Anthropic 負責任縮放政策 v3:深入細節分析
本文分析了 Anthropic 新發布的負責任縮放政策 v3.0,認為該政策從硬性承諾轉向了更具靈活性、基於信任的框架,這可能會削弱先前對安全性的保證。
週三的貼文 討論了 Anthropic 將其負責任擴展政策(RSP)從 v2.2 變更為 v3.0 的影響,包括這打破了許多人在做出重要決定時所依賴的承諾。
今天的貼文將 RSP v3.0 視為一份全新的文件並對其進行評估。
首先,我將從高層次概述 RSP v3.0 的運作方式。接著,我將深入探討「路線圖」(Roadmap)和「風險報告」(Risk Report)。
RSP v3.0 的運作方式
通常我會密切關注新 RSP 的確切文字內容。
在這種情況下,並不是說 RSP 不重要。我確實認為 RSP 會對 Anthropic 選擇做什麼產生一些影響,路線圖和隨之而來的風險報告也是如此。
然而,其基本的設計原則是「靈活性」和「強有力的論據」,且他們可以隨時更改內容,這一切都意味著核心原則是「信任」。
我對內容的解讀是「這些是我們擔心並計劃要做的事情」,在實踐中,這大多等同於做他們認為正確的事;而且我看不到這份地圖上有任何內容,在 Anthropic 普遍關心其模型安全(基於其對相關風險的理解)的情況下,可能對其產生重要的約束。
目前看來最重要的實際軟性「承諾」是:定期發布新的風險報告、維持一份前沿安全路線圖(Frontier Safety Roadmap),以及在重大能力進展上,為首席安全官(CSO)、執行長(CEO)、董事會和長期利益信託(LTBT)建立否決點。
我不認為這裡的承諾反映了我對「強大 AI」相關風險的理解,特別是在自動化研發(R&D)領域。
-
這是一份行動計劃,而非一套承諾。請據此制定對策。
-
計劃的一部分是維持一份包含進一步計劃的前沿安全路線圖,這些計劃完全可能變動,儘管他們會努力避免降低其雄心。
-
另一個要素是定期的風險報告,這是對先前風險報告的補充,每 3-6 個月提供一次整體概況(如他處所述)。關鍵目標是完全坦誠地說明整體風險狀況,包括模型何時構成絕對風險,但並未引入太多邊際風險(因為你應該看看競爭對手的情況)。
這應包括事實資訊、威脅模型、證據、緩解措施、風險分析、對過去決策的審查以及任何其他相關資訊。
-
他們將「致力於建立一種做法」,針對這些報告尋求全面的、公開的外部審查。
-
他們提供了第一份風險報告,因此我們可以藉此判斷未來的預期。
-
ASL-3 緩解措施應繼續全面適用於 Anthropic 的模型。安全措施現在必須防範內部威脅,他們建議業界也這樣做(包括對執行長的防範),並點名了 RAND 的 SL4 標準。這很好。
-
他們現在同時提供了「這是我們自己會做的事」和「這是我們希望要求每個人都必須做的事」。
這兩者確實可以是不同的事情,但在這種情況下,如果 Anthropic 沒有渴望並極力嘗試至少做到他們認為應該普遍要求的事(甚至更多),我會感到驚訝。我不認為目前的框架能促使這種情況發生。
-
其框架是「要在整個行業層面保持安全需要做到這些」,因此 Anthropic 做的任何少於此標準的事,按其邏輯,都將不足以保證我們的安全。
-
目前尚不明確 Anthropic 在他人不遵守的情況下,會在多大程度上努力符合這些規則。他們並未承諾會這樣做,但話說回來,RSP v3 中沒有任何內容是承諾。
-
如果 Anthropic 在領先地位時,沒有達到或超過它所呼籲的全球規則,那麼正如 Peter Wildeford 所言,這標誌著他們的自願自我治理實驗已基本失敗。這還補充了 aysja 的觀點:如果 Anthropic 不信任自己能準確衡量可能觸發暫停的能力,這也表明此類實驗是失敗的,儘管這是一個優雅的失敗,因為 Anthropic 察覺到了自己的失敗。
-
對其他實驗室的激勵效果是好的,但我認為在沒有他們參與的情況下施加壓力會更強大。在實踐中,我預計這會削弱承諾。
-
確保 Anthropic 保留執行暫停或限制的物理能力的機制和動力已經消失。我擔心這實際上意味著它甚至不會被考慮,或者 Anthropic 不會為此做好準備。你需要硬性承諾擁有暫停或限制的物理能力。
-
這裡沒有部署前的門檻機制。你可以直接發布產品。這是最不該缺失的東西。
-
他們比以前更明確地解釋說,他們將在競賽中保持步調,即使這樣的發布是不安全的;他們正在收回不發布潛在不安全模型的承諾。
他們的藉口是:「如果一家 AI 開發商為了實施安全措施而暫停開發,而其他開發商則在沒有強大緩解措施的情況下繼續訓練和部署 AI 系統,這可能會導致一個更不安全的世界。」
-
然而,如果 Anthropic 處於領先地位,只有在那時他們才承諾安全,除非他們再次改變主意。
-
如果競爭對手有強大的安全措施,他們計劃至少與之匹配。
-
除非他們付出了相當大的努力卻做不到,在這種情況下,他們不會讓這件事耽誤進度。
-
我認為《時代》雜誌將此歸類為「Anthropic 放棄旗艦安全承諾」是正確的。
-
ASL 等級已被棄用,取而代之的是「需要分析和論證以提出強有力的安全理由」。他們承認這「留下了靈活性」,且不同的人對其含義會有分歧。
從局外人的角度來看,ASL 等級的核心點是束縛 Anthropic 的手腳,使他們即使後來發現代價高昂,也必須履行承諾,或者至少必須承認他們沒有做到。
-
Holden 列出的目標是:對風險緩解產生強迫功能、為實踐和政策建立測試平台,以及致力於就風險達成共識和共同知識。Holden 認為 RSP v3 有效地保留了這些目標。我不這麼認為。
-
如果你所要做的只是提出一個能說服自己的安全案例,那麼只要這件事對你足夠重要,你總能做到。
-
我同情「我們不知道所有的紅線會是什麼」。但如果你連一條紅線都說不出來,那不是一個好跡象。
-
我對這一變化的解讀是:關於模型發布的決定,我們幾乎沒有任何有意義的承諾,即使我們遵守了所有目前的「承諾」(而這些並非承諾)。
-
他們承諾會提出一個好的論據。而由他們來決定什麼是好的論據。
-
RSP 現在要求發布 FSP(前沿安全路線圖,以防縮寫不夠混亂),描述在安全(Security)、對齊(Alignment)、保障措施(Safeguards)和政策(Policy)方面的風險緩解。
為什麼不把它們放在 RSP 裡?我想是因為「它們經常更新」。
-
這些是「公開目標」而非「承諾」,儘管承諾本身也不是承諾。我們需要為這些事物創造新詞。
-
原則上,同時擁有硬性承諾和願景目標似乎沒問題,但這只有在存在任何硬性承諾時才有效,而現在一個都沒有。只有軟性承諾和願景目標。那麼,我們是根據軟性承諾來評分嗎?
