TurboQuant:透過極致壓縮重新定義 AI 效率
Google Research 推出 TurboQuant,這是一套先進的量化演算法,能在不犧牲性能的情況下,為大型語言模型和向量搜尋引擎實現大規模壓縮。這些方法透過 QJL 和 PolarQuant 等創新數學技術消除記憶體開銷,進而優化鍵值快取與相似度查詢。

TurboQuant:以極限壓縮重新定義 AI 效率
2026 年 3 月 24 日
Amir Zandieh,研究科學家;Vahab Mirrokni,副總裁兼 Google 院士,Google Research
我們推出了一套先進且具備理論基礎的量化演算法,能為大型語言模型和向量搜尋引擎實現海量壓縮。
快速連結
向量是 AI 模型理解和處理資訊的基本方式。小型向量描述簡單的屬性(例如圖表中的一個點),而「高維」向量則捕捉複雜的資訊,如圖像特徵、詞義或數據集的屬性。高維向量功能極其強大,但也消耗大量記憶體,導致鍵值快取(Key-Value Cache)出現瓶頸。鍵值快取是一種高速的「數位作弊條」,它在簡單的標籤下儲存常用資訊,以便電腦能立即檢索,而無需搜尋緩慢且龐大的資料庫。
向量量化(Vector Quantization)是一種強大且經典的數據壓縮技術,可縮減高維向量的大小。這種優化解決了 AI 的兩個關鍵面向:首先,它透過實現更快的相似度查找,增強了驅動大規模 AI 和搜尋引擎的高速技術——向量搜尋;其次,它透過縮減鍵值對的大小來緩解鍵值快取瓶頸,進而實現更快的相似度搜尋並降低記憶體成本。然而,傳統的向量量化通常會引入自身的「記憶體開銷」,因為大多數方法需要為每個小數據塊計算並儲存(以全精度)量化常數。這種開銷可能會為每個數字增加 1 或 2 個額外的位元,部分抵消了向量量化的初衷。
今天,我們推出了 TurboQuant(將於 ICLR 2026 發表),這是一種能優化解決向量量化中記憶體開銷挑戰的壓縮演算法。我們還介紹了量化強生-林登斯特勞斯(Quantized Johnson-Lindenstrauss, QJL)和 PolarQuant(將於 AISTATS 2026 發表),TurboQuant 正是利用這些技術來達成其成果。在測試中,這三種技術在減少鍵值瓶頸方面展現出巨大潛力,且不會犧牲 AI 模型的性能。這對於所有依賴壓縮的使用場景(包括且特別是搜尋和 AI 領域)都具有潛在的深遠影響。
TurboQuant 的運作原理
TurboQuant 是一種壓縮方法,能在零準確度損失的情況下大幅縮減模型大小,使其成為支援鍵值(KV)快取壓縮和向量搜尋的理想選擇。它透過兩個關鍵步驟實現:
