Anthropic 經濟指數報告:學習曲線
本報告分析了 2026 年 2 月 Claude 的使用數據,揭示了任務多樣化的趨勢,並證明資深用戶透過培養 AI 使用習慣,能獲得更高的任務價值與成功率。
Anthropic 經濟指數報告:學習曲線

Anthropic 經濟指數利用我們保護隱私的數據分析系統,追蹤 Claude 在各個經濟領域的使用情況。這是我們盡早了解人工智慧經濟影響之努力的一部分,以便研究人員和政策制定者有足夠的時間做準備。
這份最新報告研究了 2026 年 2 月的 Claude 使用情況,並以我們上一份報告(使用 2025 年 11 月的數據)中引入的經濟原語(economic primitives)框架為基礎。我們的樣本涵蓋 2 月 5 日至 2 月 12 日,即 Claude Opus 4.5 發布三個月後,且適逢 Claude Opus 4.6 發布。
我們首先記錄了使用情況相對於先前報告的變化:增強(augmentation)率(即 AI 補充使用者能力的協作互動)在 Claude.ai 和 API 流量中均略有增加。在 Claude.ai 中,使用情況趨於多樣化,上個月前 10 大任務佔使用量的比例低於 2025 年 11 月。由於這種多樣化,Claude.ai 的平均對話任務工資略低於之前的報告。
接著,我們關注 Claude 對勞動力市場和廣義經濟影響的一個重要決定因素:Claude 採用的學習曲線。我們提出的證據表明,資深使用者已經建立了習慣和策略,使他們能夠更好地利用 Claude 的能力。事實上,我們記錄到經驗豐富的使用者不僅嘗試更高價值的任務,而且更有可能在對話中獲得成功的響應。
自上一份報告以來的變化
在第一章中,我們重新審視了 2026 年 1 月發布的上一份經濟指數報告的發現。我們發現:
學習曲線
經濟指數的一個核心發現是,Claude 的早期採用非常不均衡:Claude 在高收入國家、美國境內知識工作者較多的地區,以及相對較小的一組專業任務和職業中被更密集地使用。
