提案:針對零知識證明(ZK)優化的驗證型 EVM 解釋器
這是一份關於如何利用驗證編譯技術,為即將到來的 zkVM 打造高效 EVM 解釋器的提案,旨在確保以太坊遷移至 ZK 系統時的安全性與執行效率。
你好,
這是一份提案,旨在討論如何利用「經驗證的編譯」(verified compilation),為即將到來的 zkVM 準備高效的 EVM 解釋器。
背景
為了將以太坊遷移到 ZK 系統(特別是在 L1 上),安全性至關重要。目前似乎已達成共識,即應使用所有可能的技術來確保安全,包括形式化驗證(formal verification)。
截至今日,在形式化驗證電路(circuits)和加密原語(cryptographic primitives)方面已投入了大量努力。由以太坊基金會資助的 https://verified-zkevm.org/ 是一個收錄近期相關專案的優秀頁面。
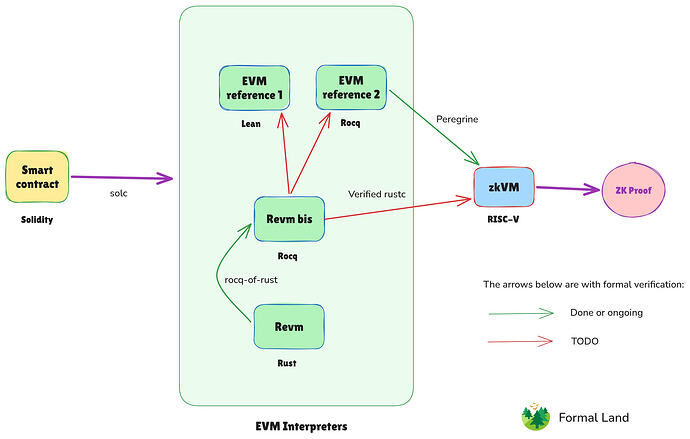
為了實現端到端的形式化驗證,我們還需要對 EVM 解釋器的組合語言代碼進行形式化驗證。因為電路通常是為 RISC-V 或類似的指令集架構(ISA)設計的,並運行如 Revm 或 Ethrex 等解釋器,這些解釋器也應該被驗證到組合語言層級。
現有技術
目前,可以使用驗證編譯流水線為 EVM 生成經驗證的組合語言代碼。該流程從使用形式化語言(Lean 或 Rocq)編寫的解釋器開始,通過經驗證的 C 編譯器 CompCert 下降到組合語言層級。請注意,CompCert 是用 Rocq 構建的,但透過 rocq-lean-import,可以在可計算項上連接 Lean 和 Rocq。一個封裝了 CompCert 的現代流水線專案是 Peregrine。
另一個尚處於早期階段的專案是直接用組合語言 (RISC-V) 編寫 EVM 解釋器,並形式化地驗證其正確實現了 EVM 規範。這就是用 Lean 編寫的 evm-asm 專案。
局限性
上述專案的一些局限性或風險如下,其中主要的風險可能是效率較低:
-
失去現有的 EVM 解釋器。 由於目前主流的 EVM 解釋器(Geth, Revm, Nethermind, ...)並非用形式化語言編寫,而上述技術需要形式化語言,我們將失去這些現有的代碼庫。這包括了多年來在可靠性和效率方面投入的所有工作。這或許是「沉沒成本謬誤」,但停用這些代碼庫確實會帶來風險。
-
效率。 編譯器和編程語言(如 Rust)包含許多能提高代碼效率的結構(內存操作原語)和優化階段,這些將會丟失或需要重新開發。這至關重要,因為 EVM 解釋器執行速度提升 2 倍,就直接等同於 zkVM 速度提升 2 倍。
-
可維護性。 如今,EVM 解釋器是用編程語言編寫的。若採用上述方法,開發者需要理解通常較難入門的形式化語言。對於 evm-asm 方法,即使是透過宏(macro)生成的,組合語言代碼也存在額外的維護成本。
-
多樣性。 這與前幾點相關;我們最終可能只剩下一個或兩個用 Lean 或 Rocq 編寫的 EVM 解釋器,這比目前可用的多種不同實現要少得多。
解決方案
我們的提議是為用於實現 EVM 解釋器的主要語言開發「形式化驗證編譯器」,首先從 Rust 開始,因為 Rust 是目前在 zkVM 上運行程序的主流選擇。
一些關鍵要素包括:
-
基於 rocq-of-rust 的語義,擴展對 Revm 的形式化工作,目前該工作已覆蓋其核心部分(由以太坊基金會資助)。
-
採用「驗證中」(verifying)編譯器方法,而非「已驗證」(verified)編譯器。這意味著修改 Rust 編譯器,使其在生成組合語言代碼的同時,生成一份形式化的等效性證明工件。這通常更簡單,因為不需要覆蓋所有通用情況(這往往是邊緣案例所在)。與 Rust 編譯器的向後兼容性可以通過比較生成的二進制代碼來檢查。
-
初期使用 CompCert 作為後端而非 LLVM。雖然它的優化較少,但一旦 LLVM 經過驗證,我們以後可以切換到 LLVM。
-
遵循 RustCompCert 論文中概述的證明策略,特別是針對借用檢查器(borrow checker)的部分。一個問題可能是:為什麼不直接使用它?在撰寫本文時它尚未完成,可能需要時間才能達到與官方 Rust 編譯器同等的水平,特別是因為它是一個「已驗證」編譯器,但也許我的看法有誤。
-
與當今任何新專案一樣,利用 AI 來處理生成等效性證明的所有繁重工作。
後續
我們目前還沒有具體的計劃,除了在夏季由我們自己開展該專案。我們很樂意討論您對此的看法!
1 則貼文 - 1 位參與者
[閱讀完整主題](https://ethereum-magicians.org/t/proposal-optimized-verified-evm-interpreters-for-zk/28086)