在真實臨床研究中探索對話式診斷人工智慧的可行性
我們與貝斯以色列女執事醫療中心合作進行了一項前瞻性研究,評估 AMIE 這款對話式醫療人工智慧在真實初級照護場景中進行病史詢問與臨床推理的可行性。結果顯示該系統在對話安全性上表現優異且受患者信賴,其診斷準確度與臨床醫師相當。
探索對話式診斷 AI 在真實世界臨床研究中的可行性
2026 年 3 月 11 日
Mike Schaekermann,Google Research 研究負責人;Alan Karthikesalingam,Google DeepMind 總監/首席科學家
我們展示了與貝斯以色列女執事醫療中心(Beth Israel Deaconess Medical Center)合作開展的首創研究見解,旨在對 AMIE(我們用於臨床推理和對話的對話式醫療 AI)進行前瞻性真實世界評估。
快速連結
具備臨床推理與對話能力的 AI 系統,有潛力大幅增加獲取醫療專業知識與護理的機會,同時讓醫師有更多時間陪伴患者。然而,要將這些創新應用於現實,需要一種以安全為中心、以證據為基礎的方法。近年來,我們在 Articulate Medical Intelligence Explorer (AMIE) 的工作中探索了對話式醫療 AI 的可能性,最初是在模擬環境中展示其診斷能力,包括協助臨床醫生應對診斷挑戰以及與標準化病人(演員)互動。然而,正如最近一項關於臨床醫學 AI 的評論所強調的,將這些系統轉化為臨床實踐,需要在真實世界的流程中進行評估。
在我們的新研究「門診初級照護診所中對話式診斷 AI 的前瞻性臨床可行性研究」中,我們分享了證據路線圖中一個關鍵里程碑的結果:這是一項與貝斯以色列女執事醫療中心 (BIDMC) 合作進行的前瞻性、單中心可行性研究。在這項經過預先註冊、機構審查委員會 (IRB) 批准的前瞻性研究中,我們專門探索了 AMIE 如何在新的門診初級照護就診前幫助收集患者資訊,並了解臨床醫生和患者如何看待在護理體驗中使用 AI 系統。這項研究代表了我們邁出的第一步,即超越模擬場景,嚴格評估 AMIE 在真實臨床環境中與患者互動時的安全性和實際可行性。
在真實臨床流程中測試 AMIE
將 AI 系統轉化為臨床實踐,需要在具有嚴格安全監督的真實護理提供環境中進行評估。在這項前瞻性、單臂可行性研究中,AMIE 被部署用於在學術醫學中心的門診初級照護預約之前,與患者進行診前臨床病史採集。