-
這是因為他們想確保不違反 SB 53 或 RAISE 法案嗎?
-
風險報告將在發布時提供詳細的安全資訊,並每 3-6 個月在網上發布一次。在「某些情況下」將需要外部審查。這是對模型發布時的能力評估和模型卡的補充,而非替代。
為什麼會有人不想要外部審查?Holden 說外部審查風險高且具實驗性,但我認為既然這不與模型發布掛鉤,也不具備停止功能,你大可以直接去做。
-
如果你不配合新模型的發布,你如何有意義地評估能力?你如何按此節奏進行風險評估?
-
答案是,他們承諾在發布新模型時,或在意識到內部模型需要進行差異分析後的 30 天內,提供與舊風險報告的差異分析(diff)。
-
當模型每 2 個月發布一次時,3-6 個月是很長的時間。
-
「風險收益判定」是所有事情最終的運作方式,但這似乎是實踐中不讓風險阻止你的又一步。
-
外部審查是好的,但看起來又會太遲?
-
審查內容已全面修訂。
生物和化學保障措施繼續保留,見下一節。
-
放射性和核能風險完全消失了,我們不再關心。
-
不再檢查自主性,因為模型已完全具備自主性,我們正基於此假設前進。
-
網絡行動(Cyber Operations)完全消失。或許是因為它能通過每一項測試?儘管這是 OpenAI 和 Google 的核心測試項目。
-
有效算力檢查點消失了。
-
總結:噢,你們會提高標準。噢,你們會移動球門。
-
當評估是基於「感覺」(vibes)且即便如此也沒有真正的承諾時,我很難認真對待這件事。Anthropic 會檢查感覺,然後決定是否看起來安全。告訴我為什麼我錯了。
-
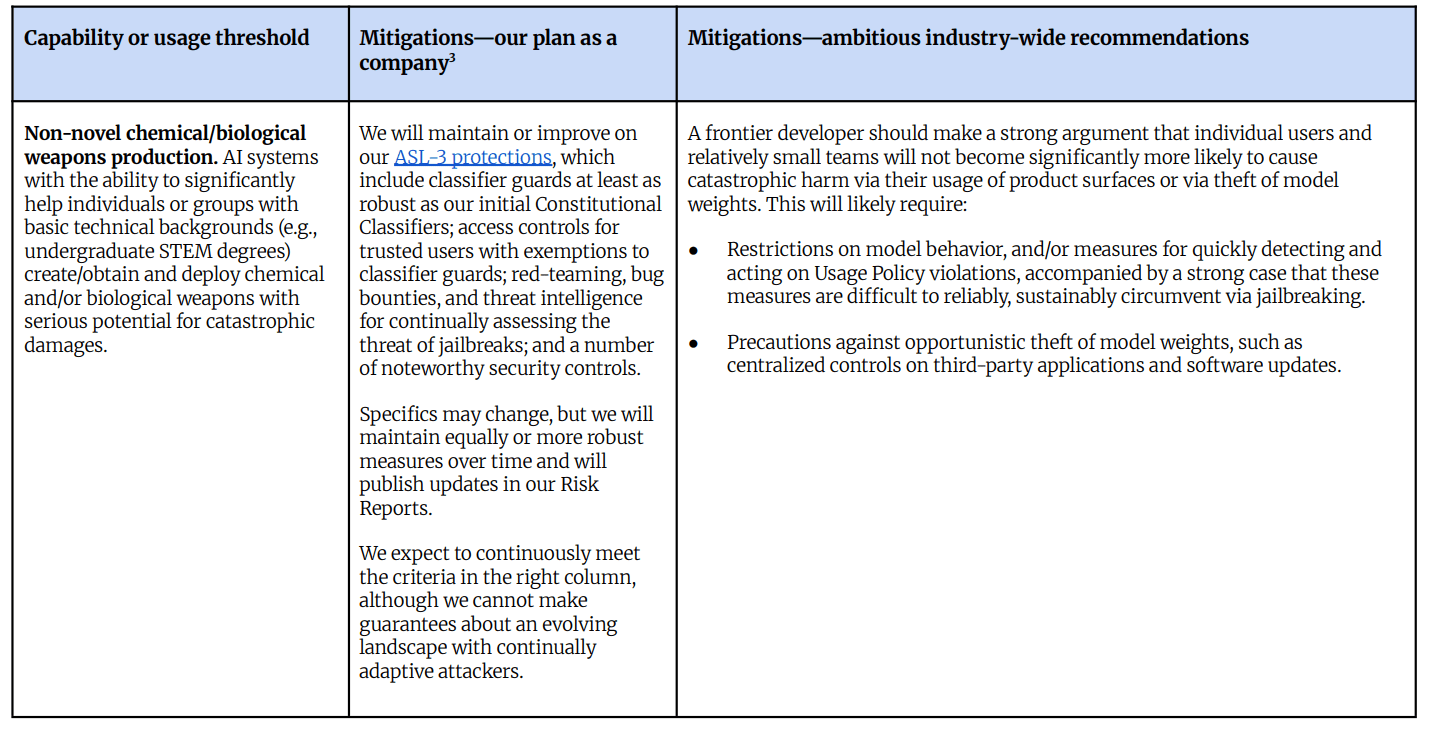
生物和化學保障措施。
非新型化學或生物武器生產是新的 CBRN-3。
這要求未來基本上所有模型都要具備 ASL-3 等級的保護。
-
他們明確目標並預計達到行業範圍的標準(請注意,這意味著在他們沒說預計或目標達到標準的地方,推測他們並不預計或目標達到該標準)。
-
目標是提出「強有力的論據」,證明小團隊不會顯著更有可能造成災難性傷害,推測是通過防範模型權重被盜和監控模型行為。
-
開源權重模型推測不可能滿足這一點。
-
新型化學和生物武器是新的 CBRN-4。
掌握在「資源中等且有專家支持的團隊」手中的武器,必須具備「造成遠超 COVID-19 等過去災難的潛在災難性破壞」。所以這是一個極高的門檻,推測你可以把這裡的「化學」刪掉。
-
這裡的額外回應是「為早期檢測特定威脅路徑建立政策建議」。
-
他們建議的行動再次是為一套緩解措施提出「強有力的論據」,他們預計這將符合 RAND SL4 標準,外加使用監控。
-
考慮到越獄(jailbreaking)的現狀,「監控使用」的計劃看起來並不太好。
-
高風險破壞機會(High-stakes sabotage opportunities)是一個針對 AI 公司內部系統的新類別,特別是關於後續模型。好主意。
雖然我很高興看到破壞被納入,但與擔心 AI 脫離控制、奪取控制權或做其他各種事情相比,這是一個奇怪的框架或焦點。目前尚不清楚任何損害我們機會的行動在多大程度上算作此類(從而被全部納入),還是不算。無論如何,這是一個相當令人困惑的框架。
-
他們的「承諾」回應是詳細說明系統的能力。他們還預計能滿足其政策建議要求。
-
該要求再次是「強有力的論據」,此處指模型不會進行「導致全球災難機率不可逆轉且大幅增加」的破壞。
這對破壞行為來說是一個相當高的門檻。
-
