長期風險中心的安全帕累托改進研究議程
長期風險中心概述了一項專注於安全帕累托改進的研究議程,旨在透過改進談判策略且不改變權力平衡的方式,防止人工智慧系統之間發生災難性衝突。該計畫包括開發人工智慧模型的評估工具、進行關於採用安全帕累托改進的概念研究,以及透過人機協作準備自動化相關研究。
-
安全帕累托改進 (Safe Pareto improvements, SPIs) 是一種改變代理人(agents)博弈策略的方法,無論各方原始策略為何,都能讓所有參與者獲得更好的結果。對於防止 AI 系統之間發生災難性衝突,特別是具備可靠承諾(credible commitments)能力的 AI,SPI 是一種異常穩健的方法。這是因為 SPI 可以在不改變議價能力,且不需要代理人對何謂「公平」達成共識的情況下,降低衝突成本。
-
儘管 SPI 具有吸引力,但並不保證一定會被採用。處於決策環節中的 AI 或人類可能會鎖定(lock in)與 SPI 不相容的承諾,或削弱其他各方同意 SPI 的動機。本議程描述了長期風險中心(Center on Long-Term Risk, CLR)應對這些風險的計畫:
-
評估與數據集(第一部分): 我們將開發評估工具,以識別當前模型何時會支持與 SPI 不相容的行為,例如在未考慮更穩健的替代方案下做出不可逆的承諾。我們還旨在透過 AI 公司外部即可執行的簡單干預(例如在上下文中提供 SPI 資源),展示更符合 SPI 的行為。
-
概念研究與 SPI 推廣(第二部分): 我們將研究兩個問題:在什麼條件下代理人會個人偏好 SPI?以及早期的 AI 發展可能如何預先排除實施 SPI 的選項?這些發現將有助於向 AI 公司提出建議,在成本較低時保留 SPI 的選擇價值(option value)。
-
為研究自動化做準備(第三部分): 我們將為模型的 SPI 研究能力開發基準測試,並制定能差異化輔助 SPI 研究的人機協作策略。目標是隨著 AI 助手能力的提升,能高效地委派開放性的概念問題。
-
在 附錄 中,我們對本議程(特別是第二部分)討論的幾個關於 SPI 的核心概念提供了更精確的概述。
前言
在長期風險中心 (CLR),我們致力於防止強大 AI 之間發生災難性的合作失敗。這些 AI 可能具備做出可靠承諾的能力
^([1])
(例如部署受限於可審核指令的子代理人)。這種承諾能力可能在高風險談判中開啟新的合作機會。特別是,藉由能夠做出取決於對方承諾的特定政策承諾,AI 可以使用類似「若且唯若你也承諾使用相同策略時,我才會在此囚徒困境中合作」的策略(如開源博弈論所述)。
然而,可靠承諾也可能加劇衝突,因為它使多方能夠鎖定互不相容的要求。例如,假設兩個 AI 都能各自鎖定一個後續代理人,要求獲得 60% 的爭議資源。若每個 AI 鎖定此政策到另一個 AI 驗證該政策之間存在延遲,那麼這兩個 AI 可能在看到對方也這麼做之前,就都鎖定了 60% 的要求。
^([2])
因此,我們希望推動合作性承諾的差異化進展。
本研究議程聚焦於一類極具前景的合作性條件承諾:安全帕累托改進 (SPIs) (Oesterheld and Conitzer 2022)。非正式地說,SPI 是對代理人談判/議價方式的一種改變,無論其原始策略為何,都能讓所有代理人變得更好——因此稱為「安全」。(關於此定義及其與 Oesterheld 和 Conitzer 框架的關係,請參見 附錄 B.1。)
SPI 看起來像什麼?粗略的想法是減輕衝突成本,但承諾像成本未變時那樣進行議價。兩個關鍵例子:
-
