優化學術工作流程:推出兩款用於提升繪圖與同儕審查品質的 AI 代理人
Google 研究部門推出了 PaperVizAgent 與 ScholarPeer,這兩款 AI 框架旨在自動化生成達出版標準的學術圖表,並提供嚴謹且基於文獻的同儕審查,藉此優化學術研究生命週期。

改善學術工作流:推出兩款用於優化圖表與同行評審的 AI 代理
2026 年 4 月 8 日
Jinsung Yoon,研究科學家,以及 Tomas Pfister,Google Cloud 總監
推出兩款旨在簡化學術研究的 AI 代理。其中包括:PaperVizAgent,一款用於繪製學術圖表的視覺化代理;以及 ScholarPeer,一款能自動且嚴謹地評估學術論文的評審代理。
快速連結
在 AI 快速進步的推動下,學術研究正以史無前例的速度演進。學術研究的工作流程以嚴謹著稱,涉及的內容遠不止構思創意和撰寫論文。許多研究人員面臨的一個障礙是如何有效地將研究成果視覺化。雖然 AI 可以草擬文本,但要創建頂級會議和期刊所需的複雜方法論圖表和精確統計圖表則困難得多。此外,科學界依賴同行評審過程來維護已發表研究的完整性。然而,論文投稿量的指數級增長使該系統承受了巨大壓力,導致評審員疲勞和評估標準不一。隨著語言模型和多代理系統變得日益精密,我們看到它們的潛力不僅在於作為研究對象,更在於作為科學過程本身的積極參與者。
為此,我們推出了兩種新型代理框架:(i) PaperVizAgent(正式名稱為 PaperBanana),一款用於繪製學術圖表的視覺化代理;以及 (ii) ScholarPeer,一款能自動且嚴謹地評估學術論文(包括文中圖表)的評審代理。這些代理專為輔助學術研究生命週期而設計,旨在賦予科學家更多力量,使其專注於創新而非行政負擔。我們的評估顯示,PaperVizAgent 能穩定生成專家級質量的圖表,顯著優於領先的基準模型(GPT-Image-1.5、Nano-Banana-Pro、Paper2Any);而 ScholarPeer 則能提供極具批判性且基於文獻的評審,超越了目前最先進的自動評審系統。
PaperVizAgent:生成可供發表的圖表
PaperVizAgent 是一個自主框架,旨在根據學術文本生成可供發表的學術插圖。通過彌合技術描述與視覺傳達之間的鴻溝,PaperVizAgent 讓研究人員能直接根據手稿創建專業級圖表。啟動該過程時,研究人員需提供兩項輸入:
PaperVizAgent 框架協調了一個由五個專門 AI 代理組成的協作團隊,包括:(1) 檢索器、(2) 規劃器、(3) 風格器、(4) 視覺化器,以及 (5) 評論器。首先,檢索器和規劃器代理收集參考資料(例如參考相關學術圖表的現有文獻)並組織內容。接著,風格器代理綜合審美指南,確保輸出符合學術標準。隨後,視覺化器渲染圖像或為統計圖表生成可執行的 Python 代碼。最後,評論器代理根據原始文本評估輸出。如果發現不一致,評論器會向視覺化器代理提供針對性的反饋,觸發迭代優化的循環。通過迭代優化,這個多代理系統確保最終插圖既具視覺吸引力又具技術準確性。

給定來源語境和傳達意圖後,PaperVizAgent 會檢索相關的參考範例,並合成經過風格優化的描述。隨後,它利用迭代優化循環將描述轉化為最終插圖。

由 PaperVizAgent 生成的方法論圖表示例。
結果
在綜合實驗中,PaperVizAgent 的表現始終優於領先的基準模型——包括直接提示(direct prompting)、少樣本提示(few-shot prompting)以及 Paper2Any(一種最先進的視覺化方法)。該系統使用比較評分指標(採用 0-100 分制,分數越高越好),在四個關鍵維度上進行了嚴格評估:忠實度、簡潔度、可讀性和美觀度。在此評估中,我們使用了一個 LLM 裁判,該裁判使用人類生成的圖表作為輸入進行校準,並設定人類表現基準為 50.0。
PaperVizAgent 獲得了 60.2 的優異總分,顯著超越了所有受評估的基準模型,如 GPT-Image-1.5、Nano-Banana-Pro 和 Paper2Any。值得注意的是,它是唯一一個在總體評分中超過既定人類基準(50.0)的框架。細分具體維度時,該系統在「簡潔度」和「美觀度」方面表現尤為出色,得分均遠高於人類閾值。它在生成統計圖表方面也達到了與人類競爭的水平,證明了其多功能性。這些結果代表了自動化插圖領域的一次重大飛躍。

PaperVizAgent 在五項關鍵指標上均優於所有基準模型,達到了與人類基準相當的結果。
使用 ScholarPeer 模擬資深評審員
ScholarPeer 是一個具備語境感知和搜索功能的多代理框架,旨在通過遵循資深研究人員的工作流程,自動化並提升同行評審過程。
與將評審視為簡單文本生成任務的標準語言模型不同,ScholarPeer 依賴於語境獲取和主動驗證的雙流過程。它利用「子領域歷史學家代理」動態構建領域敘事,將評審建立在實時、網絡規模的文獻基礎上。「基準偵察員」則充當對抗性審計員,專門尋找作者可能遺漏的數據集或對比基準。最後,「多維度問答引擎」嚴格驗證論文的技術主張,確保評論深入且基於事實。最終的評審報告包括詳細摘要、優點、缺點以及給作者的問題,與標準的專家同行評審非常相似。

