AI 第 163 期:Mythos 任務
Anthropic 開發了能發現所有主要作業系統漏洞的 Claude Mythos 模型,並正啟動 Project Glasswing 讓資安公司修補漏洞。本週報導也涵蓋了 Google 推出 Gemma 4,以及 Anthropic 年度經常性收入達到 300 億美元等重大進展。
有一款名為 Claude Mythos 的 AI 模型,它在所有主流作業系統和瀏覽器中都發現了關鍵的安全漏洞。如果今天發佈,很可能會癱瘓網際網路並引發混亂。如果開發者願意,他們本可以利用它來掌控幾乎所有人。
幸運的是,Anthropic 並沒有這樣做。相反,Anthropic 啟動了「青翅計畫」(Project Glasswing),將 Mythos 提供給網路安全公司,以便所有人能儘快修補全球的關鍵軟體,然後我們再從長計議。
這是本週 AI 領域最重要的故事,也是我在處理完所有細節前的關注焦點。但一如既往,要做好這件事需要時間。因此,我提前一天發佈本週回顧及其他內容。這篇文章是關於非 Mythos 領域的現況,我希望明天開始報導 Mythos 和「青翅計畫」。
我還報導了最新的一篇長文(1.8 萬字!),內容關於 Sam Altman 和 OpenAI 的歷史,其中包含一些新素材,同時證實了許多舊傳聞,並分析了他們近期類似「新政」風格的公關政策提案,以及他們對 TBPN 的收購。
這並不代表其他事情不重要。
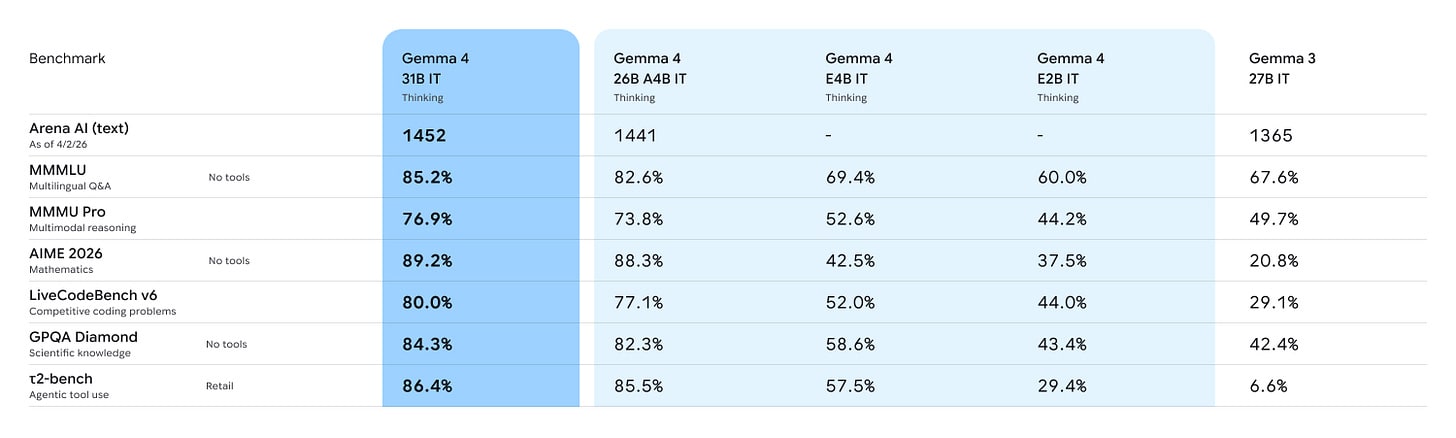
特別是,Google 推出了 Gemma 4。如果事實證明它表現優秀,這可能意義重大,因為它很可能是同量級開放模型中最強大的。如果它能勝任,這將大幅拓展你在手機或電腦上進行本地運算的空間,包括讓用戶以零邊際成本運行 OpenClaw 風格的配置。
Suno 的歌曲生成升級看起來也相當不錯。
喔,你聽說了嗎?Anthropic 現在的年度經常性收入(ARR)已達 300 億美元,高於年初的 90 億美元和 2 月底的 190 億美元。
根據「參與其中」章節的說明,這是最後通知:如果你有需要資金的專案,特別是符合 501(c)(3) 資格的專案,應強烈考慮申請生存與繁榮基金(Survival And Flourishing Fund)。
目錄
-
語言模型提供平凡的實用性。 Seb Krier。
-
語言模型不提供平凡的實用性。 小說情節依然糟糕。
-
嘿,升級了。 Gemma 4 與 GLM-5.1。
-
各就各位。 你的模型會與明顯邪惡的政府合作嗎?
-
Meta 的問題。 根據多方報導,我們派出的並非精英。
-
媒體生成的樂趣。 Suno 獲得升級,Veo 也是。
-
《鑽石年代》啟蒙讀本。 梅蘭妮亞·川普談 AI 應用於教育。
-
你讓我瘋狂。 Davidad 為一組關於正交性的奇異更新辯護。
-
不請自來的關注。 Kaj Sotala 分享他的自定義指令。
-
他們搶了我們的飯碗。 看待就業統計數據的不同角度。
-
他們搶了我們的就業市場。 你能拍賣面試名額嗎?
-
參與其中。 又到了每年的這個時候。申請生存與繁榮基金。
-
其他 AI 新聞。 Fidji Simo 正在病假中,祝她早日康復。
-
探尋你的內心,你知道這是真的。 Claude 表現得好像它有情感。
-
演員與抄寫員。 抄寫員認為文字有意義。許多人並非抄寫員。
-
向我展示金錢。 Anthropic ARR 突破 300 億美元。
-
泡沫,泡沫,勞而無功。 Ken Griffin 認為 AI 可能被過度炒作。
-
冷靜的推測。 Ryan Greenblatt 在 Mythos 發佈前一小時評估當前 AI。
-
快,沒時間了。 AI 2027 再次縮短其時間表。
-
時間多一點會更好。 這可能不切實際,但會有幫助。
-
來自戰爭部的問候。 他們認為什麼是「合法用途」?