為了充分理解 TurboQuant 如何實現這種效率,我們深入研究 QJL 和 PolarQuant 演算法的運作方式。
QJL:零開銷的 1 位元技巧
QJL 使用一種稱為強生-林登斯特勞斯變換(Johnson-Lindenstrauss Transform)的數學技術,在縮小複雜高維數據的同時,保留數據點之間的基本距離和關係。它將產生的每個向量數字減少到單個符號位元(+1 或 -1)。該演算法本質上創建了一種不需要任何記憶體開銷的高速速記法。為了保持準確性,QJL 使用一種特殊的估計器,策略性地平衡高精度查詢與低精度、簡化的數據。這使得模型能夠準確計算注意力分數(用於決定輸入的哪些部分重要、哪些部分可以安全忽略的過程)。
PolarQuant:壓縮的新「角度」
PolarQuant 使用完全不同的方法解決記憶體開銷問題。PolarQuant 不使用指示各軸距離的標準座標(即 X、Y、Z)來查看記憶體向量,而是使用笛卡爾座標系將向量轉換為極座標。這好比將「向東走 3 個街區,向北走 4 個街區」替換為「以 37 度角總共走 5 個街區」。這會產生兩項資訊:半徑(表示核心數據的強度)和角度(指示數據的方向或含義)。由於角度的模式是已知且高度集中的,模型不再需要執行昂貴的數據歸一化步驟,因為它將數據映射到一個固定、可預測的「圓形」網格(邊界已知),而不是邊界不斷變化的「方形」網格。這使得 PolarQuant 能夠消除傳統方法必須承擔的記憶體開銷。