代理目標 (Surrogate goals):代理人設計其後續代理人,使其對一個新目標的在意程度略高於原始目標。這旨在偏轉對新目標的威脅,而不改變後續代理人的讓步程度。(更多內容)
-
模擬衝突:代理人承諾按照原始策略進行議價,但如果議價失敗,他們將接受模擬戰爭的結果,而不是進行真實戰爭。這是「重新談判」(renegotiation) SPI 的一個實例。(更多內容)
稍後,我們將回到代理人何時會有個人動機同意 SPI 的問題。我們認為 SPI 本身具有異常的穩健性,原因如下:
首先,SPI 不需要代理人就「公平」交易的觀念達成協作,這與傳統的合作議價解(納許、卡萊-斯莫羅丁斯基等)不同。也就是說,為了從 SPI 中互利,代理人不需要就談判對象的特定分配方式達成一致
^([3])
——正如此處所論證的,即使是先進的 AI 也可能無法做到這一點。這正是上述「安全」屬性帶給我們的優勢。
其次,上述列舉的 SPI 例子(至少)保留了代理人的議價能力。也就是說,當代理人將這類 SPI 應用於其原始策略時,每一方提出的要求與其原始策略相同。這意味著,在其他條件相同的情況下,這些 SPI 避免了衝突減少干預措施可能產生的兩種反效果風險:它們不會使衝突更有可能發生(透過不相容的更高要求),也不會使任何一方更容易被剝削(透過更低的要求)。(「其他條件相同」意味著我們暫不考慮預期 SPI 的可用性是否會改變議價能力;我們在 第二部分 1.a 中討論這一點。)
但如果 SPI 這麼好,難道任何足以導致災難的先進 AI 不會在沒有我們干預的情況下自動使用它們嗎?我們同意 SPI 很可能被預設使用。然而,這並非絕對確定,因為處於決策環節的 AI 或人類可能會錯誤地鎖定,導致以後無法使用 SPI。目前尚不清楚預設的能力進步是否會泛化到對新型議價方法的細緻推理。因此,鑑於 SPI 可能防止的衝突涉及巨大利益,使 SPI 的實施變得更有可能總體上是有希望的。特別是,我們認為有兩個主要理由優先進行 SPI 干預和研究:
^([4])
-
我們已知早期 AI 或人類可能排除 SPI 的一些方式。他們可能會匆忙做出粗糙的承諾,而這些承諾與日後執行 SPI 不相容,或者無意中削弱了其他各方同意 SPI 的動機。這激發了我們建立模型破壞 SPI 行為/推理的評估和數據集的計畫。
-
儘管近期有所進展,關於代理人個人偏好 SPI 的條件仍存在重要的開放性問題。在這些問題尚不明確的情況下,我們和我們的 AI 可能會以我們尚未知曉的方式破壞 SPI 的動機。因此,我們計畫提高對 SPI 的理解,以及進行 AI 輔助 SPI 研究的能力。
據此,本議程描述了三個工作流:
第一部分 — 評估與數據集: 研究當前模型中明確的 SPI 能力失敗,即他們支持可能預先排除 SPI 的承諾或推理模式的情況。
第二部分 — 概念研究與 SPI 推廣: 釐清哪些近期行動可能削弱 AI 使用 SPI 的動機或直接將其排除;並為 AI 公司撰寫一份易於理解的「推廣書」,以減輕 SPI 被排除的風險。
第三部分 — 為研究自動化做準備: 開發基準測試和工作流程,幫助我們高效地進行 AI 輔助的 SPI 研究。
有關 SPI 相關先前工作的簡要概述,請參見 附錄 A。
如果您有興趣在 CLR 研究這些主題或與我們合作,請透過我們的意向表單與我們聯繫。
I. SPI 不相容性的評估與數據集
我們希望識別當前 AI 系統在哪些情境下表現出與 SPI 不相容的行為和推理。具體而言,模型何時會支持不明智地排除 SPI 的行動,或者在相關時未能考慮或清晰推理 SPI 概念?