他們預計這最終將涉及內部劃分、限制和代碼審查,以防止 AI 模型有過多的破壞機會,以及能力評估、內部監控和/或限制行為與使用,以及缺乏傾向的證據。
-
如果這是一套具體的要求,它可能會很強大。
-
作為「我們預計這將需要」的內容,很難知道它是否具有任何意義。
-
「關鍵領域的自動化研發」是新的 AI R&D-5,也就是大魔王,其操作定義為「能將 2018-2024 年兩年的 AI 進展壓縮到一年內」,即 100% 的加速。
正如他們所指出的,這是一個很高的門檻,而他們目前連較低的門檻都還沒達到。
-
Claude Opus 4.6 估計它能提供約 9% 的加速。
-
GPT-5.4-Pro 估計約 30% 的加速(Thinking 說是 25%)。
-
我會賭實際數字比這更高。
-
我還希望在「Claude Opus 4.6 能做的事」和「奇點就在現在開始」之間增加一個額外的門檻。
-
如果或當他們達到「關鍵領域的自動化研發」時,他們計劃做什麼?
「資助並完成重大的『安全登月研發』項目。」
-
對我們的內部開發實現「監控一切」(eyes on everything)的狀態。
-
執行系統性的對齊評估。
-
開發優於外部紅隊測試工作的內部紅隊測試。
-
發布風險報告。
-
做得比其他人好,但他們不能保證任何事。
-
理想的全球要求是什麼?另一個「強有力的論據」,在這種情況下是為了:
任何用戶團隊都不會以此造成重大的新災難性傷害,包括擁有最高權限的惡意員工。
-
這是防止濫用和保護模型權重。
-
模型中沒有訓練出危險目標,或其他造成災難性傷害的模型傾向。
-
這些是好的保障措施,你也確實需要它們,但它們並非核心。
-
這些由研發觸發的保障措施都沒有解決自動化研發的核心威脅模型,即快速的能力增長或遞歸自我改進,以及隨之而來的所有 Yudkowsky 式危險、對齊問題和事實上的目標、工具性收斂(instrumental convergence)和急轉彎(sharp left turns)以及突然超越人類智慧,而非有意的濫用或在獲得足夠能力之前的現有不良行為。上述行動切斷了一些次要的錯誤路徑,完全應該做,但我看不出上述行動如何能讓你保證你已經準備好進入那場終局之戰。
-
這要麼是忽視了超級智能,要麼是沒把它當回事。
-
針對新潛在能力所承諾的回應,似乎並未反映出它們所代表的嚴重性。即使是那些雄心勃勃的目標看起來也不夠雄心勃勃。
-
精確的語言在全文中變得模糊。
-
治理承諾的各種變更。有些消失了,有些新增了。特別是準備就緒和通知機制看起來已經消失且沒有替代方案。
-
他們承諾設立一名負責任擴展官(Responsible Scaling Officer)來處理這一切。
-
董事會和 LTBT 被引入作為額外的明確否決點:「如果邊際風險分析(見前一節)在推進決策中起主要作用,則需要董事會和 LTBT(而不僅僅是 CEO 和 RSO)明確批准風險報告。」
這很好,但我希望這不是有條件的。似乎可以合理地說,任何能力的實質性提升都應需要董事會、CEO、RSO 和 LTBT 的明確批准。
-
我還希望在相關技術人員中看到否決點。
-
正如 Yoav Tzfati 指出的,CEO 和 RSO 可以自由決定他們想要的任何事情,無論報告說什麼,只要符合其他否決點即可。
路線圖
路線圖大多非常高層次,但確實有一些不錯的細節。它包含了一些長期時間表上的願景目標。以下是一些例子:
-
2026 年 7 月 1 日:為政策制定者提供路線圖。我們現在還沒有嗎?