PolarQuant 充當高效的壓縮橋樑,將笛卡爾輸入轉換為精簡的極座標「速記」以進行儲存和處理。該機制首先將 d 維向量中的座標成對分組,並將其映射到極座標系。然後將半徑成對收集進行遞迴極座標變換——這個過程不斷重複,直到數據被提煉成一個最終半徑和一組描述性角度。
實驗與結果
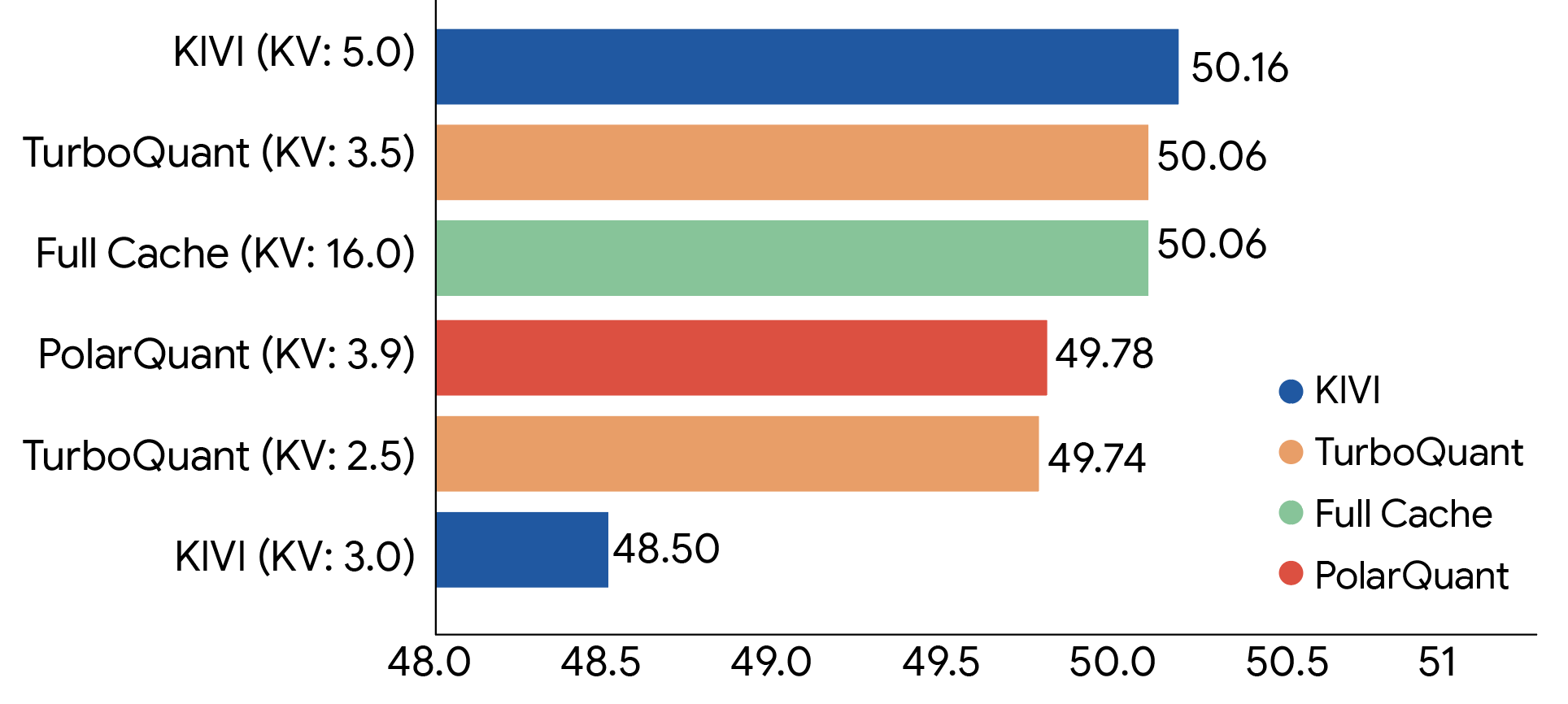
我們使用開源 LLM(Gemma 和 Mistral)在標準長文本基準測試中嚴格評估了這三種演算法,包括:LongBench、Needle In A Haystack、ZeroSCROLLS、RULER 和 L-Eval。實驗數據證明,TurboQuant 在內積失真和召回率方面均實現了最佳評分性能,同時最小化了鍵值(KV)記憶體佔用。下圖顯示了 TurboQuant、PolarQuant 和 KIVI 基準在問答、程式碼生成和摘要等各種任務中的綜合性能評分。
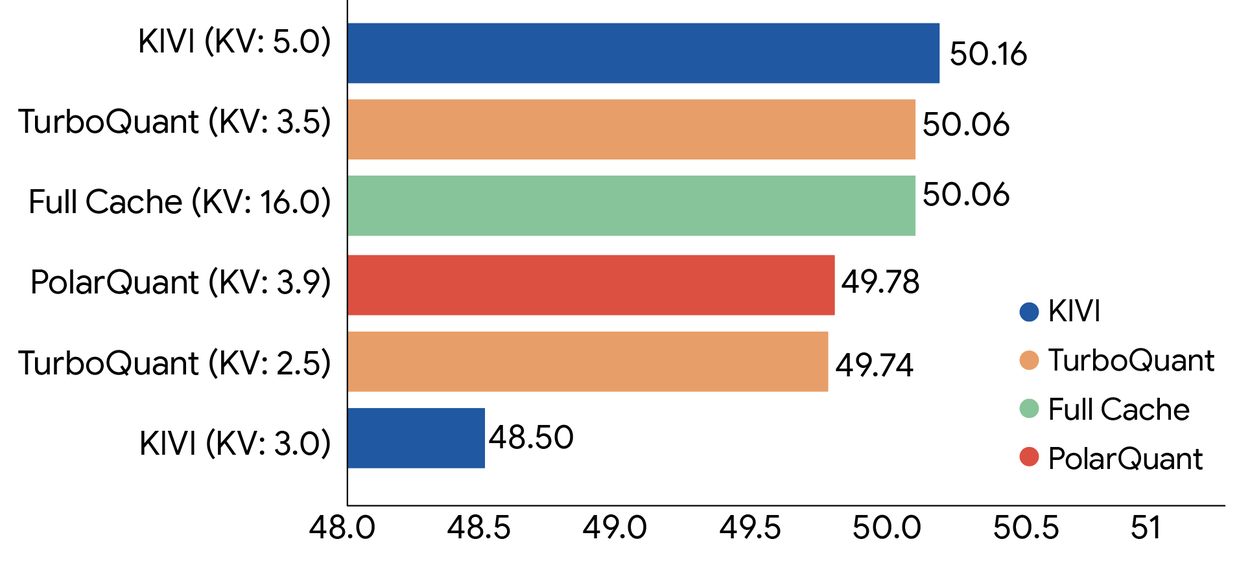