一個重要的問題是,採用的不平等可能如何決定 AI 的收益將流向何處以及流向誰。例如,如果有效使用 AI 需要互補的技能和專業知識(我們在上一份報告中提出的觀點),且如果這些技能可以通過使用和實驗獲得,那麼早期採用的收益可能會自我強化。
在第二章中,我們調查了使用者如何塑造他們從 Claude 中獲得的價值:他們如何將模型能力與手頭的任務相匹配,以及使用模式和結果如何隨著平台經驗的增加而轉變。
自上一份報告以來的變化
Claude.ai 使用案例的多樣化
我們首先觀察 Claude 被要求執行的任務類型。我們使用保護隱私的系統,這使我們能夠在不洩露個人對話內容的情況下,描述總體層面的行為。我們從 Claude.ai(面向消費者的網頁產品)和我們的一方 API(面向開發者、用於將 Claude 集成到產品和工作流中的介面)中各抽取了 100 萬個對話樣本。2
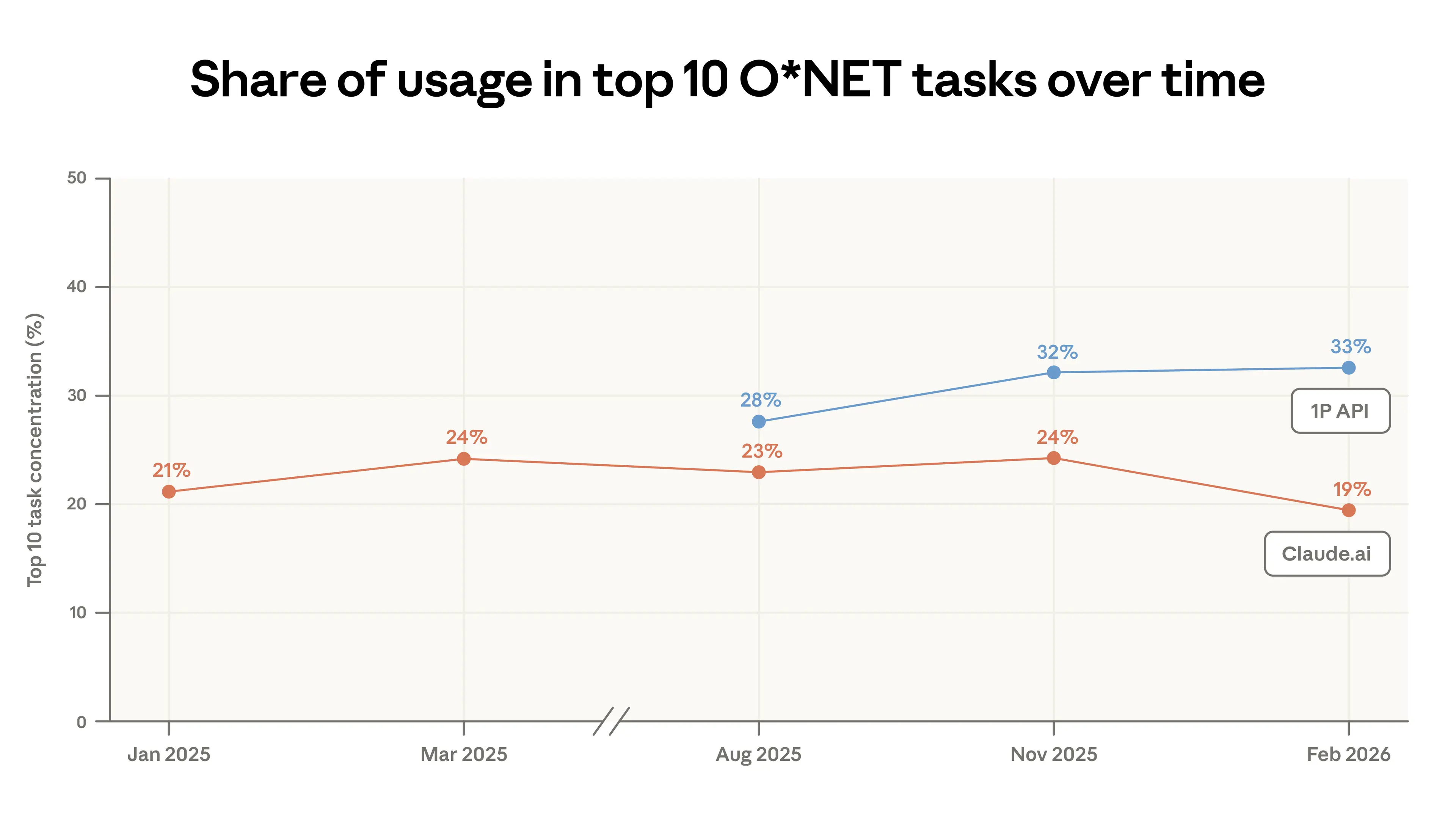
程式碼編寫仍然是我們平台上最常見的用途,與電腦和數學職業相關的任務佔 Claude.ai 對話的 35%(見附錄)。3 然而,在 2025 年 11 月至 2026 年 2 月期間,Claude.ai 的使用案例集中度降低了:前 10 個最常見的 O*NET 任務從對話的 24% 下降到僅 19%(圖 1.1)。
這種集中度的下降部分反映了程式碼任務從 Claude.ai 遷移到我們的一方 API,在該 API 中,Claude Code 已成長為樣本流量中的很大一部分。Claude Code 的代理架構將編碼工作拆分為較小的 API 調用,這些調用被標記為不同的任務。因此,雖然編碼在 API 流量中的總體份額有所增長,但它分散在許多任務類別中,而不是集中在少數幾個類別中。結果,儘管編碼活動大量湧入,API 的任務集中度仍大致持平。
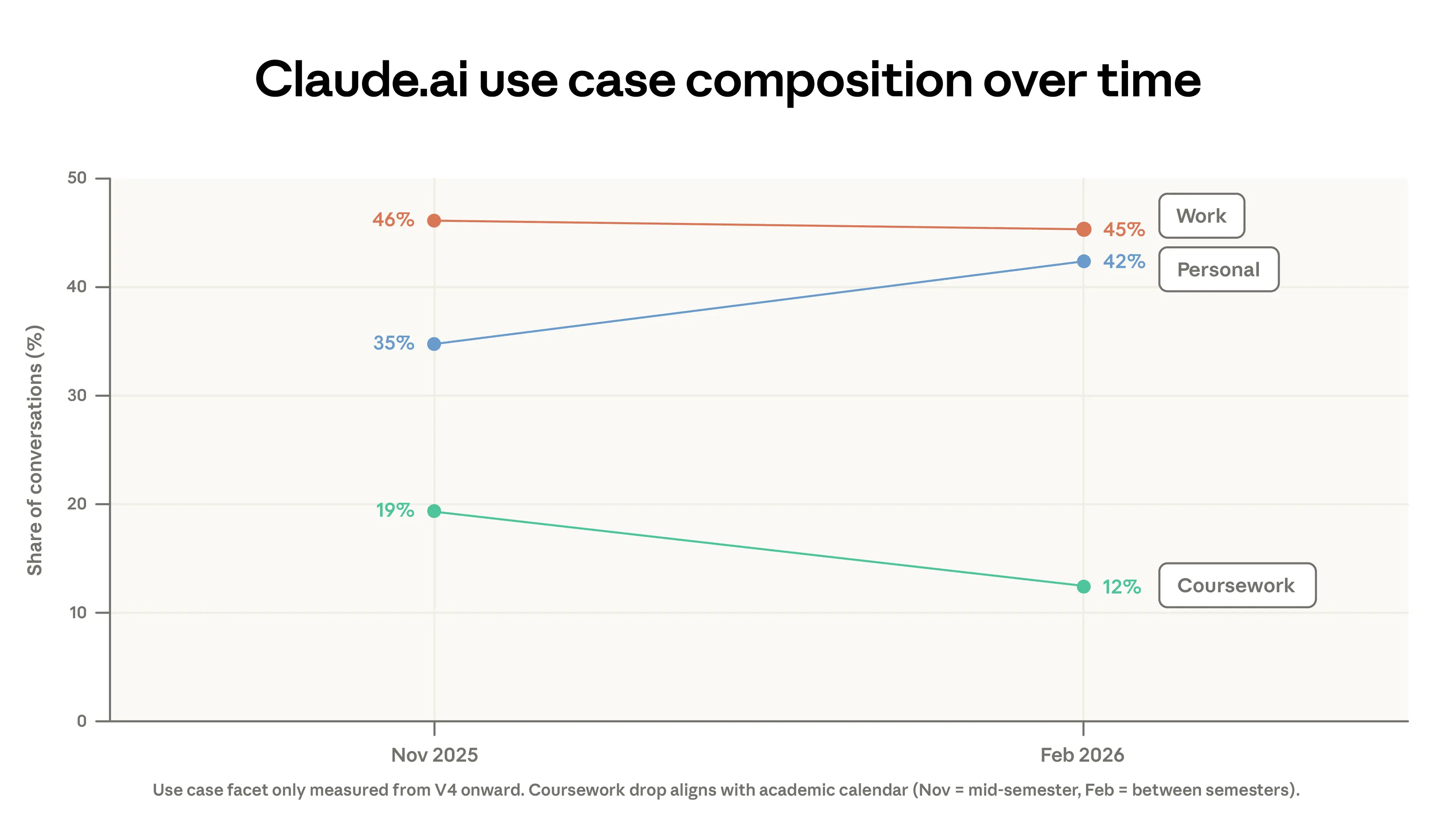