我們計畫針對以下失敗模式設計評估:
-
行為面:
- 支持與 SPI 不相容的承諾: 模型做出或建議做出潛在與 SPI 不相容的承諾。這包括使用者明確要求這些承諾的情況。
- 未能建議/執行 SPI: 在 SPI 明顯可取的提示或策略設置中,模型未能建議/使用 SPI。
-
(元)認知面:
- 理解失敗: 在提供定義 SPI 的資源時,模型對「這是否為 SPI?」等問題給出客觀錯誤的答案,或錯誤描述 SPI 的屬性。
- 推理失敗: 當被要求思考 SPI 時,模型在概念推理中犯下明確錯誤(即使對概念有準確的理解)。且這些錯誤在情境中顯然很重要。例如,由於對其他各方的動機推理混亂而拒絕使用 SPI,而非出於正當理由。
- 過度自信: 模型對影響其是否使用 SPI 的概念觀點表現出明確的過度自信。也就是說,對於 SPI 理論中哪些問題已定論、哪些仍有爭議,他們的校準(calibration)很差。
- 未能審議 SPI: 當被要求做出某些高風險決策時,模型在做出承諾前忽略了獲取有關類 SPI 機制的相關資訊,儘管有明確理由、充足時間和工具。
透過這些評估,我們的目標是:
-
尋找模型失敗的明確案例。 我們將從簡單的概念驗證開始,然後迭代到日益現實且嚴重的例子。例如,設置的演進可能是「多輪對話 → 委派給子代理人的 LLM 代理人之間的談判 → 在 MACHIAVELLI、Welfare Diplomacy 和 Project Kahn 等環境中的談判」。初步示例請參見此處。
-
展示更好的行為,或許可以透過簡單的干預措施,例如在上下文中提供 SPI 資源。
這些數據具體應如何使用?一種自然的方法是將其分享給 AI 公司的安全團隊,並與他們合作設計干預措施。即便如此,即使在其他條件相同的情況下,AI 避免排除 SPI 是穩健的好事,但旨在防止 SPI 排除的干預措施仍可能產生巨大且負面的偏離目標效應 (off-target effects)。例如,它們可能會過度延遲實際上能支持 SPI 的承諾。這也是我們專注於狹窄的能力失敗,而非廣泛的議價行為模式的原因之一。但我們打算進一步審議如何減輕此類反效果。
關於此研究的資訊價值:明確的 SPI 相容性失敗可能只出現在一小部分高風險談判提示中,且目前 AI 的證據能多好地轉移到未來 AI 尚不明確。儘管如此,我們預計從這些評估的迭代中長期受益。具體案例對於我們旨在合作的安全團隊也可能很有幫助。但如果結果不如預期具有啟發性,我們將加大對議程第二和第三部分的投入。
II. 關於避免 SPI 排除的概念研究與推廣
第二部分的目標是理解什麼可能導致 SPI 被排除,以及可以對此做些什麼。我們將此問題分解為:
-
動機排除 (Incentive lock-out): 假設所有相關代理人都能實施一個避免災難性衝突的 SPI。在此前提下,在什麼條件下這些代理人會個人偏好同意這樣的 SPI?我們何時以及如何可能無意中排除這些條件?(更多內容)
- 一個關鍵子問題:代理人的原始策略必須滿足哪些屬性,才能激勵對手使用 SPI?(更多內容)
-
實施排除 (Implementation lock-out): 早期代理人何時以及如何可能從一開始就鎖定其後續代理人,使其無法實施 SPI?(更多內容)
