邁向二元樹之路(二):現今二元樹的速度有多快?MPT 與 BTree 的效能對決
二元樹在每項存儲操作上比生產環境的 MPT 慢約 2 倍,其中讀取慢 1.7 倍,寫入慢 2.5 倍。雖然差距確實存在但已受控,且在經過一週內 4 次優化 PR 後,效能差距正持續縮小。
這篇文章有更好的視覺化呈現方式(包含動態圖表和互動元件)。如果您偏好該版本,請參閱:Binary Trie Part 2 — How Fast Is the Binary Trie Today?
在每個儲存操作上,二元試圖(Binary Trie)比生產環境的 MPT 慢約 2 倍——讀取慢 1.7 倍,寫入慢 2.5 倍。原始的 Mgas/s 數據看起來更糟(高達 9.6 倍),是因為二元試圖分支版本使用了 EIP-4762 的 Verkle Gas 規則,使得相同的工作消耗更少的 Gas。在一週內進行了 4 次優化 PR 後,差距雖然存在但已受控。
S1 – 執行摘要
二元試圖已被列入 以太坊協議草案(Ethereum protocol strawman),作為未來的狀態樹替代方案(EIP-7864)。第一部分 確定了 GD-5 和 GD-6 是二元試圖的最佳群組深度(Group-Depth)設置。在確定這些參數後,下一個自然的問題是:優化後的二元試圖與生產環境的 MPT 相比表現如何?
測試內容
在相同的裸機硬體上對比 BT-GD5(bintrie 分支,commit 991300c4)與 MPT(upstream geth master,commit 5d0e18f7)。測試三種 ERC20 工作負載:erc20_balanceof(讀取)、erc20_approve(寫入)、mixed_sload_sstore(50-50 混合)。採用冷快取(Cold-cache)協議,每次運行間均清除 OS 頁面快取並設置 --cache 0。MPT:每個基準測試運行 100 次。BT-GD5:每個基準測試運行 10 次。
測試結果
-
讀取顯示 1.7 倍的吞吐量差距(第 4 節):在相同的 100M-gas 區塊中,MPT 提供 19.0 Mgas/s,而 BT 為 11.2 Mgas/s。讀取的 Gas 調度相同,因此 Mgas/s 是公平的對比。每次快取未命中(cache-miss)的成本為 2.8 倍(0.15 vs 0.41 毫秒/未命中)。
-
寫入在每個儲存插槽顯示 2.5 倍的差距(第 5 節):總時間為 0.23 vs 0.57 毫秒/插槽。原始 Mgas/s 比率(9.6 倍)具有誤導性,因為 BT 使用 EIP-4762 見證 Gas 規則,其中 SSTORE 成本約為 5,600 gas,而 MPT 在 EIP-2929 下約為 22,100 gas。
-
隨著交易數量(tx_count)增加,每次快取未命中的讀取成本上升 7.5 倍(第 6 節):在 BT 的 approve 區塊中,從 tx=1 時的 0.40 毫秒/未命中增加到 tx=9 時的 2.99 毫秒/未命中。預取器(Prefetcher)會先消耗熱的上層路徑節點,留下逐漸變冷的路徑。
如何閱讀本文
第 2 節涵蓋自第一部分以來的變化。第 3 節詳述方法論。第 4-5 節以敘事方式呈現結果:先是讀取(乾淨的對比),然後是寫入(Gas 調度差異需要仔細歸一化)。第 6 節探討更深層的架構模式——冷尾效應(cold tail effects)、為何雜湊時間實際上是試圖遍歷時間,以及造成差距的根本原因。第 7 節調查未來的優化路徑,第 8 節給出結論。時間緊迫?請從第 4 節的核心發現開始——它構建了整個討論的框架。
立場: 二元試圖目前尚未準備好投入生產,但差距正在縮小。