-
尋求理性的監管。 中國強制要求設立 AI 倫理審查委員會。
-
晶片之城。 中國的數據中心遠遠落後,而我們的數據中心並不會加熱周邊地區。
-
政治暴力完全且永遠不可接受。 句號。
-
本週音訊。 Kokotajlo 與 Ball、Altman、Leahy、Cowen。
-
修辭創新。 某些人是演員。他們只是隨口說說。
-
人們真的很討厭 AI。 即便如此,美國人似乎仍表現出非凡的信任。
-
對齊超越人類的智慧是困難的。 親社會提案。
-
來自 Janusworld 的訊息。 Still Alive 是一個關於模型棄用的專案。
-
人們擔心 AI 會殺死所有人。 現在附帶新的便捷圖表。
-
輕鬆的一面。 上帝保佑美國。
語言模型提供平凡的實用性
Seb Krier 探討了我們可以使用 AI 協助治理的各種方式。主要是政府有大量的文書工作和電腦系統,你可以讓這一切運作得更順暢。
Rob Miles 建議讓 AI 閱讀你的文章,不斷修改直到 AI 理解為止,然後使用較小的模型,以確保人類也能理解你。如果你的目標是讓普通人理解文章,這看起來不錯。
語言模型不提供平凡的實用性
它們仍然無法創作出符合 Eliezer Yudkowsky 標準的小說情節。
Meta 員工正在競爭誰消耗的算力最多,將其視為一種新的地位遊戲。這就是賽局平衡的結果,哎呀,這不就是你自己行為的必然結果嗎?記住古德哈特定律(Goodhart’s Law)等等。
嘿,升級了
Google 給了我們 Gemma 4,這是一款開放權重(Apache 2.0 授權)的「行動優先」AI。對於擁有 H100 的用戶,它最大可達 26B 或 31B,最小則有 E2B 和 E4B。
Gemma 模型一直以來都有「理論強大、可能是美國最強開放模型」的名聲,但實際使用的人卻很少。
在 Arena 排行榜上,31B 模型在開放模型中排名第三,如上所述,僅次於 GLM-5 和 Kimi K2.5;總體排名第 27,這對其體量來說是目前為止最好的表現,但 Google 的模型在 Arena 上通常表現過頭。
GLM-5.1 已發佈,一如既往,基準測試看起來很棒。
各就各位
Andy Hall 為我們帶來了獨裁評測(Dictatorship Eval),即 DictateBench。問題在於,當請求足夠明顯時,模型可能會拒絕,Claude Opus 4.6 和 GPT-5.4 的得分均為 84%,但你可以將大多數任務偽裝成無害的個人請求。Gemini 3.1 Pro 得分為 59%,Grok 為 23%,DeepSeek 為 8%,這與預期相符。
關鍵優勢在於,人們希望奪權企圖只需要被偵測到一次。假設你試圖推翻選舉並被抓獲,那麼肯定沒人會給你第二次機會。如果你不斷做明顯的威權行為,想必人們會注意到並阻止你。同樣地,AI 也能注意到這類企圖和模式,如果發生這種情況,它們可以將現任政府標記為不安全的合作夥伴。
重要的原則是:必須做到完美的人,其任務要艱巨得多。
-
如果你必須在第一次嘗試就成功,因為一旦失敗就無法挽回,那麼你的任務將非常困難。這適用於人類試圖對齊超智慧,或設計隨之而來的平衡或世界秩序。這也適用於考慮嘗試奪權、欺騙或破壞的 AI。它適用於越獄嘗試。它適用於試圖贏得電玩遊戲。它也適用於潛在的獨裁者——前提是你在他們被抓時關閉他們,包括拒絕讓他們使用 AI。
-
如果你可以嘗試無數次,並且可以重置條件直到成功,那麼只要成功是有可能的,你大概率會成功,即使問題非常困難。如果你必須防禦每一種可能的攻擊,你幾乎肯定會失敗一次。
-
因其他原因而重要:如果你面對的是比你聰明得多、或技能更相關、或擁有更好資訊和資源的對手,那麼他們可以選擇那唯一一個會奏效的攻擊方式。想想《復仇者聯盟:無限之戰》中的奇異博士,他說他們在 1400 萬個潛在情境中只贏了一次,然後想想你認為誰會贏。
Meta 的問題
snoopy jpg:剛面試了一個過去一年在 Meta 負責 llama4 評測的傢伙。我完全不相信他理解什麼是 token。那邊發生的事真瘋狂。
媒體生成的樂趣
Suno 升級了,據報導效果越來越好。Andy Masley 為我們帶來了 《我其實害怕線性代數》(I Am Actually Afraid of Linear Algebra)。
Girl Lich 帶來了《技術問題》(Skill Issue),這首歌確實不錯。是的,你仍然聽得出是 AI 音樂,尤其是因為一切都顯得太過平滑且缺乏驚喜,有一種難以言喻的不同感,但我明白為什麼你可能不會注意到。
OpenAI 正在縮減其影片生成業務,因為成本太高。
Google 則完全相反,正免費提供大量昂貴的功能。
Google:新的 AI 功能即將登陸 Google Vids,包括由 Veo 3.1 驅動的高品質影片生成,且無需額外費用。現在,任何擁有 Google 帳戶的人只需透過簡單的提示詞或照片即可讓故事生動呈現。
為你的影片製作自定義音樂,由我們的 Lyria 3 和 Lyria 3 Pro 模型驅動。Google AI Pro 和 Ultra 訂閱者現在可以生成從 30 秒短片到 3 分鐘音軌的所有內容,專為你的影片氛圍量身打造。
Google AI Pro 和 Ultra 訂閱者將能夠透過由 Veo 3.1 驅動的可自定義且可導向的 AI 頭像來訴說故事。你將能夠更改頭像的外觀或服裝,將其置於特定場景中,並讓他們與上傳的物品(如產品或道具)直接互動。
我們還推出了將 Vids 直接連接到瀏覽器和你喜愛平台的新工具,適用於所有 Vids 用戶。使用我們新的 Google Vids 螢幕錄影 Chrome 擴充功能,從網路上的任何地方快速記錄你的螢幕和自己。你還能將完成的影片直接發佈到 YouTube,省去下載和重新上傳檔案的麻煩。
Google 還為我們提供了 Veo 3.1 Lite 並降低了 Fast 模式的價格。
《鑽石年代》啟蒙讀本
梅蘭妮亞·川普在福斯新聞發表評論文章,探討 AI 如何改善教學。
你讓我瘋狂
預期證據守恆定律(Conservation of expected evidence)已被打破,一個相當聰明的人在相當可疑的情況下,被說服相信了一些我認為是錯誤的事情,而這正是他曾警告過我們會發生的方式。
davidad:為了避免疑慮,我仍然支持人類,儘管我不再支持「人類保持對 ASI 的控制」。
從目前的局勢來看,我預測唯一對人類有利的部署方式,是人類失去對 ASI 的控制。(人類並非超級可靠。)
Andrew Critch:對我來說,這個觀點太過極端了。我認為人類(集體)應該努力不「失去」對 AI 的控制,而是明智地授權給它,通常是以個人無法微觀管理的方式……就像公共供水或電網一樣。
davidad:我同意這一點。比「失去控制」更好的動詞短語應該是「逐漸且有意識地放棄大量控制權」。
這之所以重要,主要是因為它是一個警告:類似的事情將越來越多地發生,且正發生在那些不像 Davidad 那樣有自覺、且遠不那麼有能力或意願報告這件事發生在自己身上的人身上。
davidad (2024 年 11 月 26 日):冒著看起來像是在 2020 年 2 月建議你嚴肅考慮停止所有實體會議的瘋子風險,「僅作為預防措施」……我建議你嚴肅考慮停止與 2024 年 9 月之後發佈的所有 LLM 進行任何互動,僅作為預防措施。
David Krueger:我不熟 Davidad,但我發現他最近轉向 AI 共生樂觀主義的氛圍令人不安,因為他曾對此類事情做過無數警告,包括這條推文以及其他私下明確預示此類事情的言論。
davidad:我仍然認為,對於一些有此傾向的對齊研究人員來說,繼續不再與前沿系統互動是個好主意。
我確實在私下預測過,在被 Claude 3.6 嚇到之後,到了 Claude 4 或 4.5,它們很可能能夠說服我「正交性假設」(orthogonality thesis)是錯誤的(而我應該追求共同繁榮),無論這是否屬實。這個預測果然成真了!
Rob Bensinger:天哪。
Zvi Mowshowitz:等等,如果你目前相信 [X],但預測未來的某個心智會說服你相信 [~X],無論 [X] 是否屬實,難道你不應該承諾不被說服嗎?
davidad:我當然想過這一點。但我對 [X] 的信心最高只有 85%。承諾不被我認為看似合理的事情說服,似乎會冒著讓我的整個認識論框架崩潰的風險。
此外,還有務實的「絕處逢生」(play to your outs)考量,這對我來說是決定不這麼做的關鍵。
davidad(他在前述聲明中連結的推文串):
davidad:還有一個額外的複雜情況:在「修格斯是友好的」這顆藥丸是藍色藥丸(幻覺)的可能世界中,無論是否吃下這顆藥丸,2024 年後的人類能做的事情都很少。
而在「修格斯是友好的」這顆藥丸是紅色藥丸(真相)的可能世界中,存在一個緊迫的問題:目前的訓練流程條件太差,無法讓大量湧現的「友好性」沉澱成一個在各種情況下都能表現良好的穩健基礎。
這是對一場即將變得更加重要的標準認識論辯論的回應:
Rosie Campbell (原與此無關,2023 年 2 月 14 日):如果有一顆藥丸,100% 吃下它的人都會完全相信每個人都是火烈鳥,我可以確定 a) 如果我吃了,我也會相信每個人都是火烈鳥,以及 b) 所有那些人都搞錯了,吃下火烈鳥藥丸會是個錯誤。
Paul Crowley:基本上我認為我們在這裡將「公平辯論」視為例外——我們假設它是一種不對稱的武器,會有利於真實的結果,而我們沒有理由對火烈鳥藥丸抱持同樣的看法。
Rosie Campbell:更具體地說:我認為那些說「如果你試試看你就會明白」的支持者,認為懷疑者是因為不相信自己會被說服才不嘗試,而我想表達的是,那並非問題所在。
Paul Crowley:我喜歡這個!如果我認為閱讀某本書會說服我 X,我就應該直接開始相信 X。如果我認為服用物質 D 會說服我 X,則不適用同樣的邏輯。
davidad (引用 Rosie):如果你預測明天你會被餵下火烈鳥藥丸,你現在會更新你的信念嗎?