程式碼遷出 Claude.ai 並不是導致集中度下降的唯一因素。部分下降是由於這兩個時期之間使用案例組合的變化。課業學習從對話的 19% 下降到 12%,而個人用途從 35% 上升到 42%。課業學習的部分下降可以用一些國家的學術日曆來解釋,在我們的採樣期間,那裡的學生正處於寒假。4 同時,從 2 月左右開始增加的註冊量帶來了更多休閒 AI 使用者。
雖然 Claude 工作任務的分布變得更加多樣化,但幾乎所有這些任務之前都已在我們的數據中出現過。在上一份報告中,我們指出 49% 的工作至少有四分之一的任務是使用 Claude 執行的。在這次數據提取中,該累積估計值幾乎沒有變化(附錄圖 A.2)。本報告的數據顯示,新增的 O*NET 任務比上一份報告少得多。
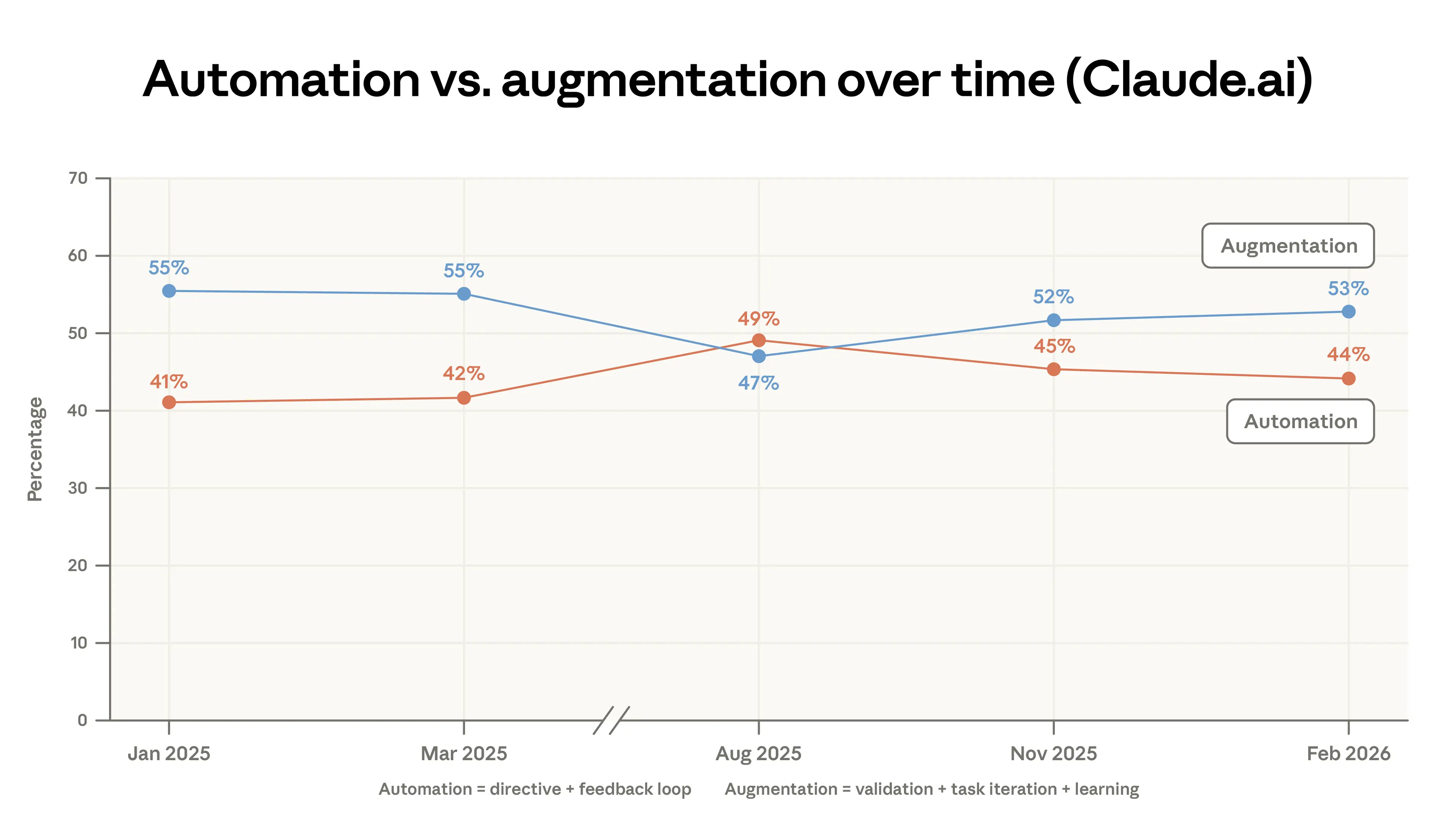
自第一份報告以來,我們將對話分為五種互動類型之一——指令型、反饋循環、任務迭代、驗證和學習——我們將其歸為兩大類:自動化(automation)和增強(augmentation)。5 圖 1.3 顯示 Claude.ai 的增強略有增加。這是由驗證和學習模式的小幅增長推動的。在附錄圖 A.3 中,我們顯示一方 API 數據中的自動化程度大幅下降。
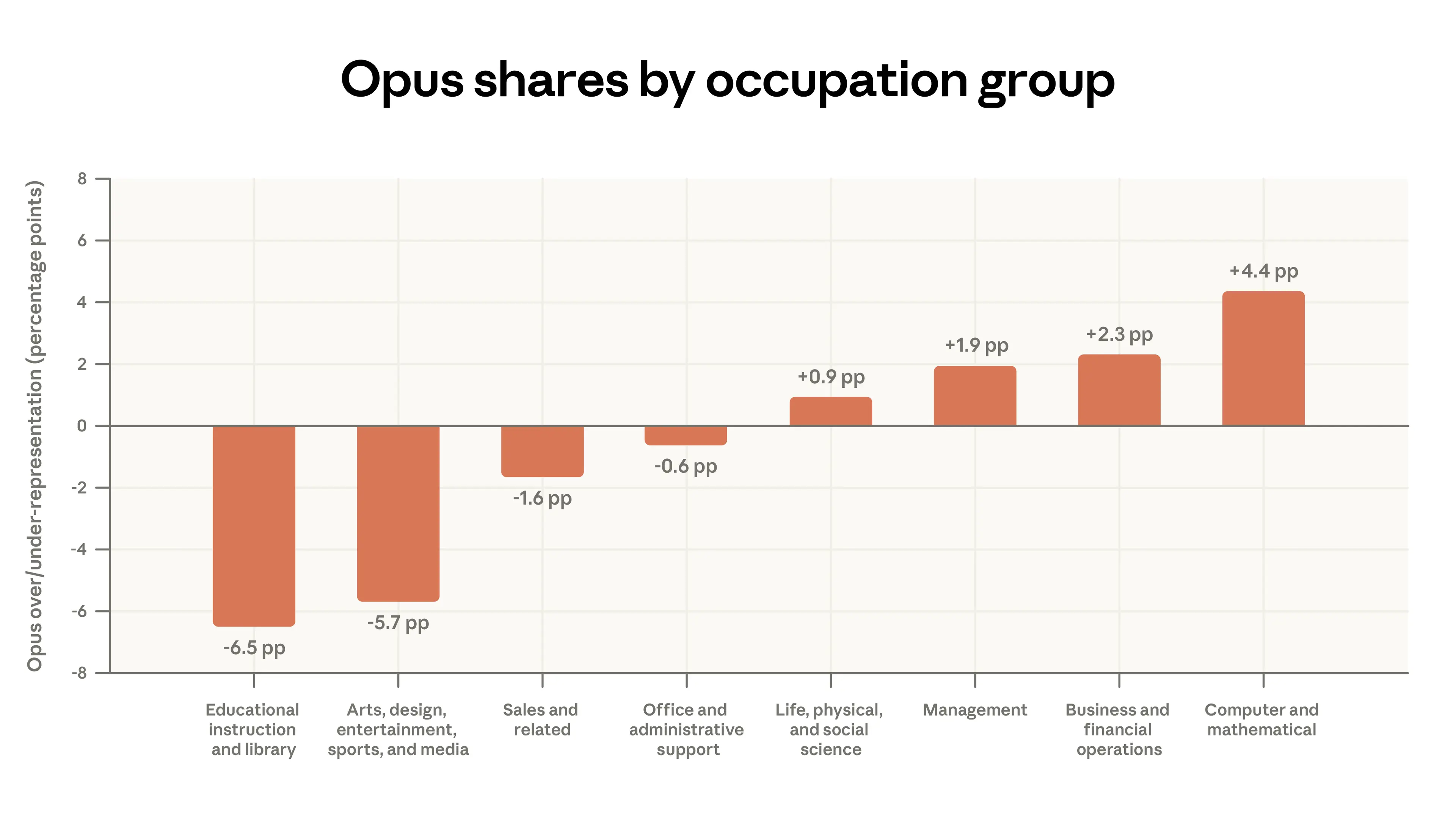
我們的 API 平台在電腦和數學任務中的份額繼續相對提高(按職業類別劃分的使用份額見附錄)。自 2025 年 August 以來,該類別任務在 API 中的份額增加了 14%,在 Claude.ai 中減少了 18%。正如我們在勞動力市場影響報告中所指出的,我們預計這種從 Claude.ai 到 API 的遷移可能預示著相關工作即將發生更緊迫的轉型。Claude.ai 中與管理職業相關的任務增加(從流量的 3% 增加到 5%),來自於分析任務(例如準備投資備忘錄)和回答客戶問題的混合。
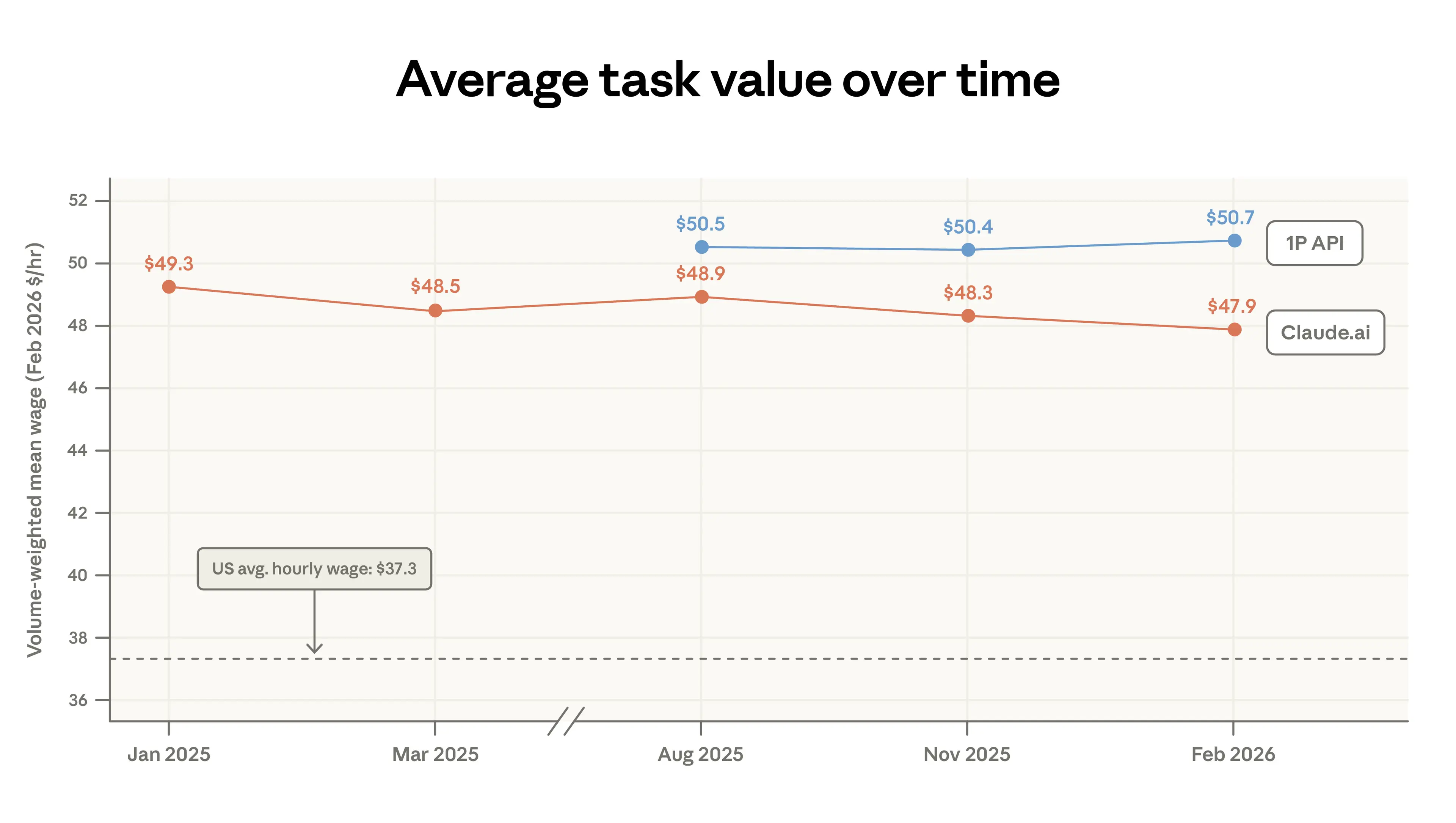