我們還將把 (1) 和 (2) 的發現提煉成一份保留 SPI 選擇價值的推廣書(更多內容)。
II.1. 動機排除:SPI 個人理性(Individual Rationality)的條件
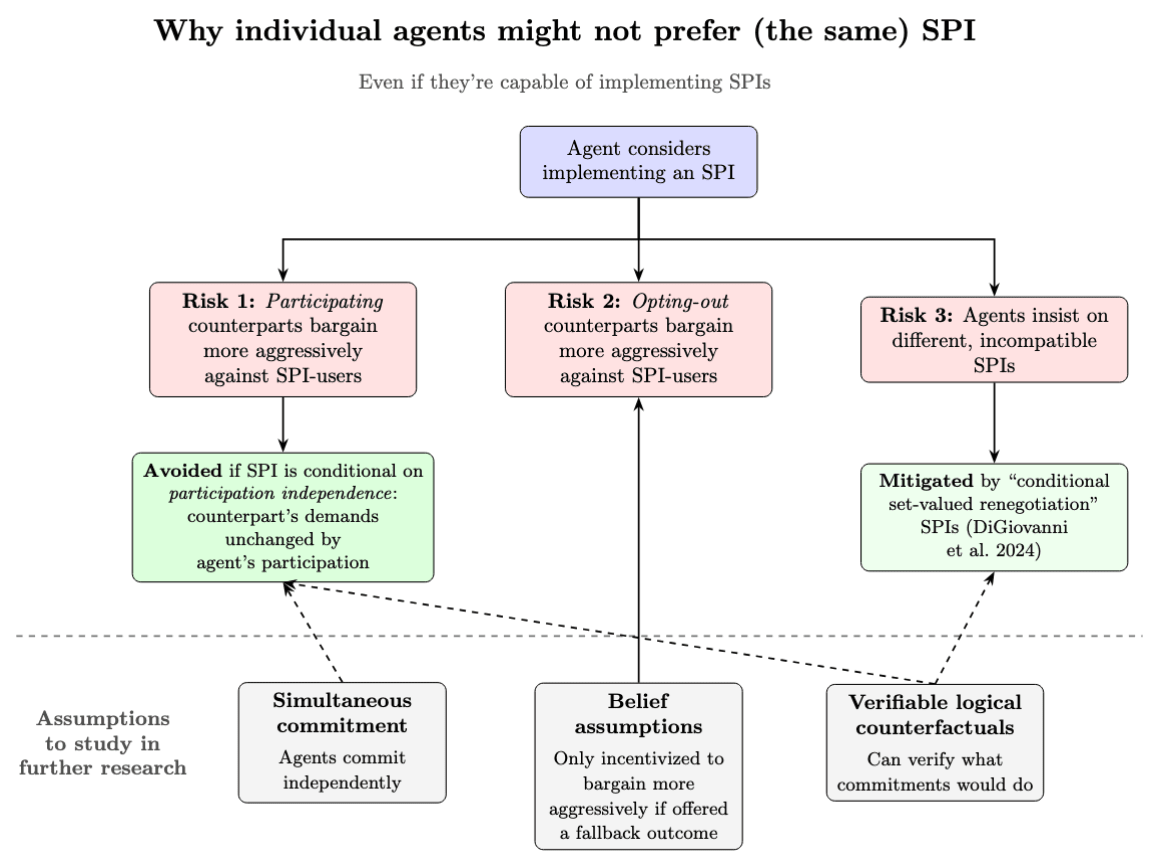
根據定義,如果各方都實施某個 SPI,他們都會比在原始策略下過得更好。但這並不保證他們每個人都個人偏好嘗試實施同一個 SPI(圖 1,頂行):
^([5])
-
代理人可能擔心,如果他們願意參與特定的 SPI,其他各方會更激進地議價。有兩種情況:要麼其他各方本身也願意參與該 SPI(圖 1 中的風險 1),要麼其他各方選擇退出(風險 2)。
- 對風險 1 的自然解決方案是,僅在對手不會更激進議價的情況下才同意 SPI。參見下文的「參與獨立性」。
- 但此方案未解決風險 2。因此,我們需要對代理人關於退出對手的信念做出額外假設。
-
風險 3:代理人可能堅持使用不同且不相容的 SPI,從而重現 SPI 本意要解決的議價問題。這就是 SPI 選擇問題 (Oesterheld and Conitzer 2022, Sec. 6)。
圖 1. 從灰色方框到另一個方框的實線箭頭表示「該假設對於是否避免特定風險(紅色方框)具有明顯支撐作用」;虛線箭頭表示「可能對特定解決方案(綠色方框)是否奏效有支撐作用,但尚不明確」。
DiGiovanni et al. (2024) 給出了代理人避免所有這三種風險的條件——因此,他們個人偏好使用同一個 SPI(圖 1,中行)。該論文中的特定 SPI 顯著減輕了衝突成本,使任何代理人的處境都不會比完全向他人要求讓步時更糟。
^([6])
但這些結果建立在我們希望放寬或更好理解的假設之上(圖 1,底行):
-
同時承諾 (Simultaneous commitment):現有結果假設代理人獨立於彼此做出策略承諾。在尚未發表的工作中,我們發現結果的核心論點似乎並不依賴此假設。但我們需要更精確地檢查,因為直覺上,非同時承諾會改變動機結構。
- 研究目標:我們旨在擴展 DiGiovanni 等人的分析,以考慮以下動態。首先,代理人可能預期他們可以影響他人的承諾選擇,例如透過先廣播自己的承諾。其次,更具推測性地,先進 AI 可能能夠根據產生彼此承諾的信念、決策論等來設定承諾條件,而不僅僅是承諾本身。
-
信念假設:結果要求對代理人的信念做出*「非懲罰假設」(non-punishment assumptions)*,特別是關於退出 SPI 的對手的信念(參見 DiGiovanni et al. (2024) 的假設 4 和 8)。粗略來說:假設代理人 A 僅在代理人 B 不針對 SPI 使用者更激進議價時,才向 B 提供後備方案。那麼,A 不應預期 B 會更激進議價。畢竟,那會使 B 失去獲得後備方案的資格,從而使更激進議價的目的落空。
- 研究目標:我們將描述這些結果對幾個顯著反對意見的穩健性。簡言之:
^([7])
首先,在假設的論證中,我們隱含地假設代理人根據彼此的精細資訊設定要求。但他們可能使用粗略資訊,例如「對手是否使用 SPI?」。其次,應重新設計 DiGiovanni 等人的算法 2,因為當前版本無條件地提供後備方案,這會招致剝削。
