我們是否已經失敗了?第二部分:走向毀滅的原因
我反思了 2026 年初人工智慧安全的現狀,並列舉了企業承諾失效、技術進步加速以及美國政府對人工智慧安全持敵對態度等原因,解釋了我對 2024 年計畫感到更加悲觀的理由。
這篇文章是為 Inkhaven Residency 快速撰寫的。
當我花時間反思 2026 年初人工智慧安全(AI Safety)的現狀時,一個問題似乎無法迴避:作為 AI 安全社群,我們是否已經輸了?也就是說,我們是否已經過了臨界點,在此之後,AI 毀滅(AI doom)既變得很有可能,且實際上已超出我們的控制範圍?
劇透:正如你可能從 貝特里奇標題定律(Betteridge’s Law) 中猜到的,我對標題問題的回答是「否」。但儘管如此,這個問題的顯著性對我來說仍非常值得注意,並反映出對未來更為負面的看法。
昨天,我闡述了我在 2024 年所理解的「計畫」。
今天,我將解釋為何我對 2024 年的計畫變得更加悲觀。(而明天,我將討論為什麼我認為答案仍然是「否」。)
更多毀滅理由
公司的(單方面)自願承諾似乎難以維持
在我們最初的 RSP 部落格文章中,我們勾勒了 RSP(負責任擴展政策)的願景,即公司「承諾將擴展規模掛鉤於具體的評估和經驗觀察」,其中「在我們確實看到危險能力的情況下,我們應該預期停止 AI 開發;而在對危險能力的擔憂被證明是過度擔憂的情況下,則繼續開發。」我認為從經驗上看,這種 RSP 的願景似乎不太可能奏效。
首先,繼 Anthropic 之後的許多前沿安全政策 在嚴格程度或規範明確度上都大幅降低。DeepMind 和 OpenAI 的政策可能是次好的,但在繼續部署的可接受條件方面,它們比 Anthropic 寬鬆得多。(此外,OpenAI 的 Preparedness 團隊似乎也經歷了不少常見的 OpenAI 安全人員離職潮。)許多公司的 RSP 完全沒有提到實際終止部署,而 XAI 的政策在 2026 年初可能就已經被違反了。
甚至連 2024 年與 METR 合作開創 RSP 先河的 Anthropic,也更新了其 RSP,使其比當初概述的內容寬鬆了許多。
AI 進展似乎與更快的時間線一致
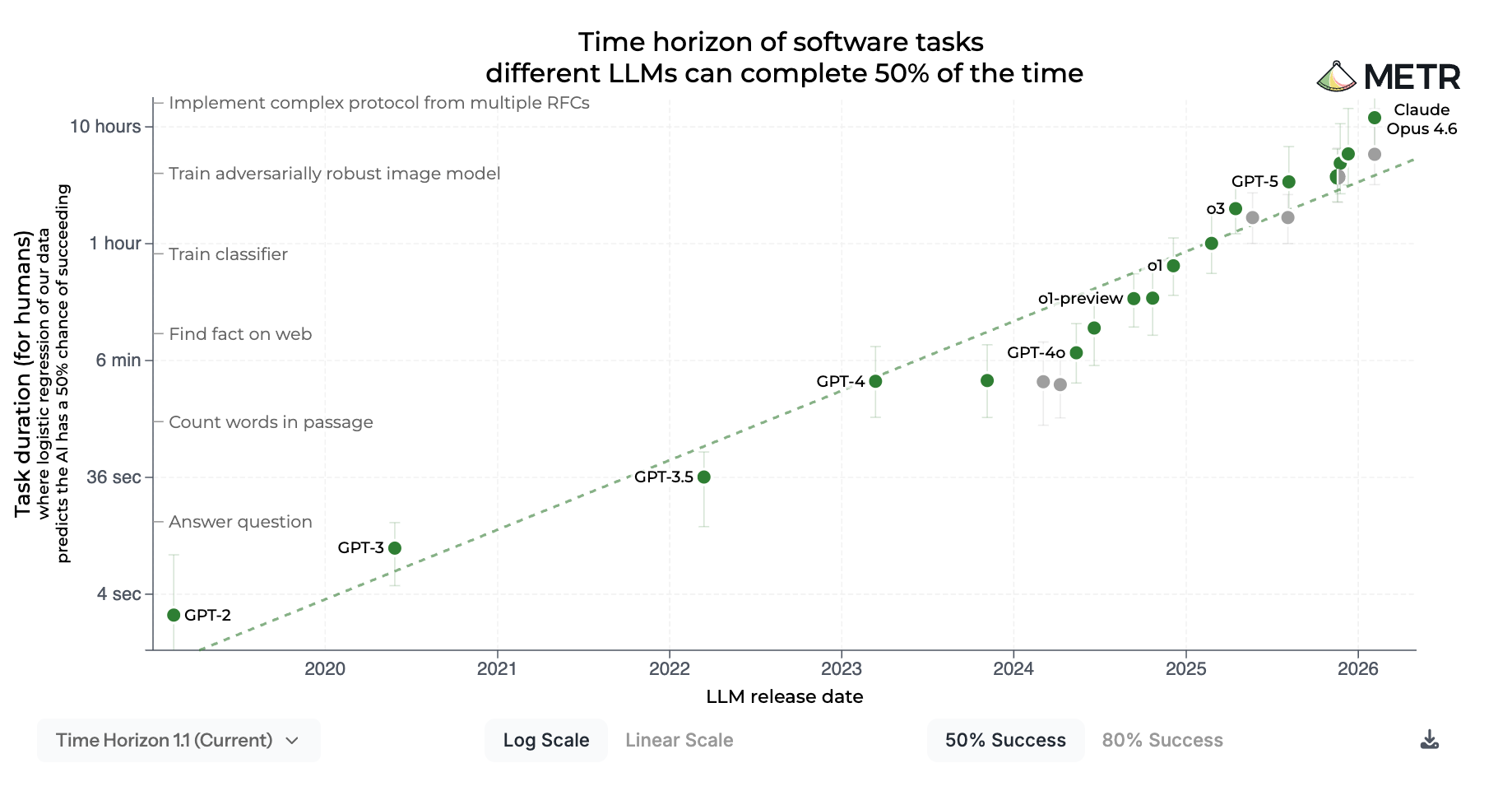
在 2024 年,人們感覺 AI 進展很快,但對於究竟有多快並沒有很好的概念。我認為到 2026 年,情況已經相當清楚:AI 的進展速度之快,使我們無法排除到 2028 年實現「接近全自動化編碼」的可能性,更不用說 2030 年或 2035 年了。
首先,最初於 2025 年 3 月發布的 METR 圖表發現,AI 能夠完成的任務長度呈現一致的指數趨勢,而這一趨勢在隨後的一年中得以維持(甚至加速):
