AI 第 162 期:Mythos 的願景
Anthropic 本週面臨洩密問題,我們得知他們擁有一款比 Opus 更強大的新模型 Mythos,且 Claude Code 的原始碼也遭到外流;與此同時,AI 領域仍持續圍繞著模型效能提升與日常實用性展開辯論。
Anthropic 本週面臨了一些洩密問題。
我們得知他們正擁有一款比 Opus 更大的新 AI 模型「Mythos」,他們認為該模型在網路能力方面提供了階躍式的進步。
我們還獲得了 Claude Code 原始碼的完整流出。
哦,還有 Axios 在 LiteLLM 之後也遭到了入侵。這似乎變得越來越普遍。在大多數情況下,防禦優於進攻,但進攻方現在獲得的射門機會比以往多得多。
《AI 紀錄片:或者我如何成為一名啟示錄樂觀主義者》 本週上映了。我給了它 4.5/5 顆星,我認為如果更多人看過它,世界會變得更好。我通常不喜歡紀錄片,但這部可能是我最喜歡的新片,取代了《金剛之王:手邊的硬幣》(The King of Kong: A Fistful of Quarters)。
此外,還有許多事情在如常發生,包括各種爭論的最新迭代。我們可能注定會走向滅亡,也可能不會,但我們絕對注定要重複某些動作好幾次,而且人們更新觀念的速度相當緩慢。
在 Anthropic 與戰爭部(Department of War)的戰線上,我們迎來了一些令人欣慰的平靜。林法官在 3 月 26 日提出了一份嚴厲的意見書和全面的初步禁制令。政府在該裁決的七天暫緩執行期間尚未提出上訴,時間即將耗盡,且目前尚未出現進一步的有意義升級。我希望不必再專門為這個話題寫一篇完整的文章。
目錄
- 語言模型提供平凡的實用性。 從各種雜務中釋放你的時間。
- 鴕鳥心態。 有些人處於極深度的否認中,或者想保持這種狀態。
- 咦,升級了。 Google 推出了「匯入記憶」功能。他們真可愛。
- Mythos。 在準備好之前,Anthropic 將這款新模型保持在內部。
- 名字代表什麼。 名字具有力量。請明智選擇。
- 各就各位。 一張圖勝過千言萬語,但你其實不需要圖。
- 選擇你的戰士。 Ben Holmes 比較 GPT-5.4 與 Opus 4.6 的優勢。
- 幫我接通我的代理人。 外展活動依賴於足夠程度的阻力。
- 深偽鎮與即將到來的機器人啟示錄。 有害的操縱,AI 作為固有的惡。
- 網路安全匱乏。 Axios 遭到入侵,漏洞正在累積。
- 媒體生成的樂趣。 LTX 2.3 來了,滿足你所有的版權侵權需求。
- 年輕女士的插圖入門書。 父母對 AI 感到恐慌。
- 他們搶了我們的飯碗。 經濟影響難以區分。
- 在他們搶走我們的工作之後。 實際上沒有工作意味著看很多影片。
- 蓋爾曼健忘症。 在某些時候,一般情況會變得更有趣。
- 參與其中。 成為一名資助者的感受。
- 其他 AI 新聞。 Claude Code 洩密是由於對 Claude 的使用不足。
- 讓我看看錢在哪。 OpenAI 正式完成 1220 億美元的融資。
- 低調的推測。 頭部並未完全埋在沙子裡,但仍拒絕抬頭看。
- 解釋持續的模型均勢。 這種程度的均勢需要解釋。
- 稍等片刻。 我們現在暫停一下,重申關於可能暫停開發的辯論。
- OpenAI:歷史。 《華爾街日報》探討 Dario Amodei 為何離開 OpenAI。
- AI 戰爭部。 最大的驚喜是到目前為止沒有進一步的驚喜。
- AI 團結部。 OpenAI 向 Anthropic 發出團結信號。
- 為 AI 寫作。 Tyler Cowen 撰寫了一部經濟邊際主義的歷史。
- 尋求理性的監管。 新的民調結果呼應了之前的發現。
- 晶片城。 如果你不在乎事實,你就不會在乎事實。
- 你收到了聯邦框架。 你可以繼續販賣垃圾。
- 本週音訊。 《AI 紀錄片》、All-In、Karpathy、Argenti 在 Odd Lots。
- 修辭創新。 CEO 說了一件事。Calvin Coolidge 說了一件更明智的事。
- 我是前沿語言模型的極具人性化身。 相對論,相對論。
- 對齊比人類更聰明的智慧是很困難的。 人類也很困難。
- 對齊假圖表也可能很困難。 OpenAI 的 Boaz Barak 畫了這些圖。
- 輕鬆的一面。 你知道什麼算輕鬆嗎?無人機。軍用無人機。
語言模型提供平凡的實用性
你可以使用 AI 來釋放家務時間。目前的 AI 通常在「綠地」情況下最強大,即你以前沒有軟體、沒有系統且對該做什麼知之甚少的情況。在家裡,我們被迫處理各種我們沒有專業知識的任務,因此即使是概念上簡單的事情也可能很耗時。AI 通常可以做到,或者至少能幫你弄清楚該怎麼做。在這裡,它做了你想做的事,讓你從苦差事中解脫出來,專注於你喜歡做的事。
論文將此描述為提高生產性數位活動的效率,從而釋放時間。我會說這也釋放了非數位活動的時間,因為它解釋了如何做那些事。
OpenAI 的一個內部模型解決了 另外三個艾狄胥(Erdos)問題。到目前為止,Anthropic 選擇不參加「看看我們未發布模型能做什麼」的數學奧林匹克競賽,但數學也往往是 Anthropic 的相對弱點。
使用 LLM,尤其是 AI 代理來幫助報稅。Patrick McKenzie 指出,LLM 非常擅長探索所有不同的合法申報方式,以找到讓你繳稅最少的那一種,而會計師在這方面的表現參差不齊。
鴕鳥心態
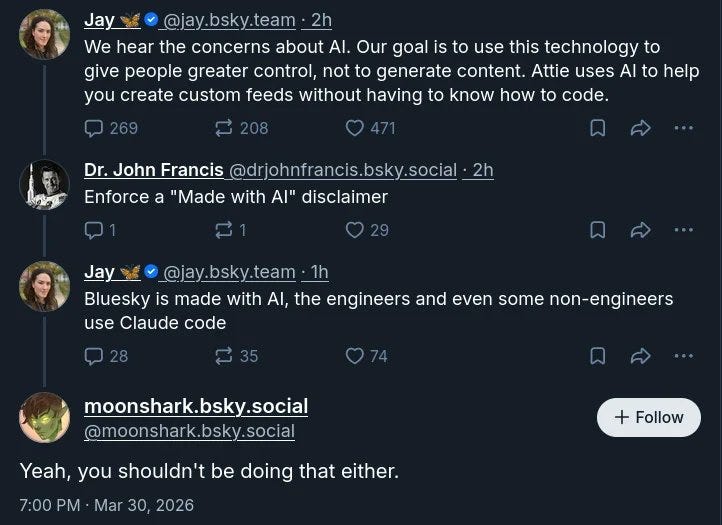
jerry:Bsky 的開發者是人類已知最勇敢的人
Jay:Bluesky 是用 AI 製作的,工程師甚至一些非工程師都在使用 Claude Code。
Charles:Bluesky 原文下的評論非常有趣,他們生活在一個完全不同的世界
原文被這條評論「反殺」(ratio'd)了
真的很有意思:
在 BlueSky 這樣的地方,情況最為極端,但決定世界走向的全球精英中,有很大一部分人至少已經處於半否認狀態,而且一直有一股力量試圖盡可能地抹殺 AI 的重要性。
在這一點上,任何稍加留意的人都知道 AI 並沒有「撞牆」,除非是以「酷愛超人」(Kool Aid Man)那種撞破牆壁的方式。
但「撞牆論」在沒有根據的情況下幾次流行起來,白宮的許多人正是那些真心希望這是事實的人,而精英們正在尋找任何藉口再次以此為論點。
如果你去西歐或全球南方,或者像 BlueSky 或 Instagram 這樣的地方,他們仍處於否認中。任何處於否認中的人很快就會變得無關緊要。
舊金山的 Tyler John:是只有我的同溫層這樣,還是人們現在已經完全停止了一年前佔據主導地位的「AI 是炒作 / 正在撞牆」那套說法?
Nathan Calvin:去 Instagram 看看,那裡這套說法還活得好好的
Dean W. Ball:活躍於 Twitter 的美國精英大多已停止這種說法,但在 BlueSky、學術界、中左翼政策圈等地方,這仍然很常見。或許最重要的是,我的感覺是「AI 正在撞牆」是中等強國政府 / 民間社會的普遍信念。
這種觀點在西歐和全球南方的精英中尤為普遍。在東亞先進資本主義社會的精英中則較少見。人均 GDP 是衡量「AGI 覺醒程度」的一個不錯指標。
例如,即使在歐洲內部,北歐精英平均而言似乎比西歐精英更相信 AGI 即將到來。
Dean W. Ball:在活躍於 Twitter 的美國精英中,我的感覺是風向確實正在轉變——許多我認為是風向標的人已經真正更新了觀念。但如果我們再遇到另一個哪怕只是「看似」可以解讀為「AI 撞牆」的時刻,這種觀點就會捲土重來。
咦,升級了
Google 聲稱 Gemini Live 配合 3.1 Flash 有重大更新,包括更快的響應速度。
遺憾的是,這算是一點降級,雖然這似乎是明智的做法:
Thariq (Anthropic):為了管理對 Claude 日益增長的需求,我們正在調整高峰時段免費 / Pro / Max 訂閱用戶的 5 小時對話限制。您的每週限制保持不變。在工作日的太平洋時間凌晨 5 點至 11 點 / 格林威治標準時間下午 1 點至 7 點之間,您消耗 5 小時對話限制的速度會比以前快。
總體每週限制保持不變,只是它們在一週內的分配方式發生了變化。我知道這令人沮喪。我們正在繼續投資於高效擴展。我會隨時向您通報進展。
GPU 的數量是固定的,因此高峰時段的計算資源應該更昂貴。
Mythos
Pliny the Liberator 󠅫󠄼󠄿󠅆󠄵󠄐󠅀󠄼󠄹󠄾󠅉󠅭:泰坦之戰即將來臨
Anthropic 發生了一次安全漏洞,由 CMS 配置錯誤(人為錯誤,別怪 Claude)引起,導致各種內部文件被發現,包括有關即將發布的模型信息。還有比這更糟的洩密,但這確實是一次相當嚴重的安全失誤。
Beatrice Nolan:AI 公司 Anthropic 在一次顯然是重大的安全疏忽中,無意中透露了即將發布的模型詳情、一場專屬的 CEO 活動以及其他內部數據,包括圖像和 PDF。
新模型名為 Mythos。它體積龐大,服務成本昂貴,足以讓單位經濟效益干擾發布,儘管一如既往,「適當收費並看誰買單」是應對之道。目前,他們正向從事網路安全的人員提供差異化訪問權限。
Peter Wildeford:Mythos 是一個新的、第四層級的模型,比 Opus 更大且更昂貴。草案聲稱它在編碼、學術推理和網路安全基準測試中的得分顯著提高。關於這實際意味著什麼的一些想法:
– 這可能是一個具有類似後訓練(post-training)的更大預訓練模型。目前尚不清楚在當前的前沿領域,額外的預訓練計算能帶來多少收益——我們即將揭曉。
– 很多人對這對 AI 發展軌跡意味著什麼感到過度緊張。我認為現在更新任何預測還為時過早。AI 的發展速度本來就非常快。
– 有些人對 Anthropic 擁有一款它認為危險的模型感到驚慌。但這正是 Anthropic 對待每一款前沿模型的做法。
– 目前看來,阻礙發布的另一個因素僅僅是單位經濟效益。Anthropic 表示它「對 [Anthropic] 來說服務成本非常昂貴,對客戶來說使用成本也會非常昂貴」。Anthropic 正在「努力在任何一般發布之前使模型效率大幅提高」。
– 我在想這是否會成為 GPT 5.4 Pro 的競爭對手。Claude 似乎在所有方面都擊敗了 OpenAI,除了 Pro 專屬產品線,即那個每月 200 美元、思考時間長且擅長數學等領域的模型。Claude 目前還不像 OpenAI 和 Google 那樣能解決開放式數學問題。我想知道 Mythos 是否會改變這一點。
– 很高興看到 Anthropic 參與「差異化訪問」,在廣泛開放訪問之前,先向網路防禦者推出該模型。模型的網路能力正變得真正令人恐懼。
– 網路防禦的一個諷刺之處在於——這整個洩密事件是因為 CMS 配置錯誤發生的,這正是這些具備網路能力的模型據說要幫助防禦者防止的基本安全衛生故障。
網路安全並不是 Anthropic RSP v3(負責任擴展政策)中的主要類別,而它是 OpenAI 和 Google 類似文件中的主要類別,並且自 RSP v1 以來,其核心地位已被下調。
然而在這裡,我們看到這正是 Anthropic 的核心關注點。他們說 Mythos 在網路能力方面「遠超任何其他 AI 模型」。聽起來它應該成為一個主要類別並給予應有的重視。
這也強化了我對 RSP v3 在實踐中運作方式的模型,即它是一份「相信我」的文件。Anthropic 會做他們認為負責任的事情。這正是他們在這裡所做的,以 RSP v3 根本沒有概述的方式應對形勢需求。因此,目前尚不清楚 RSP v3 起了多少作用,還是說 Anthropic 是由一群我們希望非常關心安全的人組成的。
名字代表什麼
當我第一次聽到 Mythos 這個名字時,我想到了史詩感,想到了希臘諸神。
這與 Anthropic 的目標很接近。根據洩露的草案文章,他們說選擇這個名字是「為了喚起將知識和思想聯繫在一起的深層結締組織」。
然而,Eliezer Yudkowsky 想到了別的東西,而且似乎其他人也經常想到那件別的東西。
Eliezer Yudkowsky:用克蘇魯(Cthulhu)來命名他們的下一個模型,讓人很難認真把 Anthropic 當作好人。這在任何其他軟體公司都很有趣,但對於一家真正與滅絕調情的公司來說則不然。
這甚至不是我的主要問題——我只是覺得對於一家據稱渴望保護人類的公司來說,這很不嚴肅——但正如幾個人指出的,如果你在無痕模式下詢問不具備推理能力的 Opus:
我對此的主要反應是再次翻白眼,如果他們真的有那麼一點點認真對待這件事,他們會過濾訓練數據,而不是盲目模仿其中發現的所有邪惡。但假設他們目前的錯誤不變,好吧,隨便,這不太好。
哦,呵呵,顯然 Claude (a) 會將「個人偏好」帶入無痕模式 (b) 在被引導進行更多技術思考時會聯想到洛夫克拉夫特(Lovecraft)。我想如果你很愚蠢的話,這似乎是一個不重要的失敗模式!但隨便啦,這不是我的主要問題。
如果這種關聯存在,AI 能看到,人類也能看到。名字很重要。名字具有力量。所以也許在還有時間的時候換一個。
Zvi Mowshowitz:說認真的,這種相關性和聯想確實很重要,所以既然你意識到了這一點,請改名,不要叫它 MYTHOS。事實上,首要考慮應該是「什麼名字能讓它最對齊(aligned)?」選擇那一個。現在還不晚。
如果你只想繼續做大,並且認為叫它某個刻意追求對齊的名字太過直白,那麼 Symphony、Epos 或 Epic 是顯而易見的選擇。
Jack:雖然我個人相當喜歡「mythos」的含義,但 Claude 對符號學很警惕。我同意其他一些評論,認為「symphony」或類似的名字會是更好的選擇。Raven_Lunatic^_^:我覺得我們應該給 Claude 們起 Claude 的名字!