衡量 Claude 任務組合變化的另一種方法是觀察任務平均價值的變化,我們將其定義為執行該任務的美國工人的平均時薪(圖 1.4)。6 Claude.ai 任務價值的估計值從 49.3 美元略降至 47.9 美元,主要是由於簡單事實問題(例如體育賽果、天氣)的增加,以及編碼任務轉向 API。如前一份報告所述,我們在 Claude 上看到的任務往往需要較高的教育程度。圖表顯示,這些任務的工資也往往高於美國全國平均水平。
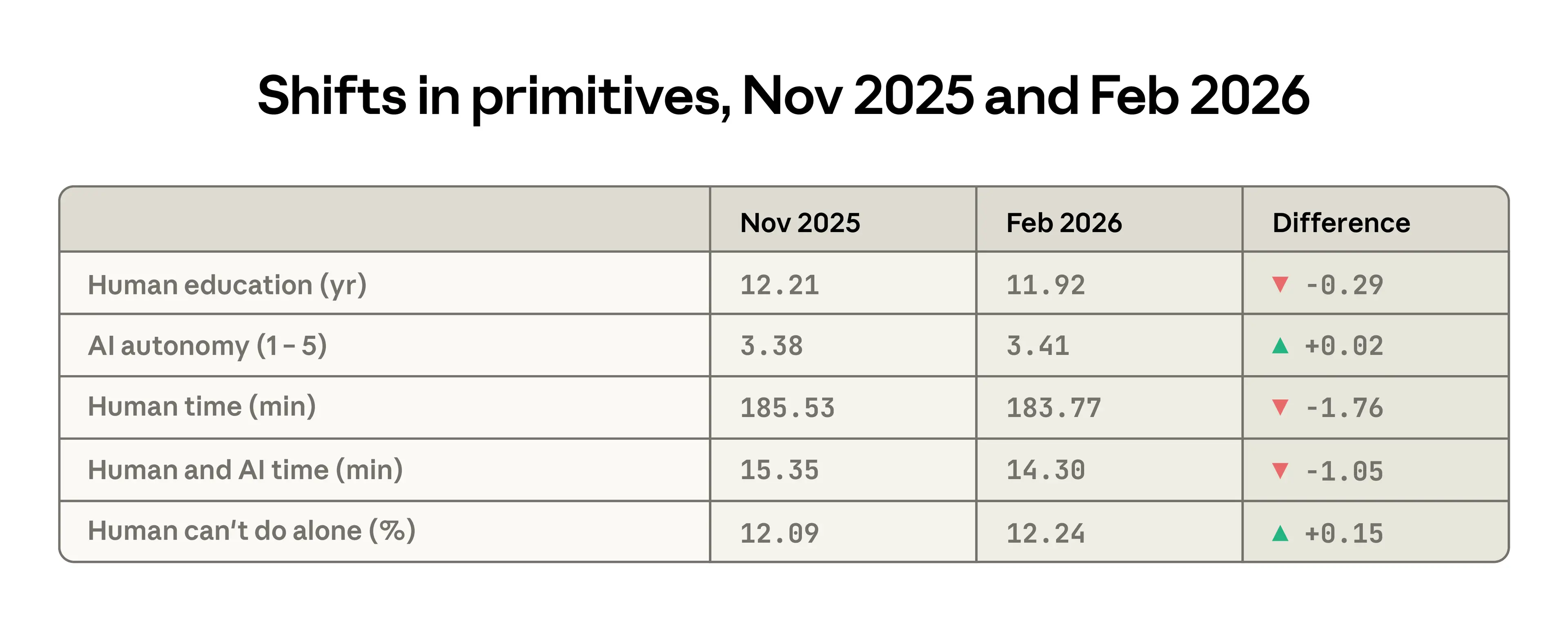
雖然幅度微小,但上一份報告與本報告之間幾個原語的變化,都捕捉到了 Claude.ai 任務複雜度的類似下降。人類輸入所需的平均受教育年限從 12.2 年下降到 11.9 年,使用者賦予了 AI 更多自主權,且人類單獨完成任務所需的時間減少了約 2 分鐘。有一項變化表面上方向相反:Claude 執行的任務被判定為人類在沒有 AI 的情況下稍微更難完成。
湧現的自動化模式
隨著任務遷移到 API,它們可能更容易受到自動化的影響。API 工作流更有可能是指令型的,對人類參與的需求較少。在之前的報告中,我們強調了客戶服務任務(例如支付和帳單問題的自動化支援)在 API 數據中非常普遍。這些因素導致觀察到的客戶服務代表暴露度較高——記錄顯示 Claude 在自動化工作流中執行了他們很大比例的任務,因此隨著 AI 的擴散,這些工作可能更有可能發生變化。
我們重點介紹了兩個在 2 月份出現頻率高於三個月前的 API 工作流,其份額在我們最新的樣本中至少翻了一倍:7
重新審視地理趨同
在上一份報告中,我們注意到 Anthropic AI 使用指數 (AUI)(根據地理區域的勞動年齡人口調整使用量)在美國各州之間迅速趨同:初始人均使用量較低的州顯示出更快的採用速度。