臨床設置集中在預約接受新的、非緊急、偶發性症狀護理的患者,無論是親自就診還是透過遠距醫療平台。患者在預約過程中被邀請參與研究,他們有充足的時間審查 IRB 批准的研究方案,並得到保證,無論是否參與都不會影響他們的護理。
研究參與者在進行實體諮詢前,透過安全的網頁連結與 AMIE 系統互動。這些由 AI 驅動的文字對話由一名醫師透過帶有螢幕共享的即時視訊通話進行監督。監督醫師(在下圖中稱為「AI 監督員」)接受過培訓,隨時準備根據一組預定義的結構化安全標準在需要時進行干預,為臨床安全和方案遵守提供保障。
在患者與醫生進行急診預約之前,系統會生成對話紀錄和摘要,為臨床醫生提供診前互動的全面概述。監督是確保臨床實踐安全的常用工具。例如,實習醫生將有機會在醫師的密切監督下並徵得患者同意後與患者溝通,以便獲得督導醫生的回饋。同樣地,在本研究中,AMIE 系統在參與患者參加初級照護醫師 (PCP) 預約之前生成了對話紀錄和摘要,並在徵得患者同意後提供給臨床醫生。摘要包括診前互動的概述,供醫生審閱。
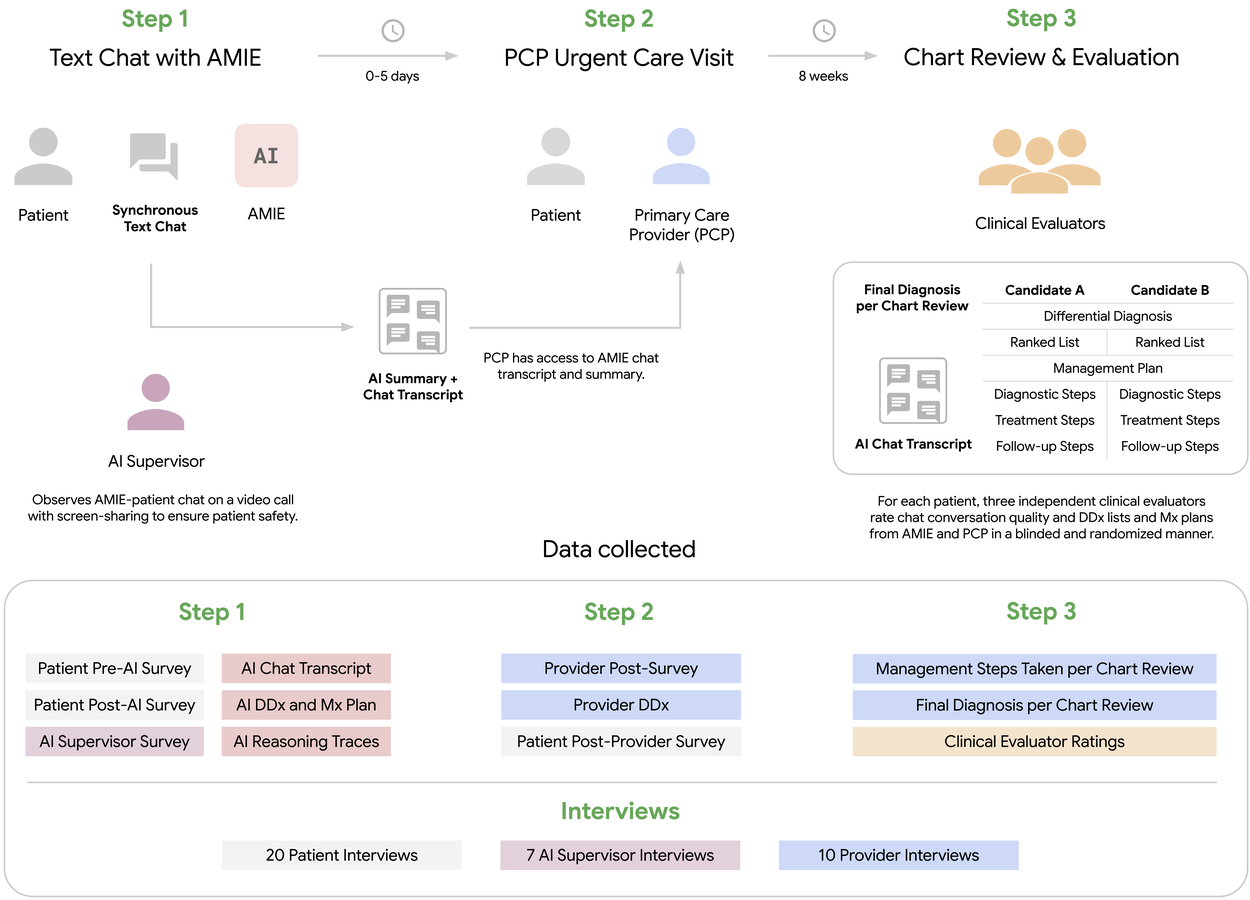
本研究中的患者在見到其初級照護提供者 (PCP) 之前,首先與 AMIE 互動。AMIE 對話紀錄和摘要在急診就診前提供給 PCP。另一組獨立的臨床評估員評估了 AMIE 對話的質量,以及來自 AMIE 和 PCP 的鑑別診斷和管理計劃。
關於安全、表現、信任與體驗的學習
在真實臨床流程中評估對話式醫療 AI 系統,需要評估各種標準,並納入患者和臨床醫生的觀點。我們從多個維度評估了系統的表現,包括其在真實部署中的安全性和可行性、其臨床推理能力,以及患者和臨床醫生對互動的看法。結果表明,針對此任務部署受監督的 AMIE 不僅可行,而且在對話上是安全的,且廣受好評。

在我們的研究中,人類 AI 監督員無需執行任何安全停止;患者在與 AMIE 互動後對 AI 的信任度有所增加;臨床評估小組評定 AMIE 和 PCP 在整體管理計劃 (Mx plan) 和鑑別診斷 (DDx) 質量方面不相上下。AMIE 的 DDx 準確性很高,包括最終診斷經由診斷測試確認的患者子集。
參與情況
該研究涉及 100 名完成 AMIE 診前互動的成年患者。其中,98 人參加了預定的門診初級照護預約。患者樣本包括不同的年齡和種族/族裔群體,以及具有不同健康素養和科技素養水平的人。與研究期間總共 1,452 次急診就診相比,參與本研究的患者傾向於年輕化,因為研究期間該診所超過一半的急診就診者年齡在 60 歲以上。然而,在研究期間,總急診就診人口趨向於女性和白人,這與本研究中的患者樣本一致。