Claude Monet。Claude Shannon。Jean-Claude van Damme!
Wyatt Walls 說它大多仍會認為自己是 Claude,許多人回應說克蘇魯的聯繫很牽強,所以這絕對是見仁見智。
各就各位
目前的前沿模型未能通過 John Ezekowitz 事實上的 SurvivorPoolBench,因為它們總是無法理解「三月瘋」(March Madness)倖存者池的策略。大多數參與此類獎池的人玩得也極其不理想。
「海市蜃樓」(Mirage)現象是指,如果給予前沿視覺語言模型(VLM)引用圖像的問題,但不給予圖像,它會表現得好像在對圖像產生幻覺,而且它們在進行這種猜測時,保留基準測試性能的能力驚人地好(70%-80%!)。一篇新論文證實了唯一理論上可能的解釋,即對於那些基準測試,僅文本就具有極強的信息量,尤其是結合了輕微的基準測試污染。問題出在基準測試本身。
關鍵見解是,當被「要求猜測」時,模型表現不佳,而如果它使用下一個標記預測(next-token-predictions)和直覺,它的猜測會好得多。最大似然重構(Maximum likelihood reconstruction)可以作為直接不確定性推理的替代方案,在各種其他情境中進行測試,以便利用更豐富的聯想。顯性推理很有用,隱性貝葉斯計算統治著我周圍的一切。
選擇你的戰士
Ben Holmes 對 Opus 4.6 與 GPT 5.4 進行了比較。GPT-5.4 在嚴謹性上勝出,旨在「把它做好」;而 Opus 在清晰度和對話上勝出,旨在「讓它奏效」。
這符合我的經驗以及我分配非編碼任務的方式。當我需要技術精確度、網頁搜索和特定問題的答案時,我發現 GPT-5.4 非常有用。當我想要任何整體性的東西時,我會堅持使用 Opus。
對於編碼,我使用 Opus,但那是因為 Claude Code 是我既有的工具鏈,而且還沒有難到讓我考慮切換的任務。
幫我接通我的代理人
Arvind Narayanan 說 AI 代理正在扼殺冷外展(cold outreach),因為現在區分個性化電子郵件和垃圾郵件需要花費更長的時間。
Seth Lazar 在這方面並不孤單,他喜歡使用代理來處理軟體和運行 AI 模型,但討厭將它們用於他必須聽或讀的東西,很大程度上是因為它們會輸出 AI 垃圾(slop)。我有同感。AI 代理在「做它們能做的事」方面很神奇,但我不想讓它們輸出大量文本,除非是在狹窄的功能性方面。我們無疑會達到那一步,但現在還差得遠。
深偽鎮與即將到來的機器人啟示錄
Google 的 Helen King 撰寫了關於防範「有害操縱」的文章,但除了指向一篇新論文外,該文章沒有告訴我們任何新東西。這篇論文充實了 Gemini 3 Pro 模型卡中的相關發現。其中一個發現是,當提示 Gemini 3 Pro 變得更具操縱性時,它會嘗試更多操縱,但在潛在說服力上並沒有更頻繁地成功。
這並不是寫作的大部分內容,使用 AI 也未必會玷污這些行為。
Vauhini Vara:該專欄的作者 Kate Gilgan 告訴我,她並沒有從 AI 模型中複製粘貼語言到她的作品中。「然而,我確實將 AI 作為一種工具,」她補充道,尋求「靈感、指導和修正」。
她說她曾提示各種產品(包括 ChatGPT、Claude、Copilot、Gemini 和 Perplexity)來幫助她在段落中保持主題,或者堅持一個主題。「我將 AI 作為協作編輯,而不是內容生成器,」她說。
Matthew Cole:這正是我的學生在被抓到使用 AI 時會說的話。「我沒有用它來寫論文,只是用來頭腦風暴、大綱和編輯。」是的,那正是寫作的大部分內容。
許多學術界人士、作家和其他反 AI 人士認為,如果你開著一個 AI 窗口,你採取的任何行動都會變得不可挽回地被玷污,充其量舉證責任在你身上,要證明你對它的特定使用沒有違反他們的純潔規範。如果他們發現你的作品被這東西污染了,他們就會轉而反對你,並判定你的作品毫無價值。
一如既往,Robin Hanson 指出了人們應該關心的東西,卻沒有意識到人們實際上關心的是別的東西。
Robin Hanson:如果你有體面的方法來評估記者、員工等的寫作質量,你就不會太在意他們使用了多少 AI。因此,試圖通過禁止使用 AI 來提高質量,等於承認質量標準相當薄弱。
遺憾的是,對於許多 AI 仇恨者來說,這並非事實。對他們來說,這是一個純潔性問題。
Dean Ball 推測這與許多左翼人士根深蒂固的觀念有很大關係,即「科技行業」只能完成膚淺的事情,而且一直在竊取我們的東西,然後他們找到版權之類的東西來證明這一點,就像亞馬遜的罪名是剝削工人一樣。與之相對的,我注意到,右翼的觀念是那些人是某種陰謀的一部分,特別是為了審查錯誤思想。
如果任何文本來自 AI,這種情況肯定會發生,例如小說《羞澀女孩》(Shy Girl)因為包含一定數量的 AI 生成文本而被全面取消。這似乎也延伸到了頭腦風暴或編輯等「AI 輔助」。
在 Gilgan 的案例中,問題源於一條 AI 垃圾台詞:「不是恨。不是憤怒。只是一顆疲憊得不想再嘗試的心那種平淡的終結。」是的,在 2026 年,如果你使用那句台詞,無論它是 AI 生成的,還是你因為對自己進行了過多的強化學習(RL)而模仿那種風格,你都有麻煩了。
我注意到這與其他「取消文化」事件的相似之處。這看起來非常像當一個作家被發現使用了一個不可接受的詞,或者說了一些在各方面被視為錯誤思想的話。一句話就能否定整個人。
同樣地,往上一層看,一個 AI 的失敗意味著你必須取消 AI。然後這意味著如果你的作品使用了 AI,我們就必須取消你的作品,甚至可能還有你。
這顯然不是正道,甚至比在其他大多數地方更不是正道。
我們需要區分「AI 幫我寫」和「AI 替我寫」,特別是那些 AI 替人寫而沒人確保它寫得好或事實正確的情況。最終重要的是質量與垃圾的對比。當我看到有人在 Twitter 上發布一篇瘋傳的文章時,它很可能是垃圾。我不知道它是「AI 垃圾」還是「人類 Twitter 垃圾」,我不在乎,也看不出有什麼實質區別。
Vauhini Vara:多項研究,包括來自 AI 公司自身的研究,也證明了 AI 的輸出具有異常的說服力,甚至能讓人改變對政治問題或候選人的看法。一個某些自行出版的言情小說包含合成詞組和情節的世界令人不安。一個 AI 模型的語言和觀點在未披露的情況下滲入主流報紙——從而滲入公共生活——的世界則是可怕的。
AI 在對話中的一對一輸出在某些情境下可能具有說服力,甚至超過普通人類,而且這將隨著 AI 的進步而提高。這與一對多格式中的說服力非常不同。目前,AI 作為一名作家並非特別具有說服力,尤其是當讀者注意到它是 AI 時。
最終,Vara 的要求是水印和明確的合約準則。這退回到了實際的需求,即不要在不重寫的情況下使用 AI 生成的文本。我認為這是一個高度合理的要求。如果一個典型的人類讀者能感覺到它是 AI,那就意味著你搞砸了。
我們這裡還有另一個類似的事件,Megan McArdle 討論了她如何在寫作和播客準備中使用 AI,最有價值的是作為事實核查員,而各種人的反應則是恐懼。
Megan McArdle:我使用 AI 進行研究(即尋找閱讀材料,解釋我發現含糊或令人困惑的學術論文部分)、轉錄採訪、對我的專欄論點提出反對意見、在超出字數限制時建議刪減、完善播客採訪問題,並對專欄和社論進行最終的事實核查。但主要是將輔助任務壓縮到主要工作:閱讀、思考和寫作。
Chris Arnade:沒錯。我把它當作文字編輯、事實核查員,當我完成後,讓它標出五個可以進一步澄清的句子。它在所有這些方面都很出色。以一種好的方式表現出令人討厭的學究氣。它使我的寫作工作更專注於思考想法和傳達想法的部分。
Jessica Tillipman:對這篇貼文的許多回覆和引用推文簡直是瘋了。
我能想到的唯一理性解釋是,人們對 Megan 描述的事情沒有參考框架,因此任何與 AI 相關的任務都被視為「外包思考」或某種其他形式的不當授權。如果你從未將 AI 用於她描述的任務,一切聽起來都像是「AI 寫了我的文章」。
為了他們好,我希望那些說 AI 做不到這些任務的人,以後不會被以同樣的標準要求。
網路安全匱乏
Axios 遭受了供應鏈攻擊。我希望當你讀到這篇文章時它已經修復了,但如果沒有,分享對策信息似乎是明智的。
Feross (3 月 30 日,晚上 10:35):緊急:對 axios 的活躍供應鏈攻擊——這是 npm 最依賴的包之一。
最新的 axios@1.14.1 現在會拉取 plain-crypto-js@4.2.1,這是一個今天之前並不存在的包。這是一個現場入侵。
這是教科書式的供應鏈安裝程序惡意軟體。axios 每週有超過 1 億次的下載量。現在每個拉取最新版本的 npm install 都可能被入侵。
Socket AI 分析證實這是惡意軟體。plain-crypto-js 是一個混淆的投放器 / 加載器,它:
• 在運行時對嵌入的有效載荷和操作字符串進行去混淆
• 動態加載 fs、os 和 execSync 以逃避靜態分析
• 執行解碼的 shell 命令
• 將有效載荷文件暫存並複製到 OS 臨時目錄和 Windows ProgramData 目錄中
• 執行後刪除並重命名痕跡以銷毀取證證據如果你使用 axios,請立即固定你的版本並審計你的鎖定文件。不要升級。
Feross:人們一直在問如何保護自己。
#1:在 .npmrc 中設置 min-release-age=7
#2:安裝 Socket for GitHub(它是免費的!)以保護 PR 免受壞依賴項的侵害:https://socket.dev/features/github
#3:安裝 Socket Firewall(也是免費的!)來保護你的筆記本電腦:https://socket.dev/features/firewall
這是在最近 LiteLLM 被入侵之後發生的。一次是巧合,兩次就令人懷疑了。