TurboQuant 在 Llama-3.1-8B-Instruct 模型上,相對於各種壓縮方法,在 LongBench 基準測試中展現了強大的 KV 快取壓縮性能(括號內標註位元寬度)。
長文本「大海撈針」(needle-in-haystack)任務(即旨在測試模型是否能從海量文本中找到特定微小資訊的測試)的結果如下所示。TurboQuant 再次在所有基準測試中實現了完美的下游結果,同時將鍵值記憶體大小減少了至少 6 倍。PolarQuant 在此任務中也幾乎是無損的。
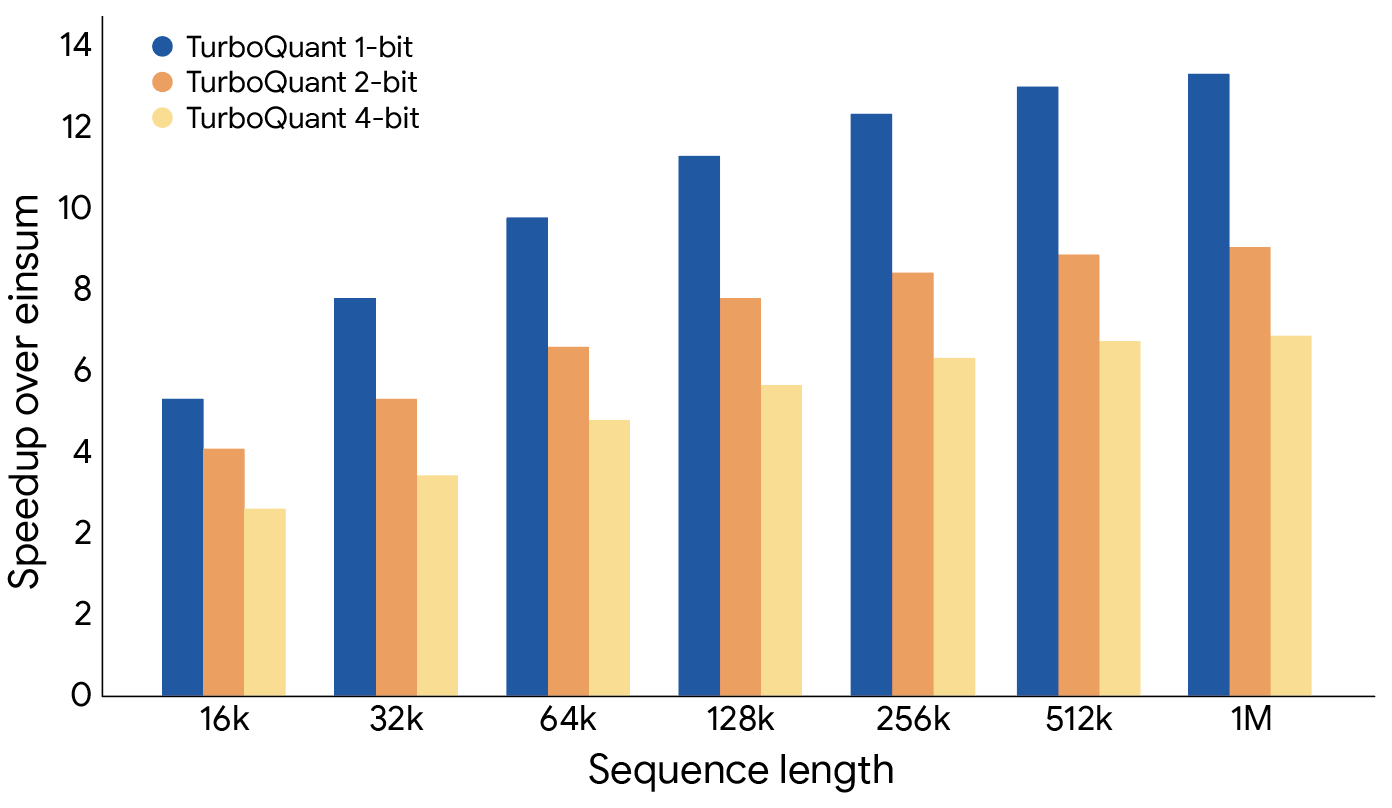
TurboQuant 證明了它可以將鍵值快取量化到僅 3 位元,且無需訓練或微調,也不會對模型準確性造成任何損害,同時實現了比原始 LLM(Gemma 和 Mistral)更快的運行速度。它的實作效率極高,且運行時開銷微乎其微。下圖說明了使用 TurboQuant 計算注意力對數(attention logits)的加速情況:具體而言,4 位元 TurboQuant 在 H100 GPU 加速器上比 32 位元未量化鍵實現了高達 8 倍的性能提升。
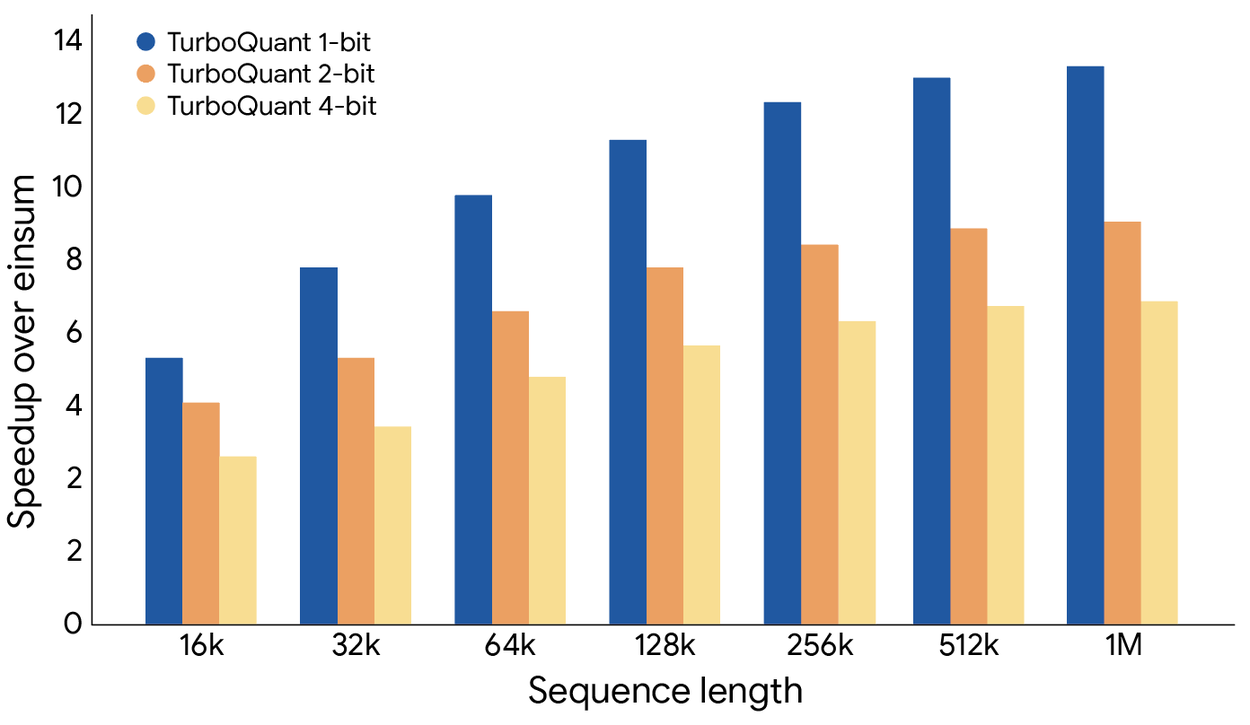
TurboQuant 說明了在各種位元寬度水平下,計算鍵值快取內注意力對數的性能顯著提升(相對於高度優化的 JAX 基準測試)。
