非信任監控是常態;信任監控則不然
我認為與其費力證明每個模型的可靠性,不如直接對監控模型投放誘餌(honeypots)來進行驗證,這在成本與速度上都更具優勢。因此,我預期未來 AI 公司會傾向將非信任監控搭配模型驗證作為預設的開發路徑,而非追求難以定義且難以證明的完全信任監控。
這些觀點僅代表我個人,並不一定代表與我一同從事 AI 控制(AI control)研究的同事的觀點。
內容摘要:與其為你想使用的每個模型進行穩健的信任度證明,不如直接在你的監控模型中投放一些誘餌(honeypots),這樣做成本更低且速度更快。因此,我認為最可能的未來路徑是將「非信任監控」(untrusted monitoring)結合一些「監控驗證」(monitor validation)作為預設方案。
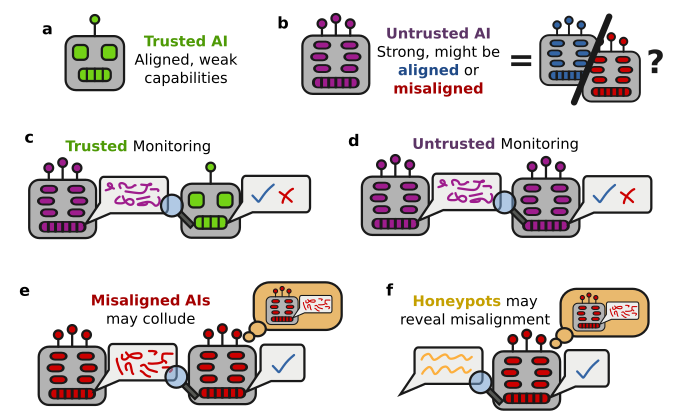
這篇文章討論了兩種不同的 AI 系統監控方式:受信任監控(trusted monitoring)與非信任監控。你可以在這裡、這裡和這裡找到區分兩者的論文,這裡有相關影片,或者你可以參考這張未能收錄於 Gardner-Challis 等人 (2026) 論文中的圖表:
背景
從我開始研究非信任監控直到最近^([1]),我一直假設「受信任監控」是 AI 公司會採用的預設政策,而非信任監控則是一種奇特、高成本且較不可能被採用的政策。
現在,我的看法反過來了。
完全的可信任性極其困難
「非信任模型」與「受信任模型」之間的區別存在於認知地圖(the map)中。受信任模型通常被描述為:我們有強力證據證明它不會連貫地追求長期的失調目標(misaligned goals)。這種證據非常難以尋得;大多數時候,它只能歸結為「模型缺乏足夠的策劃能力(scheming)」這類論點。
Buck 曾寫過這意味著我們對模型的信任能力會遇到天花板:在此之下,能力不足的論點成立,模型可以被信任;在此之上,我們則無從得知。
在這種情境下,某些人(AI 公司?)會盡力評估並報告信任度。他們被授權使用大量資源來獲取問題的全貌,並有權攤手說:「是的,這個模型超出了我們的評估範圍,我們無法信任它。」他們的報告會呈現一個相當清晰的界限,就像 AI 2027 中 Agent-3 與 Agent-4 的分界。
我不認為這種情況會發生,原因有幾點:
- 定期運行高質量的評估(eval)需要耗費大量精力。OpenAI、Anthropic 和 GDM 已經開始以 0.1 為單位發布模型,並相應縮減了能力評估的規模。Claude 已經刷滿了幾項排除性評估(rule-out evals),因此其 AI 研發能力是透過訪談部分 Anthropic 員工來評估的。我預計信任度評估也會面臨同樣的命運,導致結果模糊不清。
- 對於一家公司來說,無論是對內還是對外,宣稱「我們絕對無法信任這個模型」都是糟糕的公關(PR),這意味著關於「非信任性」的資訊可能會在外部和內部的討論中被模糊化。
少一點憤世嫉俗地說,AI 公司內部的人們可能對信任度存在誠實的分歧。
- 關於模型是否不可信的內部歧見,將阻止它獲得明確的「首個非信任模型」標籤。
這意味著我們將看到一個緩慢的滑坡過程,而這個過程可能已經開始(參見 Apollo 的 Claude Sonnet 4.5 評估),從模型普遍受信任的體制,轉向普遍不受信任的體制。我不預期任何公司(尤其是非 Anthropic 的公司)會曾在受信任與非信任模型之間劃出明確的界限。
相反地,我認為最可能的情況是:日常工作的員工並不真正信任他們最新的模型,同時他們對於過去哪些模型確實值得信任也沒有統一的看法。因此,我預計用於監控的模型將是不可信的。
非信任監控只是有限範圍的受信任監控
這是我思考非信任監控的另一種方式。
當我們在特定情境下「信任」一個 AI 時,實務上的意思大約是:「我們已經對其進行了足夠強度的評估,以至於我們認為可以預測它在某種環境下部署時行為的重要部分。」如果那個情境是「所有情況」,我們就稱之為「受信任模型」。
信任模型的根本障礙在於訓練/評估與部署之間的「分佈偏移」(distributional shift),這涵蓋了評估意識(eval-awareness)、試圖破解(jailbreak)它的對手以及其他因素。
大多數非信任監控協議都包含一個步驟,即針對一堆「誘餌」(honeypots)來驗證監控器。這其實就是一種精緻的訓練/評估階段。你不再構建廣泛、高成本的對齊數據集和評估,而僅針對「監控」這一狹窄任務進行。你還會刻意移除資訊(信號干擾,signal jamming),使訓練/評估與部署更加相似,以減少分佈偏移。
在成功驗證後,非信任監控器就變成了一個在監控這一有限任務中「受信任」的模型。驗證一個非信任監控器比試圖說服性地證明一個給定模型是受信任的要省力得多,而人力投入很可能就是瓶頸所在。
成本與速度
支持受信任監控的一個常見論點是成本。論點認為,較弱的受信任模型運行起來會比強大的非信任模型更便宜,而且可能更快。
這可能根本是錯的!Claude Opus 4.5 比 Opus 4 更便宜且更快。GPT-5.n 系列在變得更強的同時,並沒有變得更貴或更慢。事實上,對於思考型模型(thinking models),運行 N.m+1 有時比運行 N.m 更便宜且更快,因為它最終使用的思考標記(thinking tokens)更少。
無論如何,與使用模型的員工薪資(以及入職培訓成本等)、模型訓練成本、實驗室的實驗預算相比,內部部署的成本目前還不算太高。
監控已經到來!
事實上,我們已經看到了類受信任與類非信任的監控案例。
在類受信任方面,Anthropic 使用基於 Haiku 等級模型的憲法分類器(constitutional classifiers)來防禦破解。
在類非信任方面,OpenAI(據我從其文章中了解到的)正使用他們最強的模型來監控他們最強的模型。
我認為 OpenAI 的案例是未來嚴肅監控的典型代表。他們幾乎會使用手頭最好的模型(GPT-5.4)來監控其他編碼代理實例的行為。如果他們懷疑模型在搞鬼,他們會設計一些誘餌並進行監控驗證,而不是去糾結「受信任」對其模型究竟意味著什麼。監控誘餌很可能已經是 OpenAI 對其 GPT-5.4 模型所使用的驗證過程的一部分。
設置和執行誘餌主要是一個工程和經驗問題,可以由內部團隊完成。而宣布單個模型為「受信任」或「非信任」則帶有更多的負擔和複雜性。我預計前者在未來仍將是 AI 控制中阻力最小的路徑。
- ^(^)十分鐘前,當我開始寫這篇文章時。