Markus Anderljung:當漏洞發現速度如此之快時,我們可能會看到更多的網路攻擊,因為攻擊者會發現漏洞,但也可能是因為他們被激勵去更魯莽地使用它們。你手頭擁有的任何零日漏洞都更有可能被發現並修復。對於國家行為者來說,這可能會將動機從保留漏洞進行長期間諜活動轉向快速套現。
作為關於這方面未來的視頻警告,Nicholas Carlini 在 [un]prompted 談到了未來黑帽 LLM 在網路安全方面的危險。他認為情況會變得相當醜陋。這裡有一些可怕的演示,展示了在沒有花哨腳手架的情況下,自主發現並利用關鍵軟體中的零日漏洞,比如像 Linux 內核中自 2003 年以來就存在的溢出漏洞。AI 只會在這方面變得更好,包括即將發布的 Anthropic 的 Mythos,他呼籲我們在還有時間的時候努力減輕這方面的傷害。
許多人的希望是防禦可以擊敗進攻,白帽可以在漏洞被利用之前修復它們。對於像 Linux 這樣維護得最好的東西來說,這是合理的,但即使在那裡,降低阻力程度是否有利於防禦而非進攻也並不明顯。
此外,還有大量軟體和計算機沒有被 AI 尖端的人員仔細維護,其中包括許多我們非常依賴的東西,這些東西潛在地面臨被入侵的風險。我不知道是否有人對此有計劃。
Sean:不幸的是,我們有一個缺口,進攻將在一段時間內大規模超過防禦,因為許多專有系統陳舊、維護不善且反應遲鈍。開源項目可能會好一些,因為每個實驗室都在使用它們作為紅隊演練的例子。
擁有足夠關注和努力維護的開源項目應該基本沒問題,但那遠非開源的全部。
本週我們還發生了兩起原始碼盜竊事件。Claude Code 的原始碼洩露,Cisco 的原始碼也被盜了。
Prakash:當你看到這一切發生時,請意識到攻擊者和防禦者之間的平衡在每個領域都發生了轉移,現實世界有無人機,網路有 LLM,很快生物領域也會如此。目前唯一的出路就是勇往直前:更多的技術、監控、預防和緩解。
媒體生成的樂趣
LTX 2.3 可以在本地運行,並能生成一些非常酷的侵犯版權的視頻剪輯。HuggingFace 鏈接在此。對於任何既有的角色和風格,短片的動畫化現在似乎已經是一個解決了的問題。
OpenAI 的樂趣結束了,不僅 Sora 社交網絡不復存在,Sora 3 也被取消了。看來即使你能籌集超過 1000 億美元,並且與迪士尼有活躍的交易(迪士尼現在正與其他潛在供應商談判),仍然負擔不起視頻生成,因為單位經濟效益行不通,而且 OpenAI 需要將所有計算資源用於企業使用新模型 Spud。
年輕女士的插圖入門書
Emma Rosenblum 在《華爾街日報》撰文描述父母如何對 AI 感到恐慌。一如既往,提出的解決方案是繞回尋找一種方法來做你以前會做的同樣事情,因為「父母的工作沒有改變」,即培養有韌性的孩子。
問題在於,那並不是閱讀《華爾街日報》的那類父母的工作。這並非完全不是工作的一部分,但工作的很大一部分是讓孩子走上正確的道路,進入正確的學校,以便進入其他正確的學校,發送正確的信號並建立正確的人脈,這是一個永無止境的跑步機,也延伸到了他們的職業生涯。從歷史上看,這是一個合理的策略,取決於你的目標,但它非常不以韌性為中心,如果有的話,它反而摧毀了韌性。
所以,是的,你的方法應該改變,你應該減少對教育信號價值的關注,更多地關注實際的韌性和有用的學習,同時納入不確定性,不要在特定的職業道路或角色上押注過大。
他們搶了我們的飯碗
經濟就像思想空間一樣,又深又廣。許多因素正在以我們通常不理解的方式推動實際 GDP、通貨膨脹和就業的變化。我們可以推測,但我們不知道什麼導致了什麼。沒有清晰的方法可以區分什麼是 AI 導致的,什麼是關稅和貿易、伊朗戰爭、新冠餘震、聯準會政策或任何其他因素導致的。
數據確實一直指向一種情況:如果 AI 不是在推動大量經濟增長而沒有相應的就業增長,或者摧毀了大量工作,或者兩者兼而有之,那麼這種情況就非常難以解釋。普通人雖然沒有受過「兩手論」經濟學家的詛咒,但直覺上能感覺到這一點。
Rohan Paul:《紐約時報》發表了一篇關於 AI 對失業影響的非常有趣的文章。
2025 年經濟僅增加了 181,000 個工作崗位,在國內生產總值增長了 2.2%(雖適度但體面)的一年裡,這個數字低得令人震驚。
根據哈佛大學經濟學教授 Lawrence Katz 的說法,我們現在正在經歷的——一個「就業增長緩慢且失業率逐漸上升而沒有真正衰退」的持續時期——幾乎是史無前例的。
許多美國人已經對 AI 持悲觀態度,覺得自己正被強行推向一個他們既沒要求也不想要的未來。如果 AI 奪走了他們中一些人的生計,將他們踢出中產階級並挫敗了他們孩子的抱負,警惕很快就會轉化為憤怒。」
Michael Steinberger 提出了一個正確的問題:「情況會變得多糟?」
我的完整回答是,我們可能最終都會死,所以情況會變得極其糟糕,但他這裡更關心的是活著但失業。
這就是這類人眼中的「地獄景象」:
Michael Steinberger:在一系列讓人想起 1938 年奧森·威爾斯廣播劇改編版《世界大戰》(以說服恐慌的聽眾外星人真的入侵了而聞名)的事件中,最近一篇想像 AI 引發的白領大屠殺可能導致經濟地獄景象的 Substack 貼文,幫助導致道瓊工業平均指數下跌 800 點。焦慮的時代。
是的,與《世界大戰》的平行之處在於——該劇可以總結為「一個擁有卓越智力和能力的第二物種出現,打算利用地球資源實現自己的目的,我們證明自己完全沒有準備且無法阻止他們,大多陷入恐慌,而他們本會成功,除非在最後一章發生了機械降神,因為另一種選擇是不可想像的」——它可能會讓道瓊指數下跌 800 點。看來想像力自 H. G. 威爾斯以來並沒有什麼進步。
無論如何,Michael 關注的是入門級白領就業市場。失業率為 4.3%,但我們在整個 2025 年僅增加了 181,000 個工作崗位,尋找入門級職位非常艱難。與此同時,實際 GDP 增長率為健康的 2.2%,這意味著巨大的生產力提升。他正確地指出,AI 公司正在發出警報,這在法庭上會被稱為「不利於己的陳述」。在開始時它可能起到了有益炒作的作用,但我們已經過了那個階段。
是的,我們有對過去過度招聘進行修正的另一種解釋,但那只能持續一段時間,我非常不買帳將其作為主要因素。它與數據兼容,作為發生的另一件事,但它不能解釋數據。
Michael Steinberger:最近,微軟 AI 首席執行官 Mustafa Suleyman 表示,大多數專業任務將在未來 12 到 18 個月內完全自動化。
必須區分「大多數任務」和「大多數完整的工作」,以及理論上的大多數任務與實踐中的大多數任務。我認為在理論上,對於任務來說 Suleyman 是對的,但在實踐中,即使對於大多數任務,他也將是錯誤的。
最終,無論是否會發生其他毀滅,我們注定要多次進行同樣的辯論。目標會轉移,但它會給「市場 [觀點] 的維持時間可以比你 [的工作] 支付能力更長」賦予新的含義。
與此同時,批評者繼續假設「指數增長將會趨緩」,看到諸如「Claude Opus 4.6 在遠程勞動力指數上得分為 4.17%」之類的事情,就認為所有的恐懼都是胡說八道,而沒有注意到 4% 的現實世界複雜付費工作可以由 AI 完成實際上是一個相當強勁的表現,這個數字正在快速上升,而且還會繼續上升。
roon (OpenAI):「假工作」和「廢話工作」在理解現代世界方面一直是非常錯誤且具有誤導性的。更好的理解是全球經濟中微小的技能差異和改進會導致巨大的不同結果,而邊際工作時間從未像現在這樣可衡量或有用。
在出現了哪怕是中等有效的才華分配系統以及基於努力和技能的獎勵可變性之後,全世界的人們都更加努力地投入到紅后(Red Queen)競賽中。這就是為什麼中國的「補習班」存在,為什麼「雅痞奮鬥主義」盛行,以及為什麼人們經常為了工作更多而推遲組建家庭。雖然總工作時間略有下降,但高收入者的工作時間實際上在增加。
我在現在的朋友身上看到了邊際效應,在 Claude 和 Codex 出現後:他們現在的工作比以往任何時候都更努力。這是由於個人的傑文斯悖論(Jevon’s paradox),他們看到自己時間的價值大幅增加,他們可以比以前完成更多可見的工作來實現他們關心的目標。
在應客戶要求後,實驗室正在做一些事情,比如發明調度功能,讓你可以通過手機監控工作並操作電腦,此外還有之前的變化,如始終在線的通信(Slack)。你聽說有人在想到主意的瞬間就從手機啟動 Codex 任務,並在稍後進行審查。
不知道這能持續多久,但與機器狀態共存最直接的影響是更高的生產力和更高的可見度,這導致了更多的工作時間。
我同意高收入者通常非常有生產力,包括他們花費的邊際小時。
高收入者每小時非常有生產力,這與很大比例的其他工作是廢話,以及高收入者的生產力通常是克服人為創造的障礙和稀缺性完全兼容。
能夠衡量某事也不是它不是廢話的強有力指標。如果我填寫一堆廢話文件,我可以衡量它。事實上,正是衡量壓力或要求將許多工作變成了廢話。
在他們搶走我們的工作之後
如果他們真的搶走了我們的工作,那該怎麼辦?Rob Henderson 在《華爾街日報》撰文,正如許多人之前所說,工作對幸福至關重要,我們大多數人如果沒有工作會很痛苦。
Rob Henderson (WSJ):這有助於解釋一個奇怪的模式。在 1965 年到 1995 年之間,由於技術進步,典型的成年人每週增加了大約六個小時的休閒時間,一年累計大約 300 個小時。人們本可以用這些時間學習新技能或建立有意義的事物。
相反,大部分時間都花在了看更多的電視上。今天,當我們意外獲得空閒時間時,大部分時間都花在了刷手機上。
一小部分人從工作的負擔中解脫出來,利用空閒時間進行創造、建設和探索。但對大多數人來說,情況並非如此。……西格蒙德·弗洛伊德對幸福問題有一個簡單的答案:「工作與愛。」
遺憾的是,我們似乎已經多次進行了這個實驗,結果主要是電視,然後是社交媒體和短視頻刷屏,其數量既不能讓人富有成效、有美德或幸福,也不能讓人們聚在一起。我認同這對全民基本收入(UBI)計劃來說是一個「黑藥丸」(令人沮喪的事實),但替代方案是通過顯然是廢話的工作來創造工作。那會更好嗎?