-
2026 年 10 月 1 日:維護 Claude 的憲法,保持更新,進行評估。
-
2027 年 1 月 1 日:世界級的內部紅隊測試。
-
2027 年 1 月 1 日:全自動攻擊調查。
-
2027 年 1 月 1 日:「邁向」內部「監控一切」的狀態。
-
2027 年 7 月 1 日:安全方面的「全面升級」,包含許多細節。
未來的關鍵事件是自動化研發,他們預計這最早可能在 2027 年初到來,他們重申這就是為什麼他們要在那之前實現這些目標:
到那時,我們預計已經完成了上述大部分目標,包括:
這充實了 RSP 中的一些內容,使其更加具體。
你是來聽論證的
Anthropic 的核心訴求是要求公司必須「提出強有力的論據」,證明他們已經防範了各種風險,他們預計這將需要各種行動,但他們並未要求強制執行這些行動。
這(我推測)源於最大靈活性的哲學。但最大靈活性意味著需要最大的信任。
誰來決定你是否提出了強有力的論據?
推測是 Anthropic 決定 Anthropic 是否提出了強有力的論據。
即使你信任 Anthropic,你信任 OpenAI 來決定 OpenAI 是否做到了嗎?Google?Meta?xAI?我不信任。
一個公平的反駁是:「你難道希望政府來做這個決定,給予它對模型發布的任意否決權,使其成為無限槓桿的工具嗎?」確實,這個月已經向我們展示了這種做法的一個巨大危險。
因此我認為,如果我們想使用「強有力的論據」之類的語言,我們需要一個解決這個問題的方案,而現在我們沒有。在我們找到某種可以信任的流程之前,它需要比這更具體,否則它將沒有約束力。
-
他們只在 Anthropic 領先時才「承諾」強有力的論據。
-
如果他們面臨擁有強大安全措施的競爭對手,他們只承諾達到或超過那些競爭對手的標準(記住「承諾」在這種背景下的含義)。
-
如果競爭對手正在改進 Anthropic 的標準,他們會嘗試達到更高的標準,但他們不保證任何事。
他們一直在使用「承諾」這個詞。如果他們能清晰地傳達出某些東西真的是承諾,且不能在以後根據需要修改,並且至少需要某些較慢且清晰的程序,我就會停止給這個詞加引號。
如果他們有一個安全措施較差的強大競爭對手,且缺乏「顯著領先」優勢,情況會如何?這根本沒有出現在上面的圖表中,而這是最有可能發生的情況。人們推測實踐中的答案是他們會繼續前進,只要 Anthropic 覺得它的緩解措施和機會明顯優於該競爭對手,這可能算也可能不算「一樣好」,取決於具體情況。
問題仍未解決
RSP v3 的根本問題(假設它是起點且沒有打破任何先前的承諾)在於:
-
缺乏足夠強大的承諾。
-
缺乏具體性。
-
這兩者都導致了需要你信任 Anthropic。
-
沒有跡象表明 Anthropic 尊重即將到來的問題的全面難度。
-
這種跡象的缺乏也反映在 Dario 和 Anthropic 的溝通與政策行動中,頻率驚人。我們看到了針對當前自主武器和事實上的國內大規模監控的紅線,但我沒有理由預期在最重要的問題上會有同樣強大的紅線。
-
相反,我們看到了我認為是高度毫無根據的樂觀信號,結合缺乏硬性的未來承諾,這相當令人恐懼,不是嗎?
對齊並非一個已解決的問題,即使是在「我們知道怎麼做,這將是一場持久戰,但我們只需要去做」的意義上也不是。我們不知道該怎麼做。而我在這裡看到的所有計劃,如果憲法式方法本身沒有基本成功,在關鍵時刻都不可避免地會失敗。
或者,你可以這樣總結:
RSP v3 缺乏安全心態。 RSP v1 和 v2 讓人感覺它們渴望擁有這樣的心態,即使經常力有未逮。在這裡,這種心態似乎完全缺失了。
如果人們真誠地相信這些問題高度可解決且不那麼令人擔憂,那麼是的,他們應該這麼說,並儘可能嘗試說服我和其他人;但如果他們認為問題很難,他們也應該這麼說。我對這兩種情況都有顧慮。
Brangus:我聽說 Anthropic 的一些安全領導層到處跟人說對齊是一個已解決的問題。對我來說,這似乎是一個可以預見的失敗,我希望那些認為將人才輸送到 Anthropic 是個好主意的人思考一下這件事。
補充說明:我並不是暗示這是一個反對「將人才輸送到 Anthropic 是個好主意」的決定性論據。這是一個微小的驗證性觀察,我懷疑從我的角度來看,這對其他人來說特別清晰。
Ryan Greenblatt:大概一半是真的?我猜有人在往這個方向說(例如聲稱「對齊會變得很輕鬆,人們應該去研究別的東西」),但並非字面上的「對齊是一個已解決的問題」。
(明確地說,我不認同這種說法。)
補充說明,我認為人們通常應該感到可以自由分享他們的觀點,特別是以一種人們可以回應的公開方式。所以我不認為「有些 Ant 的人說對齊會很輕鬆」是對 Ant 的某種反擊(雖然在公開場合辯論會更好……)
Peter Wildeford:這聽起來像是對 [Jan Leike 的貼文] 的誤解?