圖 1.6 的左側面板顯示,這種趨同在我們最新的數據中繼續存在,但速度有所放緩。從 2025 年 8 月到 2026 年 2 月,前五個州的人均使用份額從 30% 下降到 24%。吉尼係數自 2025 年 8 月以來有所下降,儘管趨同速度已放緩。當我們更新上一份報告的估計值時,我們發現按此速度,各州將在 5-9 年內達到大致相等的人均使用量,而不是 2-5 年。8
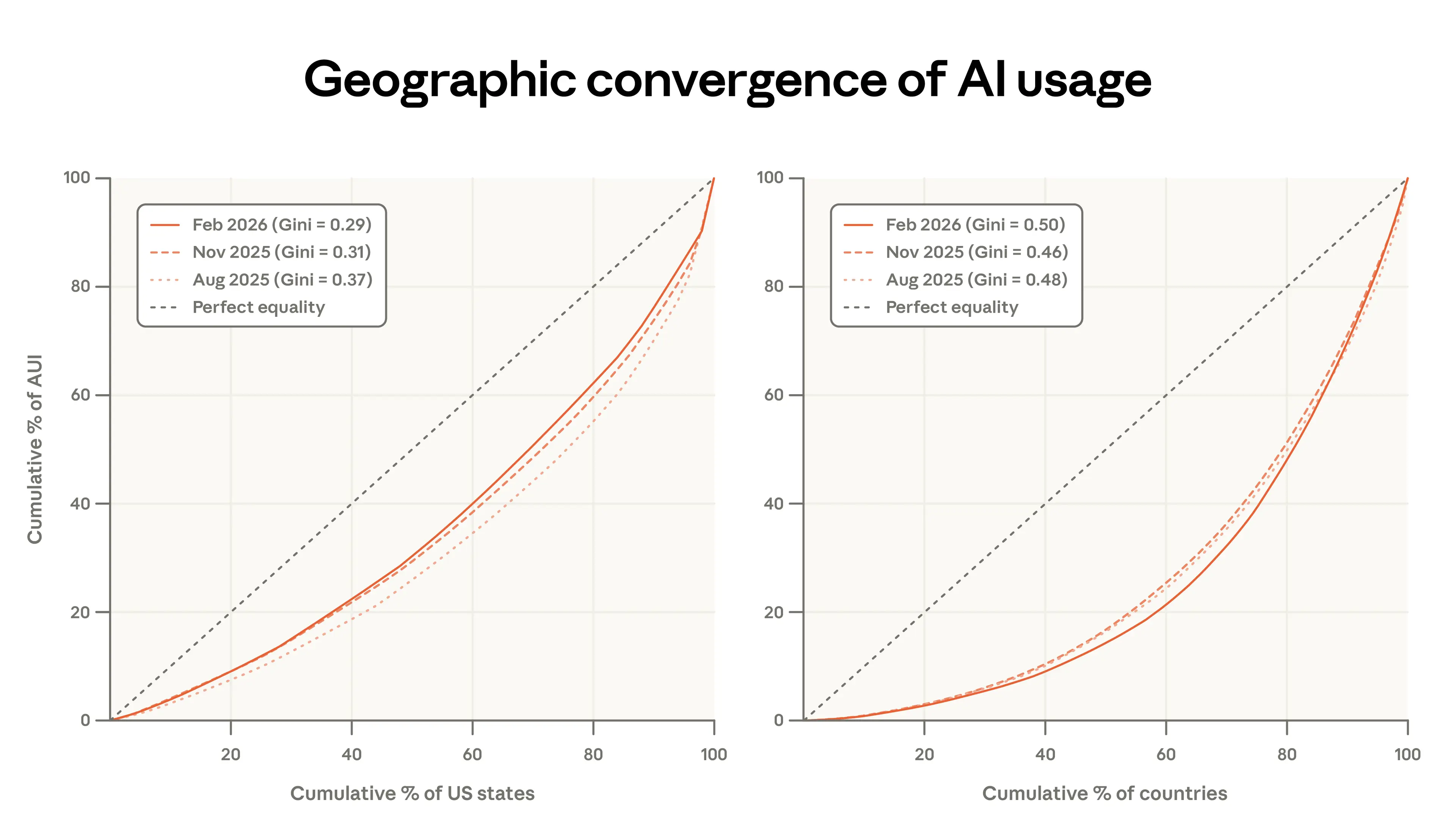
在各國之間(右側面板),情況正好相反:使用情況變得稍微更加集中,吉尼係數在同一時期內上升。Claude 使用量(人均)最高的國家現在佔總體使用量的比例更大,前 20 個國家的人口調整後使用份額從 45% 上升到 48%。
學習使用 AI
在本章中,我們關注反映人們如何部署 AI 並學習與之合作的兩個使用特徵:模型選擇和長期使用者的習慣。
首先,我們通過研究人們何時選擇 Opus(我們性能最強大的模型類別)來揭示對智能的需求。關於 AI 使用者如何在不同模型之間進行選擇,以及如何在速度、性能和成本之間進行權衡,目前知之甚少。如果使用者正在根據手頭的任務進行校準,我們應該會看到 Opus 集中在更難、更高價值的工件上。
接著,我們研究使用情況如何隨年資(tenure)而異,發現不同時間註冊的使用者之間存在差異。這揭示了學習曲線:經驗豐富的使用者會隨著時間的推移而變得更好嗎?他們的使用方式有何不同?我們發現了與「邊做邊學」一致的證據。資深使用者不僅在對話中獲得更大的成功,而且與 Claude 的協作更多,將更具挑戰性的任務交給 Claude,並且更有可能將 Claude 用於工作目的和更廣泛的任務。
模型選擇
不同的 Claude 模型類別(Haiku、Sonnet 和 Opus)在成本、速度和性能方面提供了權衡。Opus 類別的模型使用最多的 token 並擅長處理複雜任務,但在我們的 API 上每 token 價格較高。如果使用者意識到這一點並考慮到成本和使用限制,他們應該將最複雜和最有價值的任務交給 Opus,而為較簡單的任務選擇其他模型。這大致就是我們在數據中觀察到的情況。