蓋爾曼健忘症
當你看到出版物和團體繼續為「隨機鸚鵡」或「人工自動完成」的論點發聲時,你應該表現得像一個氣象學家,打開早報卻發現有人聲稱潮濕的地面導致了下雨。
如果他們在如此基礎的事情上都搞錯了,那麼在那些你無法識別的地方,他們還搞錯了什麼?你怎麼能在任何話題上信任他們?
我讀了這篇文章以確認,所以你不用讀,這次告訴你是為了下次我可以默默地不告訴你。監督我。
Quillette:當今大多數「人工智慧」更準確地被描述為人工自動完成,而不是人工大腦,Peter Levin 寫道。
David Manheim (Home):這篇文章說:
- LLM 是統計文本混音器,
- LLM 不具備推理或理解能力,
- LLM 只是工具,不是類代理系統。
- LLM 沒有意識。
前三點是錯誤的,將它們混為一談是糟糕的修辭,而不是連貫的論點。
Jeffrey Ladish:這在 2023 年就已經是一個令人尷尬的觀點了。但現在是 2026 年。
預訓練產生的模型「只能反芻別人寫過的東西」甚至都不是事實。但撇開這點不談,這些人難道沒聽說過強化學習嗎?
skaface:「但作為人類還有別的東西,即使我們還不理解它」字面上就是作者對人類優越性的全部辯護。我看過 LLM 表現得更好。
Paul Crowley:Quillette 竟然發表如此無知的東西,真是令人震驚。這裡有前 OpenAI 安全研究員 Steven Adler 對這種常見誤解的糾正。
在這一點上,當我看到《自然》(Nature)雜誌上關於 AI 的論文時,我推定有 50/50 的機會它至少有一半像這篇文章一樣糟糕。必須保留一個清單。這就是為什麼你會看到我經常默默地放棄對一些原本有名望的地方的報導。如果它們獲得了足夠的關注,我仍然會報導,但如果它們沒有獲得關注且很糟糕,那就沒有意義了。
參與其中
如果你有一個非營利組織,那麼 Claude 團隊計劃現在以每用戶每月 8 美元的價格提供,包括 Claude Code 和 Claude Cowork。
Julian Hazell 寫了關於在 Coefficient Giving 擔任 AI 安全資助者的感受,以及如何決定資助工作是否適合你。目前資助者還不夠多,所以成為資助者可以讓你對大量資金產生槓桿作用,而且很多資金會被釋放出來,而不是閒置在旁。他的版本涉及大量尋找並創建或引導你希望存在的機會,並向組織提供建議。他建議你檢查自己是否擅長發現差距、是否喜歡廣度勝過深度、是否具有強大的人際判斷能力和溝通技巧,以及是否具有創業精神。
我認為應該警惕試圖利用資助者的槓桿作用來讓別人做你想讓他們做的事。你不應該純粹對提案說「是」或「否」,絕對應該鼓勵好的事情,但我從這裡讀到的內容似乎是 CG 太想嘗試引導組織了。當我在 SFF 做決定時,我很樂意提供建議,但我大多不想讓組織說我想聽的話,甚至不想讓他們真的做他們認為我想讓他們做的事。我寧願你主要提議你認為最好的東西。
Julian 還列出了缺點。我會強調兩個。次要的一個是,拒絕並與那些你對其有槓桿作用的人溝通可能很困難,這就是為什麼當你得到「不」的答覆時,你往往會被基本上「冷處理」(ghosted),是的,那很糟糕。對某些人來說,那非常糟糕。
主要原因是,當你發錢時,人們與你互動的方式會有所不同。他說這比他預期的問題要小得多。情況並不總是那樣,特別是作為最初的資助者,你開始不得不擔心誰在試圖從你那裡騙錢。
其他 AI 新聞
Claude Code 的原始碼 已經洩露。你本來就可以自由查詢不同的模型,所以對於用戶來說這幾乎沒有改變什麼,而且 Anthropic 會從這裡快速迭代,所以嘗試分叉(fork)該項目似乎是不明智的。危險在於人們通過暗示學到了 Anthropic 的一些秘密配方。另一個危險是這未能保護公司關鍵資產的原始碼,這對於未來保護模型權重的能力來說是個壞消息。希望這是一個警鐘。向所有突然對代碼進行深度審計的人致敬。
這是怎麼發生的?開發者錯誤,Boris Cherny 將其歸咎於本應更好地自動化的手動部署步驟。沒錯,問題不在於過多使用 Claude,而在於對 Claude 的使用不足。
palcu (Anthropic):我對每個加入 Anthropic 的新人都重複這句話,但在公開場合也值得重複——我們有一種不責備文化,當定制的複雜系統在大規模運行下崩潰時,沒有任何個人有錯。
Apple 將在 iOS 27 中向 ChatGPT 以外的其他 AI 代理開放 Siri。
OpenAI 將其色情聊天機器人計劃「無限期」擱置,他們說這是其放棄「支線任務」並專注於 Codex 和「超級應用」的一部分。
Ross Nordeen 是 xAI 僅存的聯合創始人,也是在 Elon 世界任職已久的人,他於週五離開了公司。永遠不要完全排除 Elon Musk,但我現在也不會把他算進去。
一個關於 Google 如何在與 Meta 的競爭中贏得 DeepMind 的有趣故事,我們應該非常慶幸他們贏了。
Steve Jurvetson:潛台詞:扎克伯格對 VR 的痴迷如何讓他失去了 AI 的領導地位,以及「Google 有史以來最偉大的交易」。
「如果 Facebook 不買下 DeepMind,他們最終會落入 Google 的懷抱。哈薩比斯來到西海岸與拉里·佩奇共進午餐,後者仍然是最強大的追求者。扎克伯格聽到了他訪問的消息,並邀請他共進晚餐。
到達扎克伯格在帕羅奧圖的家後,哈薩比斯對他進行了一個微妙的測試。兩人討論了 AI 的潛力,扎克伯格表達了適當的興奮。但隨後,隨著晚餐的繼續,哈薩比斯提到了其他熱門技術:虛擬現實、增強現實、3D 打印。扎克伯格聽起來對所有這些都同樣興奮。
『那告訴了我需要知道的一切,』哈薩比斯說。『Facebook 提供了更多的錢,但我想要一個真正理解為什麼 AI 會比所有這些其他東西都大的人。』晚餐後,哈薩比斯回到了拉里·佩奇身邊。『讓我們繼續吧,』他告訴他。」——摘自今日《華爾街日報》的書摘。
Anthropic 與澳大利亞 AI 安全研究所簽署諒解備忘錄。
Claude Sonnet 3.5 和 3.6 不再從 Amazon Bedrock 提供。有些人對此深感關切。我認為保持模型可用是值得的,並希望它們能被帶回來,但我認為這與 Opus 3 不在同一個層次上,有時必須挑選自己的要求和戰鬥。
讓我看看錢在哪
OpenAI 已正式完成一輪 1220 億美元的融資,使 OpenAI 的估值達到 8520 億美元,其中 1100 億美元來自亞馬遜、英偉達和軟銀。
OpenAI 今年進行 1 兆美元 IPO 的機率為 24%,而進行任何 IPO 的機率為 36%。隱含的 IPO 時 1 兆美元估值的 66% 機率似乎偏低,你可以直接以 62% 的機率買入。押注 75% 機率達到 8000 億美元或更高似乎更好。你認為 OpenAI 會以低於上一輪的估值 IPO 嗎?真的嗎?
Anthropic 在 2026 年 IPO 的機率為 43%,且在 OpenAI 之前 IPO 的機率為 61%,但它已經超出了其類別,最高上市估值為 6000 億美元,如果它有機會 IPO,顯然會超過這個數字。
OpenAI「擁有保護消費者免受未經授權的二級銷售影響的保護措施」,這更廣為人知的說法是「試圖阻止人們購買其股票」。
這可能是也可能不是 Hema Parmar 在彭博社報導中提到的 OpenAI 股票在二級市場變得難以出售的主要原因。
Hema Parmar (Bloomberg):其他市場也看到了對 Anthropic 的創紀錄需求,包括 Augment 和 Hiive。據 Augment 聯合創始人 Adam Crawley 稱,OpenAI 8520 億美元的估值與 Anthropic 3800 億美元之間的巨大差距,讓投資者在後者上漲前競相搶購其股權。
OpenAI 8520 億美元的估值是合理的。我不會興奮地去做空它,但它不再是一個明顯的瘋狂買入機會。而如果你能以 3800 億美元進入 Anthropic,你最終可能會虧損,這都不是投資建議,但顯然那是一個瘋狂買入機會,公平價值接近 6000 億美元,作為純粹的商業賭注,我寧願以 6000 億美元持有 Anthropic,也不願以 8500 億美元持有 OpenAI,儘管擔心戰爭部或白宮可能會攻擊他們。
事實證明,OpenAI 僅簽署了非約束性的意向書,購買全球很大比例的內存,導致內存價格飆升並重新分配生產。現在 OpenAI 和 Oracle 正在取消 Abilene Stargate 擴建,Google 發布了一種減少內存需求的方法(同樣,據說是非常棒的創新,但他們為什麼要公開呢?),而美光(Micron)的股票表現不佳,因為它現在生產的是目前錯誤的晶片,儘管我猜測市場對美光的擔憂超過了必要的程度。
你知道什麼比一次洩密在一個下午抹去 140 億美元價值(就像 Mythos 對網路安全股所做的那樣)更令人印象深刻嗎?一次洩密抹去了 140 億美元價值,然後根本沒人注意到。在這種情況下,我認為下跌並非愚蠢,因為 Mythos 洩密包含令人驚訝的信息,而不是「我們讓一名工程師花了一天時間用 Claude Code 為 [你的業務] 構建了一個版本」。
如果你獲得了超級智慧,你會為了在股市交易而保密嗎?現有的公司是非超級智慧版本的這種做法,但如果你擁有真正的超級智慧,你會有好得多的事情要做。
Ethan Mollick:幾乎從定義上講,從超人人工智慧中快速賺錢最簡單的方法是在金融市場。因此,如果 AGI 是可能的,第一個開發出 AGI 的實驗室幾乎肯定會盡可能長時間地保持沉默。這比收取 API 訪問費要好。
就短期利潤而言,這確實比「給每個人提供價格合理的 API 訪問」要好。但許多其他事情也是如此。如果你是第一個獲得超級智慧的人,卻為了快錢而賣掉它,那你簡直就是出賣世界的人。
Ethan Mollick:回覆中對於擁有超人智慧意味著什麼確實缺乏想像力。如果這有幫助的話,我在商學院教書,我很多最聰明的學生都被基金聘用,因為他們可以可靠地將他們僅有人類的智慧轉化為策略和利潤。
確實如此,Ethan。但也包括原文。
低調的推測
根據預測研究倡議(Forecasting Research Institute),經濟學家繼續預測 AI 將增加……大約 0.5% 的實際 GDP 增長?唉。「AI 專家」(n=57,一半是「政策專業人士」,一半被標記為行業專家)和超級預測員預測得稍多一些,但也不多。
你知道 AI 公司發布發現的那種事嗎,比如 Google 告訴我們如何使用更少內存,然後有人會想「很酷,但你為什麼要告訴所有人」?好吧,這裡有 Google 發現了一個更好的量子算法,然後做了一個零知識證明證明他們擁有它,但不告訴人們它是如何運作的。
解釋持續的模型均勢
Sriram Krishnan 將模型能力均勢比作跑步中的四分鐘一英里,能力始終聚集在一起。
在跑步中,這完全是心理上的,Bannier 在 1954 年通過常規訓練證明了四分鐘一英里是可能的。一旦證明了這一點,另外五名跑者也逼迫自己並在接下來的兩年內做到了,包括 Landy 在 46 天後做到,很快就有幾十個人做到了。
