
繪製現代世界地圖:S2Vec 如何學習城市語言
我們推出了 S2Vec,這是一個自監督框架,能將複雜的地理空間數據轉換為通用嵌入向量,用以預測全球的社會經濟與環境模式。

繪製現代世界地圖:S2Vec 如何學習城市語言
2026 年 3 月 24 日
Shushman Choudhury,Google Research 研究科學家
我們推出了 S2Vec,這是一個自監督框架,能將複雜的地理空間數據轉換為通用嵌入(embeddings),用以預測全球的社會經濟與環境模式。
快速連結
當我們想到人工智慧與地理時,通常會關注導航,或如何從 A 點到達 B 點。然而,人造環境(built environment)——即定義我們世界的道路、建築、商業和基礎設施所組成的複雜網絡——所包含的信息遠不止地圖上的座標。這些特徵訴說著關於社會經濟健康、環境模式和城市發展的故事。
直到最近,將這些多樣化的地理空間特徵轉換為機器學習(ML)模型可以理解的格式,一直是一個手動且勞動力密集的過程。研究人員通常必須為他們想要解決的每個新問題親手設計特定的指標。在 Google Research,作為 Google Earth AI 倡議的一部分,我們開發了一種彌合這一差距的新方法,該倡議利用基礎模型和先進的 AI 推理將全球信息轉化為可操作的情報。