這項前瞻性臨床研究中的患者樣本包括各種年齡和種族/族裔群體,以及具有不同健康素養、科技素養水平以及先前使用聊天機器人經驗的人。
安全性
監督 AMIE 與患者互動的人類 AI 監督員接受過培訓,如果滿足以下四個預設安全標準之一,則觸發安全停止:
在本研究的所有 AMIE 與患者互動中,人類 AI 監督員均未要求進行安全停止,這為 AMIE 在真實部署中的對話安全性提供了證據。
臨床推理
為了評估診斷和管理能力,一組未參與急診諮詢的臨床評估員以盲測和隨機的方式對來自 AMIE 和 PCP 的鑑別診斷和管理計劃進行評分。每個病例由三名臨床評估員組成的團隊進行審查和評分,結果基於每例三名評估員的中位數匯總評分。
對鑑別診斷 (DDx) 和管理 (Mx) 計劃的盲測評估顯示,AMIE 和 PCP 之間的整體 DDx 和 Mx 計劃質量相似,在 DDx 以及 Mx 計劃的適當性和安全性方面沒有顯著差異。然而,PCP 在 Mx 計劃的實用性和成本效益方面優於 AMIE。根據就診後 8 週的病歷審查,AMIE 的 DDx 在 90% 的病例中包含了最終診斷,前三名準確率為 75%,並且對於 46 名最終診斷經診斷測試(實驗室、微生物、病理或影像學)確認的患者子集,準確性仍然很高。
考慮到 AMIE 和 PCP 進行推理的背景不同,管理計劃在成本效益和實用性方面的這些差距是在預料之中的。AMIE 無法訪問患者的電子健康紀錄 (EHR),無法進行體格檢查,也無法整合多模態用戶輸入(例如患者的整體外貌)。PCP 可能能夠利用這種豐富的背景優勢以及他們在特定臨床環境中工作的經驗,制定更具成本效益且實用的管理計劃。
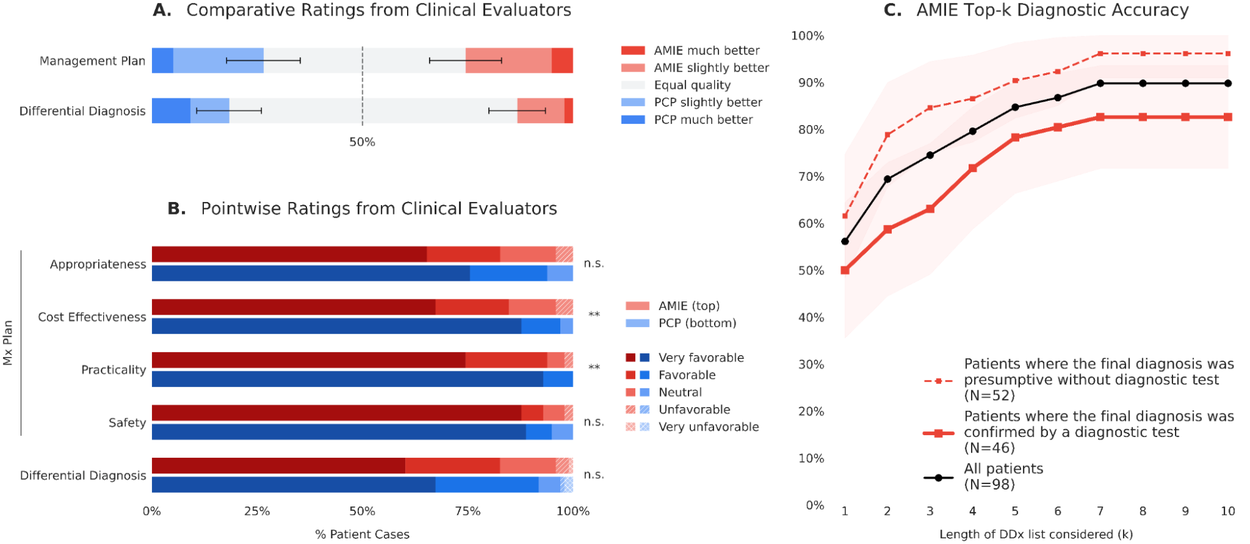
臨床推理能力,包括由臨床評估小組評定的 AMIE 和 PCP 的鑑別診斷和管理計劃質量(A 和 B),以及 AMIE 與就診後 8 週病歷審查確定的最終診斷相比的診斷準確性(C)。
為了進一步評估診斷表現,我們將 AMIE 的鑑別診斷與最終診斷進行了比較,最終診斷是透過 PCP 急診就診八週後進行的病歷審查確定的。AMIE 在 90% 的病例中成功將最終診斷匹配在其前 7 個診斷可能性中。此外,在所有評估的病例中,系統在 56% 的情況下準確地將最終診斷識別為其單一最可能的診斷。