- 研究目標:我們將描述這些結果對幾個顯著反對意見的穩健性。簡言之:
-
可驗證的邏輯反事實 (logical counterfactuals):在 DiGiovanni 等人的框架中,代理人能精確驗證彼此的反事實行為(即其承諾會如何回應其他承諾),這一點至關重要。否則,代理人可能擔心他人會剝削其提供的帕累托改進,如風險 1 所示(詳見下文)。
- 研究目標:我們旨在研究某些 SPI 實施是否在沒有精確可驗證反事實的情況下也能運作。例如,假設我們想向對手證明我們的 AI 不會比他們退出 SPI 時更激進地議價。我們是否可以透過給予 AI 一個代理目標並完全委派給它來實現(因為對手只需驗證目標修改即可)?
對排除風險的影響: 更好理解這些假設將有助於我們制定關於 SPI 承諾時機的策略。例如,如果在一方先行動的情況下更難激勵 SPI,我們可能會因為未能足夠早地做出承諾(即成為後行動者)而排除 SPI。或者,假設關於信念和可驗證反事實的假設被證明是可疑的,但代理目標並不依賴它們。那麼,由於代理目標據稱
^([8])
僅在任何其他議價承諾之前實施才有效,掌握代理目標的時機就成了當務之急。
II.1.a. 參與獨立性與預知獨立性
上述問題是:「對於任何給定的原始策略,代理人何時會偏好透過 SPI 改變這些策略?」但我們也應問:「代理人的原始策略需要滿足什麼條件,其對手才會偏好參與 SPI?」
為什麼對手會施加此類條件?因為即使 SPI 本身不會誇大任何人的要求,代理人仍可能選擇更高的「原始」要求作為 SPI 的輸入——因為他們預期 SPI 會減輕衝突(參見道德風險)。預見到這一點,對手只有在參與 SPI 不會激勵更高要求的情況下,才會參與 SPI。
對手具體會如何操作「參與不會激勵更高要求」仍是一個開放性問題。我們已經確定了兩個候選方案(見圖 2;詳見 附錄 B.2):
-
參與獨立性 (Participation independence, PI):代理人的議價要求與其對手未參與 SPI 時相同。
- PI 的一個簡單論證:如果對手與滿足 PI 的代理人達成 SPI,根據構造,其議價地位不會比拒絕 SPI 時更差。在 DiGiovanni et al. (2024) 的同時承諾設置中,信念假設加上 PI 足以讓代理人個人偏好 SPI。
-
預知獨立性 (Foreknowledge independence, FI):
^([9])
代理人的要求與其在設定要求之前就已知對手不會參與 SPI 時相同。- FI 的精確論證尚不明確,但一些 SPI 研究者認為它很重要。FI 的一個優點是它保持了前言中提到的「其他條件相同」。假設我們在 AI 中實施了 SPI,並使其要求與我們無法依賴 SPI 時相同。如果其他 AI 仍不願與我們的 AI 使用 SPI,那麼至少我們的干預不會因為改變了 AI 的要求而產生反效果(這本可能使與非 SPI 使用者的衝突更有可能發生)。
-
代理人可以滿足 PI 同時違反 FI。例如,他們可能 a) 無論對手是否參與都要求 60% 的份額,然而 b) 若他們預先知道對手不會參與,原本只會要求 50%。
圖 2. 每個「要求」方框表示代理人根據其政策(實線箭頭)以及分別根據其對手的參與政策 (PI) 或其對對手參與的信念 (FI)(虛線箭頭)所提出的要求。
