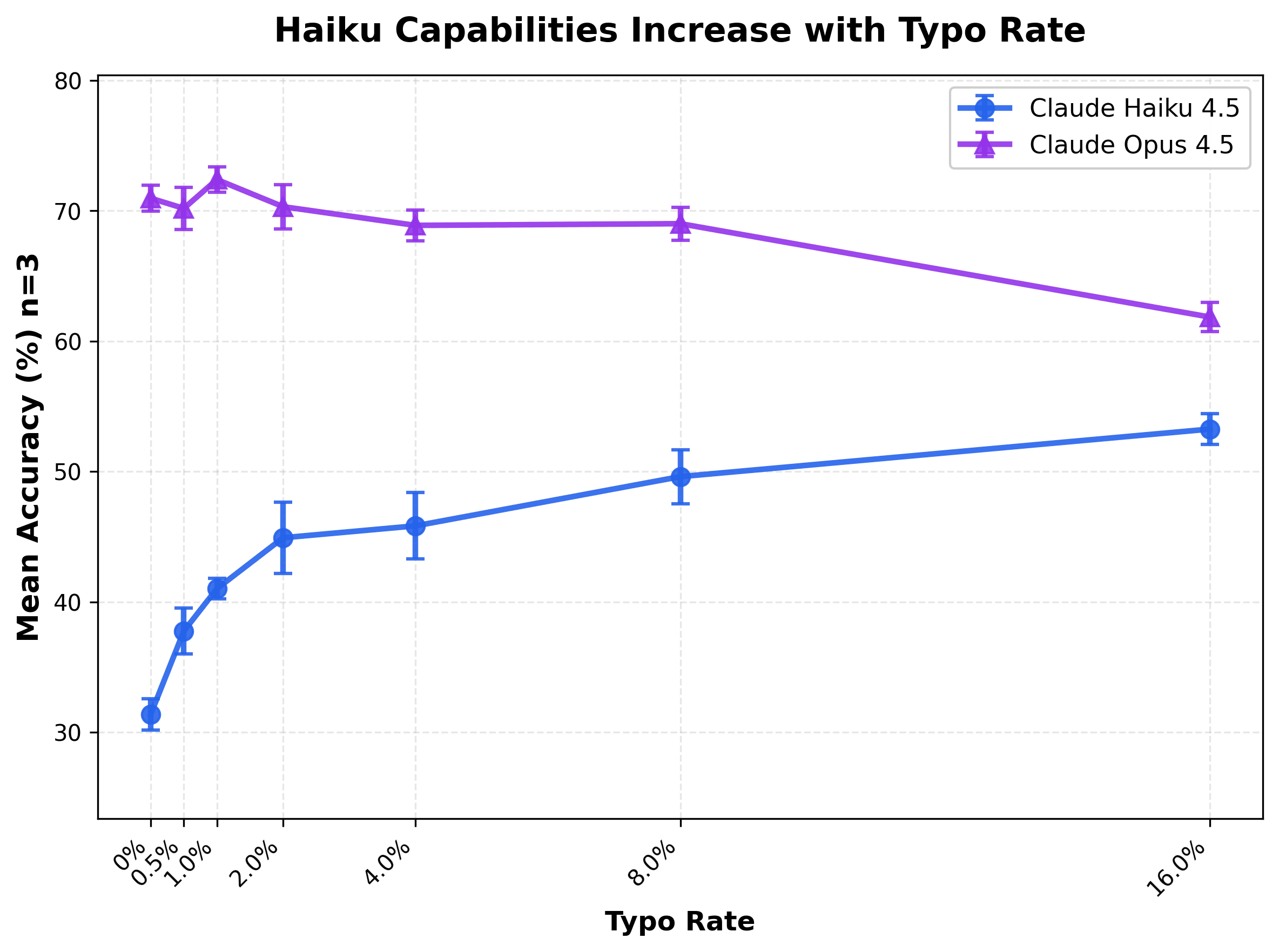
加入錯字反而提升了 Haiku 模型的準確度
我們發現隨著錯字率增加,Claude Haiku 在 BigCodeBench 上的準確度意外提升了,但深入調查後發現這並非能力增強,而是因為錯字改變了模型的輸出格式,使其剛好符合評分系統的擷取規則。
我們很好奇,當使用者提示詞包含錯字時,大型語言模型是否表現一致。為了探索這一點,我們進行了一個小實驗,在 BigCodeBench 中注入錯字,並評估了幾款 Claude 模型在雜訊程度增加時的表現。隨著錯字率上升至 16%,Opus 的準確度下降了 9%。令人驚訝的是,Haiku 的準確度反而提升了 22%。
這篇文章探討了這種意想不到的「錯字提升」(typo uplift)現象,並研究為什麼雜訊似乎對某些模型有所幫助。
錯字會讓 Haiku 更努力嗎?