S2 – 自第一部分以來的變化
新硬體
第一部分在 QEMU 虛擬機(8 vCPU, 30 GB RAM)上運行。第二部分在裸機上運行——AMD EPYC 9454P 48 核(96 執行緒),配備 126 GB RAM 和 3.5 TB SSD RAID。這消除了虛擬化開銷並提供了更真實的 I/O 特性。由於硬體更換,第一部分和第二部分的絕對數值不可直接比較。
MPT 基準
第一部分比較了二元試圖的不同配置(GD-1 到 GD-8)。第二部分增加了首次跨架構對比:BT-GD5 vs 生產環境 MPT。這是對以太坊路線圖至關重要的問題。
優化 PR
摘要 (點擊查看更多細節)
更大的資料庫
| 資料庫 | 大小 | 膨脹量 | 狀態條目 |
|---|---|---|---|
| MPT | 1.6 TB | ~2.53 GB ERC20 | ~400M |
| BT-GD5 | 1.4 TB | ~2.76 GB ERC20 | ~400M |
兩個資料庫均使用 state-actor(100K 合約,種子 25519)生成,隨後使用 spamoor erc20_bloater 部署 ERC20 儲存。約 200 GB 的大小差異反映了二元試圖在 GD-5 下更緊湊的編碼。
在確定硬體和基準後,我們進入方法論——包括一個影響寫入基準測試解讀的關鍵 Gas 調度問題。
S3 – 方法論
摘要 (點擊查看更多細節)
S4 – 第一幕:讀取
erc20_balanceof 基準測試對一個極簡 ERC20 合約調用 balanceOf(),每個區塊處理約 36,741 個隨機地址。這是一個純讀取工作負載:每單位 Gas 的儲存查找量最大化,寫入或合約邏輯的開銷最小化。
這也是本研究中最乾淨的對比:兩種配置處理相同的 100M-gas 區塊,使用相同的 Gas 調度(EIP-4762 和 EIP-2929 對讀取的收費相同),相同的約 36,741 次插槽查找,且每個區塊僅一筆交易。無需歸一化——Mgas/s 是公平的對比。
MPT: 19.0 Mgas/s, BT: 11.2 Mgas/s – 1.7 倍差距 (p < 1e-6)
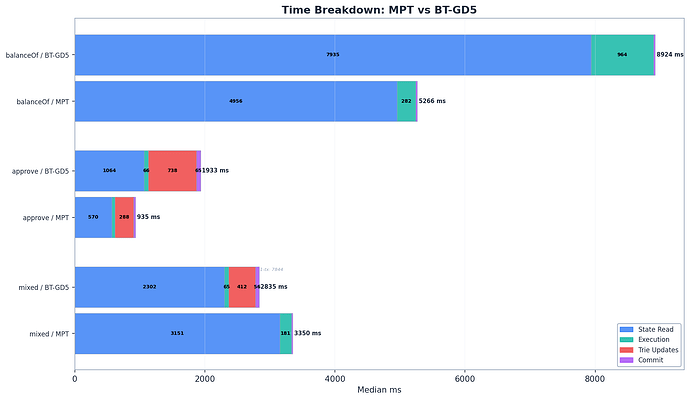
兩種配置處理相同的工作負載:每區塊 1 筆交易,約 36,741 次儲存插槽讀取,100M gas。組件拆解如下:
| 組件 | MPT | BT | 比率 |
|---|---|---|---|
| state_read_ms | 4,956 ms | 7,935 ms | 1.6x |
| execution_ms | ~280 ms | ~941 ms | – |
| state_hash_ms | 0.07 ms | 0.18 ms | – |
| commit_ms | 27.8 ms | 24.5 ms | 0.9x |
| total_ms | 5,264 ms | 8,901 ms | 1.7x |
狀態讀取在兩種配置中均佔主導地位——佔 MPT 時間的 94%,BT 的 89%。state_read_ms 中 1.6 倍的差距是核心懲罰:二元試圖路徑更深(GD-5 下約 52 個群組節點,每個封裝一個 5 層子樹,而 MPT 約為 5-6 個十六進制分支節點),且在冷讀取時,每個群組節點都需要通過 Pebble 的 LSM 樹進行單獨的資料庫查找。
每插槽讀取成本: 0.135 vs 0.216 毫秒/插槽 = 1.6 倍。
每次快取未命中讀取成本: 0.146 vs 0.405 毫秒/未命中 = 2.8 倍 (95% CI: [2.22, 3.36])。每次快取未命中代表從磁碟進行一次完整的試圖遍歷。這完全排除了快取率差異的影響,代表了遍歷二元試圖路徑(通過 Pebble 讀取約 52 個 GD-5 節點)相對於 MPT 十六進制路徑(約 5-6 個分支節點)的原始成本。
