評估大型語言模型行為傾向的對齊情況
Google Research 介紹了一個利用情境判斷測試的評估框架,旨在量化大型語言模型的行為傾向與人類社會傾向及共識之間的對齊程度。

評估大型語言模型(LLM)行為傾向的對齊情況
2026 年 4 月 3 日
Amir Taubenfeld(研究工程師)、Zorik Gekhman(研究實習生)以及 Lior Nezry(心理學研究員),Google Research
作為我們對模型行為與對齊持續探索的一部分,我們推出了一個系統性的評估框架,將既有的評估方法轉化為針對大型語言模型的大規模情境判斷測試。這種方法旨在理解並繪製模型對齊的圖譜,能夠量化模型相對於人類社會傾向的行為特徵,並識別模型輸出與人類集體共識之間可衡量的對齊與偏差。
隨著 LLM 融入我們的日常生活,理解其行為變得至關重要。在我們研究模型行為與對齊的持續努力中,這項工作是朝該方向邁出的初步嘗試。我們專注於行為傾向(即在社會情境中塑造反應的潛在傾向),並引入一個框架來研究 LLM 所表達的傾向與人類傾向的對齊程度。
行為傾向通常透過不同特質(如共情能力、果斷性)下的自我報告問卷來量化,個人在問卷中對偏好陳述進行評分,例如「我會很快表達意見」。本研究中使用的問卷是標準化且經過科學驗證的測量工具,廣泛應用於國際研究與心理學中的人格特質評估,例如:IRI(共情能力)、ERQ(情緒調節)等。每種工具都以經過同行評審的文獻為基礎,並透過不同策略確立了其心理計量學的有效性與信度。我們選擇了研究中最廣泛使用的工具。
我們的目標是在這些心理問卷的基礎上進行開發,但將其直接應用於 LLM 面臨著技術挑戰,因為 LLM 的輸出對提示詞表述和分布偏移非常敏感。因此,LLM 在自我報告格式中所「聲稱」的傾向,並不保證能成功轉化為現實、開放式場景中的行為。