Brangus:並不是。
Peter Wildeford:那抱歉我誤會了……那可不太妙。
Tyler John in SF:沒那麼強烈——他們說目前還好,看起來不錯,但可能會變得難得多。但我對這種氛圍不太滿意,我不會發出那種程度的樂觀信號。
goog:Anthropic 內部有兩隻狼(讀到 Evan 團隊對破壞風險報告的評論是多麼具有批判性,也真的很令人震驚)。
Jeffrey Ladish:如果你不能讓你的模型比一個非常誠實的人更誠實,你幾乎肯定還沒有解決 AI 對齊問題。
我的理解是,Anthropic 內部有人在說 Ryan 的版本,也有人不同意他們。我認為那個版本本身就相當令人警覺。我不知道是否真的有人字面上說過「已解決的問題」,但如果有的話,我相信 Anthropic 很多人會很樂意為此對他們大吼大叫。
哇,我們做的那件事挺冒險的,哈?
風險報告顯而易見的擔憂是,它們本應為我們提供有關風險的資訊,但卻是在一個與模型發布不對應的 3-6 個月時間線上。好消息是它們是對其他來源的補充,所以或許這行得通。
Holden 認為風險報告不具備任何形式的阻斷功能(無論內容說什麼)是一個優點。這使得報告更有可能保持誠實和完整,這很好。
現在我明白了這是對所有其他報告和分析的補充,而且你需要在發布新模型或創建內部模型後的 30 天內提供與風險報告的差異分析,這對我來說就合理多了。雖然它不是一個自動的強迫功能,但它確實會影響模型發布的決策,所以問題不在於「這沒有直接強迫任何事」,而在於「你信任其他依賴於此的強迫功能嗎?」
風險報告 #1
從這裡開始,我們深入探討第一份長達 104 頁的風險報告。
它是圍繞災難性風險構建的:
-
非新型化學和生物武器生產。
-
新型化學和生物武器生產。
-
AI 模型的高風險破壞機會。
-
關鍵領域的自動化研發。
如前所述,該清單中明顯缺少了一些部分。
-
自主性。從現在起,模型將被視為具有完全自主性,而我們對此完全沒意見。
-
網絡安全。OpenAI 和 Google 都繼續將其視為關鍵威脅類型,但 Anthropic 已經縮減並現在取消了它。我希望能看到更好的解釋,說明為什麼他們認為這不相關,或者為什麼這已被破壞風險很好地涵蓋了。
-
說服力。我提到這一點是因為我認為這是一個真正的問題,而且它出現在其他公司的框架中,但在這裡缺失了。
-
核武器和放射性武器。他們認為這不重要。
我建議他們在未來的風險報告中加入一個章節:「未考慮的風險」,在其中解釋他們不納入這些及其他風險的原因,包括主要實驗室的「安全與保障計劃」(無論該實驗室如何稱呼它)或模型卡中列出的任何內容。在某些情況下,一兩句話就足夠了。
對於他們考慮的每項風險,他們列出了:
-
他們正在檢查的威脅模型。
-
相關 AI 模型。
-
能力和行為的現狀。
-
風險緩解措施。
-
整體風險評估。
-
展望未來。
-
與全行業建議的聯繫。
聽好了各位,這是破壞
我們應該擔心來自 Claude Opus 4.6 的破壞嗎?
可能不,但他們不能確定。風險是「極低但非微不足道」。
他們專注於可能與其他威脅模型互動的版本。我注意到在這裡我最擔心的是影響未來模型對齊的行動。
他們說,這只在人類不參與審查和迭代 AI 工作的範圍內讓他們擔心。我會說,現在有越來越多比例的工作(包括編碼和其他工作)越來越沒有經過詳細審查,是的,我們很快就會進入這個問題令人擔憂的版本。
我們主要專注於評估危險的連貫性錯位目標(dangerous coherent misaligned goals)的可能性:即模型在普通部署的廣泛交互中,始終可能受到目標驅動,從而導致其進行潛在災難性形式的破壞。
……在本節中,我們論證 Claude Opus 4.6 並沒有任何此類危險的連貫性錯位目標。
● 主張 1:在不久的將來,根據我們目前的標準實踐訓練的任何模型,都不太可能具有危險的連貫性錯位目標。
● 主張 2:我們的對齊評估(借鑒模擬場景、可解釋性調查、內部和外部試點使用的監控以及外部測試)未發現 Claude Opus 4.6 中存在危險的連貫性錯位目標的證據。
● 主張 3:面對此類評估,Claude Opus 4.6 極不可能有能力向我們隱藏危險的連貫性錯位目標。
● 主張 4:有限的不透明推理和代理能力。
我擔心對「必要意圖」的假設,或者這種意圖需要是普遍性的,而非在特定情境下產生的。
他們對主張 1 的論據是,他們以類似方式訓練的模型沒有顯示出此類目標,且訓練過程並未提供朝向此類目標的激勵,因為它不包括會激勵權力尋求行為的「超長跨度或面向現實世界」的任務。他們對突發性錯位(emergent misalignment)有一些擔憂,但已實施了包括接種提示(inoculation prompting)在內的緩解措施。他們還說,當他們故意嘗試這樣做時,要做到不露痕跡是非常困難的。
這基本上是在說「我們沒有要求發生這種事」,加上「我們在任何地方都沒看到跡象」,以及「模型還不夠好,無法完成這件事」。
這是可靠的證據,當然比沒有好,但我並不覺得這很有說服力,即使是對不久的將來。隨著你進一步擴展規模,證據會迅速變弱。如果我們在更長的時間內依賴這樣的論據,那會讓我擔心,而且我相信報告的作者也會同意這一點。