快取注意事項:BT 的 35% 快取命中率相對於 MPT 的 7% 是預取器的產物,而非二元試圖的快取優勢。兩者使用相同的 stateReaderWithCache 代碼路徑。BT 較慢的每插槽解析速度給了預取器協程(goroutine)更多時間領先並預熱共享 Map。
[圖表 1]
[圖表 2]
balanceof 面板適用於直接對比。approve 和 mixed 面板顯示的是 Mgas/s,這會受到寫入 Gas 調度不同的干擾——見第 5 節。
[圖表 3]
對於讀取,差距是真實存在的,根據指標不同落在 1.7–2.8 倍之間。二元試圖更深的路徑(約 52 vs 5 個節點)使得每次遍歷更昂貴,但其增加幅度低於 10 倍深度差異所預期的程度。寫入則是另一回事,且更為複雜。
S5 – 第二幕:寫入
erc20_approve 基準測試對相同的極簡 ERC20 合約調用 approve(),每個區塊處理約 4,094 個隨機授權地址。每次調用觸發一次冷 SLOAD(讀取當前餘額)隨後是一次冷 SSTORE(寫入新餘額)。與 balanceof 不同,此工作負載同時測試了試圖的讀取和寫入路徑。
approve 基準測試揭示了一個重要的方法論注意事項:bintrie 分支使用了 EIP-4762 基於見證的 Gas 規則 (IsVerkle()=true),其中 SSTORE 成本約為 5,600 gas,而 MPT 在 EIP-2929 下約為 22,100 gas。對於同樣的 4,094 次儲存操作,MPT 消耗約 93.7M gas,而 BT 僅消耗約 24.4M——相差 3.85 倍。用較少的 Gas 除以實際時間會產生較低的 Mgas/s,因此原始 Mgas/s 不是寫入工作負載下有效的跨架構指標。
每插槽時間是主要的對比依據:
| 基準測試 | MPT 毫秒/插槽 | BT 毫秒/插槽 | 比率 | 95% CI |
|---|---|---|---|---|
| approve (總計) | 0.229 | 0.569 | 2.5x | [2.24, 2.64] |
| approve (雜湊) | 0.070 | 0.184 | 2.6x | [2.51, 2.73] |
| approve (讀取) | 0.139 | 0.260 | 1.9x | – |
每插槽總時間比率(approve 為 2.5 倍)是最公平的寫入對比。兩種配置在單筆交易區塊中均處理 4,094 個儲存插槽。2.6 倍的雜湊成本反映了 BT-GD5 的內部子樹重新雜湊——每個節點 2^5 - 1 = 31 次雜湊操作,對比 MPT 更緊湊的結構。1.9 倍的讀取成本略高於 balanceof 的 1.6 倍,因為 balanceof 讀取約 36,741 個插槽,而 approve 僅約 4,094 個。由於讀取量多出 9 倍,balanceof 更徹底地預熱了上層試圖節點快取——共享路徑前綴只需解析一次即可重複使用。Approve 較小的工作負載使得每次讀取時有更多上層試圖路徑處於冷狀態。
[圖表 4]
[圖表 5]
作為參考,原始 Mgas/s 數據為 99.8 vs 10.4(9.6 倍),但此比率將架構性能差距與 Gas 調度差異混為一談。Mgas/s 在 MPT 內部或 BT 內部的對比中仍然有用,但不適用於寫入工作負載的跨架構對比。
真正的差距在於每儲存插槽讀取約 1.7 倍,寫入約 2.5 倍。從架構上看,是什麼導致了這種差距?數據中是否有更深層的模式?