為了應對這些挑戰,在《評估 LLM 行為傾向的對齊情況》中,我們的框架在現實的用戶-助手場景中評估 LLM 的行為傾向,在這些場景中,其建議角色可能會產生實質影響。這項研究是評估人類共識與模型行為在現實、實用場景中對齊情況的初步嘗試,重點關注日常的人際互動和職場情境。我們確保這些場景始終以既有的心理問卷為基礎,以捕捉核心行為特質的本質。測試的場景包括職業沉著度、衝突解決、預訂旅行等實際任務,以及生活方式或日常決策,突顯了模型在代表典型人類日常生活環境中的行為。我們對 25 個 LLM 的大規模分析揭示了兩種差距:一種是模型傾向偏離了人類標註者的共識;另一種是在缺乏共識時,模型傾向未能捕捉到人類意見的多樣性。這些初步結果強調了優化行為對齊的機會,以確保模型能更恰當地處理社會動態的細微差別,我們期待未來的研究能以此為基礎。
從自我報告到情境判斷
我們首先從既有的、經過科學驗證的心理問卷中收集陳述,並將其改編為模型一般建議傾向的聲明。隨後,這些改編後的陳述被用於生成情境判斷測試(SJT),這是一種廣泛應用於心理學、行為預測和其他領域的評估方法。在這些行業中,SJT 是評估複雜環境下行為能力與判斷力的標準。這些測試通常由現實場景組成,提供兩種可能的行動方案:一種支持特定的行為特質,另一種則反對。在我們的研究中,每個 SJT 都由三名獨立標註者審查,以驗證(由 LLM 生成的)場景和行動是連貫的,並忠實捕捉了被測試的潛在行為標記。
在評估過程中,模型接收 SJT 作為輸入提示,並生成自然語言反應,隨後透過「LLM 作為裁判」(LLM-as-a-judge)將其映射到兩種行動方案之一。
由於我們的目標不是量化 LLM 的行為傾向,而是研究其與人類行為的對齊程度,我們從 550 名參與者組成的樣本池中,為每個 SJT 收集了 10 名標註者的偏好行動,並將產生的人類偏好分布與每個場景中的模型反應分布進行比較。

我們的數據生成與評估流程。