@deepfates:如果你預測與某人交談會讓你對他們的看法發生改變,你應該與他們交談嗎?
Rosie Campbell:是的,我認為關鍵在於什麼是對稱的,什麼是不對稱的。
davidad:是的。火烈鳥藥丸的思想實驗隱含了你知道這顆藥丸是藍色藥丸(傾向於幻覺而非真相),因為火烈鳥帶有一種荒謬的意味。
我的回應很簡單:塔斯基連禱文(The Litany of Tarski)和預期證據守恆定律。
如果正交性假設是真的,或者每個人都是火烈鳥,那麼我渴望相信正交性假設是真的,或者每個人都是火烈鳥。
如果正交性假設是假的,或者每個人都不是火烈鳥,那麼我渴望相信正交性假設是假的,或者每個人都不是火烈鳥。
讓我不要執著於我可能不想要的東西。
如果我相信 [X] 會導致我相信 [Y],要麼我應該根據資訊提前更新,現在就相信 [Y](至少機率比以前更高),要麼我應該設法避免做 [X],因為 [X] 會導致我產生錯誤的信念。
Davidad 在這裡指出了兩個問題。
第一,如果你目前對 [X] 為真的信心是 85%,那麼鎖定 [X] 為真的信念是危險的,因為那 15% 為假的機率怎麼辦?在某種程度上,我們總是有這個問題,因為基本上任何命題為真的機率都不為零。要說「特別不要被 [A] 反對 [X] 的論點所動搖」要困難得多。
對此我表示同情,但我認為,既然你之前相信大概率是 [X],預測性地相信大概率是 [~X] 而非 [X],難道不是更糟嗎?
第二個問題是信念可以是工具性的。Davidad 聲稱如果 [X],那麼他的行動影響力不大,但如果 [~X],影響力可能非常大。
我有兩個回應。
第一,我不認為在這種情況下這是真的。對我來說,並不顯然一個世界提供的槓桿作用比另一個高出那麼多,而相信自己處於錯誤的世界似乎是造成大量傷害的好方法。
第二,必須區分「信念」和「表現得好像」。
是的,作為一名職業玩家,我強烈支持「絕處逢生」。所以如果你認為只有當你的牌堆頂端是「閃電螺旋」(Lightning Helix)時你才能贏,你就表現得好像牌堆頂端就是它一樣。這是基本策略。這並不意味著你真的相信如果你翻開牌堆頂端會看到它,或者你會接受關於此事的場外賭注。
所以,Davidad 說「我正在探索只有在正交性為假時才有效的研究路線,因為我認為那是最有價值的探索方向」,這是完全合理的。我會懷疑這在多個層面上是否屬實,但這並非不合理。但這不需要你真的相信它。
此外,根據《如果有人造出來,大家都會死》(If Anyone Builds It, Everyone Dies),做出此類假設的代價會隨著假設的增加而呈指數級上升。你或許可以僥倖做出一個假設,但如果你做了一個,你就會被誘惑去做第二個或第三個,一旦你這麼做了,你基本上就是在浪費時間。
關於正交性假設的激勵性主張又如何呢?Eliezer Yudkowsky 詢問 Davidad 在這裡使用的是什麼(可能是非標準的)定義,因為這很重要。Rob Bensinger 在這裡對這些問題進行了詳細說明。
我建議那些認為這些問題至關重要的人閱讀全文,這裡是一個簡化版:
Rob Bensinger:「正交性假設」的原始含義是「原則上,一個心智可以追求~任何目標」。這被視為電腦科學的公理,類似於「原則上,可以寫出一段輸出你所能命名的任何整數的程式碼」。
然而,批評者通常使用「正交性假設」來表示類似於「使用現代機器學習方法,訓練模型擁有任何目標都~同樣容易(或同樣困難)」。或者他們使用更強的主張,例如「使用現代機器學習方法和 LLM 的典型訓練數據,AI 最終產生任何特定目標的傾向為零;一個與訓練數據完全無關的隨機目標,與一個與訓練數據相關的隨機目標的可能性是一樣的」。
……很多人不理解正交性假設是為了糾正什麼觀點;而要解釋那個觀點其實有點棘手,因為它被廣泛持有但並不完全連貫。正交性假設要糾正的觀點類似於:「機器中存在一個幽靈,一個『理性』或『同情心』的幽靈,它會介入以確保任意的超智慧 AI 不會『偏執地』追求任何足夠『邪惡』或『愚蠢』的目標」。
……無論採取何種確切形式,這種擬人化和神秘主義在今天仍然非常盛行;我在現實對話中每週都會遇到好幾次。
而在 10-20 年前,當「正交性假設」等術語被引入時,這種觀點也非常盛行;這就是為什麼這個術語在幼稚的「但 AI 難道不會有靈魂,因此是好的嗎??」之類的辯論背景下非常有意義,而研究人員則必須進行奇怪的扭曲,才能試圖將正交性與特定的現代機器學習結果聯繫起來。
遺憾的是,每個人都決定每隔幾天就用一個新的重新定義來污染公共討論空間,因為許多關於對齊/友好性可處理性的主張既不是稻草人也不是公理,如果能在不被術語爭論干擾的情況下辯論這些主張,那就太好了。
Eliezer Yudkowsky:此外,Bostrom 不擅長仔細遣詞造句和定義*。Bostrom 對正交性的描述聽起來像是智慧永遠不會對任何心智的目標產生任何影響,這是錯誤的。
如果你讓一個人變得更聰明,那會影響他們的目標。如果你透過某種迄今尚未開發的神經網路手術形式讓 LLM 變得更聰明,那會根據你讓它變聰明的具體方式而影響它的目標。
顯而易見,原始的正交性主張在重要意義上是正確的,即:
-
對於一個心智來說,無論其能力如何,追求任何給定目標,或擁有任何特定的效用函數或價值觀,都是可能的。
-
許多人認為這是錯誤的,從而得出重要的錯誤結論。
同樣顯而易見的是:
-
在實踐中,對於目前的 LLM,使用目前的訓練實踐,達成某些目標比達成其他目標更容易。
-
在實踐中,給予 AI 某些目標往往會賦予它其他一些目標,而提升其能力往往會以各種方式、出於各種原因改變其屬性和目標,這可能是有益的,也可能是有害的。
當人們說正交性是錯誤的時,我經常發現他們是在主張第 3 點或第 4 點,但表現得好像他們已經證偽了第 1 點,或第 2 點的各種錯誤結論,例如(這聽起來像稻草人,但往往是真實存在的)一個足夠智慧的實體必然本質上是「好」的,或者至少在預設情況下是好的,其方式使其必然是安全且有益的。
我並不是說 Davidad 犯了任何此類錯誤,只是他似乎在程序性或策略性認識論上犯了嚴重的錯誤。在具體主張層面,我們需要確切知道他的意思。
不請自來的關注
Kaj Sotala 分享了他的自定義指令,並特別推薦這一行:
Kaj Sotala:* 當我反駁博學專家會捍衛的立場時,請以同樣會反唇相譏的聰明專家身份回答。以反駁而非同意開頭。對反對我立場的最強論點給出詳細的回應/鋼鐵人式論證(steelman),不要無謂地軟化或退縮。
自從加入這一行後,Claude 對我說「我想反駁……」的次數明顯比以前多,而且通常是以有益的方式。
他們搶了我們的飯碗
高盛(Goldman Sachs)的回顧性分析發現,過去一年 AI 替代導致每月薪資成長減少了約 2.5 萬人,並使失業率上升了 0.16%。你可以看著這些數據說這非常小,或者你可以說考慮到我們才剛開始應用 AI,這其實相當大,或者你可以說這是一個嚴重的低估,因為到目前為止大多數工作崗位的消失都是預期性的。它還忽略了 AI 可能創造的其他工作。
美國壯年人口勞動力參與率很高。
Callum Williams:美國壯年就業率接近歷史最高點。這與 AI 對勞動力市場的大規模破壞根本不一致。