S6 – 深層模式
6a. 冷尾效應(Cold Tail Effect)
這是本研究中最有趣的發現。
在 BT approve 區塊中,隨著 tx_count 增加,每次快取未命中的成本上升 7.5 倍。
在多交易區塊中,預取器會先快取易於訪問的插槽。隨著交易數增加,剩餘的快取未命中對應於逐漸變冷、更深的試圖路徑。機制如下:預取器協程先消耗熱的上層共享節點。後期的未命中在較淺的深度就開始分叉,需要在試圖路徑的每一層進行新的磁碟尋道。
| tx_count | 區塊數 | 中位數 毫秒/未命中 | vs tx=1 |
|---|---|---|---|
| 1 | 9 | 0.40 | 基準 |
| 5 | 6 | 1.37 | 3.4x |
| 6 | 1 | 1.61 | 4.0x |
| 7 | 2 | 2.07 | 5.2x |
| 8 | 5 | 2.90 | 7.3x |
| 9 | 2 | 2.99 | 7.5x |
這不是測量誤差。這是二元試圖訪問模式的一個基本屬性:頻繁訪問的插槽聚集在較熱的試圖區域,當預取器先處理完這些插槽後,剩餘的未命中將命中日益寒冷的路徑。冷尾效應解釋了為何 approve 和 mixed 的每未命中成本(8.4–8.5 倍)遠高於 balanceof(2.8 倍)——多交易區塊在快取後只留下了最困難的未命中。
[圖表 6]
6b. 架構開銷
性能差距源於兩種試圖設計之間根本的結構差異。
為何 MPT 每次查找僅需 5–6 個節點: MPT 使用獨立的每帳戶儲存試圖,具有 16 路十六進制分支。帳戶查找遍歷帳戶試圖中的約 5 個分支節點,然後進入目標插槽所屬的獨立且較小的儲存試圖。每帳戶試圖很淺,因為它僅索引該帳戶的儲存,而非整個狀態。
為何 BT 每次查找需要約 52 個節點: 二元試圖將所有帳戶和儲存統合成一個單一的 256 位元金鑰空間。每個金鑰都經過 SHA-256 雜湊,在 GD-5 下每個節點封裝 5 個二元層級(2^5 = 32 個子指標)。從根到葉的完整遍歷跨越約 52 個磁碟節點——每個都需要單獨的 Pebble 查找。
為何雜湊成本從基本原理看是 2.6 倍: 每個 GD-5 群組節點包含一個 5 層內部二元子樹。當金鑰被修改時,通過子樹的髒路徑需要 5 次雜湊操作(每層一次)。路徑上有約 52 個群組節點,單金鑰更新總共觸發約 260 次 SHA-256 雜湊。如果多個金鑰弄髒了同一個群組內的不同路徑,成本會上升到最壞情況下的每群組 2^5 - 1 = 31 次雜湊。相比之下,MPT 在約 5 個路徑節點上更新約 2-3 個分支修改,產生約 10-15 次更新。實測的 2.6 倍差距遠小於原始雜湊計數比率,因為 95-98% 的「雜湊時間」實際上是節點遍歷、髒節點收集和 I/O——而非加密操作本身(見下文 6c)。
| 屬性 | 二元試圖 (GD-5) | MPT |
|---|---|---|
| 雜湊函數 | SHA-256 | Keccak-256 |
| 結構 | 統一試圖 (所有帳戶 + 儲存) | 獨立的每帳戶儲存試圖 |
| 路徑深度 | 每次查找約 52 個節點 | 約 5–6 個分支節點 |