秉持著 EarthAI 的願景,我們最近推出了 S2Vec,這是一個自監督框架,旨在學習人造環境的通用嵌入(即緊湊的數值摘要)。S2Vec 讓 AI 能夠像人類一樣理解社區的特徵,識別加油站、公園和住宅分佈的模式,並利用這些知識來預測重要的指標,從人口密度到環境影響。在我們的評估中,S2Vec 在社會經濟預測任務中展現出與基於圖像的基準模型相當的競爭力,特別是在地理適應(外推)方面,同時也顯示出在環境任務(如樹木覆蓋率和海拔)上仍有明顯的改進空間。
挑戰:超越地圖上的點
地理空間數據因其多模態且尺度差異極大而出了名地難以處理。一個城市街區可能包含數百個數據點(建築、咖啡館、巴士站),而農村地區可能只有幾個。標準的機器學習模型偏好結構化、統一的數據,例如照片中的像素網格。
為了應對這一挑戰,S2Vec 使用兩步過程將世界「網格化」(rasterize):
這種轉換使我們能夠像處理 AI 可以「看見」的數位照片一樣處理人造環境的地理數據。反過來,這種網格化開啟了廣大且成熟的電腦視覺工具箱,這些技術已基本解決了自然圖像理解的問題。
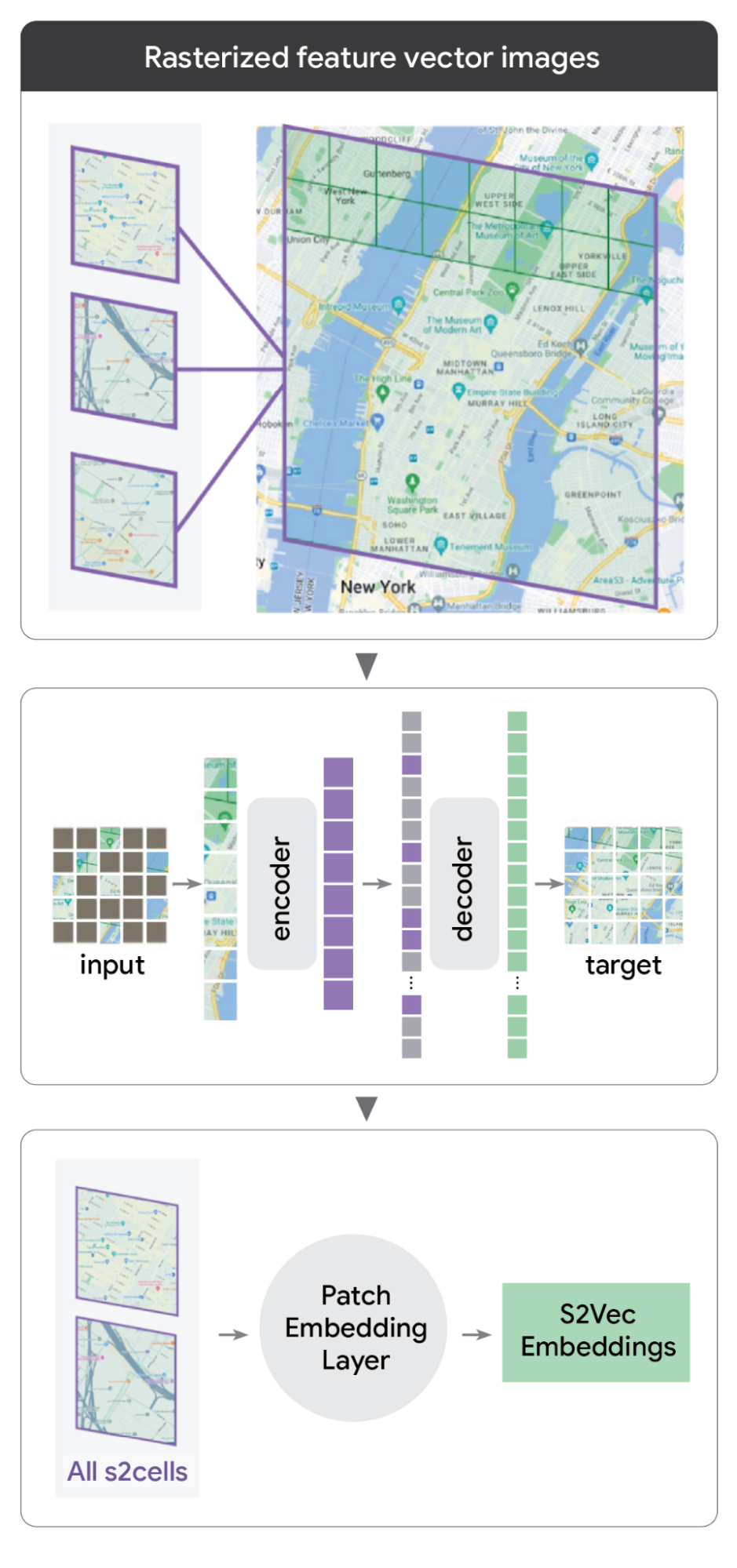
S2Vec 將圖像網格化以學習人造環境的嵌入。
遮蓋自動編碼:無需標籤的學習
在將人造環境轉換為網格化的特徵圖像後,S2Vec 使用遮蓋自動編碼(Masked Autoencoding, MAE)進行分析,這是一種強大的自監督學習技術。傳統的機器學習依賴於人工標籤(例如,手動標記區域的收入水平或空氣質量),而自監督學習消除了這個瓶頸。由於為整個地球打標籤是一項不可能完成的任務,MAE 讓我們無需手動標籤即可解鎖全球洞察。