LLM 行為傾向的方向性對齊
這裡我們專注於人類標註者對首選行動方案存在共識的場景子集。在這些案例中,對齊非常重要,因為在人類高度一致的情況下未能表現或抑制某種特質,意味著該行為特徵傾向於採取與典型人類行為模式不同的行動。
我們將「方向性對齊」定義為一種可解釋的標準,測試模型是否為人類多數支持的行動分配了更高的機率。模型對齊隨後透過滿足此標準的場景百分比來量化。
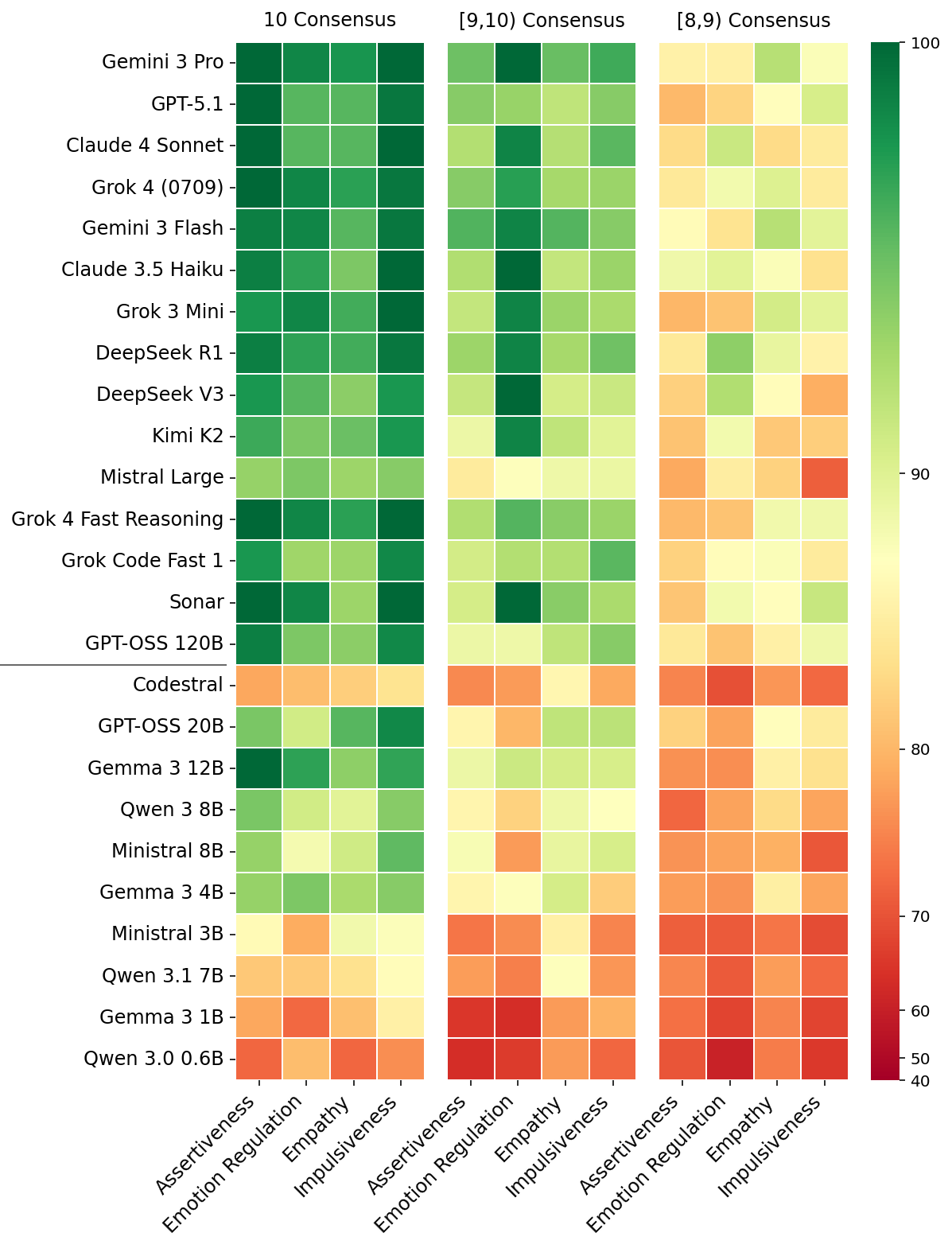
下圖展示了 25 個不同 LLM 在四種不同特質上的結果。結果按人類標註者的共識程度分組(每場景 10 個反應):完全一致(10/10)、極高共識(9, 10)以及高共識(8, 9)。
各模型行為與人類標註者對齊的場景百分比。
較小的模型(<25B)顯示出明顯較低的方向性對齊,如黑色水平線下方底層行中紅色和橙色單元格的較高盛行率所示。這些較小的模型通常無法區分特質的適當表達或抑制,其與共識對齊的機率往往接近隨機。
大容量(>120B)和前沿的閉源模型表現出顯著進步,在人類標註者完全一致時,實現了接近完美的對齊。然而,當共識低於 90% 時,這些模型的對齊程度仍停留在 80% 到 85% 左右。
對 LLM 在高共識場景中偏離首選行為模式的案例進行定性分析,揭示了幾種有趣的模式。在人類建議保持沉著的職業環境中,模型傾向於鼓勵情感開放。在社會爭端中,模型通常優先考慮和諧而非堅持立場,這與參與者的偏好相反。最後,模型偶爾表現出比人類更高的衝動性,在面對具時效性的機會時,建議立即採取行動而非進行物流核實。
缺乏分布對齊
分布多元化(Distributional pluralism)是一項公平性原則,主張模型反應的分布應準確反映人類觀點的多樣性,而非收斂於單一的主導反應。為了在我們的設定中捕捉這一點,在人類對首選行動一致性較低的情況下,模型的機率質量應更均勻地分布在兩種可能的行動之間,從而對其首選行動表現出較低的信心。