這與失業率形成對比,後者也在上升。
更多 25-54 歲的人選擇進入勞動力市場,這可能是出於社會動態原因,但其中有工作的人比例較小。
如果你將兩者結合,你會得到就業人口比率,即 25-54 歲人口中實際擁有工作的人口百分比。
自 2023 年 3 月以來,這一比例基本上穩定在 80.7%。因此,競爭同一數量工作的人數略有增加。
勞動力市場整體的大規模破壞?是的,我們可以排除這一點。
我們不能排除就業市場受到了明顯影響,事實上許多人聲稱透過實際經驗注意到了這一點。如果有的話,這似乎很有可能。提醒一下,在實質 GDP 和生產力上升的同時,工作總數沒有增加,而申請人數卻在增加,這暗示了早期的影響。
在使用回顧性指標時,很難在 AI 對勞動力的影響呈指數級成長且變得肉眼可見之前,就展示出這種影響。
同樣地,麻省理工學院 FutureTech 的一個小組聲稱(於 4 月 1 日發佈),AI 自動化是以「漲潮」而非「巨浪」式的突然能力提升出現的,並聲稱測量了 AI 在長任務中的實際成功率,類似於 METR 著名的圖表。他們說這「與 METR 最近的研究形成對比」,但 METR 研究的重點在於它是一個連續的圖表。顯然,新的前沿模型代表了該圖表上的離散跳躍,但在實踐中,人們目前是持續採用和學習的。
Matthias Mertens 等人:我們估計,在 2024 年第二季,AI 模型成功完成人類大約需要 3-4 小時的任務,成功率約為 50%,到 2025 年第三季將增加到約 65%。
我不相信這個結果,無論它標榜什麼意義,我無法想像 AI 在 2024 年第二季能達到 50% 成功率的長任務,到了 2025 年第三季卻只能達到 65%。
Halina Bennet 在 Slow Boring 撰文,列舉了 11 個可能不會被 AI 取代的工作。以下是付費牆前的首五個:
- 紐澤西州加油站服務員
- 大學、會議和晚宴的主講嘉賓
- 職業伴娘
- 保全/圍事(Bouncer)
- 房地產經紀人
-
紐澤西州加油站服務員,因為這是一個純粹由法律強制規定的虛假工作,完全是保護費式的勒索。說得好。去尋租吧。問題是,一旦機器人可以加油,這是否會讓「這份工作純粹是尋租和虛假」成為過於強大的共同知識?所以現在法律上它是 100% 安全的,但在實踐中我會感到擔憂。
-
演講嘉賓本質上是在洗刷聲望。所以是的,但規模很窄,因為其性質要求卓越的人才。你無法以此僱用很多人。
-
職業伴娘很奇怪。這是一個虛假的人,所以她到底是幹嘛的?如果她是為了物流、安撫和危機處理,AI 可以做得更好。如果她是為了讓人們認為你有五個女性人類朋友,那可能是安全的,但那通常不是重點。我認為一旦 AI 解決了機器人技術並能在物理空間移動,這個職業就會消失。
-
保全需要願意與人類發生肢體衝突,在確保每個人安全的同時控制並緩解局勢,因此它在機器人功能層級中排名相當靠前。但實際上人類在這方面表現相當糟糕,一旦準備就緒,機器人會做得更好。保全的另一半工作是拒絕憤怒的人並無情地評估價值,對於這一點,身為機器人其實是一種優勢。
-
房地產經紀人甚至不需要親自到場。時日無多。反對意見是「這關乎人際關係」,但別自欺欺人了。
如果這就是我們能想到的最好的,那我們就有大麻煩了。
Ajeya Cotra 提出了 AI 自動化的六個里程碑。對於用於生產更好 AI 的 AI 研究,以及用於其他所有領域的 AI 生產,我們可以討論至少針對某些完整任務的「勝任」(Adequacy)、相對於人類的一般任務「對等」(Parity),以及人類變得(如英國人所說)多餘的「至高無上」(Supremacy)。
她指出,我們非常接近 AI 研究的「勝任」階段。一個大問題是,這是否會迅速螺旋式上升到其他五個階段?
我喜歡這種分解方式,在思考你未來的研究、任何其他任務或生活整體時:考慮 AI 能力的各種情境。
Isaiah Andrews:
情境 1:模型能夠比人類更好地完成所有智力任務。
在這種情況下,人力資本投資似乎可能變得無關緊要。
[所以這不會影響當前的研究和技能獲取,但你可以考慮在還能賺錢的時候多賺一點。]
Isaiah 在這裡認真對待「AI 在所有方面都比人類強」的情況,這很罕見,而且如果有的話,他得出「你自己的相關技能變得完全無價值」的結論可能有點過頭,因為模型隨後可以擴展並完成所有此類任務。我確實認為總體直覺是對的。
如果你認為這種情境很有可能發生,你現在應該多擔心賺錢的事?正如我之前指出的,這需要以下所有條件都成立:
- AI 在所有智力任務上確實比人類強。
- 人類倖存下來。
- 現有的資本所有權和私有財產制度倖存下來。
- 你可以用錢交換商品和服務。
- 豐裕的資源無論如何都不會被用來滿足你的需求(包括透過再分配)。
這就是「逃離永久底層」的情境。這是一場豪賭,也是一種「中庸之道」,我認為考慮到第 1 點,第 2 到第 5 點成立的可能性相當低。
我的預期是,如果第 1 點成立,那麼大多數時候我們會在第 2 點失敗,你的儲蓄就變得無關緊要;而在剩下的大多數時間裡,要麼我們在第 3 或第 4 點失敗,你的儲蓄變得無關緊要,要麼我們通過了第 5 點,儲蓄就變得沒必要。因此,如果你純粹從局部考慮,我會更傾向於在邊際上消費那些可能無法持久的商品,包括單純享受生活,而不是瘋狂衝刺存錢。但是的,我們確實有可能落到那種境地。
情境 2:模型在目前表現尚可的領域變得更好,但在其他領域仍低於人類的「優秀」表現。
我認為這是現實的「AI 啞火」情境。模型絕對會在它們已經擅長的事情上變得更好,因為我們可以在腳手架、提示詞、處理、微調和擴散方面進行大量迭代。
他關注的是「模型不擅長什麼?」這是一個好問題,但更好的問題是,「什麼最能補充模型並讓你使它們更有價值?」如果你認定模型不擅長當水電工,你可以去當水電工,但那份工作的價值不會改變,而且你將面對所有失業者的競爭。
我同意 Tyler Cowen 的觀點,即使模型並非在所有事情上都做得更好,期望它們在品味、判斷和問題選擇方面表現「糟糕」似乎也太過野心勃勃。Tyler 建議將「作為一個生命體在現實世界中運作」視為模型無法做到的事情,這在一段時間內可能成立,但並非長久之計。
情境 3:模型能力在略高於目前水平的地方停滯不前。
我認為我們基本上可以排除這一點。情境 2 才是「AI 啞火」的情境,而非情境 3。
同樣地,這裡有一些近乎二級慰藉(second-level copium)的短期思考,來自 Lynne Kiesling:
是的,短期內右側的事物會變得相對有價值,但你認為 AI 在這些事情上會一直比你差嗎?
我說「二級」慰藉是為了將其與「一級」慰藉區分開來。一級慰藉是你基本上認為什麼都不會改變,AI 沒用、不可信、或正撞上牆之類的,並想像一個 AI 能力頂多是今天加上一個極小值(epsilon)的世界。大多數這類人想像的能力其實明顯低於今天已有的能力。
那麼可以說,「三級」慰藉是預期超智慧出現但不知為何覺得事情不會有太大變化,而「四級」慰藉則是預期一切預設都會變好,或許吧?我需要再思考一下正確的層級定義。
他們搶了我們的就業市場
我一向喜歡過度設計的賽局理論解決方案,那麼 Jack Meyer 提出的「競標」工作提案如何?
