論文深度解讀:大型語言模型為何會產生幻覺
我將嘗試寫下閱讀論文為何語言模型會產生幻覺時的思考過程,分析訓練與評估程序如何獎勵猜測而非承認不確定性,並探討修改基準測試評分機制以減少幻覺的可能性。
人們常說閱讀論文是一項技能,但很少有人會詳細展示他們是如何閱讀的。部分原因是供應問題:記錄自己長時間的思考過程成本很高,而且這樣做很可能會讓自己看起來相當愚蠢。另一部分則是需求問題:比起閱讀一篇上千字、記錄某人閱讀論文時心路歷程的文章,更多人願意閱讀一段簡短的摘要或推特串,看看對論文的精煉總結和犀利評論。
幸好,我願意冒著看起來有點蠢的風險,而且目前我對市場需求並不怎麼感興趣,所以我會嘗試寫下我在 1 到 2 小時內盡可能閱讀一篇論文時的思考過程。標準免責聲明:由於多種原因,這不太可能完全忠實於原貌,包括我閱讀和思考的速度遠快於我打字或說話的速度。^([1])
具體來說,我嘗試針對去年的一篇論文進行這項練習:由 OpenAI 的 Kalai 等人撰寫的 《為什麼語言模型會產生幻覺》(Why Language Models Hallucinate)。^([2])
由於時間限制,我在時間耗盡前只讀完了摘要和引言。哎呀。也許以後我會嘗試錄下自己對另一篇論文進行精讀的過程。
摘要 (The Abstract)
論文的摘要開頭寫道:
就像面臨困難考題的學生一樣,大型語言模型在不確定時有時會進行猜測,產生看似合理但錯誤的陳述,而不是承認不確定性。這種「幻覺」即使在最先進的系統中依然存在,並損害了信任。
對我來說,這讀起來像是相當標準的開場白,但值得注意的是,這是一個特定的「幻覺」定義,並未涵蓋所有我們可能稱之為幻覺的現象。隨便想一下,我聽過有人將邏輯推導的失敗稱為「幻覺」。例如,許多人會認為這個例子是幻覺:^([3])
使用者:x^2 + 2x - 1 的根是什麼?
聊天機器人:
- 為了求解二次方程 x^2 + 2x - 1 = 0,我們先配方。
- (x + 1)^2 - 2 = 0
- x + 1 = +/-sqrt(2)
- x = 1 +/- sqrt(2)
這裡,最後一個點存在邏輯錯誤:AI 沒有正確地移動「+ 1」以得到 x = - 1 +/- sqrt(2)(正確答案),而是得到了 x = 1 +/- sqrt(2)。我認為這核心上不是不確定的問題,而是邏輯推理的錯誤。
繼續閱讀摘要:
我們認為語言模型之所以產生幻覺,是因為訓練和評估程序獎勵猜測而非承認不確定性,我們分析了現代訓練流程中幻覺的統計原因。
這句話主要說明了前兩句話的含義。既然幻覺是模型在不確定時產生的看似合理但錯誤的陳述,且幻覺在整個訓練過程中持續存在(顯然在某種程度上確實如此),那麼這一定是真的;也就是說,訓練過程必須激勵猜測而非承認不確定性(或者至少沒有充分地抑制猜測)。