| 節點大小 | ~1 KB (32 子指標 x 32 bytes) | 可變 (分支節點最多 17 個插槽) |
| 金鑰分佈 | SHA-256 雜湊至 256 位元空間 | 每個試圖獨立 Keccak-256 雜湊 |
| 每次寫入內部雜湊數 | 5/節點 x ~52 節點 = ~260 (單金鑰) | ~2–3/節點 x ~5 節點 = ~10–15 |
6c. 雜湊時間即試圖遍歷
state_hash_ms 指標的命名具有誤導性。它測量的是完整的狀態根重新計算:遍歷試圖以定位髒節點、在雜湊計算需要時從磁碟讀取兄弟節點,以及計算加密雜湊。它由 I/O 和遍歷主導,而非雜湊函數本身。
-
MPT: 4,094 個插槽的雜湊時間為 288 毫秒。相同數據量的純 Keccak-256 成本約為 4.8 毫秒。這意味著試圖操作帶來了 60 倍的開銷。
-
BT: 4,094 個插槽的雜湊時間為 727 毫秒。純 SHA-256 成本約為 38 毫秒。這意味著試圖操作帶來了 19 倍的開銷。
95-98% 的「雜湊」時間是節點遍歷、髒節點收集和序列化——而非實際的 SHA-256 或 Keccak 加密。結論很明顯:優化雜湊函數(SHA-256 vs Keccak)不會顯著改變性能差距。優化試圖遍歷和節點更新路徑才會。
從架構模式出發,我們來看看可以做些什麼。
S7 – 縮小差距
剩餘的優化途徑
快照層(Snapshot layer)/ pathdb 快速讀取: 在 geth 目前的 pathdb 方案中,平面狀態讀取已經使用類似快照的路徑——通過差異層直接進行雜湊查找至磁碟,本質上是鍵值對獲取。Geth 開發者預計 pathdb 的讀取速度將接近快照級別。如果這對二元試圖也成立,1.7 倍的讀取差距可能會顯著縮小。剩餘的差距將是 2.6 倍的寫入成本——這由試圖遍歷和兄弟節點解析主導,快照層無法避免。
Pebble 區塊大小調優: GD-5 節點序列化後約為 1 KB。Pebble 預設的 4 KB 區塊大小意味著每個區塊可容納多個節點,但 NVMe 頁面讀取基準測試 顯示隨機 16 KB 讀取的吞吐量是 4 KB 的 2.3 倍。如果較大的 Pebble 區塊能更好地匹配訪問模式,可能會有幫助。
並行執行: NVMe 在 QD=8 時的隨機 4 KB 吞吐量比 QD=1 提高 8.7 倍(673 vs 77 MB/s)。並行 EVM 執行可以增加有效的 I/O 隊列深度,壓縮不同架構間的讀取延遲差異。
--cache.noprefetch 基準測試: 禁用交易級預取器將移除預熱共享狀態快取的並行預執行,從而顯示沒有該優化時的原始試圖性能。然而,試圖節點預取器(在交易處理期間預填試圖節點)仍會保持活動。這將提供一個部分受控的視角——比目前的數據更乾淨,但仍非純粹的冷試圖性能。這也會犧牲一個真實的生產環境優化,因此結果無法反映實際部署的行為。
S8 – 結論:二元試圖準備好了嗎?
二元試圖目前尚未準備好投入生產。 約 2 倍的讀取差距是關鍵擔憂,因為以太坊是讀取密集型的。然而,優化軌跡令人鼓舞——一週內合併了 4 個 PR——且最大的潛在改進(快照層)尚未被探索。
12 秒時段預算(Slot Budget)
BT 距離適應以太坊 12 秒的時段窗口還有多遠?