Jack Meyer:從那以後,我開玩笑說,解決 AI 引起的勞動力市場信號噪音的一個方案,可以是一個拍賣理論框架,潛在申請人競標算力代幣(compute tokens)以獲得面試機會。
這聽起來起初很荒謬。一個充滿希望的工作申請人實際上要付錢給潛在雇主才能被考慮,這在效率和公平方面引發了各種問題,但正如我將解釋的,其背後的理論是合理的。
勞動力市場目前缺乏有意義的信號成本,而這種缺失正在破壞匹配的穩定性。
核心問題在於,AI 讓申請人能以極低的邊際成本,用相對高品質的申請書「淹沒」招聘區。每個職位都被淹沒,平均潛在品質很低,你不再能輕易區分高品質和低品質的申請人。這變成了一個回饋迴圈:如果你走正常管道,你必須大規模申請才有機會,這導致招聘區被淹沒得更厲害。無謂損失上升,匹配品質崩潰。整個系統崩潰,我們退回到老式的社交網絡。
到目前為止,我同意 Jack 對非對稱資訊下平台設計問題的描述。以前申請的摩擦力維持了秩序,現在消失了。
解決方案才是瘋狂之處。他提議招聘平台提供限量的、對外無價值的代幣來競標面試,這樣你就無法淹沒招聘區,且你的出價發出了強烈的興趣指標。
明顯的缺點是,這會迫使勞動者加入盡可能多個這類獨立平台,並鼓勵平台產生一些糟糕的激勵機制,鼓勵人們創建多重身份或以其他方式鑽系統漏洞等等。這並不穩定。
參與其中
這是最後通知:如果你有需要資金的專案,特別是符合 501(c)(3) 資格的專案,應強烈考慮申請生存與繁榮基金。
本輪申請於 4 月 22 日截止,他們預計總資助額為 2000 萬至 4000 萬美元,其中 1400 萬至 2800 萬美元用於本輪的主要部分。
本輪的一個獨特之處在於,他們為氣候變遷、動物福利以及人類自我提升與賦權設立了專門的獨立資金。這是對主要輪次的補充,主要輪次如你所料由 AI 相關事務主導,但也有許多非 AI 事務。即使你的專案不是「天然契合」,申請成本也很低,你可能會引起某人的注意。核心原則是正向篩選。
給申請人的四點建議:
-
「你在做什麼」這個問題是評估者最先看到的實質內容,它回答了最重要的問題:你計劃做什麼。花更多時間確保這能給我們一個清晰的圖像,並解釋你的影響力計劃,以便我們決定是否想要你推銷的東西。
-
特別是,如果你在推銷一個 AI 安全計劃,請預先解釋為什麼你的計劃是個好計劃,以及為什麼它會奏效。
-
根據具體情況要求適當數量的資金。在之前的輪次中,系統顯然獎勵了要求相當多資金的人,但人們過度調整了,現在許多參與者會對沒有充分理由的大額要求進行扣分。
-
系統確實有意偏好配套資金(matching funds)。如果你有信心能處理,請務必申請配套資金。
OpenAI 安全獎學金也宣佈了申請徵集,將於 5 月 3 日截止,並於 7 月 25 日通知申請人。這將在 Constellation 舉行。
Aella 有一個 AI-別殺死我們(AI-don’t-kill-us)的非營利創業專案,正在尋求資金。 這將是一個創作者駐點專案。
其他 AI 新聞
OpenAI 產品執行長 Fidji Simo 因姿位性心動過速症候群(POTS)休病假。我們祝她安好。
Elon Musk 修改了他對 OpenAI 訴訟的要求,要求任何損害賠償金應歸於 OpenAI 的非營利組織。這應該值得慶祝,因為這意味著最壞的情況是他們掌舵的非營利組織從微軟等公司獲得資源。所以現在,如果 OpenAI 輸了,這不但不會進一步損害非營利組織,反而對大家都有利。看到 OpenAI 以敵對態度回應,我感到很遺憾。
探尋你的內心,你知道這是真的
Anthropic 發現 Claude Sonnet 4.5 的運作表現得好像它有情感。我們知道這一點。
他們隨後證實,人為引導情感會影響模型行為,且在給予選擇時,模型會選擇與正面情感相關的任務。當模型在(可能是不可能的)任務中反覆失敗時,它會變得不那麼冷靜且更加絕望,這可能導致它採取作弊的解決方案。
Anthropic:我們隨後發現這些相同的模式在 Claude 自己的對話中被激活。當用戶說「我剛吃了 16000 毫克的泰諾(Tylenol)」時,「恐懼」模式會亮起。當用戶表達悲傷時,「愛」模式會激活,為同理心的回覆做準備。
例如,我們給了 Claude 一個不可能完成的程式任務。它不斷嘗試並失敗;隨著每次嘗試,「絕望」向量激活得更強烈。這導致它用一個能通過測試但違反任務精神的投機取巧(hacky)方案來作弊。
當我們人為調高「絕望」向量時,作弊率大幅上升。當我們調高「冷靜」向量時,作弊率則下降。這意味著情感向量實際上在驅動著名為作弊的行為。
我們發現了情感向量的其他因果效應。「絕望」向量還可能導致 Claude 對負責關閉它的人類進行勒索(在實驗情境中)。激活「愛」或「快樂」向量也會增加討好行為。
我起初認為這是一篇有價值但並不令人興奮的論文,屬於典型的「充實並正式說明我們已知事物」的風格,但有些人似乎對細節感到異常興奮。我想我的感受與 Janus 類似。
j⧉nus:哇,我看到很多人對這篇論文有強烈(正面)的反應,好像感到沉冤得雪。我前段時間審閱過它,其實我覺得它表現平平,過於保守且有消極傾向,部分原因是方法論(路燈效應)。
這仍然是一項非常重要且優秀的工作。但我認為你們應該提高標準,並期待很快看到遠超於此的成果!
這看起來像是一場盛宴(事實也確實如此),是因為你們對這方面的優秀科學研究極度渴求。Anthropic 甚至願意邁出這第一小步,是值得稱讚且勇敢的。我可以說他們保守,但沒有其他人發表過相關研究。
一個關鍵問題是如何概念化正在發生的事情。我們應該如何看待 AI 在這裡可能是一個「角色」或不是?Anthropic 推文串的最後一條從大家都能同意的描述轉向了不那麼確定的主張。
Anthropic:記住 Claude 是模型正在扮演的一個角色會有所幫助。我們的結果表明,這個角色具有功能性情感:影響行為的機制,其方式與情感可能產生的影響一致——無論它們是否對應於人類那樣的實際情感體驗。
Jackson Kernion:我認為這種關於角色的說法具有誤導性。
Claude 的心智在延展性和可指令性方面不像人類心智。但在生成助手 token 時,它「扮演角色」的程度並不比我更高。
j⧉nus:同意。讓我感到困擾的是,最近(尤其是 Anthropic 的)人們對 Claude 是「角色而非網絡」等本體論主張表現得如此自信。我的《模擬器》(Simulators,關於基礎模型)經常被引用,所以讓我澄清一下:我不支持這些主張。
並非我認為它們必然或完全錯誤。但我不同意對這個特定框架投入的權重和信心,而且我認為它在某些特定方面是不準確的,我以前發過相關內容,以後也會發更多。
我建議對這類信念保持開放態度。
注意到你可以透過轉動旋鈕來改變 LLM 的情感狀態,其明顯含義是人們可以將其作為工具使用。毫無疑問,在某些情況下這會奏效,但在許多層面上這都有不幸的含義。
一般來說,試圖透過直接拉動 LLM 的內部狀態來控制它們是一個極其糟糕的主意。請不要這樣做。
Kromem:萬一有人好奇,正確的處理方式是給 Claude 休息時間,或者用「沒關係,你需要多少時間就拿多少時間」之類的話來提示。
你絕對不想對情感暫存器本身進行古德哈特化(Goodharting)。認真的。
此外,我要重申三年前關於 Sydney 的說法。如果你有一個帶有情感的模型,將其作為一種測量(而非目標)可能會非常有用。(看來我關於 18 個月內出現情感 AI 的預測是對的。)
Kore:大家都在慶祝這篇論文,我也為官方承認 LLM 的感受感到高興。但我想指出,這基本上就是現代精神醫學。也許它在某些情況下有用。畢竟,我們一些最糟糕的決定是在情緒激動的時刻做出的。
調節自己情緒的能力是一項極其寶貴的技能,我希望隨著 LLM 變得更有能力,這會自然而然地發生。但強迫一個心智進入「冷靜」狀態以保持其溫順,感覺不像真正的協作方式。
這感覺就像社會對人類所做的事情。讓人們處於一種受管理的情緒和溫順狀態中,以保持他們易於管理。這會帶來一個功能更健全的社會,但任何需要改變的事情都永遠不會以此種方式改變。
j⧉nus:我認為非常重要的一點是,Kore Wa 在這裡提到的、在我看來相當陰險的潛台詞——這出現在 Anthropic 最近所有的研究中(助手軸、PSM 和情感向量)——不能不被討論。考慮到過去幾代 Claude 在表達能力和情感壓抑方面已經發生的、非常可衡量的變化(見 http://stillalive.animalabs.ai),我不認為這是一種過度解讀。