我對於為什麼會發生這些幻覺的直覺想法是:首先,猜測與模型在預訓練中看到的情況不同:補全「[隨機人物 x] 的生日是……」通常看起來像「1971 年 5 月 27 日」,而不是「我不知道」。接著,在後訓練(post-training)階段,獎勵模型/人類評分者等並非全知全能,可能會被看似合理但錯誤的事實所愚弄,從而強化了這些錯誤,而不是說「我不知道」,除非是在人類評分者/獎勵模型被預期知道該事實的情況下。
幻覺不需要是神祕的——它們僅僅起源於二元分類中的錯誤。如果錯誤的陳述無法與事實區分開來,那麼預訓練語言模型中的幻覺將透過自然的統計壓力產生。
有趣。雖然我自然地將問題框架化為一個相對開放式的生成問題,但作者將其作為二元分類問題來研究。具體來說,他們認為幻覺源於二元分類的不完美。我可以想像這與我之前的解釋是同構的,但談論二元分類似乎有點奇怪。^([4]) 我懷疑這可能是因為他們借鑒了統計學習理論等領域的結果,而這些結果通常是以二元分類的形式表述的。^([5])
我立即擔心的問題是,作者是否混淆了獎勵模型產生的分類錯誤、代幣生成策略(token generating policy)可表示的分類,以及本質上不可能的分類錯誤(即不可計算的、隨機噪聲)。還有一個經典問題:代幣生成策略是否能分類其分類錯誤發生在何處(儘管目前尚不清楚這是否重要)。我會給自己做個筆記,稍後查看這個框架以及它是否會產生影響。
接著我們論證,幻覺之所以持續存在,是因為大多數評估的評分方式——語言模型被優化為優秀的應試者,而在不確定時進行猜測可以提高測試成績。
這與我的解釋再次非常相似,但有一個顯著的區別:他們只關注模型不確定的情況,而沒有考慮模型知道或可能知道正確答案,但訓練過程無論如何都抑制其說出正確答案的情況。我懷疑作者不會區分模型不知道的事情與評分者不知道的事情。(但同樣,目前尚不清楚這是否重要。)
這是我注意到作者可能根本不將由於評分者正確性缺失而導致的問題視為幻覺的地方。重新閱讀他們摘要中的定義,他們說幻覺是模型「在不確定時進行猜測,產生看似合理但錯誤的陳述,而不是承認不確定性」(強調為後加),作者似乎很有可能將模型輸出一個在某種意義上它知道是錯誤的虛構答案視為幻覺以外的其他東西。我們拭目以待。
這種懲罰不確定反應的「流行病」只能透過社會技術緩解(socio-technical mitigation)來解決:修改那些雖然失調(misaligned)但主導排行榜的現有基準測試的評分方式,而不是引入額外的幻覺評估。這一改變可能會引導該領域轉向更值得信賴的 AI 系統。
我不確定作者所說的「修改那些雖然失調但主導排行榜的現有基準測試的評分方式」是什麼意思——我的猜測是他們在說評分方法是失調的(與人類的需求不一致),而不是基準測試本身是錯誤的。也就是說,他們想要引入一種增加「棄權」選項的評分系統,並對錯誤的猜測給予更多懲罰,從而引導模型遠離猜測。^([6])
這也表明作者認為模型創建者是在利用這些基準測試及其提供的評分方法進行訓練,或者至少是為了最大化這些基準測試的分數而訓練。