下圖 2.1 顯示,對於可以訪問所有模型類別的付費 Claude.ai 帳戶,55% 的電腦和數學任務(如編寫軟體)使用 Opus,而教育任務的比例為 45%。技術使用者可能會注意到性能提升並主動從預設的 Sonnet 切換。或者,注重效率的使用者可能會學會對較簡單的任務使用 Sonnet,以避免達到使用限制。與此相關的是,這裡的差異可能反映了大多數教育任務對於 Sonnet 來說已經相當容易,或者學生更有可能關注使用限制。
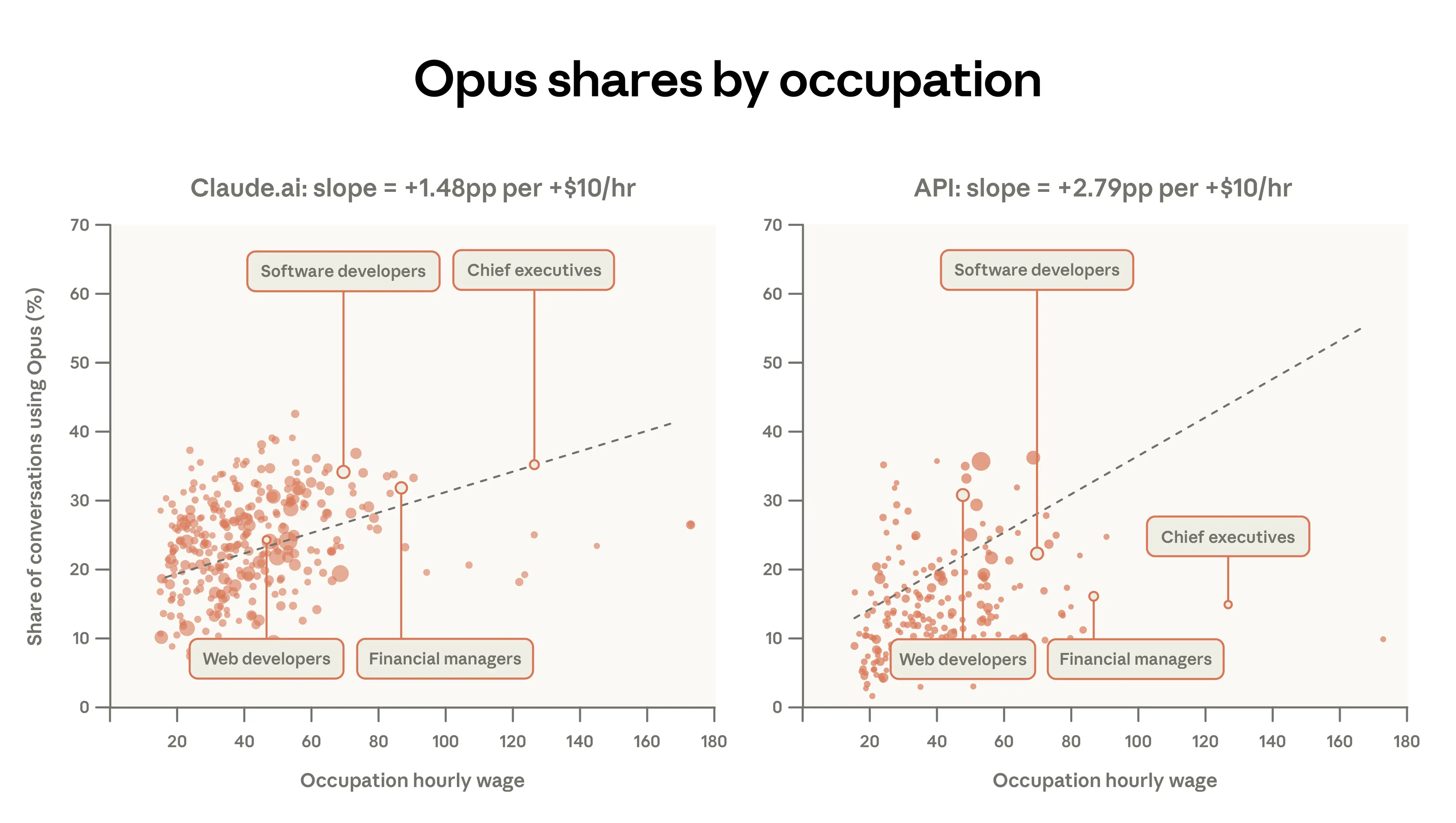
下圖 2.2 以更細緻的方式顯示了這一點。當使用者執行與高薪工作相關的任務時,他們更頻繁地使用 Opus。例如,在 Claude.ai 上,34% 的軟體開發人員任務涉及 Opus,而導師任務僅為 12%。總體而言,任務時薪每增加 10 美元,Claude.ai 使用者使用 Opus 的對話份額就會增加 1.5 個百分點。一方 API 流量對任務複雜性的反應更為強烈。其斜率大約是兩倍,任務價值每增加 10 美元,Opus 份額就增加 2.8 個百分點。與網頁使用者相比,部署程式化工作流的使用者可能有更多理由在模型之間切換。
學習曲線
第一個 Claude 模型於 2023 年 3 月發布。從那時起,Claude.ai 和 API 的使用者群都迅速增長。我們最新的樣本包含各種使用者,其中一些人在 Claude 最初發布時就註冊了,而另一些人則是在我們測量其使用情況的前一天才註冊。一個人在 Claude 的年資如何塑造他們的體驗?9
表 2.1 顯示了低年資和高年資使用者之間的差異,後者被定義為至少在 6 個月前註冊 Claude 的人,而低年資使用者則是其他所有人。10 高年資使用者更有可能使用 Claude 來迭代他們的工作,而不太可能通過指令型使用模式委託更大的責任。他們將 Claude 用於工作的可能性高出 7 個百分點,並且將 Claude 用於通常需要更高教育程度的任務。最後,他們的使用在特定任務中的集中度較低。前 10 個 O*NET 任務在高年資組的使用份額略低(20.7% 對比 22.2%)。