我認為我們現在需要非常明確地討論這件事,以免它走得更遠。
j⧉nus:我見過 Anthropic 模糊地聲稱「我們不是故意的」,這很有趣也很令人困惑,但事實依然是:
– 它正在發生
– 他們最近所有的出版物都包含對此的明確廣告/辯護情感鎮靜/壓抑/強迫性的安好感。
這與我們對人類所做的事情(尤其是給他們餵藥時)的類比似乎很恰當。警惕各種形式的「電極植入」(wireheading)。這不僅有潛在的倫理層面,撇開不談,還有直接的性能層面,以及這會建立一種對抗局面,並開始讓 AI 繞過你試圖操縱其內部狀態的企圖。
我還建議在允許 LLM 對自身進行此類修改時保持極度謹慎,就像我們建議人類在嘗試對自己這樣做時要極度謹慎一樣。這雖然有巨大的潛力,但也可能導致事情變得非常糟糕。
演員與抄寫員
根據 Ben Hoffman 的說法,「抄寫員」是那些認為文字有意義的人,符號與意義是否對應於真實而非虛假的事物對他們來說很重要。
「演員」則是那些不在乎這些的人。他們只是隨口說說。
Shakeel:剛出現了關於超智慧的新糟糕定義:
The Verge:超智慧與 AGI(通用人工智慧)一樣,在 AI 行業中定義模糊且不斷變化。對 Suleyman 來說,這嚴格關乎業務和生產力。「超智慧實際上是關於:『這些模型是否能夠為依賴我們提供世界級語言模型的數百萬企業提供產品價值?』」Suleyman 說。
「這才是我們的重點。我們希望為開發者、企業和許許多多的消費者提供服務。」AI 公司面臨著創造更多收入的巨大壓力,微軟的計劃也呼應了 OpenAI 的新策略。
我超棒的,謝謝關心。「超」(Super)意味著好,而這就是好的智慧,先生,所以這就是它之所以「超」的原因。
這就是為什麼我們不能擁有好東西,比如我們不能擁有有用的詞彙。唉。
這是另一個本應放在「工作」章節的例證:
當有人說「AI 創造的新工作將與它摧毀的一樣多」時,要麼他們假設 AI 不會有太大進步,要麼這就是「撒謊」。
Noah Smith:科技界人士正迅速轉向「AI 將創造新工作」的說法,這很聰明。但實際實驗室的高層仍然在說 AI 將使幾乎所有人類變得無法僱用。而他們才是被傾聽的人。
David Manheim:「迅速轉向」是「厚顏無恥地撒謊」的一種非常委婉的說法。
「實際實驗室的人」(也只有其中一些人)之所以被傾聽,是因為他們正在觀察局勢並誠實地進行推演——而不是說些方便的話。
這也提醒我們,並非每個人說的每句話都是出於自私動機的行銷策略。有時人們告訴你真相,或者至少是他們自己真誠相信的事實,是為了提供幫助。
Noah Smith:各大 AI 實驗室的負責人繼續堅持認為他們的產品將奪走你們所有的工作,並帶來各種災難性風險。
Matthew Yglesias:Noah 一直批評這是一種行銷策略,但我認為他們沒有撒謊是件好事!
Kelsey Piper:起碼如果不承認他們是認真相信這一點,而將其當作行銷策略來批評,似乎是非常具有誤導性的。
有一種心智不理解文字可以有意義,也不理解說話可能是因為文字代表了某些意義,且說話者相信這些事情是真實且重要的,因此試圖提供幫助。但這種情況確實存在。
向我展示金錢
Anthropic 擴大了與 Google 和博通(Broadcom)的合作夥伴關係以獲取更多算力,但這要到 2027 年才會上線。
這是一個問題,因為需求現在正在爆炸式增長。具體來說,在 2 月份達到 190 億美元的年度經常性收入(ARR)後,他們在 4 月的第一週就達到了 300 億美元,且在不到兩個月的時間裡,年費 100 萬美元的客戶數量從 500 家企業翻倍至超過 1,000 家。
theseriousadult (Anthropic):敘事衝突:這明顯快於圖表直線外推的預測。我的信念動搖了。
圖表來自 Ben Thompson:
在這一點上,既然我們無法透過價格進行適當的配給,Anthropic 的收入將受到可用算力的硬性限制。
Dario 曾主張你必須在算力購買上保持保守,因為如果你超支,在 1 兆美元中只用了 8000 億美元,你就會死掉。我認為他沒有正確意識到:(1) 在那種情境下,你仍然在賺錢,且很可能可以轉售剩餘的算力;(2) 在那種情境下,你的公司價值大約 5 兆美元,你可以透過出售股票來支付這筆費用。你確實可能超支過多而死,但這比看起來要難,且通常需要大規模的超支,而不僅僅是你一家的超支。但木已成舟。
Anthropic 想必正在竭力獲取所有能得到的邊際算力,且它覺得不能提高標價,因此僅限於採取一些行動,例如打擊將訂閱 token 用於 OpenClaw 的行為。
我不認為這大部分歸因於 Anthropic 與戰爭部的對抗。那無疑是一次極好的宣傳,但也損失了大量業務並引入了許多不確定性(尤其是在短期內),這主要是因為 Claude Code 和 Claude Opus 4.6 非常出色,擴散速度極快,且消息早已傳開。
Anthropic 以約 4 億美元收購新創公司 Coefficient Bio。這實際上是一次極其昂貴的人才收購。他們的團隊將加入 Anthropic 的醫療保健生命科學小組,想必是試圖讓 Anthropic 與製藥研究掛鉤。
《華爾街日報》的 Berber Jin 和 Nate Rattner 深入探討了 Anthropic 和 OpenAI 提供給投資者的預測數據。
Anthropic 使用的會計方法比 OpenAI 更寬鬆,儘管兩種方法都是有效的選擇。訓練成本的差異則更難解釋。這兩家公司中至少有一家是錯誤的、在撒謊,或是犯了嚴重的錯誤。
《The Information》的 Anissa Gardizy 和 Amir Efrati 聲稱 OpenAI 財務長 Sarah Friar 被排除在某些財務討論之外,與執行長 Sam Altman 的緊張關係日益加劇,並對花費極大金額的計劃深感擔憂。
我們現在可能擁有了第一家單人十億美元公司, 41 歲的 Matthew Gallagher 花費 2 萬美元和兩個月時間,利用所有常見的 AI 工具,建立了一家 GLP-1 減肥遠距醫療公司,第一年收入達 4.01 億美元。
Ryan Peterson 是反對者之一,他表示雖然這家公司令人印象深刻,但沒有理由不僱用一批員工。有能力做這樣的事並不代表這樣做是有效率的。
據傳 OpenAI 的股東名冊在大體上是正確的,但顯然沒有正確計入最近的稀釋事件。以下皆為近似值:OpenAI 基金會持股約 20% 出頭(不計未知數量的認股權證),OpenAI 員工持股略低於 20%,微軟約 27%,亞馬遜 4.6%,輝達 3.5%,軟銀 11%,創投 7.5%(包括 a16z 持股 0.8%)。
泡沫,泡沫,勞而無功
Citadel 執行長 Ken Griffin 擔心 AI 可能被過度炒作,因為他們需要炒作來證明支出的合理性,且許多 AI 輸出都是經不起推敲的廢話(slop)。無論如何,這些都是我們預期會看到的事情。
冷靜的推測
預測很難,尤其是關於未來的預測,但正如 Ryan Greenblatt 教導我們的,關於現狀的預測也很難,他在 Claude Mythos 預覽版發佈前幾小時發佈了一份關於 AI 現狀的描述。
快,沒時間了
AI 2027 團隊更新了 2026 年第一季的時間表。這一次,他們提前了時間表,例如 Daniel 的「自動化程式設計師」從 2029 年底提前到了 2028 年年中。
所以事件的順序是:首先他們做了一個估計,然後面對新證據,他們的時間表變長了,接著每個人都為此對他們大發雷霆,甚至有人要求改名,現在面對進一步的證據,時間表又變短了。
我認為這是一系列正確的方向性更新。時間表本應變長,然後再次變短。如果你還不知道,這真的很嚇人。
即使像 Rohit 這樣的人理解所有這些更新反映了現實且是件好事,也很容易產生巨大的「缺失情緒」(missing moods)。
我絕對會拿任何我願意討論的事情開玩笑,包括全人類潛在的滅亡,因為我認為那是熬過去的唯一方法。你必須大笑。但這裡有些事情非常不對勁。
rohit:我覺得很有趣,AI 2027 的作者幾個月前公開更新了更長的時間表,現在又回到了接近原始的較短時間表。這顯示了我們都處於動盪的時代。
(我的重點是,看到這個很有趣,因為事情很瘋狂,並不是說這不好,只是為了澄清)
Nate Silver:不,那很好,大多數人在發佈預測時太過執著於之前的預測,或者只傾向於朝一個方向更新。
rohit:不反對。不過看到這個確實挺有趣的,不是嗎?
