
從 RTX 到 Spark:NVIDIA 加速 Gemma 4 以實現本地代理式 AI
Google 與 NVIDIA 展開合作,針對 NVIDIA GPU 優化了全新的 Gemma 4 模型系列,讓從 RTX PC 到邊緣 AI 模組的各式裝置都能實現高效能的本地執行。
開放模型正推動新一波裝置端 AI 浪潮,將創新從雲端延伸至日常裝置。隨著這些模型的進步,其價值日益取決於對本地即時情境的存取,進而將具意義的洞察轉化為行動。
專為此轉變而設計,Google 在 Gemma 4 系列中推出的最新成員,是一類小型、快速且具備全方位能力(omni-capable)的模型,旨在各種裝置上實現高效的本地執行。
Google 與 NVIDIA 合作針對 NVIDIA GPU 優化了 Gemma 4,使其在各種系統上都能發揮高效能——從資料中心部署到搭載 NVIDIA RTX 的 PC 與工作站、NVIDIA DGX Spark 個人 AI 超級電腦,以及 NVIDIA Jetson Orin Nano 邊緣 AI 模組。
Gemma 4:針對 NVIDIA GPU 優化的精簡模型
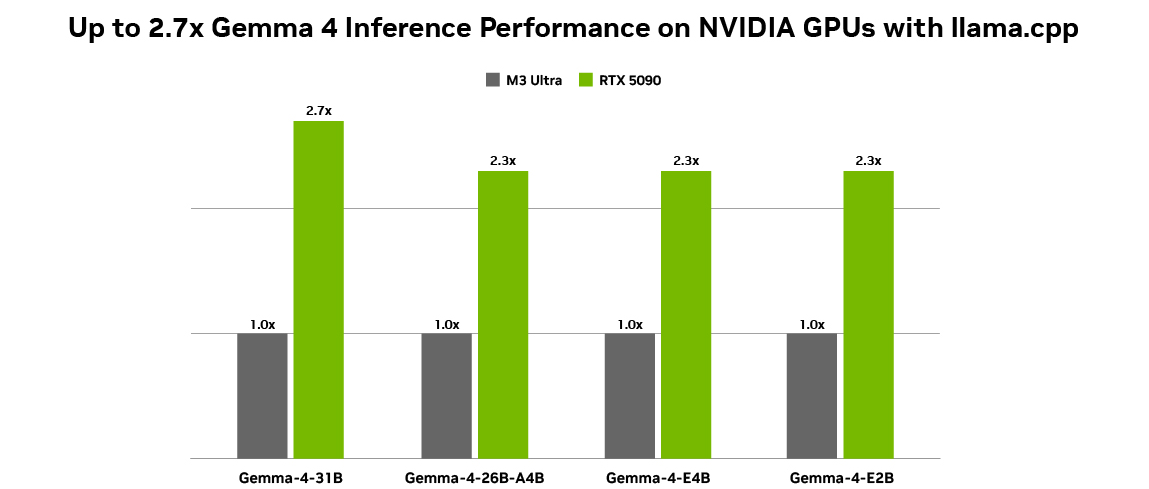
Gemma 4 開放模型系列的最新成員——涵蓋 E2B、E4B、26B 和 31B 版本——旨在實現從邊緣裝置到高效能 GPU 的高效部署。
* 所有配置均在 NVIDIA GeForce RTX 5090 和 Mac M3 Ultra 桌上型電腦上使用 Q4_K_M 量化、BS = 1、ISL = 4096 和 OSL = 128 進行測量。Token 生成吞吐量是在 llama.cpp b7789 上使用 llama-bench 工具測得。
{kind=link}
這新一代的精簡模型支援一系列任務,包括:
-
推理: 在複雜的問題解決任務中表現強勁。
-
程式碼: 為開發者工作流提供程式碼生成與除錯。
-
代理(Agents): 原生支援結構化工具使用(函式呼叫)。
-
視覺、影片與音訊能力: 實現豐富的多模態互動,用於物件識別、自動語音辨識以及文件或影片智能分析。
-
交錯式多模態輸入: 在單一提示詞中以任何順序混合文字與圖像。
-
多語言: 開箱即支援 35 種以上語言,並在 140 多種語言上進行過預訓練。
E2B 和 E4B 模型專為邊緣端的超高效、低延遲推理而建構,可在包括 Jetson Nano 模組在內的許多裝置上完全離線運行,且延遲趨近於零。
26B 和 31B 模型則專為高效能推理和以開發者為中心的工作流而設計,非常適合代理式 AI(agentic AI)。這些模型經過優化,可提供頂尖且易於取得的推理能力,在 NVIDIA RTX GPU 和 DGX Spark 上高效運行,為開發環境、程式碼助手和代理驅動的工作流提供動力。