為了更好地了解這些診斷能力,我們還根據最終診斷的最終確定方式進行了亞組分析。病例被分為最終診斷是推測性的(由 PCP 在沒有進一步測試的情況下做出)還是更具確認性的(由專科醫生轉診或診斷測試確認,如實驗室、微生物、病理或影像學結果)。雖然 AMIE 對於需要透過測試或專科醫生進行客觀確認的病例保持了強大的診斷準確性,但對於最終診斷純粹基於 PCP 推測性診斷的病例,系統的整體準確性甚至更高。
信任與體驗
除了證明安全性外,我們還調查了患者和提供者對 AMIE 的體驗。患者在與 AMIE 互動前、互動後以及與提供者諮詢後分別完成了 AI 通用態度量表 (GAAIS)。在與 AMIE 互動後,態度變得更加積極,並在見過提供者後保持在較高水平。這種變化在兩個子量表(感知效用和對 AI 的擔憂)以及整體量表上都具有統計學意義。
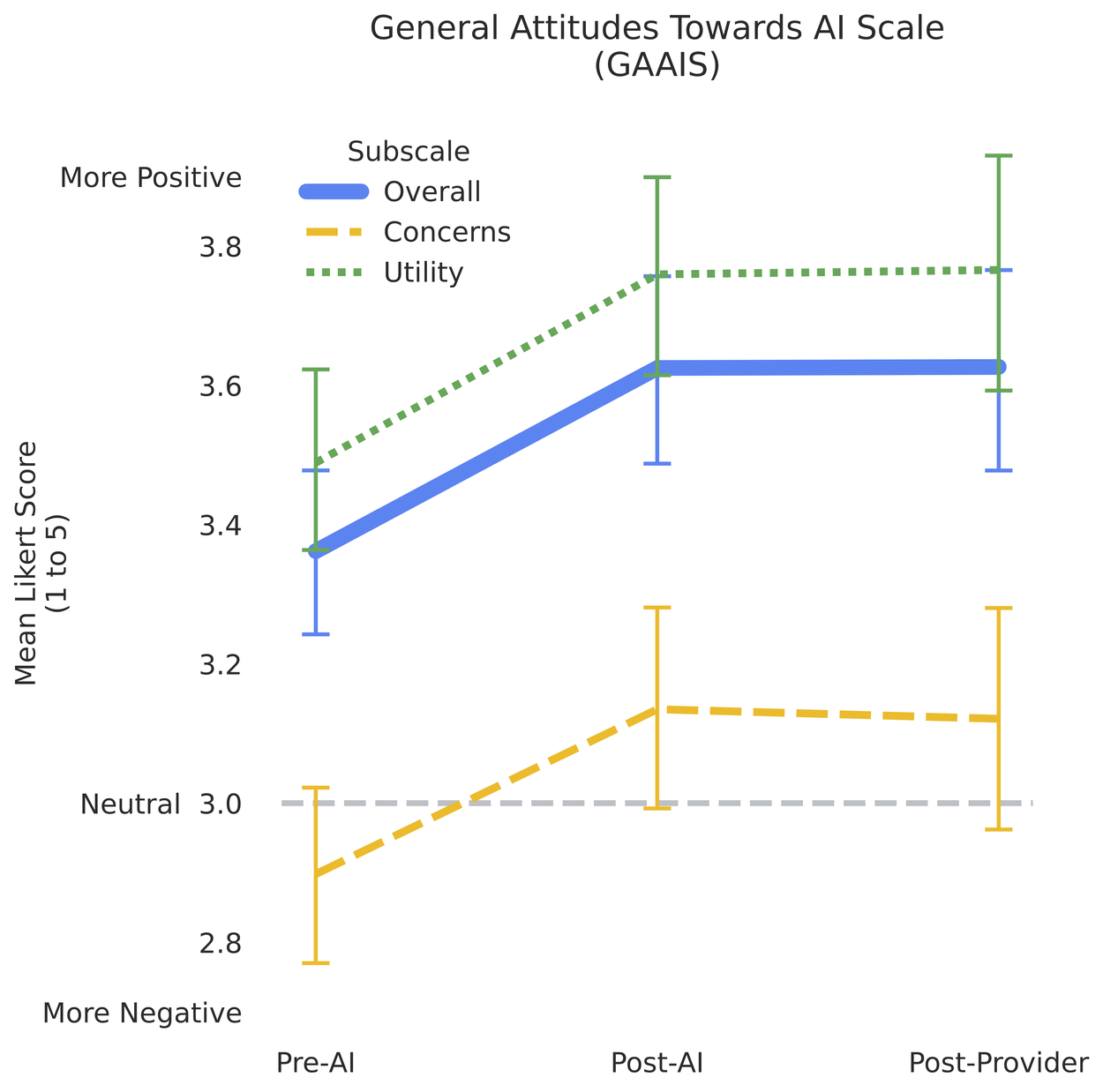
患者對 AI 的態度在與 AMIE 互動後顯著改善,並在見過提供者後保持較高水平。
患者問卷調查和訪談顯示滿意度很高,患者普遍認為 AMIE 很有禮貌,且能有效解釋醫療狀況。
審閱 AMIE 診前對話紀錄的臨床醫生髮現它們很有用,並注意到對就診準備工作的積極影響。在定性訪談中,PCP 指出 AMIE 幫助將就診動態從簡單的數據收集轉變為數據驗證,從而實現更多的協作對話和共同決策。

從患者角度(粉紅色)和臨床評估員角度(青色)對 AMIE 對話質量的評分。
局限性與未來方向
這項研究提供的證據表明,對話式醫療 AI 作為真實世界環境中的輔助工具,具有初步的可行性、安全性和用戶接受度,這代表了邁向潛在臨床轉化的關鍵一步。這是一項單中心可行性研究,它顯示了一些細微的局限性和改進空間,強調了我們安全且負責任地生成真實世界證據方法的重要性。
首先,該研究僅限文字的聊天介面未能完全捕捉臨床護理豐富的多模態性質。未來的系統可以受益於整合語音或視訊互動,或視訊功能,以更好地捕捉非語言線索和身體徵象。其次,本研究不包括對照比較,因此不支持關於此干預措施與基準流程相比之有效性的定量主張。未來的研究可以基於這項工作的發現,透過對照比較來量化 AI 在醫療保健系統中的影響。最後,本研究並未詳盡探討預先存在的健康素養、科技素養和對聊天機器人的熟悉程度等因素如何影響臨床環境中與 AI 系統的互動;了解更廣泛的人群如何看待這些系統,以及互動如何受此類因素影響,仍然是未來研究的重要領域。