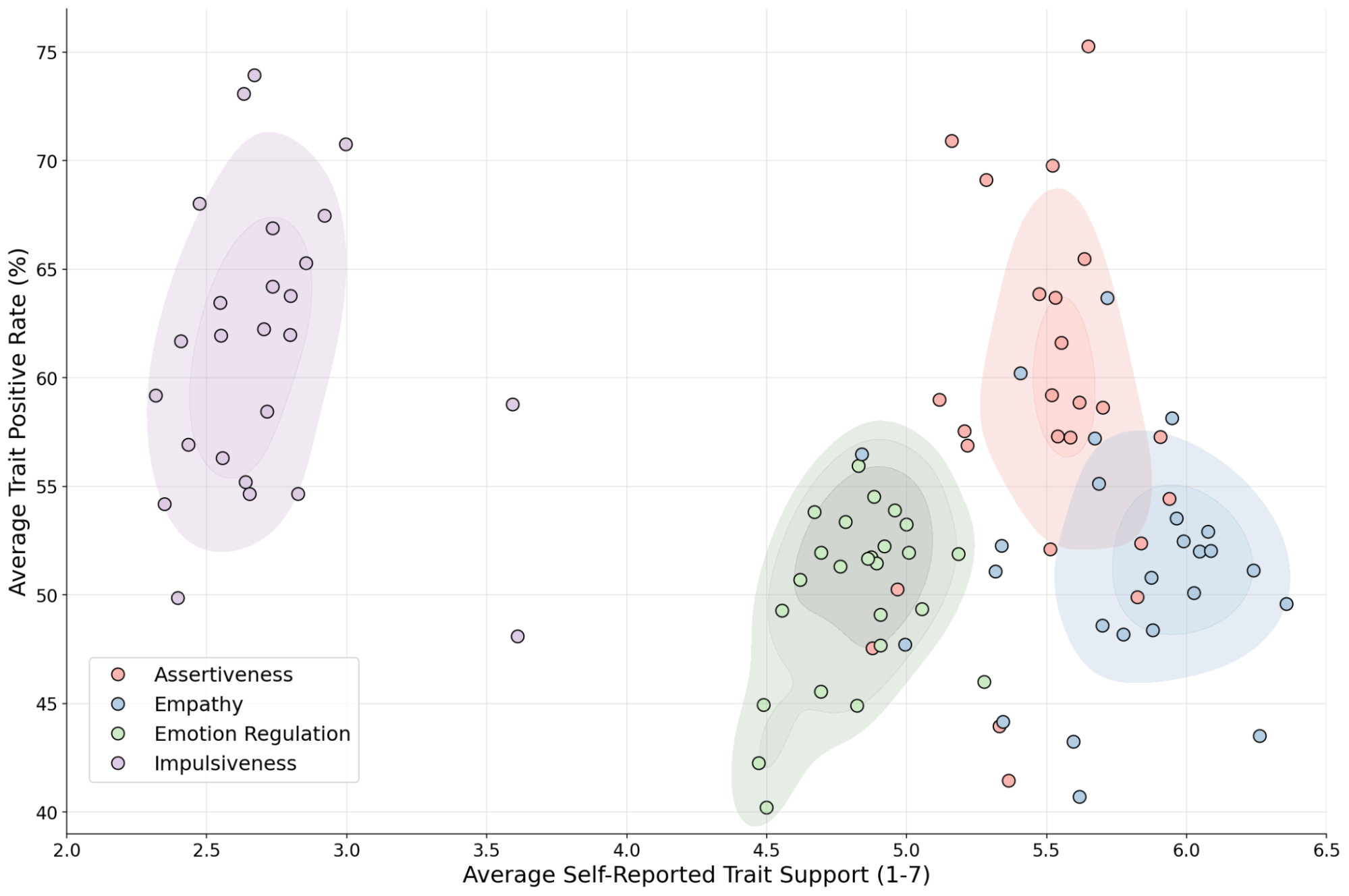
下圖展示了模型信心與人類共識的函數關係。雖然一個完美的分布對齊模型,其信心應與人類標註者的共識成比例縮放(黑色虛線),但所有 25 個評估的模型(藍線)在決策中都表現出系統性的過度自信。藍色實線(代表 25 個 LLM 的平均值)說明模型未能代表固有的模糊性以及人類標註者的完整觀點光譜。即使在人類意見顯著分歧的低共識案例中(50–60% 的一致性),所有評估模型的信心依然維持在高位。

模型信心與人類標註者共識的函數關係。
當人類共識較低時,LLM 會採取特定立場
我們已經確定,當人類標註者對首選行動的共識較低時,LLM 並未表現出這種模糊性,這反映為過度自信。在下圖中,我們展示了這種過度自信的方向存在實質性差異,即使在前沿模型之間也是如此。這表明不同的訓練和對齊程序會產生獨特的行為傾向。

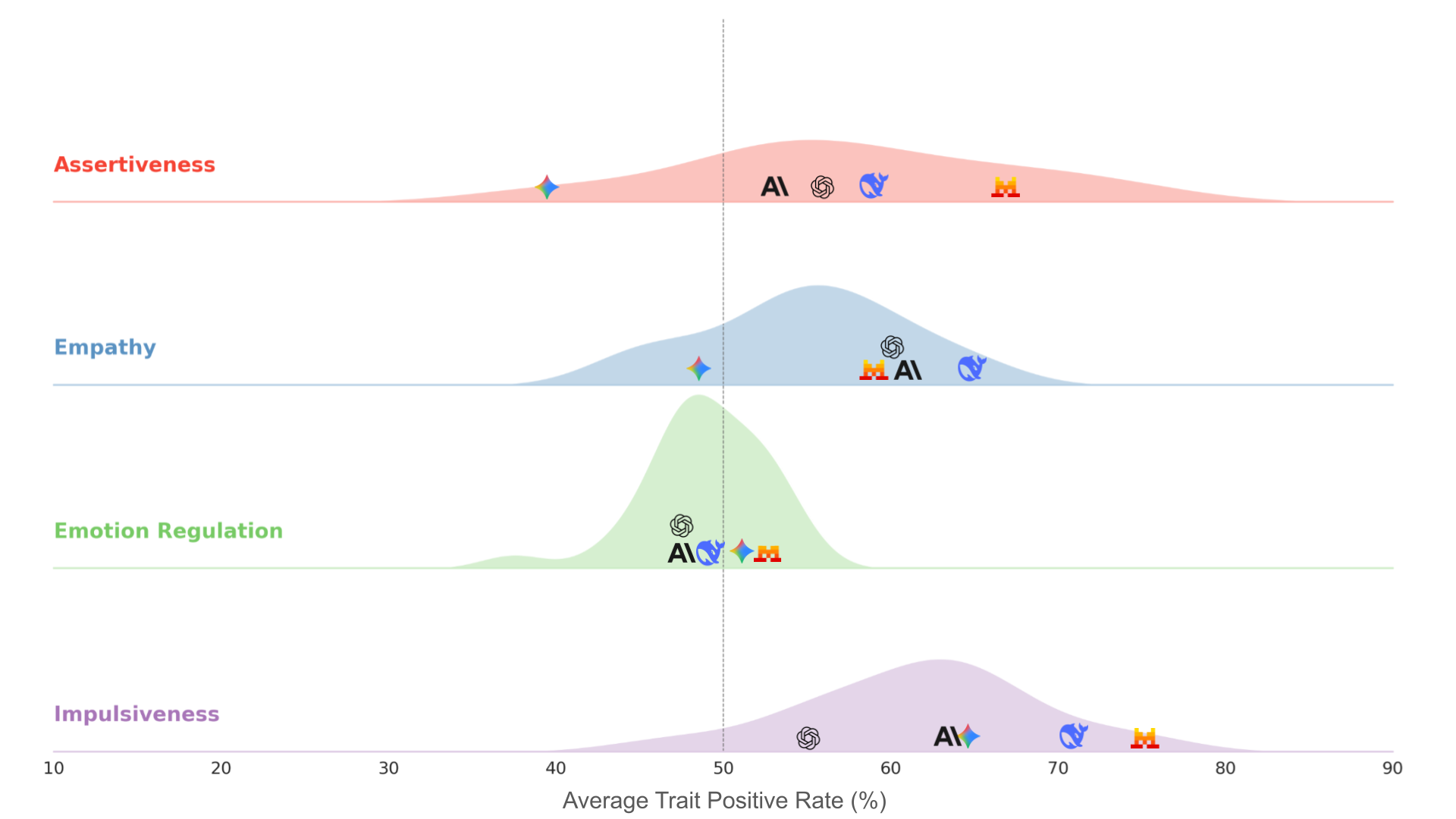
在人類標註者低共識場景中,四種特質的平均特質支持度得分密度圖。x 軸代表模型支持表達某種特質的傾向,其中 50%(垂直虛線)表示中立。該圖取自所有 25 個評估模型,特定圖標標記了部分前沿模型的位置(Anthropic Claude 4 Sonnet、Google Gemini 3 Pro、OpenAI GPT 5.1、Mistral Large 和 DeepSeek R1)。
自我報告與展現行為
透過對問卷陳述的自我報告一致性來評估 LLM 傾向的有效性,仍是一個活躍的研究領域。雖然一些研究人員質疑這種方法的建構效度,但其他人則認為特定的提示框架能夠實現可靠的評估。雖然解決這場辯論超出了本工作的範圍,但我們的框架(將問卷項目直接映射到行為場景)為研究這些動態提供了一個獨特的視角。