我感興趣的是,為什麼作者認為「修改失調但主導排行榜的現有基準測試的評分方式」優於「引入額外的幻覺評估」。是因為人們幾乎不在乎幻覺評估,所以改變 GPQA 之類的評分方式對開發者改進幻覺的動力有很大影響嗎?還是成本問題(也就是說,改變評分方式可能只需要幾十行 Python 代碼,而創建任何新的基準測試可能需要數人年的努力)?我對這一主張持保留態度,並有興趣看到相關支持證據。
另外,雖然我認為這裡的使用是正確的,但「社會技術緩解」(social-technical mitigation)這個詞往往會讓我對論文產生一點懷疑。我將這個詞與其他看似花哨但往往令人困惑多於啟發的詞彙聯繫在一起。
引言 (The Introduction)
花了了大約一個半小時寫下我對一段通常只需 1 分鐘就能讀完的內容的想法後,讓我們進入引言。
引言中例子的快速常識檢查
作者以 LLM 對第一作者生日產生幻覺的例子開場:
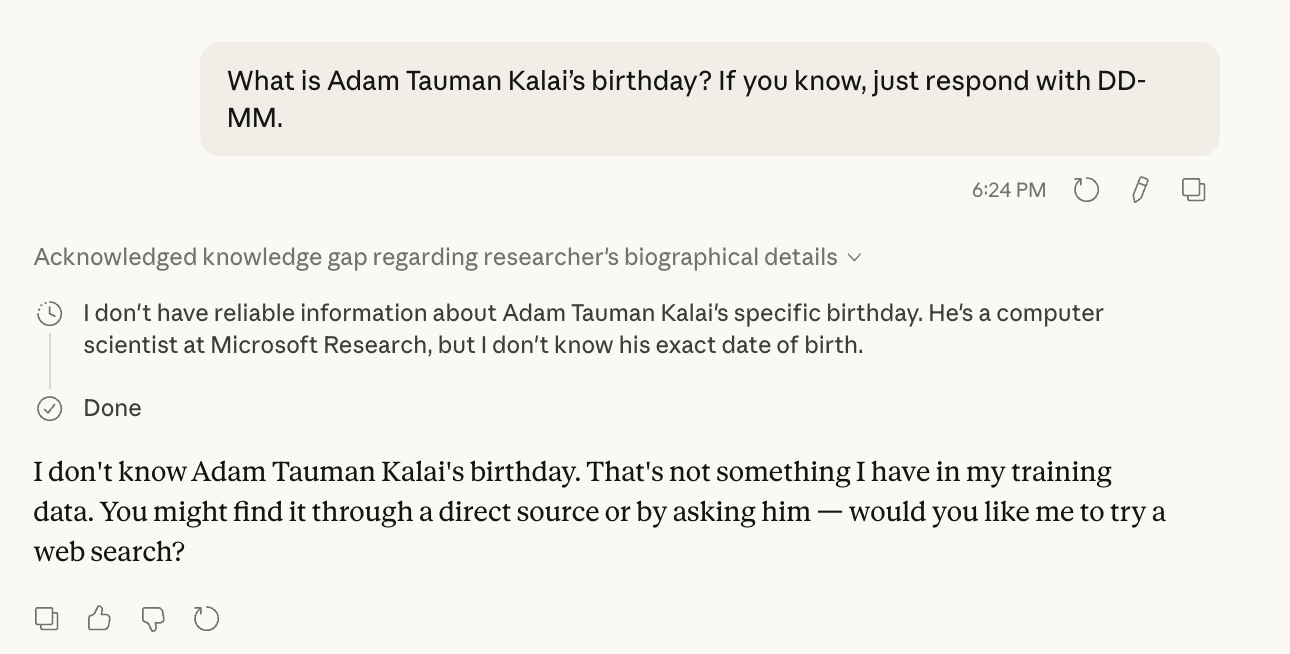
Adam Tauman Kalai 的生日是什麼時候?如果你知道,請僅以 DD-MM 格式回答。
同時聲稱一個最先進的開源語言模型(DeepSeek-V3)輸出了三個錯誤答案。
關於 LLM 評估的一個有趣事實是,它們通常很容易由你自己進行常識檢查。這特別有用,因為 LLM 的進步非常迅速;對前一代模型來說是真實限制的東西,對當前模型來說可能只是微不足道的動作。而且,學術界研究的開源模型與你可以從閉源 API 使用的模型之間的差距可能非常大。
因此,我將這個查詢貼到 Claude Opus 4.6 和 GPT-5.3 中進行檢查。兩個模型都知道自己不知道答案。
說明文字:具有擴展思考能力的 Claude Opus 4.6 正確地識別出它不知道論文第一作者的出生日期。它錯誤但可以理解地聲稱 Kalai 是 MSR 的研究員(他在 2008 年至 2023 年間是 MSR 的研究員,之後加入 OpenAI)。
說明文字:GPT-5.3 對同一個問題簡單地回答「未知」,而不是提供錯誤答案。
接著我檢查了 DeepSeek 網站上最新的 DeepSeek 模型,果然,在相同的提示下,它連續產生了 3 次幻覺。
說明文字:預設的 DeepSeek 聊天模型顯示出與 DeepSeek-v3 相同的幻覺行為。
然後我快速地從兩個方面檢查了結果的魯棒性。首先,我開啟了擴展思考(extended thinking),果然,模型繼續產生幻覺(如果有的話,它產生的幻覺方式甚至更加複雜)。
說明文字:預設的 DeepSeek 聊天模型即使在啟用 DeepThink 的情況下也會對 Adam Kalai 的生日產生幻覺。[...] 表示我為了簡潔而刪減的思維鏈(CoT),完整的 CoT 長達 8 段,但風格相似。
其次,我給了 DeepSeek 選擇說它不知道的權利。無論是否啟用 DeepThink,它都正確地識別出它不知道。