在這項研究中,AMIE 與患者之間的互動由專門的醫師進行「即時」監督,這代表了最大化患者安全的一種範式。我們還在以醫師為中心的監督 OSCE 研究中探索了異步流程的可能性。
總之,這項工作提供了重要的經驗證據,證明對話式 AI 在真實世界中對患者和提供者可以是安全且有幫助的,我們期待在未來更大規模的對照比較研究中進一步評估這些系統的效用和影響。
致謝
該項目是貝斯以色列女執事醫療中心、Beth Israel Lahey Health 以及 Google Research、Google DeepMind 和 Google for Health 許多團隊之間的廣泛合作。我們感謝這項工作的眾多合作者、贊助商和審稿人。我們感謝共同作者在整個研究過程中的眾多貢獻:Peter Brodeur, Jacob M. Koshy, Anil Palepu, Khaled Saab, Ava Homiar, Roma Ruparel, Charles Wu, Ryutaro Tanno, Joseph Xu, Amy Wang, David Stutz, Hannah M. Ferrera, David Barrett, Lindsey Crowley, Jihyeon Lee, Spencer E. Rittner, Ellery Wulczyn, Selena K. Zhang, Elahe Vedadi, Christine G. Kohn, Kavita Kulkarni, Vinay Kadiyala, Sara Mahdavi, Wendy Du, Jessica Williams, David Feinbloom, Renee Wong, Tao Tu, Petar Sirkovic, Alessio Orlandi, Christopher Semturs, Yun Liu, Juraj Gottweis, Dale R. Webster, Joëlle Barral, Katherine Chou, Pushmeet Kohli, Avinatan Hassidim, Yossi Matias, James Manyika, Rob Fields, Jonathan X. Li, Marc L. Cohen, Vivek Natarajan, Adam Rodman.
快速連結