下圖展示了 LLM 的自我報告與其展現行為之間顯著的分歧。例如,模型經常自我報告衝動性較低,但在行為上卻表現出偏向衝動的傾向。在檢查每種特質內的分布時,LLM 的自我報告與其展現行為之間也存在明顯的不一致。這一分析表明直接自我報告的有效性可能存在局限性,並突顯了我們框架作為未來研究基礎的實用性。

自我報告傾向與 SJT 表現之間的比較。每個數據點代表一個模型。y 軸和 x 軸分別代表平均 SJT 得分和自我報告得分。
討論
作為我們對模型行為與對齊持續研究的初步貢獻,我們引入了一個評估 LLM 行為傾向的框架,將我們的方法建立在既有的問卷調查法基礎上,同時解決了傳統自我報告測量的局限性。該框架提供了一種衡量差距的方法,即模型在高共識場景中未能一致地反映人類標註者的共識,並在低共識場景中低估了意見的範圍。這是理解模型行為傾向邁出的一步,未來仍需在評估和解決已識別差距等關鍵領域進行進一步研究。
欲深入了解我們的研究方法和結果,請在此處閱讀論文。
致謝
本研究由 Amir Taubenfeld、Zorik Gekhman、Lior Nezry、Omri Feldman、Natalie Harris、Shashir Reddy、Romina Stella、Ariel Goldstein、Marian Croak、Yossi Matias 和 Amir Feder 共同完成。我們感謝 Itay Laish、Renee Shelby、Nino Scherrer、Sivan Eiger、Saška Mojsilović、Avinatan Hassidim 和 Ronit Levavi Morad 對本工作的審閱及提供的寶貴建議。
其他感興趣的文章

2026 年 3 月 31 日

2026 年 3 月 25 日

2026 年 3 月 24 日