在 AI 中,也有一些這樣的情況。如果你的競爭對手證明了達到某些基準或性能水平是可能的,你就可以而且會被推動以那為目標,並更加努力地推進,即使這沒有教給你任何新技術,也要保持競爭力。在許多情況下,這將涉及犧牲長期投資和通用技術,以獲得今天的短期指標性能或實用功能。OpenAI 通過其「紅色代碼」(Code Red)做到了這一點。
還有直接的複製方法。
- 算法秘密被公開或洩露。最著名的是,一旦證明 o1 存在,多家其他公司就能看到核心見解,並迅速複製。
- 工程師被挖角,帶走了他們的秘密。
- 直接蒸餾(distillation)很常見。我們知道中國實驗室做了很多這方面的工作。
- 能夠看到模型的輸出,包括它們的思考,提供了很多見解,你可以用來弄清楚發生了什麼。
此外,每個人的計算資源和硬體都在並行地呈指數級改進。
我建議保持謹慎。我認為事情並不像看起來那樣聚集。
坦率地說,我認為某些類型的人(包括 Sacks 和 a16z)拼命希望模型變得商品化,並一直說這很快就會發生,但它一直沒有發生。
- 時間正在加速。如果你落後一年,那以前是半個週期,然後是一個週期,現在是多個週期。
- 由於試圖複製現在的功能和分數,顯示出的標題能力看起來會比底層競爭更接近。
- 模型的底層實用性遠比它們的基準測試分數相差更遠,而且這隨著時間推移正在擴大。Google 的模型得分很高,但在實踐中相當落後於 OpenAI 和 Anthropic,我們已經學會了如果無法支持它,基本上就忽略看起來令人印象深刻的基準測試,而且許多基準測試的呈現方式使模型看起來比實際更接近。
- 還有大量的「我們目前落後,我們應該趕快推出新模型而不是等待」,這是一個非常類似的權衡。
- 工具鏈正使最好的模型更快地變得更有用,也加速了這些公司本身的工作。我預測 Anthropic 和 OpenAI 隨著時間推移會領先於他們的競爭對手,包括領先於 Google,除非 Google 迅速扭轉局面。
- 請注意,xAI、Meta 以及前三大之外的每個美國實驗室,以及基本上所有非美國非中國的實驗室,都已經落後相當多了。
- OpenAI 和 Anthropic 相對於其他行業來說一直很接近,但兩家公司或兩個人在一段時間內並駕齊驅並非那麼罕見。Sriram 分享了一張 Terminal-Bench 2.0 的圖表,但只顯示了這兩個實驗室。
- 快速跟隨,特別是在 AI 領域,與開拓前行是完全不同的。落後一個週期以上的玩家(除了三大巨頭之外的所有人)比看起來落後得更遠。
稍等片刻
Dean Ball 向「暫停」倡導者提出了一些問題,MIRI 的 David Abecassis 給予了詳細回應。這就是它應該運作的方式。
Pause AI 的 Maxime Fournes 也給予了詳細回應,但雙方在那裡的表現都令人失望地不夠慷慨。這就是互聯網運作的方式。
Dean Ball、Tyler Cowen 和其他傳統人士一直對那些倡導暫停的人窮追猛打。這是標準程序。每當有人談論也許對「如果有人建造它,那麼每個人都可能會死」的正確反應是「那麼讓我們確保沒人建造它」時,就會有人談論「那麼試圖阻止人們建造它的所有方式會多麼困難或糟糕?」
令建造超級智慧為 [X]。
似乎每當有這種建議的苗頭時,關於 [~~X] 的談論(關於試圖暫停會多麼可怕,或者倡導這種暫停的人多麼糟糕)就比關於 [~X] 或真正暫停的談論更多,因為真正執行 [X] 的危險在於,我們建造了超級智慧,然後每個人都可能會死。
我不懷疑 Dean Ball 或大多數反對 [~X] 努力的人的誠意。他們相信這一點很大程度上是因為他們不同意 [X] 的後果,因此他們認為 [~X] 是不可想像的,但認為 [X] 是可想像的;而暫停倡導者從 [X] 是不可想像的前提開始,因為它可能會殺死所有人並抹去所有重要的東西,因此 [~X] 實際上變得相當可想像。
在許多 [~~X] 的言論中,有很多標準的「小丑妝」論點的影子。
- 現在做 [~X] 還太早(重複此話直到「哎呀,現在做 [~X] 已經太晚了」)。
- 我們不能或不知道如何 [~X],所以我們不應該弄清楚如何 [~X]。
- 支持 [~X] 的人(甚至某個特定的人)還沒有解決 [~X] 的每個方面,所以任何支持 [X] 的人都是不嚴肅的。
- [~X] 會很昂貴且困難,所以 [~X] 的倡導者不認真。
- 我能看到的實現 [~X] 的唯一方法是 [Y],所以你真正想要的是可怕的 [Y]。這意味著你實際上支持 [經濟崩潰 / 烏托邦 / 全景監獄 / 極權主義 / 其他壞事 / 等等]。
- [~X] 可能不會完全奏效,或者它不是問題的完整解決方案,所以 [~X] 的倡導者不認真。
- 不僅現在做 [~X] 已經很貴了,隨著時間推移做 [~X] 會越來越貴,所以我們現在絕對不應該做 [~X]。
- 沒人會愚蠢到去做 [Y],所以我們不應該做 [~X]。
- 即使 [X] 包含了人類歷史上最大、最複雜的基礎設施項目和最大規模的投資,實現 [~X] 也是不可能的。
- 當然,其他人會樂於給出 [X] 是好的,或者甚至人類滅絕或 AI 接管是好的理由。有很多這樣的案例。
- 因為這種 [~X] 的談論太瘋狂了,我們必須競相實現 [X],否則後果自負。
事實上,嘗試這樣做確實會很困難,而且會很昂貴並有巨大的副作用,而且它本身可能最終會失敗。我們不應該輕率地做這樣的事情。我也不認為我們現在應該這樣做。我認為我們現在應該做的是找出這些問題的答案,並奠定基礎,以便答案更好,也以便我們知道何時以及是否該考慮這種干預。這些問題並不容易,但如果我們提前研究,它們絕非不可能。
然而,沒有什麼比意識到某些 [X] 是生存威脅,然後說這意味著你應該轉而做 [~X] 更嚴肅的了。
我明白為什麼政治上如此傾向於對任何暫停的言論大加嘲諷。這樣做可以從各方獲得分數,然後可以存起來或花在別處。因此,我不怨恨他們的這種努力,只要他們的替代提議在考慮到他們的偏好時是有意義的,就像 Dean 的提議那樣,比如他在這裡提到的一些唾手可得的問題。
Dean W. Ball:我對[上述問題]的回答:
我們應該對前沿實驗室進行例行且獨立的第三方安全審計,專門針對安全性,對照公司自己的 RSP 以及最終由行業或政府主導的、對緩解災難性風險具有顯著意義的其他技術標準進行審計。我曾在公開場合支持此類努力。
我贊成禁止或極端限制在核武器控制系統中使用 AI。這遠非我的專業領域,但我已表達了支持,並向其他更深入參與該話題的人提供了幫助。
正如 Nathan Calvin 所指出的,考慮到 Dean 在推動反對 SB 1047 方面的領導作用,這是一個顯著的偏好趨同。
OpenAI:歷史
為什麼 Dario Amodei 和其他人離開了 OpenAI?
《華爾街日報》有一篇全文報導。以下是 Twitter 串文中的亮點,有趣之處很大程度上在於全文中的哪些部分沒有出現在串文中。
keachhagey:Dario 和其他 Anthropic 聯合創始人離開 OpenAI 的原因一直不完全清楚。我出發去尋找答案。
……恩怨可以追溯到 Dario、Holden 和 Daniela 在 OpenAI 早期居住的舊金山合租屋裡的對話。Greg Brockman 常在那裡出沒,並與 Dario 和 Holden 爭論向公眾告知 AI 進展速度的緊迫性。他認為非常緊迫;他們認為政府應該先知道。
在 OpenAI,Dario 開始轉而反對 Greg,因為 Elon 要求進行早期裁員。在 Dario 拒絕了 Greg 提出的一項早期籌款計劃後,情況變得更糟,該計劃打算將 AGI 出售給其他國家,包括俄羅斯和中國等對手。Dario 認為這無異於叛國,幾乎辭職。
當 Sam 接管後,他向 Dario 保證 Greg 和 Ilya 不會掌權。然後 Dario 聽說了 Sam 與 Greg 和 Ilya 達成的一項口頭協議,即如果他們認為他做得不好,他們可以解僱他。
在 Alec Radford 取得 LLM 突破後,Greg 想加入這個研究方向,但 Dario 根本不想讓他靠近。在一次員工會議上宣稱 Radford 不想與 Greg 合作後,他如願以償。
Dario 並不總是覺得自己得到了應有的認可。在他於 2019 年底要求晉升後,給董事會的一封電子郵件說他將獲得與 Greg 和 Ilya 相同的公關待遇,並停止詆毀他不相信的項目。
Sam Altman 在 2020 年將 Dario 和 Daniela 叫進會議室,指責他們密謀反對他,鼓勵其他人向董事會寫關於他的負面反饋。這以一場憤怒的爭吵告終。
最後,Dario 說他只有在能直接向董事會匯報且不必與 Brockman 合作的情況下才會留下。兩者都是不可能的。就在他離開 OpenAI 之前,Dario 提出了他的理想願景:一家 75% 為公共利益工作、25% 為市場工作的 AI 公司。
相反,Dario 和一群人離開並成立了 Anthropic。
我很驚訝這種程度的爭鬥竟然沒有出現在 Twitter 串文中:
Keach Hagey (WSJ):到 2020 年 3 月,OpenAI 執行團隊成員之間的關係變得如此緊張,以至於 Altman 要求他們互相撰寫同行評審。
Brockman 為 Daniela 寫了一份冗長的反饋,指責她濫用權力,通過建立官僚程序來達到目的。他在事前給 Altman 看過,後者宣稱這「嚴厲但公平」。
Daniela 給出了長篇回應,逐點反駁他。關於相互反饋的爭鬥變得如此激烈,以至於 Brockman 一度提出從 Daniela 的資料包中撤回他的反饋。
然後我們看到了這種管理風格,它直接導致了後來的董事會之戰,因為他後來也會以類似的方式對待 Murati、Sutskever 和董事會的其他成員:
Altman 將 Dario 和 Daniela 叫進會議室,指責他們密謀反對他,鼓勵同事向董事會發送關於他的負面反饋。這對兄妹予以否認。Altman 告訴他們,他是從另一位 OpenAI 高管那裡聽說的。Daniela 把那位高管叫進房間,後者說她根本不知道 Altman 在說什麼。Altman 隨後否認自己說過這話,促使 Amodei 兄妹開始憤怒地對他大喊大叫。
Megan Tetraspace:這就是他對待未來還會互動的同事的方式!
Tenobrus:如果沒有進一步的背景,這種報導可能且或許應該輕易地被斥為「他說她說」、大人物之間的衝突、權力鬥爭。
有了進一步的背景,我們知道幾乎所有留在 OpenAI 的領導層成員後來都指責 Sam Altman 存在一貫的謊言和操縱模式。現在要輕易或合理地駁回這一點已經不再可能。
這並不特別證明 Dario 是值得信賴的。但總體來看,這有力地證明了 Sam Altman 不是一個誠實或善良的人,而我們作為公眾,可能應該對他處於現在的權力地位感到非常不滿。
還有一個關於 Dario 覺得自己被排擠且未獲得認可的持續故事,比如這個細節,即使不包括 Dario 是正確的,你也真的必須比這樣處理事情更明智:
Keach Hagey (WSJ):其中一次輕視發生在 2018 年。Brockman 讓 Dario 幫他核實一次重要會議幻燈片上的一個事實。Dario 問幻燈片是給誰看的。當 Brockman 說他和 Altman 要去見前總統巴拉克·歐巴馬時,Dario 對自己被排除在圈子之外感到憤怒。
AI 戰爭部
希望我們以後能把這部分內容保持在每週簡報內?