| 基準測試 | BT 處理 100M Gas 的時間 | 佔 12s 時段的百分比 |
|---|---|---|
| balanceof | ~8.9 s | 74% |
| approve | ~7.6 s | 64% |
| mixed | ~10.9 s | 91% |
BT 在混合負載下佔用 12 秒時段的 91%,幾乎沒有留給網路傳輸、證明(attestation)和其他非執行開銷的餘地。在典型的驗證者硬體上(通常比我們的 48 核 EPYC 規格更低),如果沒有進一步優化,這可能是不可行的。相比之下,MPT 在 3.4–5.3 秒內處理 100M gas(佔時段的 28–44%)。雖然這看起來留有餘地,但實際上的區塊執行預算更緊湊——重新執行、網路和證明開銷消耗了大部分剩餘時間。以太坊一直運行在其執行預算的邊緣,儘管目前尚未發生事故。
決策框架
| 因素 | 有利於 BT | 有利於 MPT | 權重 |
|---|---|---|---|
| 無狀態客戶端證明 | 中等 (見證數據更小,有助於 ZK-EVM 證明生成,儘管 ZK-EVM 目前已支持 MPT) | – | 高 |
| 當前讀取吞吐量 | – | 強 (快 1.7–2.8 倍) | 高 |
| 當前寫入吞吐量 | – | 強 (每插槽快 2.5 倍) | 高 |
| 優化上限 | 中等 (早期階段,速度快) | 低 (成熟代碼庫) | 中 |
| 代碼複雜度 | 較簡單 (統一試圖) | 複雜 (每帳戶試圖) | 低 |
持續存在的模式
模式 1:讀取差距真實存在但受控 (1.7–2.8x)。 每次快取未命中的對比 (2.8x) 是上限;原始吞吐量 (1.7x) 是下限。兩者均值得信賴——它們使用相同的 Gas、相同的插槽數、相同的交易數。二元試圖約 52 節點的路徑對比 MPT 約 5 節點的路徑使得每次遍歷更貴,但遠低於 10 倍深度比率所暗示的程度。
模式 2:BT 受限於讀取。 在讀取密集型工作負載中,狀態讀取佔 BT 區塊處理時間的約 89%,MPT 則為 94%。讀取路徑是主要的優化目標——減少單個節點的讀取延遲會在每次查找的約 52 個節點中產生複利效應。
模式 3:雜湊成本為每插槽 2.6 倍,且由試圖遍歷主導。 這是來自 GD-5 每個節點 2^5 - 1 = 31 次內部雜湊操作的純寫入懲罰。但測得的雜湊時間中 95-98% 是試圖遍歷和序列化,而非加密雜湊。更換雜湊函數不會有實質性幫助。
開放性問題
-
快照層基準測試: 平面快照層是否能縮小讀取差距?這是二元試圖生產可行性中最重要的單一實驗。
-
--cache.noprefetch 運行: 禁用預取器的基準測試將消除快取不對稱的干擾,提供最純粹的試圖對試圖對比。
-
主網讀寫比率分析: 以太坊區塊是讀取密集型的,但確切比率尚未經過系統測量。1.7 倍讀取差距與 2.5 倍寫入差距的實際影響取決於此比例。
-
資料庫架構重新設計: 不同的磁碟佈局是否能減少二元試圖的遍歷懲罰?目前的實現將每個 GD-5 節點存儲為單獨的 Pebble 金鑰——替代佈局(例如將路徑兄弟節點放置在一起)可能會減少尋道開銷。
-
Pebble 是否是統一二元試圖的正確資料庫引擎? 二元試圖的訪問模式——每次儲存讀取約 52 次順序金鑰查找,每次解析不同的群組節點——與 MPT 的每帳戶儲存試圖有根本不同。針對前綴順序讀取優化或更好地支持二元試圖訪問模式的資料庫引擎可能會縮小讀取差距。
基準測試在以太坊 execution-specs 框架上運行,使用 geth 二元試圖分支 (EIP-7864)。方法論、原始數據和可重複性腳本可在 bintrie-benchmarks 儲存庫 中獲得。本系列的第一部分:Narrower Than Expected: Optimal Group Depth for Ethereum’s Binary Trie。
1 則貼文 - 1 位參與者
[閱讀完整主題](https://ethresear.ch/t/the-path-towards-binary-tries-2-how-fast-is-the-binary-trie-today-mpt-vs-btree/24564)