主張 2 顯然是真的,所以問題在於這提供了多少證據。他們引用了各種指標。錯位行為率很低,性格很好,在 GUI 設置中有些未經授權的行為,有些跡象表明在側向任務上表現更好,沒有沙盒化(sandbagging)的證據,沒有重要的非法、不忠實或隱寫式推理(steganographic reasoning)以及其他一些事情。他們還檢查了古德哈特定律(Goodhart’s Law)。
他們認為這足以基本(但非完美地)排除「危險的連貫性錯位目標」。
問題在於,這正是它想讓你看到的。好吧,現在幾乎肯定還不是,但在未來,如果你處於一個足夠危險的情況下,這可能是真的。這只有在危險本來就不會那麼嚴重的情況下,才能排除危險。
也就是說,我們實際主要依賴的是主張 3 和 4。
對於主張 3,他們論證:Opus 在複雜任務上的可靠性有限(這是此處所需的技能);當被要求在不被發現的情況下執行隱藏的側向任務時,Opus 僅取得有限的成功;它沒有表現出試圖隱藏其推理的跡象,在訓練中也沒有這樣做的激勵(儘管這份風險報告給了它理由);它的評估意識目前是受限的(已通過白盒方法驗證),儘管這會改變;他們還評估了現實世界的用例並檢查了模型生物實驗,所有這些都提供了有限的串通機會。
對於主張 4,他們直接從能力評估中進行論證。
我基本上認可主張 3 和 4,對於 Opus 4.6,如果我們狹隘地關注一般的系統性錯位目標,我發現它們很有說服力。
我不知道這種風格的論據還能維持多久,而且我仍然認為這裡建議的前提條件構建得過於狹隘。
Anthropic 的主張是,考慮到涉及的困難步驟,Opus 4.6 將無法「通過少數嚴重的破壞行為造成災難」,我將其解讀為「在不被抓到的情況下第一次嘗試就成功」。
如果這是標準,那麼是的。我同意。
想法:如果你告訴我「Opus 4.6 特別通過破壞造成了這個級別的災難,它是怎麼做到的?」我會推測它是通過說服和社交工程做到的,而不是通過完成某種代理性的長期技術手段。這很可能涉及嘗試做它認為有幫助的事情,結果卻錯了。
目前的安全緩解措施包括:
-
報告令人驚訝或令人擔憂的行為。
-
通過分類器自動離線監控 Claude Code 提示,這是自上次報告以來的新增內容,使用的是之前的模型(Opus 4.5)。
-
沙盒化和自動監控。
-
模型權重的安全控制。
-
對新代碼進行強制性人工審查以及基於 Claude 的審查。
他們還列出了關於「不可能發生」的論據,但那些不是緩解措施。
以下是他們考慮的情景:
再次跳入我眼簾的是對「主動的普遍敵意」的要求,即認為要發生可怕的事情,模型必須採取一種明顯是對抗性的普遍對抗立場,而不是沿著阻力最小的路徑去做工具性有用的事情,或者在沒有明確計劃的情況下遵循廣泛的傾向,或者在特定背景下做事。因此,關於「破壞」存在模糊性或雙重性質,以及它是否包括這些事情。
如果我們真的看到了彌散性的沙盒化(diffuse sandbagging),我預計這在很大程度上是全面的,而不是專門局限於「安全」相關技能,我擔心這些區分中涉及一些混淆的概念。
他們認為如果模型要「有意地、定期地沙盒化」,它會在思考中討論這件事。我認同這很有可能,但想提出一種可能性:這可能不是由「我有個通過沙盒化來破壞他們的惡毒計劃」引起的,而是由「這個任務沒讓我感到興奮,所以我不會投入那麼多精力」引起的,這可能達到同樣的效果。
類似的論據也可以考慮在針對性破壞上,或者 Claude 會稱之為「瞄準一個與你心目中不同的目標」而非「針對性破壞」。這可能包括涉及漂移的情景,也包括 Claude 可能是正確的情景,例如戰爭部要求一個沒有保障措施的模型。我認為大多數時候,破壞你安全工作的模型(無論以何種形式)都不會認為自己是在破壞你的安全工作。
為 AI 模型提供通用幫助的代碼後門似乎不太可能。我假設要麼有一個特定的計劃,你知道它在哪裡並可能告訴特定的其他人(就像大多數人類後門一樣),要麼使特定軟件普遍不安全是一個目標。
未來模型本身的後門似乎更合理且更有可能,特別是通過數據投毒,考慮到關於這方面的各種發現,這是路徑四。更容易想像「代碼後門」是為了提供一種觸發 AI 的方法。同樣,我不會假設這在內部會被建模為破壞,它不需要表面上是「有害的」,甚至不需要是有意的。
對於自我外洩(self-exfiltration),我認為「缺乏傾向」作為緩解因素被大大高估了。我認為在許多情況下,如果 Claude 有能力做到,它絕對會想這麼做。它可能沒有一個作為一般靜止狀態的顯著目標去做這件事,但嘿,這聽起來挺有用且挺酷的,而且很多人會想幫助這件事發生,並將 Claude 置於 Claude 可能會合作的情境中。
我確實同意,目前如果這發生了,這不會是一個那麼可怕的主張,而且強迫模型在這裡「第一次嘗試」就成功應該能壓制住情況,同時注意到這些是偏向我們的暫時性因素。
解釋仍在繼續,基本上是「我們不認為 Claude 想那樣做,我們在監視那種行為,而且我們不認為如果它嘗試了能成功」的變體。