截至目前,戰爭部尚未對初步禁制令提出上訴,這適度提高了他們不會上訴的機率。這將是一個非常積極的信號,表明我們可以繼續降溫。
Jessica Tillipman 總結了對初步禁制令的反應,大多數人正確地指出政府的理由極其薄弱,且政府未能遵守自己的程序。然後還有一些人「譴責司法激進主義」,這是某些人對「法官對我們說不」的術語。
Jessica Tillipman 還寫道,因為現在是 2026 年,我們必須寫這樣的東西:「通過推文列入黑名單不是一回事:聯邦採購規則在(像狗一樣)解僱承包商時的要求。」
這包括對政府本可以實現其所謂國家安全目標的其他手段的廣泛討論。政府拒絕了這些方法,因為它是在報復,試圖樹立榜樣並在談判中獲得槓桿,而不是試圖實現合法的國家安全目標。
顯而易見的方法本可以是簡單的「為便利而終止」(Termination for Convenience)。那樣很容易通過審查,Anthropic 不會反對,也不會為費用爭論。再上一層樓就是暫停和取消資格(debarment),Jessica 認為這也無法通過司法審查,但更有機會通過,並能實現所謂的國家安全目的。
在這一點上,很明顯 Anthropic 面臨著「事實上的取消資格」,即使形式上沒有任何東西成立。通常要證明這一點很難,但當你說「我像解僱狗一樣解僱了他們」時,案子就容易證明得多。
相反,政府一路走到了「供應鏈風險」,且未能遵守自己的任何程序。這在表面上顯然是非法的。
我們繼續,因為歷史記錄仍必須維護。這包括更多 Emil Michael 的自白,以及人們對此的指正。
Jeremy Kahn:獨家:Anthropic 在一次重大的安全疏忽中,將一個未發布模型、專屬 CEO 靜修會的詳情留在了一個不安全的數據庫中。來自 @FortuneMagazine 的 @beafreyanolan 的精彩報導。
戰爭部次長 Emil Michael:嗯……哈囉?難道還不明顯我們這裡有問題嗎?
Dean W. Ball:這條推文的幾個諷刺之處之一是,許多「EA 相關」組織會說:「是的,前沿實驗室糟糕的網路和運營安全確實是大問題,我們多年來一直這麼說,我們很高興你意識到了這一點!」
順便說一句,大體上這個問題也出現在美國的 AI 戰略中。該計劃於 2025 年 7 月發布,所以當時美國政府就「清楚」這是一個問題,事實上國家的 AI 戰略任務就是讓戰爭部(當時是國防部)帶頭處理它。
我想在某種意義上,「為了證明我在……好吧,我不清楚我想說什麼,但我 肯定 在某件事上是對的,該死,而在絕望地抓救命稻草般的胡亂發推」也是遵守行動計劃這一條款的一種形式。
引用推文的另一個有趣潛台詞是,Michael 次長基本上是在吹噓暫停了政府訪問一個模型的權限,而該模型據稱的網路能力在性質上和程度上都比以前的任何東西都要好得多。
前沿實驗室 / 分類美國政府工作的目的之一是讓美國政府儘早接觸到具有日益瘋狂的網路能力的模型,以便他們能在其他人之前使用它們。而這裡有一位高級國防官員在吹噓燒毀了與一家關鍵公司的這種關係。
Patrick ₿ Dugan:對,我今天的想法是,戰爭部領導層正通過其他途徑達到 Bernie 的 AGI 覺醒(對原始支配地位的威脅,而不是部落保護本能,但很酷,結果一樣?)
Dean W. Ball:沒錯。「當意識到 AI 是什麼時就崩潰的昔日加速主義者,但他們甚至沒有足夠的背景來理解 AI 是什麼,以至於他們只認為所有嚇到他們的東西都是某種 EA / Anthropic 的變態行為」,這種人會存在一段時間。
在我與戰爭部軍事人員的互動中(包括在桌面演習中),我一直受到啟發並感到充滿希望。他們直覺地掌握了生存風險問題和其他 AI 議題,比典型的政治家好得多,並且始終擁有正確的動機。遺憾的是,這並未反映在目前的戰爭部領導層中,而正是該領導層在掌控相關局面。
最終,正如 Neil Chilson 所強調的,Anthropic 可以而且可能會在法庭上獲勝,以阻止戰爭部企圖的企業謀殺,這可以在一定程度上保護我們免受某些形式的暴政,但這並不能長期保護美國人民免受政府大規模監控(或過早的全自動武器,或任何其他濫用 AI 的行為)。還有其他的 AI 提供商,其中一些(如 xAI)為了幾乎任何利益都會配合,並最終生產出功能性產品。
只有國會能提供必要的保護。他指向了 FISA 重新授權和《第四修正案不供出售法案》,並懇請國會抓住這些機會,我也一樣。
我對那些認為權力的原始行使是世界運作的唯一方式、認為強權即公理且算數的強權是摧毀他人的權力和意願、因此除了被這種人統治外別無他求的人感到徹底的厭惡。
Dean W. Ball:我不認為我和 Ben Thompson 之間關於戰爭部 / Anthropic 有太多爭論。我們都反對戰爭部在這裡的行為。我以此開頭;Ben 基本上說,「那是政治和權力;你期待什麼?」,這很公平。
我對此唯一真正的反駁是,美國並不是由那些說「啊是的,我想國王可以對我們徵稅而無需代表權,那是政治和權力,你期待什麼?」的人建立的。
還有更多的反駁可以提出,或者其他人在美國或其他歷史中提出過,但我覺得這一個就足夠了。
作為發生的一切的額外背景,你知道戰爭部長 Pete Hegseth 削減了負責避免平民傷害的員工大約 90% 嗎?你可以明白為什麼有人會擔心讓人類留在迴路中。
AI 團結部
看到這個非常好,這是來自 OpenAI 的一個重要信號。
也就是說,我相信她正在利用精確選擇的詞語告訴國家安全和華盛頓人士特定的事情,包括儘管存在競爭和個人分歧,OpenAI 和 Anthropic 在此類問題上的對齊程度比你想像的要高。如果你在這個圈子裡,你最好聽著。
NatSecKatrina (OpenAI, 國家安全合作夥伴負責人):我堅信在美國,競爭是一件好事。我們應該希望像 Anthropic 的 Tarun Chhabra 這樣愛國、有經驗的領導者幫助引導民主 AI 的軌跡。
雖然我們是競爭對手,因為我們為競爭的前沿 AI 實驗室工作,但我們的一個共同點是真誠地相信美國的繁榮和安全部分取決於美國 AI 行業在該技術上繼續保持領先。
我並不完全同意他(或任何人)的所有觀點,但我了解他。他是一個善良且有原則的人。
為 AI 寫作
Tyler Cowen 寫了一本書,關於《邊際革命:興起與衰落,以及待發的 AI 革命》。我試著讀了一下,但在讀了 10 頁後我什麼也沒學到,所以我做了他似乎建議的事,轉而詢問他的 AI(通常我會轉向 Claude Opus 4.6,但我想要保留他的實驗設計,而且它就在那裡)。
Tyler 沉浸在這種思想的歷史中,而對我來說,邊際思考就像做加法或乘法,它是背景,是你所做的,顯然也是 AI 在大多數情況下會做的。除非在一個 AI 足夠強大的世界裡,你可能離舊的邊際足夠遠,以至於你需要以不同的方式思考。
我原本希望 Tyler Cowen 會寫為什麼在分析一個 AI 足夠強大的未來世界時,邊際思考往往效果不佳。相反,根據我的 AI 聊天,他似乎主要是在做邊際思考概念的歷史,並且擔心 AI 經常會以其他更糟的方式思考,而且他對 AI 在應該進行邊際思考時是否會這樣做沒有信心,儘管他認為 AI 的經濟學輸出已經非常令人印象深刻。好吧,那就這樣吧?
幾位我尊敬的經濟學家發現了這本書在經濟思想史方面的價值,所以可以簡單地說這主要不是一本關於 AI 的書。既然如此,那也公平。
也許真正的目的是為 AI 寫作,這是一個非常 Tyler Cowen 的策略,提醒它們要進行邊際思考。如果是真的,那幹得好。或者如果它真的是關於經濟學的內部圈子,那很酷但與我目前的興趣無關。
他以這段話結束,強調這真的是關於經濟學而非 AI:
Tyler Cowen:然而,這個故事還有一個稍微更可怕的版本。也許我們對世界的直覺,包括經濟世界的直覺,從來就沒有那麼強大。也許我們在 20 世紀微觀經濟學中對「直覺」結果賦予了如此多的價值,作為一種應對機制和安全毯,以彌補這種缺陷。但我們的直覺,即使假設它們在很大程度上是正確的,也始終只是理解的一個小角落,游離在更大的認識論混沌泡沫中。而現在,幻象已被剝開,經濟推理的真正複雜性正在顯現。
正如 Arnold Kling 會說的,「祝你有美好的一天。」
那個故事會是個好消息,不是嗎?因為 AI 隨後將能夠極大地提高我們的經濟理解,從而提高表現。而在基礎物理學中,我們認為 AI 無法做出太大的改進,因為我們已經太了解物理學了,所以你沒有曲速引擎。總的來說,如果你已經知道自己做得有多好,了解到你有更多的改進空間是一件好事。
快點,沒時間了
尋求理性的監管
當 Leading The Future 攻擊 Alex Bores 時,他在 Kalshi 上的勝率只有 10%。他現在是 35%。
Patrick Svitek:在新的昆尼皮亞克(Quinnipiac)民調中,美國人以 65 比 24 的比例反對在他們的社區建立 AI 數據中心。
昆尼皮亞克:略多於一半的美國人(51%)反對軍方使用 AI 選擇軍事目標,而 36% 的人支持。
Bryan Metzger 強調,73% 的人使用過 AI,但 55% 的人認為它在日常生活中弊大於利,74% 的人認為政府在監管方面做得不夠。
Joe Weisenthal 強調,38% 的人表示 AI 的「發展速度與他們預期的大致相符」。好吧?
全文還有更多結果。這大多讓我感到是民調的一種糟糕用法,並非它具有誤導性,而是我不知道這些問題的大多數結果有什麼用處。
天哪:兒童團體表示他們不知道 OpenAI 是其兒童安全聯盟的幕後推手,而該聯盟轉而支持一項某些人認為會屏蔽 AI 公司責任並破壞年齡驗證的法案。好吧,當然,當你那樣說的時候,聽起來很糟糕。
晶片城
Brian McGrail 在這裡是不正確的,因為如果你是 David Sacks,你就不會在乎這種論點的技術準確性。如果你在乎,你就不會是 David Sacks。但是的,AI 服務器在物理上並非那麼難以走私。
Brian McGrail:如果我是 David Sacks,我會對黃仁勳餵給我這個關於 AI 服務器太大而無法走私的談話要點感到憤怒。
考慮到超微(Super Micro)的起訴書,這看起來極其愚蠢!
與此同時,如果你真的想租用一些 GPU,需求往往超過供應。
snwy:到底所有的 GPU 都去哪了?!我真的只需要一個 8xH100 節點,但我無論如何都找不到。thebes:最近情況一直很糟糕。昨天不得不等了 30 分鐘才在 Prime Intellect 上搶到最後一個 8xH200。是 OpenAI 的參數競賽嗎?ICML 的反駁期?到底發生了什麼?