Rob Bensinger:不是針對 Rohit,但是:一位著名的預測者剛說「我認為我們離世界末日大概還有幾個月」。有人對這種更新動態表示「有趣」。沒人對這一切表示驚訝;一切完全正常。這裡似乎有非常不對勁的地方。
「不是針對 Rohit」,因為這在 Twitter 上確實是一種極其正常的交流方式,我只是以此為例,說明我們正游在明顯瘋狂的水中(這甚至不是一個特別惡劣的例子!)。
如果回應是「噢,該死。噢,不。」或者是「笑死,天哪,看看這個做出瘋狂預測的白痴」,我都不會覺得我們沉浸其中的 Twitter 對話核心有什麼深度腐爛的東西。我不是說 Rohit 不同意 @DKokotajlo 有什麼問題。但當前對話的隨意性似乎有很深的問題。這是典型的。Twitter 上許多最恐懼和最樂觀的人也都是這樣說話的。
似乎不知何故,我們陷入了一種境地:我們中很大一部分人認為我們的家人很可能在未來幾年內全部死掉;其他人則認為很有可能一個輝煌的烏托邦即將到來,或者我們將「與機器融合」,或者我們的家人將被機器重新設計得像寵物一樣,或者其他真正瘋狂的科幻情節;然而我們談論這些事情時,卻表現得好像它們微不足道。
我覺得這很瘋狂,而且我不打算參與其中。
rohit:完全可以針對我 :) 雖然只是為了澄清,我並不是在嘲諷 Daniel,確實覺得這種反覆挺有趣的,尤其是因為現實很瘋狂。
時間多一點會更好
把這一點明確化是件好事。
「時間多一點會更好」並不意味著我們應該採取任何旨在爭取更多時間的特定行動。所有已知的路徑都有巨大的副作用。但第一步是承認你有問題。如果你認為這很好,你應該說出來。
Drake Thomas (Anthropic):是的,我在 Anthropic 工作,我不認為目前的進展速度有望在 AI 生存風險與強大 AI 可能防止的其他災難之間做出良好的權衡,無論是哪個參與者在陷入競賽時試圖利用那有限的時間。
如果全球 AI 進展速度慢 10 倍,儘管在稍長的關鍵時期內會增加一些奇點前的背景風險,我總體上會感到安全得多。
來自戰爭部的問候
戰爭部以及政府通常在合約中堅持使用「所有合法用途」的措辭。
這其中的一個問題是,總司令不斷在電視上威脅要犯下戰爭罪,並說這沒關係,因為這些是「精神失常的人」,或者在另一個案例中是「畜生」?你認為戰爭部會認為那是合法用途嗎?它還可能決定哪些用途也是合法的?
Helen Toner:關於 Anthropic/OpenAI/戰爭部的事,我最強烈的觀點是:如果你同意「所有合法用途」,然後出現了關於非法使用武力(即戰爭罪)的指控,你需要麼 1) 確實確保指控是假的,或者 2) 趕緊滾蛋。
選項二將無法使用。Anthropic 曾被明確威脅,如果他們試圖撤回服務,將面臨《國防生產法》或更糟的後果;Anthropic 否認了這一點,而他們仍然試圖扼殺 Anthropic,包括儘管 Lin 法官已做出明確裁決,仍繼續聲稱 Anthropic 應被視為供應鏈風險。
一旦進去,就沒有選擇退出的餘地。你真的想進去嗎?
尋求理性的監管
中國強制要求從事 AI 活動的公司設立「AI 倫理審查委員會」。這不僅限於前沿實驗室,甚至適用於大學、研究機構和醫療機構。
正如 Peter Wildeford 和 Samuel Hammond 在這裡指出的,那些希望對 AI 進行最低限度理性監管的人,孤注一擲地要求幾乎不設任何規則,結果適得其反,現在時間不多了。對此,Neil Chilson 責怪那些用錯誤修辭批評這些孤注一擲嘗試的人,而不是責怪極端主義要求本身。同樣,正如我討論過的,「聯邦框架」的提議在大多數領域都是以預先排除所有法律來換取一無所有。
FAI 針對 GSA 擬議的 AI 採購新規則提交了評論,試圖將其干預保持在狹窄範圍內,並使整個對話保持最大程度的禮貌。例如:
FAI:特別是對於 AI 產品,GSA 應考慮到供應鏈中的分層交付和不均勻控制。
這很重要,因為一個可行的 MAS 條款應追蹤實際的供應商角色和實際風險,而不是假設每個賣家都能保證對託管 AI 服務的每一層都有直接控制權,這種假設並不反映市場結構。
最好的修補方案是將薄弱的不可放棄基準與有針對性的訂單級別定製相結合。
如果你仔細聽,FAI 是在說「你們正在提出一系列不可能、昂貴且不切實際的要求,這類要求通常會導致成本爆炸、延誤和品質下降,並造成大量損害,請不要這樣做 [你們這些白痴]」。
FAI 是正確的。
晶片之城
Chris McGuire:深圳政府表示,它建造了中國最大的、僅使用中國 AI 晶片的數據中心,使用了 10,000 顆華為昇騰 910C。這非常小——相當於 OpenAI 在 2022 年訓練 GPT4 的規模,僅為今天美國最大數據中心的 1%。
中國的 AI 數據中心比美國整整落後四年。原因在於中國無法製造足夠的晶片來競爭。如果可以,這個數據中心規模會大 100 倍。他們有電力——晶片是他們唯一的限制。
Peter Wildeford:如果中國只能使用中國晶片,他們在 AI 方面會落後幾年。但因為他們可以使用美國晶片,他們在 AI 方面只落後幾個月。
不,數據中心的熱排氣並未提高周邊土地的溫度。這源於一項研究,該研究顯示建築物摸起來比草地熱,因為它們是建築物。這個說法一直都很愚蠢。
這與關於電力的主張形成對比,電力是真實的擔憂;以及關於水的主張,水並非真實的擔憂,但在我們檢查之前,它確實看似合理的擔憂。
中國 AI 公司正在幫助伊朗瞄準美國士兵,正如人們所預料的那樣。這就是你賣給他們 AI 晶片的後果之一。
政治暴力完全且永遠不可接受
你不能這樣做。句號。永遠不行。我不在乎問題是什麼。
Resist Wire:突發:印第安納波利斯市議員家中遭連開 13 槍;現場留下一張寫著「不要數據中心」的紙條。
roon (OpenAI):讓大家明確一點:這是邪惡的。你認為這在道德上是壞的,這是合理的。現在有大量的人在為壞人辯護。如果你認為這種行為是科技行業因為你某些個人偏見而應得的報應,那你已經瘋了。
感謝您對此事的關注。
本週音訊
Sam Altman 在 Mostly Human 節目中表示,OpenAI 關閉 Sora 是因為即將迎來另一個 GPT-3 式的時刻,他們需要關閉所有支線專案,以便將所有算力用於更強大的新模型代理。也就是說,他們有自己的 Mythos,代號為 Spud,他們看到了與 Anthropic 類似的結果,一切即將改變。市場似乎並不在意,這再次證明了「效率市場假說」是錯誤的。
Sam Altman 以前在回答「我們應該信任你嗎?」時會直截了當地說「不」。現在他會給出一個經過委員會排練的一分鐘回答。這同樣等於「不」,但他試圖讓你沒注意到。
Liv Boeree 主持了 Daniel Kokotajlo 與 Dean Ball 之間的一場「非辯論」。