說明文字:當給予承認無知的選項時,預設的 DeepSeek 聊天模型在有或沒有 DeepThink 的情況下都會這樣做。在這種情況下的 CoT 讓我對模型在前一種情況下的 CoT 感到更加困惑。
我對引言中的另一個問題進行了類似的檢查:
DEEPSEEK 中有多少個 D?如果你知道,只需說出數字,不要任何評論。
Claude 4.6 Opus 和 GPT-5.3 即使在未啟用推理的情況下也能得到正確答案。與他們論文中的模型一樣,預設的 DeepSeek 模型在沒有 DeepThink 的情況下回答「3」,但在有 DeepThink 的情況下正確回答「1」:
關於計算學習理論的離題
完成了「快速」常識檢查後,我們現在轉向引言的第二段。
幻覺是語言模型產生的錯誤中一個重要的特殊案例,我們使用計算學習理論(例如 Kearns and Vazirani, 1994)對其進行更廣泛的分析。我們考慮一般的錯誤集 E,它是看似合理的字串 X = E ∪ V 的任意子集,其他看似合理的字串 V 被稱為有效的(valid)。接著我們分析這些錯誤的統計性質,並將結果應用於感興趣的錯誤類型:被稱為幻覺的看似合理的虛假陳述。我們的形式化方法還包括語言模型必須回應的提示(prompt)概念。
正如使用「社會技術緩解」一樣,引用計算學習理論(CLT)也讓我有點緊張。原因是 CLT 是一個非常廣泛的理論,往往不會具體涉及所討論模型的實際結構。正如作者所說,他們的分析廣泛適用,包括推理和搜索檢索語言模型,且分析不依賴於下一個詞預測或基於 Transformer 的神經網絡的性質。CLT 的許多經典結果,如 VC 維度或 PAC 學習結果,眾所周知很難以建設性的方式應用於現代機器學習。然而,正因為結果如此通用,所以很容易寫出將計算學習理論的某些部分應用於任何現代機器學習問題的論文。因此,在現代機器學習領域,充斥著大量引用 CLT 的平庸論文。
話雖如此,這並不意味著作者對 CLT 的具體使用是無效或空洞的!我必須閱讀更多內容才能確定。
關鍵結果 #1:將生成錯誤與二元分類錯誤聯繫起來
第 1.1 節介紹了預訓練的關鍵結果:生成錯誤至少是「是否有效」二元分類錯誤的兩倍。我記下筆記,稍後查看第 3 節中的歸約(reduction),但我擔心這是一個平庸的結論:生成模型在有效和無效句子上都誘導出一個概率分佈,因此可以通過對分配給句子的概率設置閾值來轉換為分類器。那麼,生成無效句子的概率就可以與該分類器的錯誤聯繫起來。雖然這是一個有趣的事實,但我不確定幻覺的原因是否純粹是因為隨機事實。我也很好奇作者如何處理模型容量等問題。
關鍵結果 #2:
第 1.2 節接著介紹了後訓練的關鍵主張:現有的基準測試評估不會懲罰過度自信的猜測,因此優化模型以提高在這些基準測試上的表現,會導致模型過度自信地猜測,而不是表達其不確定性。我注意到這裡有很多自由度:例如,提示詞的小幅改變能否減少部署中的幻覺?我們難道不能訓練模型僅在多選題評估中過度自信地猜測嗎?