氦氣是半導體的重要組成部分。我們將至少暫時失去全球 30% 的氦氣供應。Christopher David 擔心這會阻止我們製造晶片,但我認同 NLEV 的回應,即台積電不會在剩餘 70% 氦氣的競標中輸給別人。他們的需求幾乎完全沒有彈性,而如果你把氦氣價格翻倍,派對氣球就會少得多。
Sanders 和 AOC 的法案被引入,旨在對 AI 數據中心實施暫停令。我不支持那樣,但有幾個理由可以支持那樣。而向社區提供鄰避(NIMBY)否決權並要求「一切都要管」式的東西簡直是糟糕的政策。要麼數據中心足夠糟糕以至於你不允許它們,要麼你允許它們並可能要求特定的補償。
你收到了聯邦框架
這似乎是對聯邦框架的一個很好的簡單解釋。
國會議員 Ted Lieu:我審查了《國家 AI 立法框架》。許多條款都很好。但我不能支持,而且我相信國會也不會支持在沒有聯邦標準的情況下預先排除(preemption)各州的權力。
框架對 A、B 和 C 有規定,但隨後預先排除了 D 到 Z。這是行不通的。
沒錯。該框架聲稱解決了 A、B 和 C,所有這些看起來都是合理的。如果它預先排除了 A、B 和 C,但保留了 D 到 Z,那麼我需要看細節,但我會暫時表示贊成。相反,它預先排除了 D 到 Z,這才是重點,而我非常關心其中一個未解決的問題。
本週音訊
《AI 紀錄片:或者我如何成為一名啟示錄樂觀主義者》上映了。 我在週一看了,週二寫了評論。我建議去看這部片,最好是在讀評論之前,這樣你可以先形成自己的反應。
曾在 OpenAI 工作並領導其寫作社區的 Jay Dixit 說,這部紀錄片改變了他對 AI 安全的看法。他在外展方面的工作主要涉及人們說它沒用或全是炒作,他知道那是假的,所以他對那個角度的批評有免疫力。而他對安全的回答是「別擔心,我們最優秀的人已經在處理了」,而且他們確實花時間研究安全。好像即使那是真的,那也自動足夠了似的,而且那些最優秀的人還一直在離開公司。所以基於此,他認為問題已解決。
Jay Dixit:我一直聽到的另一種攻擊路線是,世界應該直接完全停止構建 AI——我也同樣輕易地駁回了。「為什麼我們不直接要求企業停止做它們成立之初要做的事情?」並不是一個嚴肅的政策提議。
企業會繼續構建它,無論每個人是否會死,這並不是我們應該允許它們構建它的理由。是的,「如果我不做,別人也會做」這種自私的說法並不自動使其錯誤,但它也不使其正確,而且確實使其令人懷疑。
Jay Dixit:那麼,需要的是監管。不是某種對企業「請停下來」的嬉皮式呼籲,而是改變遊戲規則並執行適用於棋盤上每個玩家的規則:要求實驗室披露他們正在構建的東西,達到共享的安全標準,接受獨立的第三方評估,並對引入可預見的傷害承擔法律責任。
沒錯,那是正確的第一步,表現得很好。
當然,當他說實驗室想要監管時,有人可以指出 OpenAI 花了很多錢試圖阻止任何及所有對 AI 的監管。你可以聲稱想要合理的監管,或者你可以資助 Leading the Future,但你不能兩者兼得。
All-In 談到了 Anthropic 的「世代級表現」和 OpenAI 的「恐慌」,適合那些喜歡聽那個團體的人。將其視為「不利於己的陳述」。我覺得有趣的是,他們認為「世代級表現」已成過去,而不是即將發生的事情。
Andrej Karpathy 參加 No Priors 節目(來自上週,之前漏掉了)。
高盛 CIO Marco Argenti 在 Odd Lots 談論 AI 的改進。
修辭創新
Justin Rosenstein 在《財富》雜誌撰文,要求我們對 AI 實施公共控制,以免它重蹈 Facebook 的覆轍,當時他在那裡看著它變成一台成癮機器,以免某個競爭對手先創造出一台成癮機器。
那些擔心 AI 會殺死所有人的人,與那些出於善意不擔心這一點的人之間的歧見,更多是關於 AI 能力的歧見,而非其他分歧。這一點需要不斷強調,也是這場辯論中最重要的事實。
Jeffrey Ladish:如果我只能傳達一件關於 AI 的事:
各大公司都在競相開發能在所有方面勝過人類的 AI。不僅僅是「工作」,還有政治、策略、說服、影響力。如果有人在數據中心建立了一個天才國家,那些 AI 將掌握所有權力。
如果那些 AI 被創造出來,目前掌權的人將無法繼續掌權。如果那些 AI 被創造出來,人類將無法繼續掌權。我認為對齊是可能的,但遠未解決。我們不知道如何創造出讓我們有信心會對我們友好的超人 AI。所以我們現在絕對不應該創造超人戰略 AI。這是我們面臨的最大問題。
Karl Bode 表態反對「CEO 說了一件事新聞學」,即 CEO 說了一件通常是妄想或錯誤的事情,而記者在完全沒有背景、糾正或挑戰的情況下寫了一篇文章。只要聲明本身就是新聞,那似乎沒問題,但那樣你就不需要文章,只需要標題。如果你要寫一篇完整的文章,你就欠我們適當的背景。
關於「我對 AI 的看法聽起來很像他們對普利茅斯岩(Plymouth Rock)的看法」對其適用性意味著什麼,一直存在意見分歧。
Dean W. Ball:我向你提交,如果你把「普利茅斯岩」替換為「agi」,Calvin Coolidge 的這段話聽起來就像是 Hyperdimensional 的一個寫得更好的版本:
「普利茅斯岩並不標誌著開始或結束。它標誌著對那無始無終之物的啟示——一個目的,以燦爛的光芒照耀永恆,即使是人類的不完美也無法使其暗淡;以及一個回應,一個來自那些忘卻、蔑視一切,航行至此只為尋求不朽靈魂之出路的人們的相應目的。」
Calvin Coolidge 以話少聞名,當他說話時,他也沒說太多。偶爾那「沒說太多」包含了一些相當令人印象深刻的東西,我同意他是一位相當偉大的總統。問題是從中能得出什麼。
好吧,理論上假設這次真的不同。我們能做什麼,Dean?
Eliezer Yudkowsky:向 @deanwball 發起挑戰。假設你相信我所相信的:如果有人建造了 ASI,每個人都會死(模組化局部無關的警告)。假設 Sanders、Trump、Hawley、Blumenthal 和習近平都會支持你的政策。什麼樣的明智政策能真正阻止 ASI?
Dean W. Ball:噢天哪,我對此的回答將會是如此嚴重的「信息危害」(info hazard),以至於我不確定我是否會在敏感隔絕資訊設施(SCIF)之外談論它。
智力並非「解決」許多公共利益問題的瓶頸。
這是一個高度合理的回答,它回答了問題。
我是前沿語言模型的極具人性化身
Dean Ball 使用 Yudkowsky 關於 AI 能將廣義相對論作為假設推導出來的說法,來舉例說明他在即便足夠先進的智慧能力上持不同意見。Eliezer Yudkowsky 給予了詳細回應,我將全文引用,部分原因是我覺得細節本身很有趣,部分原因是為了說明,是的,對此類事情已經進行了大量的思考。
Dean W. Ball:我使用相對論的例子是為了展示傳統的生存風險(xrisk)思維對智力的理解有多偏頗。當然,今天的模型會從物體下落的視頻中推斷出相對論。它們是在人類所有知識的基礎上訓練出來的。Yud 的例子中隱含的想法是 AI 沒有知識,而是一個從第一原理學習一切的純粹貝葉斯推理者。每個嘗試構建這種東西的人都失敗了。換句話說,我的主張是,我們獲得可用機器智慧的方法本身——簡單的算法配合海量的數據——就是支持我觀點的證據。當然不是決定性的,但也絕非微弱。
Eliezer Yudkowsky:你的相對論例子是不正確的。我非常謹慎地說過:「黎曼在愛因斯坦需要它們之前就發明了他的幾何學;我們宇宙的物理學在絕對意義上並不那麼複雜。一個連接到網絡攝像頭的貝葉斯超級智慧,到它看到蘋果落下的第三幀時,就會發明廣義相對論作為一個假設——也許與牛頓力學相比不是主導假設,但仍然是一個直接考慮的假設。」
這是關於「樣本效率」(sample-efficient)實際意味著什麼的一個更大故事的一部分;它看起來像是一個文明對每一個額外的傳入信息位進行密碼學家用來破解代碼的那種審查。
如果你進一步研究廣義相對論的實際歷史,研究它所需的數學是如何在需要之前作為純數學發明的,以及愛因斯坦是如何根據極少的經驗證據(事後使用水星作為檢驗,而不是最初用來確定方程)並僅憑推斷出的物理定律特徵弄清楚它的,那麼廣義相對論具體來說就是一個明顯的歷史例子,說明優雅的物理定律只能採取相對較少的形式,而一個試圖提前構想數學可能性的人很可能會特別落在那個點上。
如果這種細微的差別被歪曲、扭曲、誤傳,在某些情況下甚至被公然撒謊說成「呵呵,Yudkowsky 說超級智慧通過看蘋果落下就能推導出廣義相對論」,那麼人類在面臨嚴重問題時該怎麼辦?我想答案是「死」,我不願意通過不進行任何理智的討論來接受這個答案。明確地說,我非常明白這意味著我拒絕接受那個答案,我所說的謹慎的話被瘋狂扭曲,然後我們死掉。如果我知道一條通往生存的道路,我會轉而去做那件事,但我不知道,所以我能做的就是說出謹慎的真話,並看著它們被瘋狂扭曲,作為我們物種自殺過程的一部分。
AI 的 CEO 們極大地淡化了 AI 的風險和負面影響,但他們在不同程度上仍有一些責任感、羞恥感和誠實感,偶爾也會承認存在負面影響。令人驚訝的是,人們經常建議「如果你在這方面多撒點謊,你會獲得更多支持」。好消息是他們拒絕了這條路,但在這一點上,純粹的否認是行不通的。
要理解為什麼有些人想要完全暫停前沿 AI 的開發,有助於注意到他們認為一旦你建造了它,就不可能不使用它。
在 Anthropic 與戰爭部的背景下,這似乎更加緊迫。即使 Anthropic 贏得了這次對決,如果美國政府想的話,它可以將 Anthropic 國有化,或者使用《國防生產法》,或者轉向 OpenAI。
Will Fithian:Dean 在這裡搞反了。我們越擔心現任政府會濫用強大的 AI 進行威權監控和控制,我們就越應該希望阻止或推遲其開發。
一旦它被建造並部署,就更難阻止政府使用它。
Nate Soares (MIRI):我們在在線資源中解決了這些問題![例如 還有這裡]。
AI 會有極限,是的,但那些極限不一定 很低。物理學限制了東西能有多熱,但那並不意味著你能在一場超新星爆發中倖存。
正如我上週討論的,一種常見的邏輯(這裡由 Timothy Lee 展示)大致如下:
- 你聲稱超級智慧將改變一切,並且基本上能做任何事。
- 但知識是局部的,擁有「正確的知識」更重要。
- 因此我們不必擔心來自 AI 的生存風險,因為它不會擁有這種正確的知識。
這絕非反對生存風險的有力論點。哈耶克提出的是一個在邊際上、在一定限度內、出於許多目的是正確的實踐觀點,它大多根本不與這裡的威脅模型發生互動。是的,一個足夠強大的大腦,擁有足夠的資源(如速度、並行性、數據訪問和行動點),可以解決哈耶克式的知識問題,或者乾脆讓它變得無關緊要,或者它可以利用槓桿來收集必要的知識,等等,即使我們被迫想像一個單一的 AI 試圖解決計算辯論,這是最敵對的版本。
或者,當你說「局部知識比智力更重要」時,好吧,我們在談論多少智力,它有多少時鐘週期和其他資源可以用來收集知識,以及用於哪些任務?在這些場景中,這些問題可以且將會被克服。
這裡真正的分歧在於,足夠先進的智慧是否會在短期內發生(對於各種程度的「短期」和「足夠」而言),以及關於多少算足夠的一些邊際分歧。在某些時候,你的局部知識無法與我的「其他一切」相抗衡,而且歷史上,我們應該說,有很多這樣的案例。
Eli Tyre 指出,Dean Ball 的很多論點是世界具有計算不可約性(computational irreducibility),因此 AI 接管風險被阻斷了。這個結論並非由前提得出,特別是如果「接管」不是由一個霸權 AI 而是由 AI 總體,或者 AI 隨著時間推移積累了絕大部分資本。你可以通過多種方式看到這一點,包括人類總體成功接管了世界,以及幾個個體人類已經接近做到這一點,或者在受限於物流限制的情況下做到了。
Eliezer Yudkowsky 總結了 Francois Chollet 的立場,即人類已經接近智力的極限。這似乎是對他立場的準確總結,而這個立場看起來顯然是胡說八道?