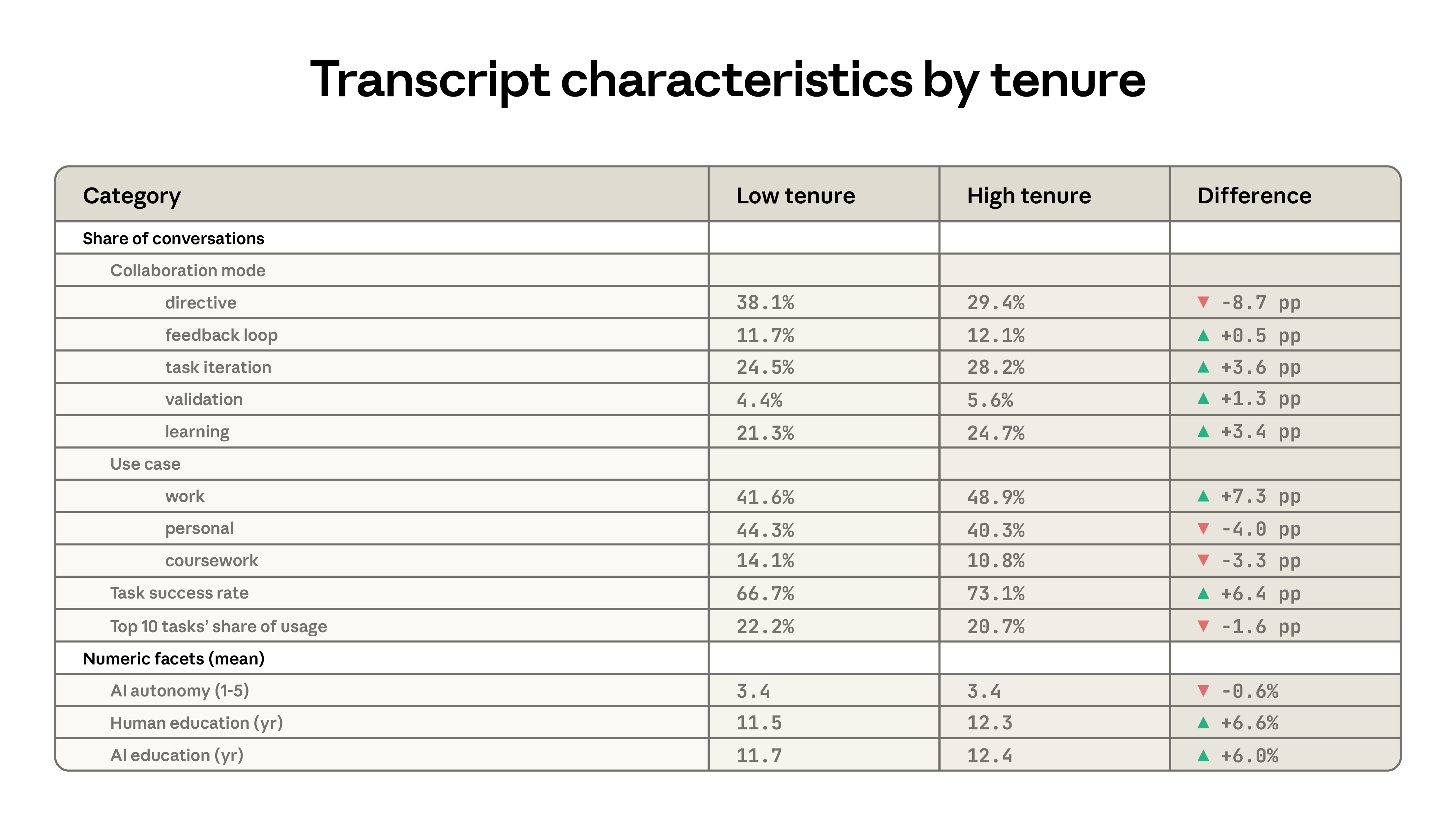
下面,我們深入探討上述兩個原語:與每個對話相關的人類受教育年限,以及用於個人用途的對話比例。
在左側面板中,我們顯示理解人類提示所需的受教育年限隨著 Claude 使用年資每增加一年而增加近 1 年。在右側面板中,我們顯示與此同時,個人用途減少了:一年前註冊的人將 38% 的對話用於個人使用案例,而最新使用者的比例為 44%。
圖 2.3 待補
在這種快速進步的通用技術的使用者群中,有幾個因素可以解釋這些模式。高年資使用者是自我篩選的,這裡的差異可能反映了穩定的特徵。例如,他們可能是更有可能成為早期採用的電腦程式設計師。此外,還存在固有的生存者偏差:在我們提取數據一年前註冊的人,可能從他們的使用中看到了積極的結果。我們沒有觀察到一年前註冊但不再使用 Claude 的人。
這些發現與我們在《經濟原語》報告中看到的相呼應:低收入、受教育程度較低的國家在某些情況下矛盾地顯示出更複雜的使用。最早的採用者通常擁有高價值、技術性的使用案例。在採用率低得多的較貧窮國家,這些早期採用者仍然主導著使用者群。
當 AI 擴散到更廣泛的人群時,就會出現更多休閒用途。事實上,在請求集群中,平均年資最高的任務包括:AI 研究、git 操作、修改手稿和新創公司融資。平均年資最低的任務則擁有更簡單的工作流,如寫俳句、查看體育比分和為派對建議食物。11
經驗效應
我們在下圖 2.4 中進一步探討這些關係,使用日誌級數據來細緻地控制對話特徵。在頂部面板中,規格 (1) 顯示了一個簡單的雙變量回歸,以任務成功為結果,長年資指標為預測因子。成功是 Claude 對對話是否成功的評估,詳見我們之前的報告。圖表顯示,長年資使用者獲得成功對話的可能性高出約 5 個百分點。
這可能反映了高年資使用者更擅長提示(prompting)。但如果這反映了他們帶給 Claude 的任務不同——那些更有可能成功的任務呢?
