2026 年初人工智慧安全現狀:四張虛擬圖表背後的分析
我評估了當前人工智慧安全的現狀,指出雖然模型能力和對齊技術正在進步,但社會準備程度和制度治理仍然嚴重滯後。一個關鍵的好消息是我們已能成功利用人工智慧來監控其他人工智慧系統,儘管對抗魯棒性和欺騙行為等挑戰依然存在。
以下是我對 2026 年初 AI 安全現狀直覺看法的快速概覽:
**
-
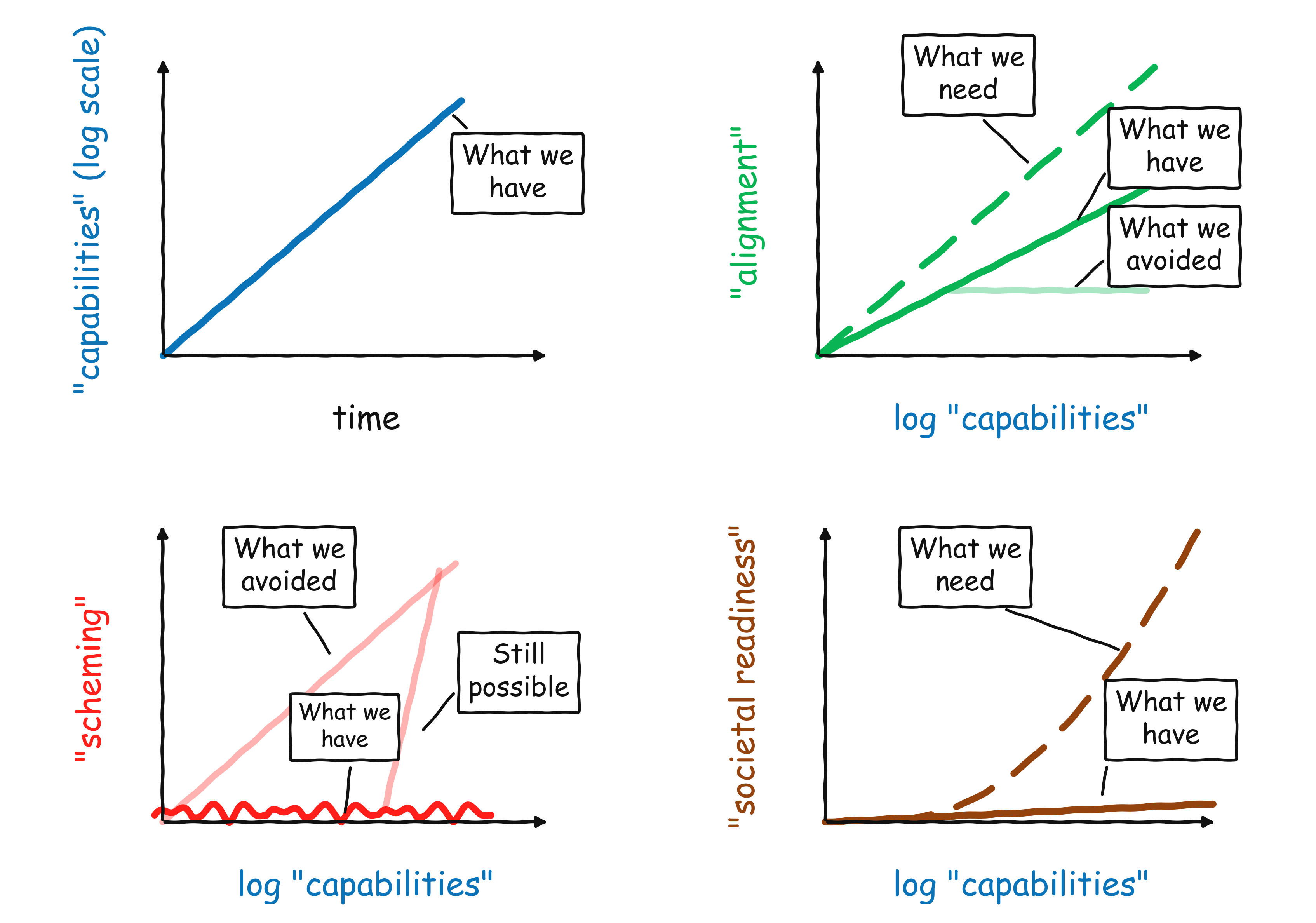
到目前為止,我們持續看到能力的指數級提升。這在著名的「METR 圖表」中表現得最為明顯,但這種趨勢在許多其他指標中也很清晰,包括營收。如果你仔細觀察,甚至可以看到曲線近期有「向上彎曲」的潛力,因為我們正開始利用 AI 來加速 AI 的開發。
-
我們在對齊(alignment)方面看到了一些好消息——隨著模型能力增強,它們在多項衡量標準下也變得更加對齊,包括規範合規性。然而,這種進步還不足以應對能力提升所帶來的更高風險。我們仍未完全解決對抗性魯棒性(adversarial robustness)、不誠實和獎勵操縱(reward hacking)等挑戰,且距離高風險應用所需的可靠性與安全性標準仍有很大差距。(參見我 AI 安全課程中 Nicholas Carlini 講座的投影片。)我們還需要將對齊研究擴展到傳統焦點之外(即孤立對話中的模型行為),特別是監控和對齊擁有大量代理(agents)的系統。增加「對齊線」的斜率是我技術研究的主要焦點——致力於構建具有良好價值觀但不會「越權立法」的忠實服從機器。
有人可能會認為,目前的對齊程度對於自動化對齊研究員來說已經「足夠好」了,AI 可以從這裡接手。我不同意。我不認為對齊所欠缺的只是一個聰明的點子。相反,我們需要方法來有效地擴展計算規模,以改進意圖遵循、誠實性、監控和多代理對齊。這項工作需要多次經驗實驗的迭代。AI 可以協助我們完成這些工作,但它不會是萬靈丹。此外,我們承擔不起等待 AI 為我們解決對齊問題的代價,因為與此同時,AI 將不斷被部署在風險越來越高的領域(包括能力研究)。
-
一個好消息是,我們雖然可以說已經超越了僅靠可靠且可擴展的人類監督來實現安全的階段,但仍能提升對齊程度。因此,我們避免了在 RLHF(人類回饋強化學習)後勁不足時可能出現的對齊停滯。這與我們在模型中尚未觀察到非常顯著的陰謀(scheming)或勾結有關,因此我們能夠使用模型來監控其他模型!(例如,參見此處)。這或許是我們目前在 AI 安全方面看到的最重要好消息。我們需要持續追蹤這一點!(特別是,如果模型變成了陰謀家,由於它們已經具備相當強的情境覺知能力,屆時甚至很難衡量它們的對齊程度,更不用說改進了。)但我們有理由希望這種趨勢能持續下去。
-
最壞的消息是,社會還沒準備好迎接 AI,也沒有表現出準備好的跡象。無論是面對生物和網絡領域日益增強的能力(包括開源模型能力的提升)、為經濟衝擊做準備、制定保護民主和個人賦權的法規(例如,避免出現像數據中心裡的國稅局特工國家這樣的情境),還是 AI 安全的國際合作,我們的政府和機構都未能應對挑戰。這或許是支持「AI 暫停」的最佳論據,但 (a) 我不認為這種暫停是可行或務實的,且 (b) 我不相信政府會明智地利用這段時間——經驗顯示,政府無所作為的能力是很難被高估的。