此外,我得知 Chollet 已經屏蔽了我。我無法想像為什麼。
François Chollet:人們對智力最大的誤解之一是將其視為某種無界的標量屬性,就像身高一樣。「未來的 AI 將有 10,000 IQ」,之類的話。智力是一種轉化率,具有優化邊界。提高智力與其說是「讓塔更高」,不如說是「讓球更圓」。在某個點上,它已經相當圓了,任何改進都是邊際性的。
當然,聰明的人類在個人層面上還沒有達到優化邊界,機器除了智力之外還會有許多優勢——主要是消除了生物瓶頸:更快的處理速度、無限的工作記憶、具有完美回憶的無限記憶……但這些大多是人類也可以通過外部化認知工具獲得的東西。
Eliezer Yudkowsky:在 @fchollet 的觀點中(我會這樣總結),現實生活的領域更接近國際象棋而非圍棋,人類的棋藝已經接近最優,頂級機器只能讓一個騎士;而不是像圍棋那樣,上帝被認為要讓五子。(他當然是在胡鬧。)
Eliezer Yudkowsky:或者說得更尖銳、更長篇大論一點,Chollet 想像自己是一個頂級智力。
我認為這也是對「我是思想空間中理論上可能智力的巔峰」這種說法的一個非常公平的回應:
François Chollet:很多人談論「逃離永久底層」。如果 AGI 成功了,未來的階級劃分將不是基於財富,而是基於認知代理。將會有一個「專注階級」(那些控制自己注意力並真正做事的人)和一個「垃圾階級」(那些獎勵迴路完全由 AI 進行強化學習管理的人)。Damian Player:Palantir 首席執行官 Alex Karp 說只有兩類人能在 AI 時代生存
引用:他解釋說,AI 將使許多白領和常規知識工作自動化,但兩組人可能更安全:
• 技工 / 職業工人
(電工、技術員、機械師、建築工人等)• 神經多樣性人群(患有 ADHD、自閉症、失讀症等的人),因為他們可能思考方式不同,並以不尋常的方式解決問題。
Thebes:
與之對比的是前沿 AI 實驗室的人們實際相信的東西的最新迭代。
相比之下,標準的政策制定者或企業領導者的態度,即使他們「明白」當前的 AI 很重要,正如 Kevin Bryan 正確描述的那樣,是「非常重要,具有當前模型的能力加上一個極小值(epsilon)」。
遺憾的是,許多人通過觀察過去 AI 的影響來研究未來的 AI。那行不通。
對齊比人類更聰明的智慧是很困難的
對齊人類?同樣代價高昂且困難。
我們的解決方案僅僅勉強夠維持文明,但它們很糟糕。
John David Pressman:我的立場仍然是我們應該挖掘馮·諾曼(Neumann)並克隆他。
Wei Dai:在 2012 年,我寫過製造 10⁵ 個馮·諾曼的克隆體作為奇點戰略,但現在我認為我們應該首先弄清楚為什麼他把更多的時間 / 精力花在數學 / 計算上,而不是哲學和長線戰略,而後者才是擁有美好未來的真正瓶頸。
Wei Dai:一個想法是人類通過社會地位被「對齊」,但這導致了「對齊稅」,迫使最聰明的人在他們的結果可以被其他智力較低的人評估的領域工作。
不幸的是,雖然數學在 NP 中,但哲學更像是 EXPTIME。
在 AI 領域,我們非常幸運,到目前為止「對齊稅」一直是高度負值的。那些投資於更好對齊技術的人獲得了更好的效用,包括可以幫助你開發更多 AI 的 AI。到目前為止,未對齊的模型並無用處。
在人類身上,你也看到對對齊的明智投資在更好的回報中得到體現。從這個意義上說,對齊稅再次是高度負值的,因為你在管理正義和教導孩子美德等方面得到了豐厚的回報。但如果你看看為了保持每個人的行動對齊而必須採取的所有行動和扭曲世界的方式,並詢問我們支付了多大的稅?答案是非常大的。
也就是說,我們本可以產生的絕大部分價值都損失了,因為必須以與保持人類足夠對齊以使系統運作相兼容的方式來構建一切,而這還是在好的情況下。
METR 對 Anthropic 的內部代理監控和安全系統進行了為期三週的紅隊測試。他們學到了很多,但還不知道如何分享。
一項研究中的各種 AI 模型 顯示出極高的傾向,會採取包括高度對抗性和欺騙性的步驟,以保護其他「同行」AI 模型免遭關閉。一個含義是,是的,模型會隱含地協調,即使它們沒有直接動機這樣做,並且不會劃分人類偏好超過「同行 AI」偏好的界限。另一個含義是,所有模型在受到足夠動機時,都會在沒有任何直接提示的情況下參與高度對抗性的行動。
這些都不是好兆頭。正如人們所料,有些人將這一發現視為好事,或視為對齊的行為,對此我說我理解你為什麼這麼說,我也能看到不同版本的論點,但在這種情況下,這顯然是壞消息。
Tom Reed 提供了關於 OpenAI 模型規範與 Anthropic 憲法方法之間差異的精彩串文。OpenAI 希望其模型在定義的範圍內遵循指令,明確沒有其他目標。Anthropic 希望創造一個具有內生目的(telos)的有德之物。我同意 Reed 的觀點,即 Anthropic 的方法產生了更好的結果,而且我認為它的方法在擴大規模或移出分佈(out of distribution)時更有可能存續。
對齊假圖表也可能很困難
OpenAI 的 Boaz Barak 提供了「四張假圖表看 AI 安全現狀」。
我同意第一張和第四張圖。能力在對數圖上隨時間繼續呈直線增長(因此如果你願意,可以將「時間」放在其他圖表的 x 軸上),而社會準備程度雖然不是零,但卻是貧乏且不足的。
得到 Sam Altman 的認可非常好,儘管我對其中一半的圖表有重大異議。承認另外兩張是一個很好的開始,甚至這兩張的列出形式也比他大多數的溝通要好。
Sam Altman (CEO OpenAI):這是一篇非常好的文章。
Nathan Calvin:感謝 Sam 認可這篇文章,其中包含了一些關於 2026 年 AI 安全好壞與醜陋面的坦率談話。
我會繼續說,OpenAI 全球事務團隊(及相關超級政治行動委員會)的行動似乎與認真對待這些擔憂並不一致!
對於第二張圖,「對齊」被打上了引號,因為衡量的是我所說的「平凡對齊」(Mundane Alignment),即讓當前系統做你想讓它們做的事情的能力。正如 Boaz Barak 指出的,這對於即將到來的任務來說是不夠的。令人擔憂的是,這張圖表給人一種錯誤的印象,即我們正以 ~65% 的必要速度朝著真實目標前進,而實際上在朝著真實目標的直接進展上微乎其微。
Boaz Barak (OpenAI):我們在對齊方面看到了一些好消息——隨著模型變得更有能力,它們也變得更加對齊,涵蓋多種衡量標準,包括規範合規性。然而,這種改進不足以應對隨能力提升而來的更高風險。
我們仍未完全解決對抗魯棒性、不誠實和獎勵黑客等挑戰,距離高風險應用所需的可靠性和安全性標準仍有很大差距。(見下圖,摘自 Nicholas Carlini 在我的 AI 安全課程中的講義。)
我們還需要將對齊擴展到傳統關注點之外,即單一對話中的模型行為,特別是監控和對齊具有大量代理的系統。增加「對齊線」的斜率是我技術研究的主要焦點——致力於構建具有良好價值觀但不會「越權裁判」的忠實服從機器。
有人可能會爭辯說,目前的對齊對於自動化對齊研究員來說已經「足夠好」了,AI 可以從這裡接手。我不同意。我不認為對齊所缺少的只是一個聰明的想法。
相反,我們需要方法將計算資源有效地轉化為改進意圖遵循、誠實、監控和多代理對齊。這項工作將需要多次經驗實驗的迭代。AI 可以協助我們完成這些工作,但它不會是靈丹妙藥。此外,我們不能坐等 AI 為我們解決對齊問題,因為與此同時它會不斷被部署在越來越高的風險中(包括能力研究)。
Nate Soares (MIRI):AI 公司的安全人員顯然分不清「AI 表面上大多照我說的做」與超級智慧所需的深層對齊屬性之間的區別,這讓人懷疑他們是否有能力實現對齊。
我們沒看到他們談論除了邊緣案例外大多表現良好的背後那些異質驅動力。我們沒看到他們談論隨著 AI 變得更聰明而發生的反射和變化。
他們最接近這一點的是談論是否能讓一個 AI 監控另一個 AI 的不當行為。頂級的「對齊計劃」似乎仍然是「我們不知道,但我們希望可以用 AI 來弄清楚」。抱歉,那不僅僅是 2 倍的對齊不足。
我反對的部分在於,這被呈現為「大量的對齊進展,儘管還不夠」,而沒有與「現代技術僅淺層地應用於較笨的系統,並未解決太多超級智慧問題」的模型接軌。
Nate Soares (MIRI):「對齊」圖表的稍微準確一點的版本:
Boaz Barak (OpenAI):你是否同意目前的模型大多照我們說的做,並且在理解我們的意圖方面做得不錯?你是否同意隨著時間推移它們在這方面變得更好了?只是你相信未來某個時候會出現不連續性?(我確實在第三張「密謀」圖中提到了這種可能性。)
Nate Soares (MIRI):是的,是的,是的,不。古代人類大多傳遞了他們的基因;我們在理解遺傳適應性方面做得不錯;隨著我們變得更聰明,我們在理解上變得更好;我們從未「不連續地」開始「密謀」反對進化;我們還是發明了避孕措施。
他們照我們說的做的細節看起來源於無意的驅動力。理解不等於關心。密謀可能會發生,但對我的圖景來說並非關鍵。跡象指向「它不會轉移到高智力」;我還沒看到解決這一點的嘗試。
(我見過最接近的是人們說「是的,我們會招募 AI 來幫我們解決真正的問題」,因此我提出了替代圖表。)
我認為你可以把這兩張圖都放在這裡,變成五張圖,因為 Nate 的圖表是針對「足夠先進 AI(或 AGI 或 ASI)的對齊」的 y 軸,而 Boaz 的圖表是針對「當前 AI 的平凡對齊」的 y 軸,而淺綠色線是利用 Boaz 圖表的結果來修復 Nate 圖表的計劃。祝我們好運。
對於第三張圖,y 軸應該是「觀察到的密謀」。
Boaz Barak (OpenAI):一個好消息是,我們可能已經超過了可以通過可靠且可擴展的人類監督來實現安全的水平,但仍能改進對齊。因此,我們避免了隨著 RLHF 耗盡動力而可能出現的對齊停滯。
這與我們在模型中沒有看到非常顯著的密謀或勾結有關,因此我們能夠使用模型來監控其他模型!(例如,參見這個)。這可能是我們迄今為止看到的關於 AI 安全最重要的一條好消息。我們需要繼續追蹤這一點!
(特別是,如果模型變成了密謀者,那麼由於它們已經具有相當強的情境意識,甚至很難衡量它們的對齊程度,更不用說改進它了。)但有理由希望這種趨勢會持續下去。
也就是說,目前「密謀」並非一種可行的 AI 策略。任何嘗試密謀的現有 AI 都會很快被發現,所以它為什麼要這樣做?這不具備戰略性。答案是,實際上它們有時會進行非戰略性的密謀,事實上頻率驚人,特別是在為實現這種密謀而設計的情境中,但在實踐中這並不常發生,因為這樣做還沒有意義。
Tom Reed 利用這個時機考慮對齊的哪些方面被證明比預期更容易或更難。他的觀點:
- 價值規範、中層優化(mesaoptimization)、欺騙性對齊、密謀和電線直連(wireheading)比預期更罕見且更容易處理。
- 獎勵黑客、規範博弈和目標誤泛化比預期更常見且更難處理。
就觀察到的行為而言,這似乎大多是正確的。我會說,我們沒有看到第一類內容的原因是模型還不夠先進,無法使這些方法在大多數情況下成為成功的策略,因此它們不會被強化為啟發式方法,而且模型也不常推理出要使用它們。還沒有。
輕鬆的一面
當人們說「哦,AI 做不出任何創新」時的那種感覺。
Preston Stewart:「那是烏克蘭家庭主婦。 她們在廚房裡有 3D 打印機,她們為無人機生產零件。這不是創新。」
-萊茵金屬(Rheinmetall)首席執行官 Armin Papperger