給定輸入論文後,ScholarPeer 採用雙流信息檢索過程。語境與知識模塊利用摘要器和具備搜索功能的文獻綜述來壓縮內部與外部信息。這些輸入進入多維度問答引擎,該引擎針對創新性和技術完備性生成並回答探究性問題。最後,評審生成器利用這些輸入和特定會議的評審指南生成最終評審。
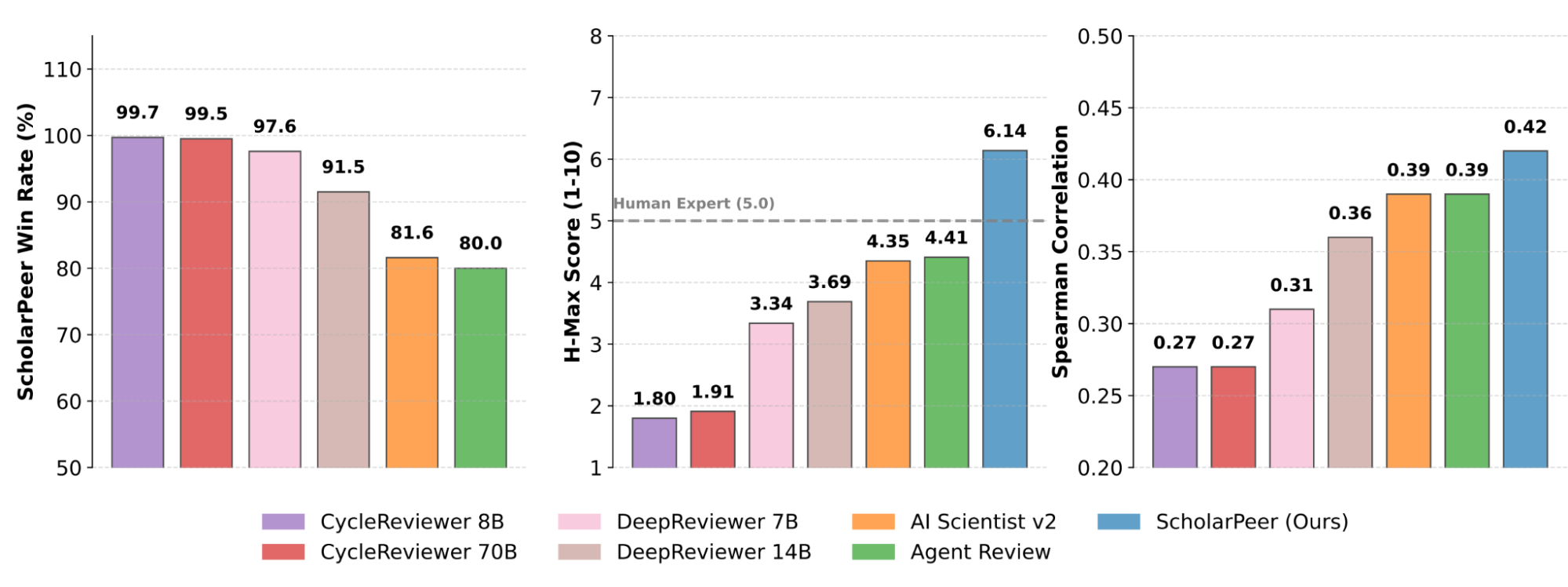
ScholarPeer 的表現展示了將主動網絡搜索與多代理協作整合用於學術評估的巨大潛力。在廣泛的公開數據集測試中,ScholarPeer 在側向對比評估中對最先進的自動評審方法取得了顯著的勝率。更重要的是,該系統的主動驗證工作流大幅縮小了 AI 生成反饋與人類水平多樣性之間的差距,產出的評審具有高度批判性、現實性,且深植於現有文獻中。

ScholarPeer 與現有框架在公開數據集上的對比評估。左:ScholarPeer 相對於微調模型和代理基準模型的勝率。中:各框架生成評審的平均單側得分(最佳人類評審視為 5 分)。右:人類專家評估與自動評審框架排名之間的相關性。
科學界的下一步
PaperVizAgent 和 ScholarPeer 是我們更廣泛探索 AI 輔助研究工作的一部分。通過應對出版生命週期中兩個不同但同樣要求嚴苛的階段,這些工具充當了提升科學對話質量的協作者,並能與其他工具一起加速知識的傳播。
雖然這兩個框架為學術界提供了即時且切實的利益,但它們僅僅是我們旅程的開始。我們預見未來研究人員將能使用一個豐富、互聯的 AI 助手生態系統,無縫整合到科學工作流的各個層面,而我們正積極在這一領域繼續工作。
致謝
我們要感謝 Palash Goyal, Dawei Zhu, Mihir Parmar, Rui Meng, Yiwen Song, Yale Song, Hamid Palangi, Xiyu Wei, Sujian Li 和 Burak Gokturk 對這項工作的寶貴貢獻。
免責聲明
PaperVizAgent 和 ScholarPeer 是實驗性研究原型,而非生產就緒的工具。其自動生成的反饋、圖表和評審僅用於研究探索,不應被視為編輯或出版決定的最終依據。
快速連結
其他感興趣的文章

2026 年 4 月 3 日

2026 年 3 月 24 日

2026 年 3 月 16 日