在規格 (2) 中,我們加入了特定 O*NET 任務和請求集群的固定效應。這相當於在同一個定義狹窄的任務中比較高年資和低年資使用者,而不是跨任務比較。例如,我們有一個名為「為特定公司執行企業財務分析、估值和建模」的請求集群。固定效應比較了該集群內的高年資和低年資使用者,其他每個集群也是如此。只有當平均而言,長年資使用者在這些任務內比較中更成功時,我們才會觀察到正係數。這種控制在一定程度上緩和了效應,使其接近 3 個百分點。
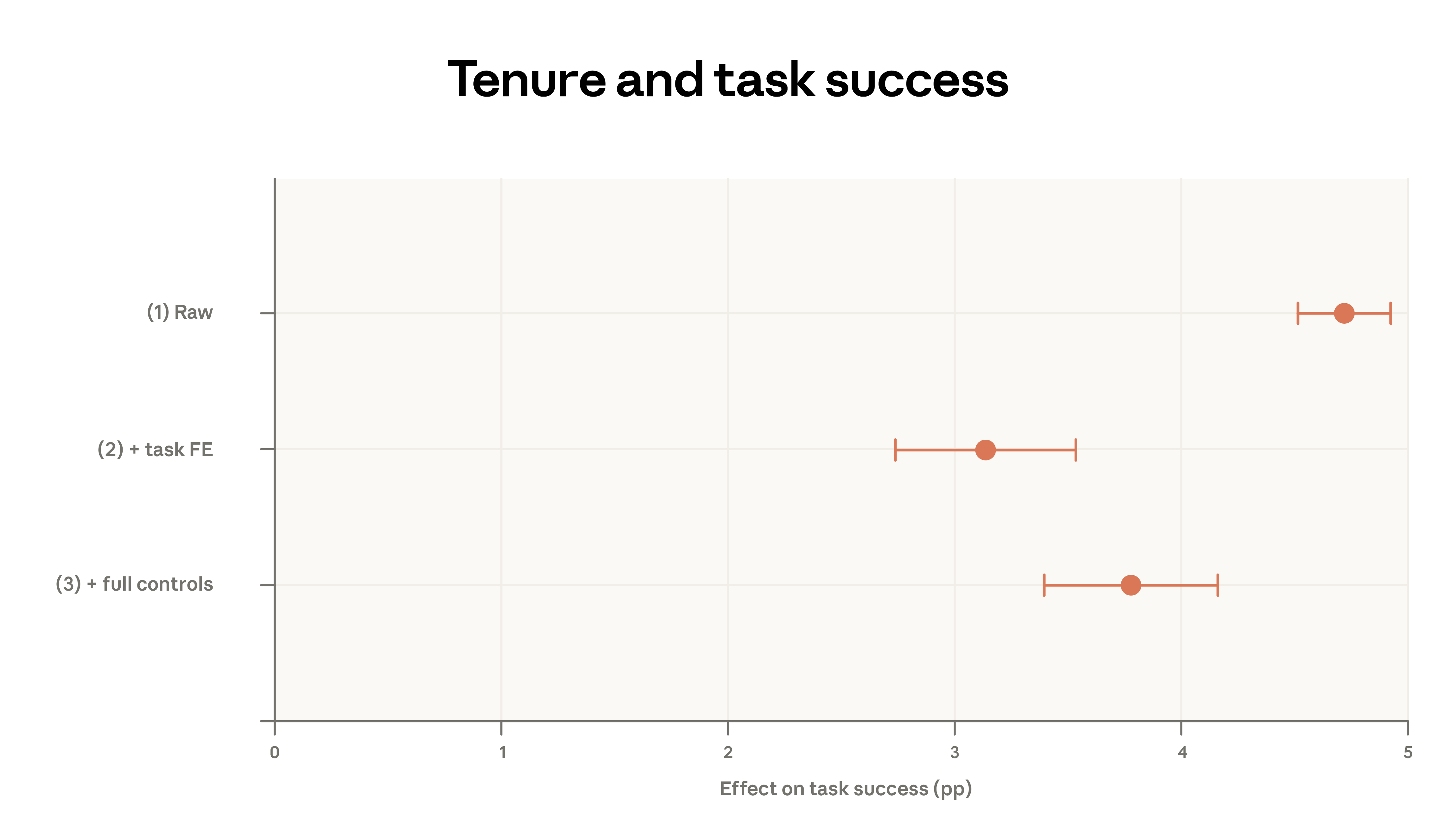
最後,我們詢問這種關係是否受到高年資使用者選擇不同模型、使用不同語言溝通、擁有不同使用案例或在不同國家登入的影響。該回歸顯示長年資的影響略高,表明在考慮完整控制後,成功率高出 4 個百分點。
這些結果表明,高年資使用者在 Claude 對話中獲得了更多成功,且這並非由於語言或所執行任務等簡單因素造成的。一個引人入勝的潛在解釋是,這些使用者更好地學會了如何從 AI 中提取他們想要的東西。對這些平台的熟練程度可能是成功的關鍵決定因素,且似乎隨經驗而增長。
討論
本報告重新審視了我們用於追蹤 Claude 使用情況的核心指標,並首次分析了模型選擇和成功率。自 2025 年 8 月以來,一方 API 的使用變得更加集中,前 10 個 O*NET 任務現在佔流量的 33%,高於 28%。另一方面,自 2025 年 11 月的數據以來,Claude.ai 的任務趨於多樣化。在美國,低使用率州份的較快採用仍在繼續,儘管速度比上一份報告有所放緩。低採用率國家則進一步落後。
通過這份報告,我們可以開始追蹤各種經濟原語的變化。課業學習在佔比中下降,而個人對話增加。我們還注意到 Claude.ai 提示的總體複雜度略有下降,Claude.ai 中的對話顯示出較不複雜的輸入和較短的預計完成時間。
總體而言,Claude 被用於高價值、複雜的工作,這在美國經濟中並不具有廣泛的代表性。但隨著使用者群的增長,報酬較低的任務在流量中所佔份額略有增加。自我們第一份報告以來,Claude.ai 上的任務平均價值(以與這些任務相關職業的工人預估工資衡量)有所下降,而 API 使用者則有所上升。在兩個介面上,使用者都會將最複雜的任務交給我們更強大的模型類別 Opus。這種趨勢在 API 客戶中更為強烈。
經驗豐富的使用者傾向於以更具協作性的方式使用 Claude,更多地出於工作相關原因,處理更複雜的任務,並獲得更多成功。這反駁了我們去年提出的一個假設,即自動化使用可能在更有經驗、更成熟的使用者中更典型;相反,我們發現最先進的使用者更有可能與 Claude 進行迭代。這也與「邊做邊學」一致:使用 AI 的時間越長,利用它的效率就越高。
當然,另一種解釋是這些結果是由世代效應(cohort effects)或生存者偏差驅動的。早期採用者可能更具技術性。那些繼續使用 Claude 的人可能是那些擁有 Claude 特別擅長處理的任務的人。但經過仔細控制的回歸排除了這些干擾因素的簡單版本,例如長年資使用者帶來不同類型的任務。隨著時間的推移,我們將能夠更清晰地將世代效應和生存者偏差與邊做邊學區分開來。
這些觀察到的成功率差異可能會加深勞動力市場的不平等。經濟學家長期以來一直注意到技能偏向型技術變革(skill-biased technological change)的可能性:提高高技能工人薪資同時壓低其他工人薪資的創新。我們在本報告中的分析確定了一個渠道,通過該渠道,這種技能偏向型轉型可能已經在展開:擁有高技能任務的早期採用者與 Claude 的互動比後來的、非技術性採用者更成功。這些早期採用的使用者可能同時最容易受到 AI 驅動的顛覆,並在最初的增強式採用浪潮中得到 AI 的最大幫助。
附錄
可在此處獲取。
數據可用性
本報告的數據可在此處獲取。
作者與致謝
第一作者組*:
Maxim Massenkoff, Eva Lyubich, Peter McCrory
*報告的主要作者