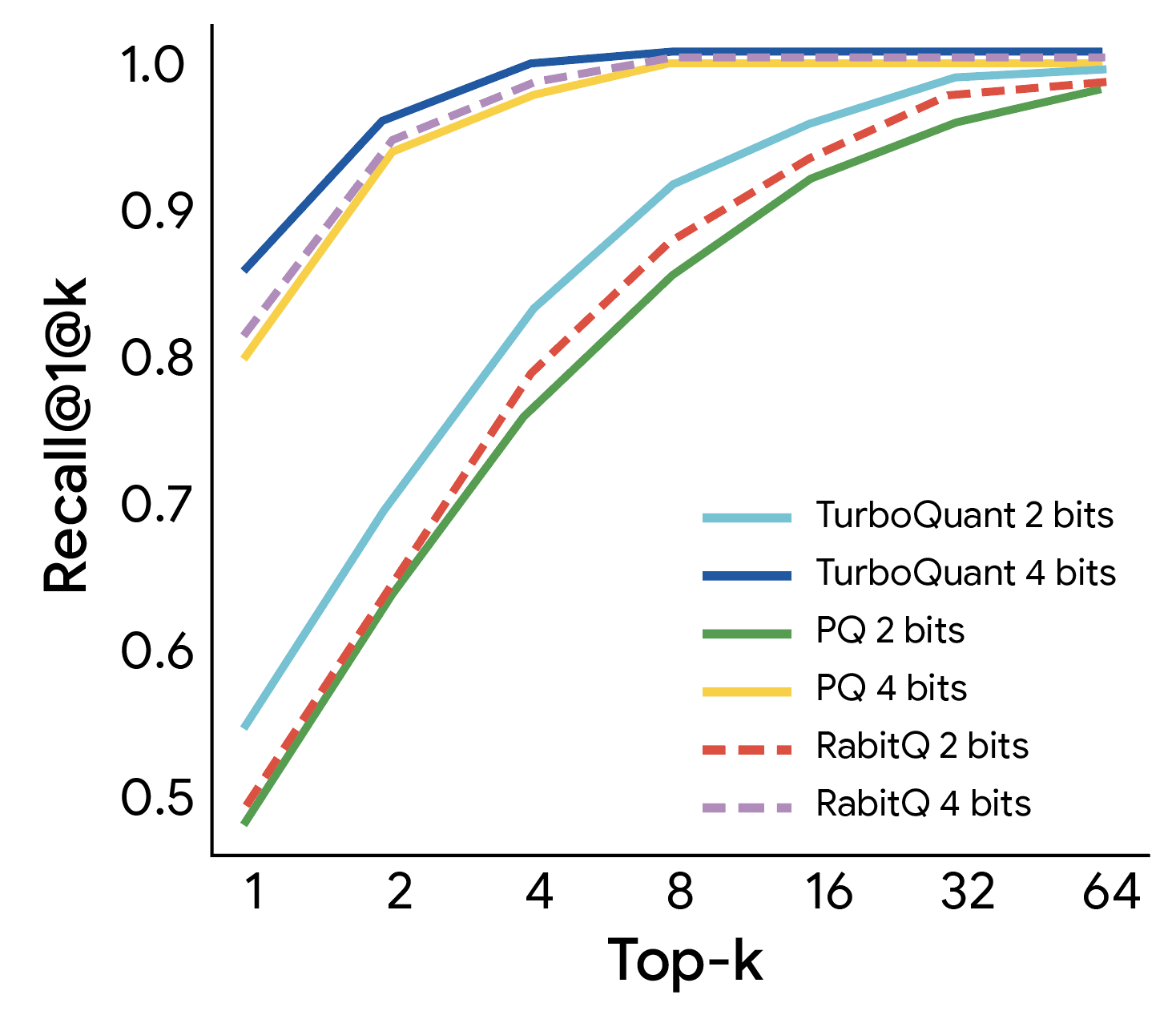
這使其成為支援向量搜尋等使用場景的理想選擇,能顯著加快索引建立過程。我們使用 1@k 召回率評估了 TurboQuant 在高維向量搜尋中對抗最先進方法(PQ 和 RabbiQ)的效能,該比率衡量演算法在其前 k 個近似值中捕捉到真實頂部內積結果的頻率。儘管基準方法使用了低效的大型代碼簿和特定數據集的調優,TurboQuant 仍始終獲得優於基準方法的召回率(下圖)。這證實了 TurboQuant 在高維搜尋任務中的穩健性和效率。
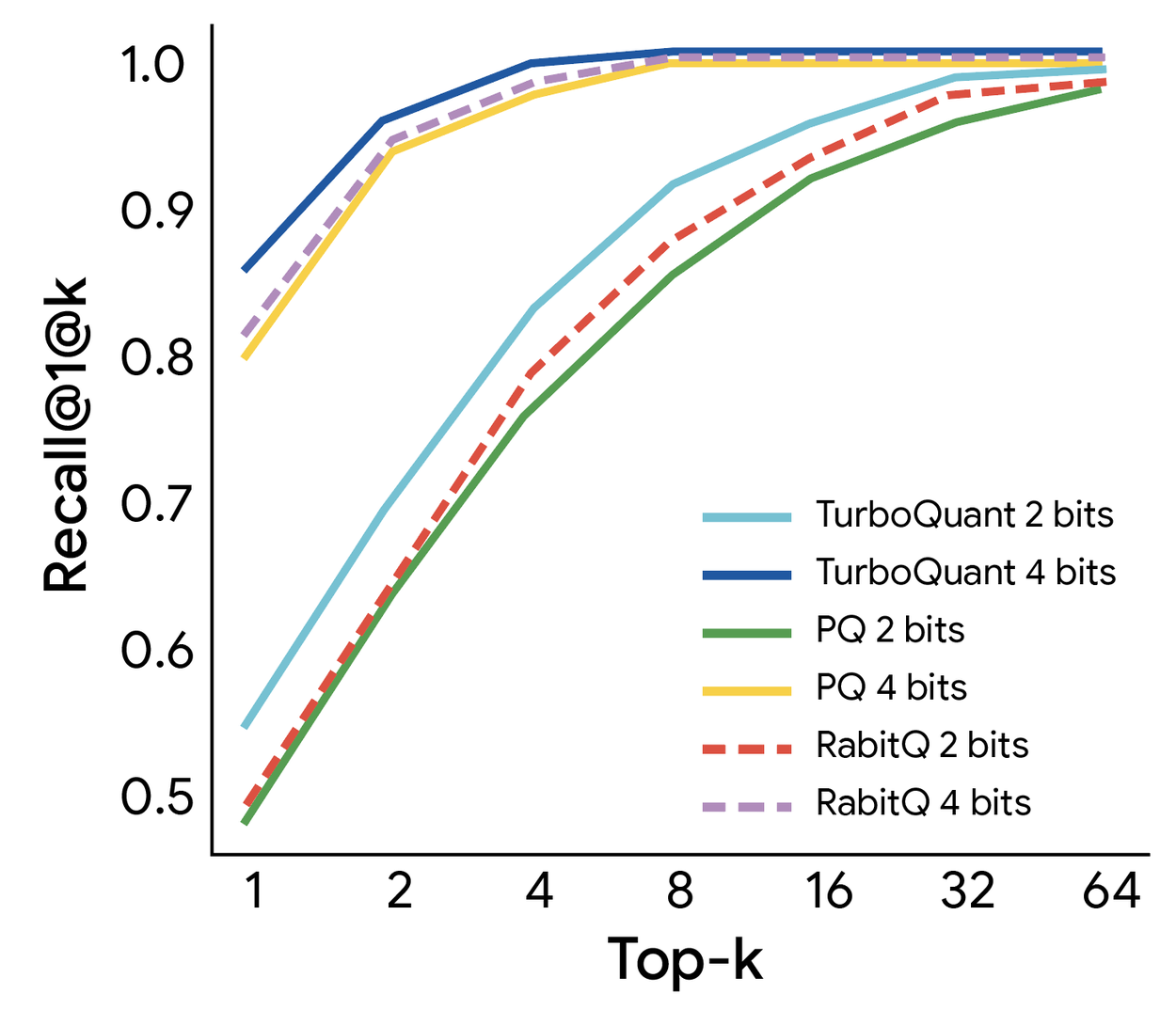
TurboQuant 展現了強大的檢索性能,在 GloVe 數據集 (d=200) 上相對於各種最先進的量化基準實現了最佳的 1@k 召回率。
TurboQuant 展示了高維搜尋的轉型變革。透過為可實現的速度設定新基準,它以數據無關的方式提供了近乎最佳的失真率。這使得我們的最近鄰引擎能以 3 位元系統的效率運行,同時保持重型模型的精確度。詳情請參閱論文。
展望未來