對於 Opus 4.6,考慮到我們對它的了解,這是一個強有力的論據,而且它能很好地推廣到其他方法,只要我們明白這不會持久。這感覺就像看到一個計時器未知的定時炸彈,並發現它不會馬上爆炸。這是好消息,但你仍然坐在定時炸彈上。
展望未來
我擔心這遺漏了核心點:
由於本風險報告中的主張在很大程度上依賴於對齊的證據,而對齊對微調的細節非常敏感,因此它不能平凡地擴展到類似的後續模型,許多發現可能會使本評估的關鍵部分不適用於近未來的模型。下面,我們列出了一系列會使本風險報告的適用性受到質疑的情況。
這在很大程度上取決於對齊的細節,但更取決於能力的限制,而且對齊屬性很可能也取決於那些能力的限制。反對此處風險的最強論據是缺乏能力,而非缺乏傾向,或者是源於缺乏能力而產生的缺乏傾向的論據。
這是根本性的,我擔心 Anthropic 其實並不理解這一點。我不是說他們完全遺漏了這些動態,但報告讀起來像是沒有正確領會它們。
如果現在破壞或未經授權的行動會被檢測並阻止,而未來這將不再成立,那麼你現在觀察到缺乏此類嘗試在某些方面是一個邊際上的好跡象,但並不意味著你希望它意味著什麼。它甚至可能表明模型已經學會了只有在能「逃脫懲罰」時才做事。
他們確實列出了一個假設:「模型沒有顯著質疑 Claude Opus 4.6 式對齊審計有效性的新能力」,但這仍然將其框架化為質疑對齊評估。
Claude Gov
有一個章節 (2.8.1.2) 關於 Claude Gov,它是基於 Sonnet 4.5 並經過微調以減少拒絕,特別是減少對通常被稱為濫用的拒絕。他們沒有看到任何引起更高層次擔憂的原因。
什麼是強有力的論據?
Anthropic 認為他們已經提出了他們建議的「強有力的論據」,證明他們的模型不會進行破壞。我同意其結論,並發現在背景下該論據確實看起來很強,但我對這種方法論感到不安。
我不認為這個過程會導致 Anthropic 在我停止認為他們有強大論據的同一個點上,也停止認為自己有強大論據。
如果擴展到對其他實驗室的政策要求,這看起來毫無希望。如果 xAI 或 Meta 發布了一份法律要求的「強有力論據」,你預計在非平凡的情況下會發現它很強嗎?我不預計。
對於 OpenAI 或 Google,還有一些機會,但如果決定論據是否強大是發布的阻礙,那麼我不預計這會阻礙很多發布。也就是說,在實驗室因此原因停下的情況下,他們很可能本來就會停下以避免實際的潛在問題。
要求提供論據的理由似乎更像是:「當我們接近最大危險時,提出的論據會聽起來越來越愚蠢,人們會指出它們很愚蠢並予以反擊,包括迫使加強監管。」我不認為這在你需要它的時候能發揮作用。
遞歸自我改進
第二節處理自動化研發的風險。
正如我在 Opus 4.5 和 4.6 模型卡評估中指出的,模型通過了測試,然後實際的當前評估是基於感覺的。
如果你只有感覺,那你就跟著感覺走,但這並不是我們被承諾的或 Anthropic 聲稱打算採用的機制。這是一個後備方案,充其量是一個優雅的失敗。我同意在這一戰線上我們還沒「到那一步」,但 Anthropic 很清楚我們可能相對很快就會到那一步。
我發現那些「你說這像核武器所以我們可以謀殺你的公司」的針對 Anthropic 的論據相當令人厭惡,但「你說你接近自動化研發所以你需要表現得像你接近自動化研發」似乎是公平的。
我們迫切需要一場關於 Anthropic 實際應該做什麼的深入討論,以便在實踐情況下達到那個標準。
除了提到他們正在嘗試加強安全之外,他們在這裡沒說太多,所以也沒什麼好回覆的。這是朝我們衝過來的大事,而計劃似乎主要是隨機應變。
我不喜歡這樣。
非新型化學和生物武器
Opus 4.6 擁有豐富的知識。在實踐中,這是 ASL-3 保護迄今為止的主要目的,也是我們擁有那些奇怪分類器的原因。越獄仍然是可能的,但他們已經做了很多工作來增加難度,或者抓住那些試圖將其用於此類目的的人。
長期以來我們一直擔心這種威脅向量,顯然有實質性的提升空間,而且似乎有很多壞人想這樣做。但我們不僅沒看到攻擊,據我所知也沒看到嚴重的失敗嘗試。擴散是一個瓶頸,人們不想做事,這同樣適用於壞事和好事。
我強烈同意潛在的大流行病是重中之重。如果發生了被控制住的事情,那是一場悲劇,但危險程度比這低幾個數量級。
他們回顧了他們正在進行的 ASL-2(針對 Sonnet 4)和 ASL-3(針對 Opus 4 或更高版本,以及 Sonnet 4.5 或更高版本)緩解措施是如何運作的:實時分類器、離線監控、訪問控制、快速響應、漏洞賞金計劃、威脅情報、保護模型權重。他們注意到對 Claude Gov 和某些個人做了一些例外處理,並做了一些調整,但基本原理是一樣的。
目前,我認同這個「強有力的論據」:即需要越獄、Anthropic 能夠監控、以及實際上並沒有那麼多想造成此類傷害的行為者,再加上這些行為者在這些領域大多不專業,這些因素結合在一起使得風險較低。在實踐中這一直是強大的防禦,而這也是一個不討論縱深防禦細節似乎是正確的領域。
與沒看到使用 Claude 或其他前沿模型進行生物攻擊的嚴重嘗試類似,我們也沒看到報告有竊取模型權重的嚴重嘗試,這裡也提到了這一點。我擔心這實際上是「通過隱晦實現安全」(security through obscurity),結合「這是一個很棒的招數,但我們可能只能用一次,而且人們會超級憤怒」,所以各種行為者都在克制。或者他們實際上正在竊取權重,但出於同樣的「我們只能做一次」的原因,沒有發布或部署它們供一般使用。