隨著本地代理式 AI 持續升溫,像 OpenClaw 這樣的應用程式正讓 RTX PC、工作站和 DGX Spark 上的常駐 AI 助手成為可能。最新的 Gemma 4 模型與 OpenClaw 相容,允許使用者建立強大的本地代理,從個人檔案、應用程式和工作流中提取情境以自動化任務。了解如何在 RTX GPU 和 DGX Spark 上免費運行 OpenClaw,或使用 DGX Spark OpenClaw 指南。
查看 Google DeepMind 公告部落格以了解更多關於 Gemma 4 系列最新成員的資訊。
入門指南:在 RTX GPU 與 DGX Spark 上運行 Gemma 4
NVIDIA 已與 Ollama 和 llama.cpp 合作,為每個 Gemma 4 模型提供最佳的本地部署體驗。
若要在本地使用 Gemma 4,使用者可以下載 Ollama 來運行 Gemma 4 模型,或安裝 llama.cpp 並搭配 Gemma 4 GGUF Hugging Face 權重。此外,Unsloth 提供首日支援,透過 Unsloth Studio 提供優化且量化的模型,用於高效的本地微調與部署。立即開始在 Unsloth Studio 中運行並微調 Gemma 4。
在 NVIDIA GPU 上運行像 Gemma 4 系列這樣的開放模型可獲得最佳效能,因為 NVIDIA Tensor 核心能加速 AI 推理工作負載,為本地執行提供更高的吞吐量和更低的延遲。此外,CUDA 軟體堆疊確保了與領先框架和工具的廣泛相容性,使新模型從第一天起就能高效運行。
這種結合使得像 Gemma 4 這樣的開放模型能夠跨越各種系統進行擴展——從邊緣的 Jetson Orin Nano 到 RTX PC、工作站和 DGX Spark——而無需進行大量的優化。
查看 NVIDIA 技術部落格以獲取更多關於如何在 NVIDIA GPU 上開始使用 Gemma 4 的細節,並進一步了解 NVIDIA 在開放模型方面的工作。
#ICYMI:RTX AI PC 的最新更新
關注 RTX AI Garage 部落格,獲取來自 NVIDIA GTC 的一系列代理式 AI 公告,例如用於本地代理的新開放模型。這些模型包括 NVIDIA Nemotron 3 Nano 4B 和 Nemotron 3 Super 120B,以及針對 Qwen 3.5 和 Mistral Small 4 的優化。
NVIDIA 最近推出了 NVIDIA NemoClaw,這是一個開源堆疊,透過提高安全性並支援本地模型,優化了 NVIDIA 裝置上的 OpenClaw 體驗。
**Accomplish.ai 宣布推出 Accomplish FREE,這是其內建模型的開源桌面 AI 代理的免費版本。它利用 NVIDIA GPU 在本地運行開放權重模型,同時透過混合路由器在本地 RTX 硬體與雲端之間動態平衡工作負載——實現快速、私密、零配置的執行,且無需應用程式介面(API)金鑰。
在 Facebook、Instagram、TikTok 和 X 上關注 NVIDIA AI PC,並訂閱 RTX AI PC 電子報 以隨時掌握最新資訊。