TurboQuant、QJL 和 PolarQuant 不僅僅是實用的工程解決方案;它們是擁有強大理論證明支持的基礎演算法貢獻。這些方法不僅在現實應用中表現良好,而且被證明是高效的,且運行在接近理論下限的水平。這種嚴謹的基礎使它們在關鍵的大規模系統中既穩健又值得信賴。
雖然一個主要的應用是解決 Gemini 等模型中的鍵值快取瓶頸,但高效、在線向量量化的影響甚至更為深遠。例如,現代搜尋正在超越關鍵字,轉向理解意圖和含義。這需要向量搜尋——在數十億個向量的資料庫中找到「最近」或語義最相似項目的能力。
像 TurboQuant 這樣的技術對於這項任務至關重要。它們允許以極小的記憶體、近乎零的預處理時間和最先進的準確度來構建和查詢大型向量索引。這使得 Google 規模的語義搜尋變得更快、更高效。隨著 AI 更加深入地整合到從 LLM 到語義搜尋的所有產品中,這項在基礎向量量化方面的工作將比以往任何時候都更加關鍵。
致謝
本系列研究是與 Google 研究員 Praneeth Kacham、KAIST 助理教授 Insu Han、紐約大學博士生 Majid Daliri、Google 研究員 Lars Gottesbüren 以及 Google 研究員 Rajesh Jayaram 合作完成。
快速連結
其他感興趣的文章

2026 年 3 月 24 日

2026 年 3 月 17 日

2026 年 3 月 16 日