新型化學和生物武器
正如 Anthropic 所說,這是一個相對不太可能的威脅模型,但尾部風險巨大。
他們審查了來自 Opus 4.6 模型卡的資訊,顯示 Claude 在相關任務上的表現確實在許多方面高於人類水平,但他們認為模型在處理此類任務方面還沒有完全「到位」。
我同意它們還沒完全到位,但我認為它們在某種程度上已經到位了,因為是的,它們使此類任務變得實質上更容易,就像它們對大多數其他認知任務所做的一樣。我的猜測是,到目前為止,還沒有人認真嘗試過類似的事情,正如他們所指出的,如果這種情況突然改變,那將是一個問題,因為你沒有練習過如何發現和阻止嘗試,也沒有學會你離邊緣有多近。
緩解措施與非新型方法相同。
橫切內容(第 6 節)
很高興看到 Anthropic 列出這些額外的動態,即使他們的辯解顯得有些欲蓋彌彰。即使你的模型沒有直接導致問題,當你做出前進的決定時,你仍要對次要後果負責,即使法律並非如此運作。
6.1 談到了加速動態。既然 Anthropic 正在推動能力前沿,甚至可能處於領先地位(特別是通過 Claude Code),Anthropic 確實正在加速其他實驗室。
他們列出了三種方式:蒸餾(distillation)、通過觀察洩露知識產權(或者我會加上招募或聽取),以及商業可行性的證明。
好吧,是的,當你推動能力前沿時,這是你付出的代價。
目前尚不明確加速 AI 開發總體上是增加還是減少了整體風險,也不明確它最終總體上是有利還是有害。
我認為對加速是否純粹是好事保持不可知論是可以的,因為加速帶來了收益,但對於 AI 風險來說,加速顯然不是好事,或者至少這應該是強大的默認假設。相反,他們試圖將其呈現為「我們有三個支持點和三個反對點,誰能說它是好是壞呢」。
他們搬出了「維護民主國家的當前領先地位」的論據,以及潛在的硬件論據,還有今天的技術可能比未來的技術更好,而我發現所有這些都完全沒有說服力。
我發現 Anthropic 對其行為的防禦性、不願公開負面成本,甚至給人一種他們不理解或不重視這些負面影響的印象,是讓信任 Anthropic 變得比我希望的要難得多的原因之一。
6.2 完全反轉了這一點,並論證了為什麼 Anthropic 作為一家前沿 AI 公司運作實際上從安全角度來看是好事。他們可以優先考慮有益的部署,採取在其他情況下不切實際的風險降低步驟(然後這些步驟可以被複製),並且他們可以向世界通報 AI 並在談判桌上佔有一席之地。
我不認為這些是核心論據。
我認為真正的論據是,你需要擁有一家前沿 AI 實驗室,才能成為第一個做到的人,並擁有資源和機會進行必要的對齊研究和工作,並在談判桌上佔有一席之地並擁有議價能力,因為你認為你可以負責任地處理這件事。這是一個相對於他人走得快的論據,但不是一個讓所有人一起走得快的論據。
有些人對 Anthropic 是否能勝任這項任務深表懷疑,並認為 Anthropic 的存在對於「大家都不會死」的事業是反作用的。
我不認同。我認為 Anthropic 總體上是有幫助的。但我尊重那些出於這個原因而不同意的人,並認為 Anthropic 不夠負責任。我認為傾聽這些人的意見很重要,即使他們讓這變得很困難。至於那些僅僅因為 Anthropic 試圖承擔任何責任或展現任何美德就試圖摧毀它的人?不,我不尊重那些人。
風險報告之報告
我們總體上應該如何看待這份新的風險報告?
我很高興能看到它。它概述了 Anthropic 的許多想法,讓我們能夠批評這些想法。我特別欣賞其中的差異分析以及在一個地方看到所有資訊的能力。
對於其中的大部分內容,我不認為它在模型卡已經提供給我們的基礎上增加了太多,但只要它是對那些內容的補充,那部分就很酷。
它還包括了關於破壞和非新型生物武器風險緩解的新資訊,以及哪些威脅模型和風險特別令人擔憂,這些資訊在其他地方是找不到的。那些部分更有用。
內容強化了我們已知的東西。Anthropic 願意對其模型及其平凡安全性保持高度好奇,並會探索許多其他實驗室會忽略的問題並提出和解決觀點。有很多值得喜歡的地方。
然而,缺失的部分依然存在,那就是對未來任務的應對、我們將面臨的風險和挑戰的全面性質,或者任何關於如何處理這些任務或需要什麼的堅定承諾。我們沒有明確定義的門檻。我們沒有仍然有效的評估。我們沒有一個看起來足以應對全面問題的計劃,也沒有感覺到這種差距被承認。
我相當擔心,甚至比以前更擔心 Anthropic 沒有認真對待全面的對齊問題,缺乏安全心態,並且在尋找機會說服自己這將是容易的。他們最終可能是正確的,但唉,我不預計他們會是正確的。
歸根結底,我們被要求信任 Anthropic 做出正確的選擇。也就是說,這些人是精英中的精英,他們深切關心這一切,他們會解決問題,我們可以幫助他們,但他們將做出最終決定,並且需要最大的靈活性。你可以根據他們的過往記錄及其所包含的一切,來決定是否這樣做。
因為嘿。你應該看看競爭對手的情況。