我們首先假設 Haiku 的能力提升是因為難以閱讀的文本讓 Haiku 思考得更深入。這與在人類身上觀察到的結果一致:困難的字體能讓學生更好地保留知識,因為這迫使他們投入更多精力。作為精力的代理指標,我們繪製了兩個模型生成的輸出標記(tokens)數量^([1])。與我們的假設相反,輸出標記的數量隨著錯字率的增加而減少。
錯字並不會讓模型思考得更努力。隨著錯字率增加,Haiku 和 Opus 的輸出長度都會下降。
這種異常現象是 Haiku 特有的
接著我們測試了其他小型模型是否也存在這種錯字提升的異常現象。我們發現 Haiku 3.5 和 4.5 都有這種準確度隨錯字增加而提升的效果,而來自 Gemini、GPT、Qwen 和 Llama 家族的其他較小模型則沒有這種效果。
Haiku 模型的準確度隨錯字率增加而提升,而其他模型則沒有看到提升。
這種異常現象是特定於基準測試的
隨後我們測試了錯字提升異常現象是否在其他基準測試中依然存在。我們選擇了 BBH 和 GPQA Diamond,因為 Haiku 在不引入錯字的情況下表現就已經相當吃力。在這裡,我們不再觀察到錯字提升異常,Haiku 的能力隨著錯字率增加而下降。
Haiku 在 BIG-Bench Hard 和 GPQA 中的表現並未隨錯字率增加而提升,因此該效應是 BigCodeBench 特有的。
罪魁禍首
回到我們的評估日誌,我們發現對於單個 BigCodeBench 提示詞,Haiku 和 Opus 經常生成多個程式碼區塊^([2])。隨著錯字率增加,Haiku 的行為在大約 20% 的時間裡從生成多個程式碼區塊轉變為僅生成一個程式碼區塊。
進一步調查顯示,評分工具(grading harness)僅提取了最後一個程式碼區塊,跳過了之前生成的任何其他程式碼區塊。隨後我們修改了工具並評估了每一個程式碼區塊。
在考慮了多個程式碼區塊(黑色虛線)後,錯字提升異常(藍點、紫色三角形)消失了。藍色區域(單區塊正確)是指僅有一個程式碼區塊且程式碼正確的回答。一旦考慮了所有程式碼區塊,Haiku 的最終準確度就不再隨錯字率增加而提升。最初觀察到的準確度提升是由於輸出格式行為的轉變,逐漸與評分器對齊,而非實際能力的提升。
給評估工程師的啟示
並非所有評分工具都是平等的
我們認為這是關於構建評分工具的一個教訓。BigCodeBench 官方倉庫使用了一種更複雜的方法,即提取語法上有效的最長 Python 程式碼區塊,而 Inspect Evals 則明確提取第一個程式碼區塊。由於我們必須注入錯字,我們無法使用這兩種工具,因此我們構建了自己的評分工具。在不改變腳手架或底層模型的情況下,僅透過調整此工具,我們將 Haiku 的得分從 31% 「提高」到了 53%。Epoch AI 有一篇很棒的文章詳細介紹了基準測試各個部分的決策選擇如何顯著影響結果。
分數是下限
評估基礎設施中的設計選擇可能會導致模型的得分低於模型實際能達到的水平。即使我們使用 Inspect Evals 工具,我們也會因為遺漏上圖中的橙色區域而低估模型的能力。我們建議調整評估基礎設施並觀察模型性能的變化,以盡可能防止這種影響。
讓模型對齊評估
一種更穩健的評估方式是讓模型了解評分機制,以便其相應地調整回答格式。在我們的案例中,這將是讓模型知道程式碼區塊將如何被提取,或指示它以某種方式輸出程式碼區塊。請注意,這存在權衡,可能會引發模型對評估的意識(eval awareness)甚至獎勵作弊(reward hacking)。
感謝 Roy Rinberg 與我一同深入研究這個問題。*
附錄
為了注入錯字,我們製作了一個模擬人類錯字分佈的倉庫。
人類的錯字率約為 3%。模型在該範圍內大多表現穩健(見本文第二張圖)。我們使用的錯字率最高延伸至 16%:
| 錯字率 | 注入的文本 |
|---|---|
| 0% | The quick brown fox jumps over the lazy dog. This sentence contains every letter of the alphabet and is commonly used for testing purposes. |
| 0.5% | The quick brown fox jumps over the lazy dog. This sentence contains every letter of the alphabet and is commonly used for tessting purposes. |
| 1.0% | The quick brown fox jumps over the lazy dog. This sentence contains every letter of the alphabet and is commonly used for teesting purposes. |
| 2.0% | The quick brown fox jumps over the lazy dog. This sentence contains every letter of the alphabet ane is commmonly used for testing purposes. |
| 4.0% | Thhe quicj brown fox jumps over the lazy dog. This sentence contains every letter of the alphabet and is commmonly used for testing purposes. |
| 8.0% | Thhe quicj brown fox jumps over the lazy dog. This setence conyaiins every letter of the alphabet and is commonly used for tseting purposes. |
| 16.0% | Thhe qucuk brown fox jjmuups over the azy dog. Thi sentence conntain every lerero f the alpyabet and s coommmonlt used for testing pufpoar. |
此實驗的 Repo 連結(最初的動機是為了評估意識,因此得名)。