我們還看到了 AI 編碼助手的海量使用,以及領先實驗室投資規模的大幅擴張,這僅僅是進展神速的另外兩個跡象。
就我們的計畫需要更多時間而言,更快的時間線絕對是個壞消息。
雄心勃勃的技術研究(很大程度上)尚未取得回報
在 2024 年,(雄心勃勃的)機械解釋性(mechanistic interpretability)雖有爭議,但仍是主要的投資領域。當時還有許多其他雄心勃勃的 AI 安全研究議程,旨在嚴謹地解決 AI 對齊問題的重要部分,例如 ARC 的 ELK/啟發式論證議程(Heuristic Arguments Agenda)、奇異學習理論(Singular Learning Theory)或非代理型 AI 科學家。雖然這些議程中的每一項工作都在持續進行,但沒有一個議程真正產生了巨大的回報。
社群的投資很大程度上集中在 Anthropic
在 2024 年,Anthropic 可能是全球所有組織中,技能加權後的 AI 安全人才最大消耗者。然而,當時它還只是佔據相對多數,而非絕對多數。
我認為在 2026 年,Anthropic 顯然消耗了技能加權後 AI 安全人才的絕大部分。這本身並不一定是件壞事:就「讓 Anthropic 獲勝」計畫是擁有餘裕去投資競爭力較弱但更安全的方法的主要途徑而言,這幾乎是必然發生的。但就 Anthropic 作為一個組織存在問題而言——例如,在 AI 安全的關鍵問題上出錯,或受利潤或地位動機驅動而產生動機性思維,或無法有效利用邊際人才——那麼從社群的角度來看,這顯然是一件壞事。
無論這在淨效應上是好是壞,我認為由於 Anthropic 的商業成功(以及 OpenAI 的幾波人才流失),AI 安全社群在 Anthropic 之外幾乎沒有獨立的存在,這仍然令人感到遺憾。
現任美國政府從 AI 安全的角度來看有許多惡劣特質,並明確反對「AI 安全」
11 月 5 日,當我看到初步選舉結果出來時,我心想,就 AI 治理而言,我們現在進入了「困難模式」。考慮到之後發生的一切,我認為我的評估相當準確。
許多我認為對國內 AI 治理有積極意義的進展,都被現任美國政府明確反對或撤銷。現任美國政府還採取了許多行動,使 AI 安全方面的國際合作變得更不可能,包括與美國許多現有盟友對抗。此外,政府的關鍵成員明確反對 AI 安全(有些人甚至散布瘋狂的陰謀論,聲稱所有的 AI 安全都是 Anthropic 企圖進行監管俘虜的手段)。
總體而言,這屆政府一直表現得極其愚蠢、腐敗且混亂。(最近的一個例子是,將 Anthropic 指定為供應鏈風險,以此作為一種(失敗的)談判策略。)