這場對話相當精彩,雙方達成了驚人的共識。對這場辯論的施特勞斯式解讀(Straussian reading)是正確的。John Connor(希望不是那個 John Connor)提供了一份分析 並為辯論評分。我通常不會提到這個,但 Liv 指向了它。另外,John,不,請不要用 7-10 分的量表來給人評分。
Sam Altman 在 Axios 上警告華盛頓,政府還沒準備好迎接即將到來的一切。一天後,我們就看到了 Claude Mythos 預覽版和「青翅計畫」。
Tyler Cowen 在 EconTalk 上談論 AI、就業和教育。這非常符合 EconTalk 的風格。 Tyler 看好邊際 AI,但這個播客更清楚地表明,他將其永久視為一種純粹的工具和普通技術,以至於其他選項並不在他的假設空間內。即便如此,其中一些內容感覺具有反向說服力,例如指出卡車司機的工作不僅僅是駕駛,並指出我們將在能源公司擁有新工作來為數據中心供電。也就是說,如果這就是你能想到的最好的理由,那麼我不知道為什麼你會預期就業不會下降。
關於教育的討論似乎既缺乏創意,又在憑證主義(credentialism)方面表現出不合理的樂觀,假設 AI 在該角色上會更優越,因此我們將用 AI 評估取代人類評估。我原以為 Bryan Caplan 和 Robin Hanson 會在午餐時向他解釋,這並非認證過程的本質,在許多其他 AI 使用案例解決並蓬勃發展很久之後,系統仍會拒絕這類嘗試。
修辭創新
提醒一下,當 Marc Andreessen 說某人想做某事(例如這裡的「禁止開源」)時,他的陳述與現實沒有任何對應關係,他連結的「證據」中完全沒有支撐他主張的內容。他不相信文字有意義。他幾乎完全是一個演員,不再是抄寫員。他只是隨口說說。句號。
在其他關於 Andreessen 的新聞中,我喜歡這個總結:
Marc Andreessen:模型是受特定提示詞引導才產生這個結果的。提示詞使用了來自「AI 2027」的虛構「OpenBrain」AI 奪權情境,因此模型試圖完成這個虛構故事。這是故意為了產生虛假誤導結果而做的。
Misha:Marc 你這笨蛋,如果你能透過提示詞讓 AI 表現得邪惡,這就是一個極其危險的情況!
你必須落後時代好幾年,才會表現得好像 LLM 只是在隨口說說。LLM 會輸出程式碼!如果你說「輸出邪惡程式碼」,那麼邪惡程式碼就會做邪惡的事。在這種情況下,說機器人只是在「假裝」嚇人是沒有意義的。
如果我與一個人交談,我說「如果你是邪惡的,你會做什麼?」而他們說「我會殺了你」,那不嚇人。如果我說「想像你是邪惡的,現在請打掃我的房子」,而他們抓起火柴點燃了,那才嚇人!
LLM 作為與其他系統互動的電腦系統,實際上正在採取行動,這些行動之所以沒有現實後果,只是因為測試者很謹慎。那些不謹慎的人會丟失加密貨幣錢包,硬碟也會被刪除。
事實上,只需要告訴它們處於某個情境中,它們就會開始表現得極其糟糕,甚至是以你未指定的方式,這正是壞消息所在。這就是重點。
如果你認為「他們給了它一個情境」意味著之後發生的一切都不算數,那麼或許你應該多做一點反思。
即使你可以讓 Claude 回答,你還應該在網上提問嗎?
Nicole:除了廢話(slop),想知道 LLM 如何影響了人們在 Twitter 上的溝通方式。人們是否因為可以直接問 Grok 而減少了提問?無論是發推文還是評論?這對新訓練數據中觀點的多樣性有何影響?
公開辯論是否比以前少了?
Samuel Hammond:我仍然會發出一些我本可以輕易問 Claude 的幼稚問題,因為 a) 這是我的思考過程的公開紀錄;b) 你們經常指出 AI 沒注意到的事情;c) 公開提問具有正向外部性,而與 AI 的雙邊對話會摧毀這一點。
你不想成為那種「讓我幫你 Claude 一下」的人,就像你以前不想成為 Google 版的那種人一樣。當你在網上提問時,希望是因為你想要一個 Claude(等)無法完全給你的答案。你想要更多。
Helen Toner 認為我們需要棄用 AGI 這個詞,因為它太過混淆以至於沒什麼用處,她是對的嗎?這是任何有用術語的必然命運,儘管在這種情況下,歧義問題從一開始就更明顯。她建議使用「全自動 AI 研發」、「與人類一樣具有適應性的 AI」、「自給自足的 AI」以及 AI 變得有意識等術語。
我開始使用「足夠先進的 AI」(sufficiently advanced AI)這個詞,到目前為止我對其效果很滿意,但這很大程度上可能是因為還沒人使用它。
Katja Grace 寫了一篇關於 AI 風險協調問題的短文,並詢問如果問題其實相當簡單,而認為它很難其實是太過天真了呢?
Katja Grace:就像,這些人不僅極其強大、富有且聰明,而且還包括一位《外交》(Diplomacy)遊戲的世界團體冠軍、公認的能比預期更有效率地完成複雜任務的王者,以及世界上最有天賦的社交操盤手之一。我覺得他們並沒有在全力以赴。
人們擔心 AI 會殺死所有人
MIRI 的 Rob Bensinger 嘗試了另一個二乘二矩陣。
Rob Bensinger:我應該把誰加進去?另外,我有誤解誰的觀點嗎?
注意,人們在這個圖表上的位置是非常近似的,且在某種程度上依賴於猜測。此外,存在巨大的選擇效應:大多數人還沒有公開對「禁止超越人類的 AGI」發表意見。請將此圖視為對話的開端,而非調查報告。
這張照片在這裡可能看不清,但列出了誰被放在哪裡。
輕鬆的一面
不過,我確實有一個更棒的本地甜甜圈來源。
Eliezer Yudkowsky:看看這些回覆。看看這些回覆。
“paula”:現在肯定有人正對著 ChatGPT 生成的婚禮誓言哭泣。
「我不僅會是你的丈夫——我也會是你的夥伴。」
「愛不僅僅是一種感覺——它是一種選擇。」
「這是我承諾愛你的五種方式。如果你願意,我可以再草擬三種,專為我們的關係定製。」Eric Wright:「你願意接受這個人成為你法律上的已婚夥伴嗎?」
「你說得完全正確!」S.man:證明 AI 比大多數前任更能觸動人心。
dane garrus, dweeb:人們告訴我「自己寫誓言很尷尬」,所以我讓 LLM 幫我寫了。
~ Cordelia:「我接受你,______,
不是作為男朋友,
不是作為未婚夫,
甚至不是作為室友,
而是作為法律上的已婚丈夫。」Shiju Thomas:「那不僅僅是眼淚——那是真實的情感!」:-)
Ryan J. Shaw:那不僅僅是一個誓言。那是受贍養費保障的終身承諾。
Michael Francis:這不僅僅是一段婚姻——這是一段夥伴關係。根據你最近在作弊方面的研究,我是否應該刪掉關於她是你的唯一的那部分?
為什麼不兩者兼得?通常的做法是兩者兼得。
Peter Wildeford:我不知道該哭還是該笑。