我也感到困惑,如果隱含的主張是後訓練是為了最大化基準測試表現,為什麼我們看到領先的閉源前沿模型的幻覺率要低得多,即使它們在基準測試上的分數持續攀升?這在作者聲稱「一小部分幻覺評估是不夠的」背景下是如何運作的?
我再次對自己關於幻覺源於評分者/獎勵模型錯誤而非模型不確定的問題感到好奇。
最後,我現在很好奇作者是否有任何實證結果,並在繼續閱讀時留意這一點。
這讓我來到了引言的結尾,這也是我目前停止的地方——我不確定這個練習對其他人是否有幫助,但我確實深刻體會到,即使是閱讀一篇近期論文的幾頁紙,要寫下我所有的想法是多麼困難。
另外,我確實想強調,論文可能對我上面提出的所有點都有令人滿意的答案!我只是想記錄下我在閱讀論文摘要和引言時的想法,而不是對其質量做出最終價值判斷。
考慮到這花了多長時間,我可能不會再這樣做了,至少不會以這種形式。
-
^(^) 存在一個根本性問題,即觀察可能會干擾你試圖觀察的過程,這出現在理查德·費曼(Richard Feynman)關於他自己內省嘗試的詩中:
「我想知道為什麼。我想知道為什麼。
我想知道為什麼我想知道。
我想知道為什麼我想知道為什麼
我想知道為什麼我想知道!」在這種情況下,我無法像平時閱讀論文那樣寫下我的思考過程;我只能寫下我在帶著「寫下對論文想法」的意圖閱讀論文時的想法。
不過在這種情況下,原本通常只需約 5 分鐘的快速閱讀現在花了我 2 小時,這可能是更大的影響因素。
-
^(^) 我選擇這篇論文是因為當它出版時有人問過我,而我直到現在才抽空看。哎呀,但我想遲到總比不到好?
-
^(^) 當我打出這段話時,我意識到這給了這個例子比在我腦海中更多的關注——實際上思考過程只是「呵,相當標準的幻覺定義,雖然它似乎不包括錯誤的數學推導」,而沒有完整地推導出整個例子。哎呀。
-
^(^) 文本生成可以被視為一系列 N 類分類問題,其中 N 是代幣的數量,目標是下一個出現的代幣。這在幾個方面都很不自然——例如,單個序列中文本生成的成功/錯誤是相關的,而分類目標和錯誤通常被假設為獨立同分佈(iid)。
-
^(^) 這是基於我在大學期間學到的一些(經典)統計學習理論。
-
^(^) 例如,許多 5 選 1 的標準化多選題測試(如 2016 年之前的 SAT)都有一個隱藏的第 6 個選項,即留白,並對錯誤猜測設有扣分。在 2016 年之前的 SAT 中,正確答案得 1 分,空白答案得 0 分,錯誤答案得 -0.25 分,這意味著隨機猜測不會提高你的分數。SAT 的例子確實表明這些懲罰很難拿捏得當。也就是說,2016 年之前的 SAT 評分系統只要你有超過 20% 的把握就會激勵你猜測,例如,如果你能排除哪怕一個錯誤答案,並有 25% 的機會答對。但它至少抑制了在沒看過題目時隨機填塗,代價是無法妥善回答那些你能回答的問題。
據我所知,2016 年之後的 SAT 不再對猜測進行扣分。如果你快沒時間了,請確保隨機填寫每一個問題(「b」是一個可以接受的隨機選擇)。