。(我預留了一段短暫的適應期,在沒有進一步 AI 進展的情況下,允許重新調整機器人和製造產能。)
-
AC
-
TEDAI
請注意,(1) 與我歷史上使用的「AI 研發全自動化」的操作定義有所不同;它稍微弱一些。(因此我的機率相應地高一些。)
我的預測(大多?可能?)沒有考慮到旨在減緩 AI 發展的激進政策反應,但包含了「照常營業」的監管阻礙。這可能是一個錯誤。
| 日期 | 1. AI 研發對等 | 2. AI 堆棧 + 衝突對等 | 3. AC | 4. TEDAI |
|---|---|---|---|---|
| 2026 年底 | 7% | 3% | 11% | 4% |
| 2027 年底 | 19% | 9% | 27% | 12% |
| 2028 年底 | 30% | 17% | 39% | 19% |
| 2029 年底 | 40% | 25% | 48% | 26% |
| 2030 年底 | 48% | 32% | 56% | 32% |
| 2031 年底 | 54% | 37% | 62% | 37% |
| 2032 年底 | 58% | 42% | 66% | 42% |
| 2033 年底 | 61% | 47% | 69% | 46% |
| 2034 年底 | 63% | 51% | 71% | 50% |
| 2038 年底 | 70% | 61% | 77% | 58% |
作為比較,Cotra 對「AI 研究對等」(與我的 AI 研發對等相當)的中位數預測是 2030 年初(略早於我的中位數 2031 年初),她對「AI 生產對等」(與我的 AI 堆棧 + 衝突對等相當,儘管我的還包含衝突)的中位數預測是 2032 年中(早於我的中位數 2034 年底)。
雖然我給出了精確的數字,但我的觀點在反思上並不那麼穩定(例如,在過去一週思考之後,我對時間線進行了中等程度的延後修正!)。
^([11])
注意:我對從里程碑 A 到後續里程碑 B 的時間中位數,顯著小於我對 A 和 B 各自中位數的差值。這是因為對於右偏分佈,和的中位數大於中位數的和。直觀上:每個里程碑都有可能花費極長時間(重右尾),當你把延遲加在一起時,這些右尾會產生複合效應,將總時間的中位數推向比單獨中位數相加更遠的右側。因此 median(B) - median(A) > median(B - A),也就是說,中位數之間的差值誇大了里程碑之間實際時間的中位數。
^([12])
例如,我估計從 AI 研發對等(假設這發生在 2035 年之前)到 TEDAI 的時間中位數大約是 1.75 年,而我預測的中位數差值約為 3.5 年。
^([13])
-
我主要在 2026 年 2 月進行了修正,並在 3 月進一步完善了思考。↩︎
-
我對 AI 研發對等(解僱所有從事 AI 研發的人類比退回到使用 2020 年代的 AI 更好)的預測是 30%,但對於全自動化(解僱所有人類僅會使進度減慢約 5%)的預測則稍低,大約是 26%。↩︎
-
也就是說,不需要想出網路上還沒有的想法。如果任務的關鍵部分在於發現某些人知道但非公開的、難以找到的想法,這也會使任務對模型來說困難得多。↩︎
-
我所說的「50% 可靠性時間跨度」是指:如果你從相關任務分佈中隨機抽取任務,這是在該時間跨度內 AI 有 50% 成功機率的點。請注意,在實踐中,這主要是由任務間的差異(某些任務對 AI 來說比其他任務更難)驅動的,而不是模型在給定任務上隨機失敗。因此,稱其為「可靠性」有點不自然。我使用這個詞是因為 METR 這麼用,且讀起來很順口(例如「50% 可靠性」),儘管「成功率」可能更準確。↩︎
-
我之前的觀點是基於認為 2025 年進展特別快是由於 RL 中一些容易實現的目標,且部分進展來自於成本佔人類成本比例的增加。我認為這些因素在某種程度上仍然成立,只是我預期它們的重要性將低於其他因素。↩︎
-
我們不應重複計算這一點:我的觀點只是在其他條件相同的情況下,隨著越接近 AI 研發的全自動化,AI 進展會加速,而這已經計入我的時間線中。(在實踐中,我預期其他條件並非完全相同,且我預期算力擴張將在 3 年左右開始放緩,原因是生產能力限制或投資在達到極端水平後放緩。我認為我們已經看到 DRAM/HBM 算力生產問題的一些跡象,儘管值得考慮到適應能力和一定的滯後性。)↩︎
-
所謂「完全 CLI」,我指的是任務不需要視覺、電腦操作或非平凡的、難以程序化自動化的交互。↩︎
-
請注意,僅僅向我對超指數性開始顯現的中位數修正,也會縮短我的時間線;情況並非對稱的。根本原因在於,由於許多不同因素的緩慢尾部,我的時間線實質上更長。↩︎
-
你也可以進行在線 RL,但這有一些缺點。↩︎
-
我擔心他們的操作定義比他們預想的要弱。除了他們的遠程工作操作定義外,我還打算讓定義包括在任何相當重要的研發領域中,純遠程工作時擊敗人類專家。也就是說,在任何相當重要的研發中,撇開物理操作不談,你肯定會更傾向於僱用 AI 而非頂尖人類專家。↩︎
-
既然存在這種不穩定性,為什麼還要給出這麼精確的數字?我暫且認為我的精確度實際上代表了稍微好一點的猜測;例如,我預期如果被迫四捨五入到最接近的 5% 或 10%,我的預測表現會差一點,儘管我也很可能在進一步反思後大幅調整我的猜測,這兩者可以同時成立。此外,擁有一條平滑的曲線也很好。↩︎
-
在這裡,A 和 B 是對應於某個事件發生年份的隨機變量。↩︎
-
此外,如果 A 和 B-A 是相關的(正如我認為這裡討論的里程碑一樣,更短的時間線與更快的起飛相關),那麼以 A 較早達成作為條件,也會縮短 B 的預期剩餘時間。因此,如果我們在 2028 年中達成 AI 研發對等,那麼我預期到 TEDAI 的差距會更小。↩︎