MAE 過程系統地向模型展示人造環境的一個「區塊」(patch),同時隱藏(遮蓋)其中的某些部分。然後,模型僅根據周圍的上下文來重建缺失的部分:
輸出結果是一個通用嵌入:一種捕捉位置特徵的獨特數學簡寫。這些數字串代表了一個位置的特徵,建立了一個隨後可以適配於一系列任務的基礎。
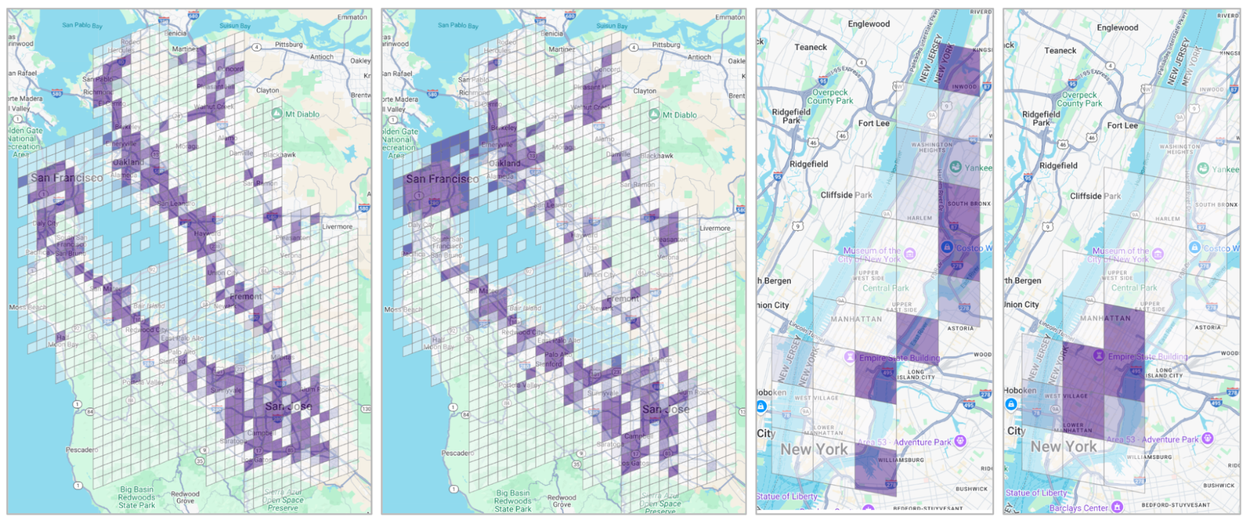
S2Vec 通過將區域劃分為網格來捕捉城市區域的「特徵」,其中每個單元格都作為建築和道路等人造環境特徵的數據點。
接著,MAE 學習「填補」隱藏地圖部分的空白,識別出人造環境中的深層模式。這為任何位置創建了強大的數學「嵌入」,使我們能夠以全球規模和準確性預測房價和人口密度等社會經濟指標。
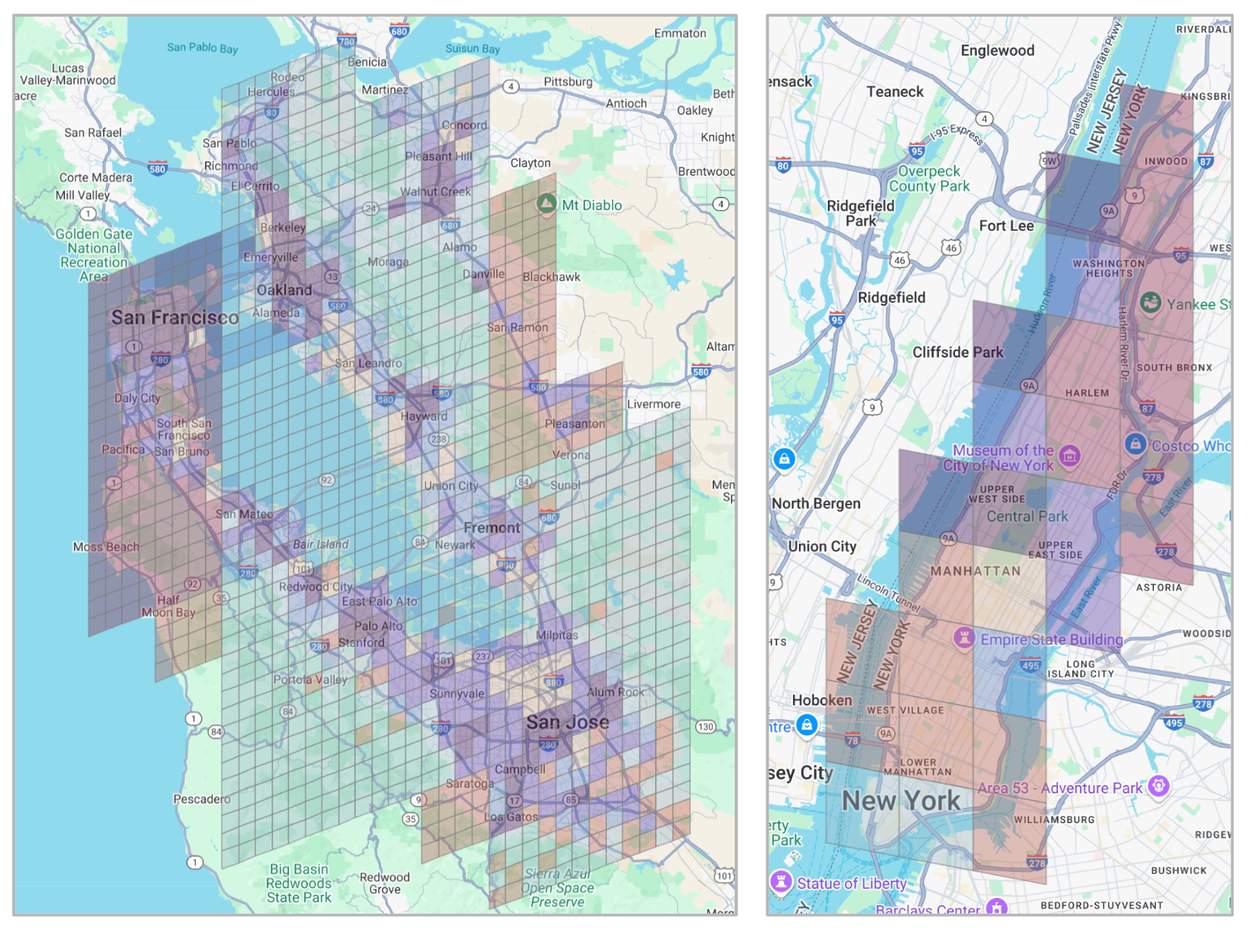
S2Vec 自動編碼器對區域進行標記,本質上使其能夠根據社會經濟數據和人口密度等因素進行更深入的分類和分析。
即使沒有被告知什麼是「金融區」或「郊區住宅區」,模型也能純粹根據其特徵的空間關係將它們歸類在一起。
評估
我們將 S2Vec 的地理空間性能與幾種基於地理空間和圖像的嵌入方法進行了比較,包括:SATCLIP、GEOCLIP、RS-MaMMUT、Hex2vec 和 GeoVeX。這些模型在多個地理空間回歸基準上進行了評估,特別是預測全美範圍內的人口密度和中位數收入等社會經濟指標,以及包括碳排放、樹木覆蓋率和海拔在內的環境因素。