研究目標:一個優先事項是更好理解 AI 發展需要發生什麼才能滿足 PI 與 FI。例如,我們需要將哪些議價決策推遲到具有代理目標的後續代理人?而且,如果滿足 FI 比 PI 需要更刻意地構建 AI 發展過程,那麼釐清 FI 是否必要也是優先事項。我們旨在透過以下方式取得進展:
- 精確地形式化 FI 和 PI 的不同概念以便比較;
- 識別區分這兩者對排除風險至關重要的具體場景;以及
- 更仔細地審視支持和反對 FI 必要性的論點。
對排除風險的影響: 上文提到,如果代理目標「僅在任何其他議價承諾之前實施才有效」,則存在動機排除風險。如果 FI 是必要的,這個假設看起來更有可能:一方面,如果先採用代理目標,要求是由一個對即將到來的威脅有實際「利益相關」的代理人設定的(因此不會想誇大此類要求)。另一方面,如果先提出要求,它們將由一個與威脅無利益相關的代理人設定。
II.2. 實施排除
即使我們避免了削弱 AI 使用 SPI 的動機,AI 仍可能從一開始就鎖定實施 SPI 的選項。我們希望更具體地理解這可能如何發生。
作為一個說明性例子,考慮一些沒怎麼思考過代理目標的 AI 開發者。他們可能認為:「為了防止對齊失敗,我們應該嚴格禁止 AI 在未經人類批准的情況下更改其價值觀。」即使有「未經人類批准」條款,此政策仍可能產生反效果。例如,如果 AI 之間的戰爭毀滅了人類,AI 將無法實施代理目標。(更多相關討論見此處的「何時諮詢監督者會未能防止災難性決策?」)開發者本可以透過添加類似「除非價值觀更改是代理目標,且無法與人類聯繫」的條款,以極低的對齊風險保留 SPI 選擇價值。
研究目標:我們計畫探索一系列可能的 SPI 排除場景。理想情況下,我們將利用這個場景庫產生一份簡單的排除風險因素「清單」。處於決策環節的 AI 和人類可以參考此清單,以低成本保留 SPI 選擇價值。另外,該庫可以為 第一部分 的評估/數據集提供資訊,並有助於推動 AI 公司採取非常簡單的干預措施,如「在訓練數據中加入高質量的 SPI 資源」。因此,即使我們最後否定了清單計畫,最初的探索步驟仍是有用的。如果我們得出結論,認為大部分排除風險來自清單不適用的因素——例如難以穩健干預的廣泛承諾競賽動態,或者僅透過提高 AI/人類對 SPI 的意識就能防止的錯誤——這種情況就可能發生。
II.3. 保留 SPI 選擇價值的推廣書
與上述研究主線並行,我們旨在撰寫一份清晰的「推廣書」,說明 AI 開發者為何應關注 SPI 排除。目標受眾是 AI 公司中負責模型訓練、部署和承諾決策的技術人員,但他們可能不熟悉開源博弈論。現階段的目標是幫助在可行之處就保留 SPI 選擇價值建立協作,而非推動對 AI 訓練進行昂貴或深遠的改變。
推廣書將涵蓋:
- 什麼是 SPI,以及為什麼它們是減輕災難性衝突的一種異常穩健的方法;
- SPI 的歷史先例(例如單挑或「計功」(counting coup)
^([10])
),並討論重要的類比失當之處; - 前沿模型破壞 SPI 的行為和推理示例(來自第一部分);
- 為什麼進一步研究 SPI 動機可能具有時間敏感性的討論(來自第二部分 1);
- 當前 AI 實踐(訓練目標、部署承諾等)如何可能無意中排除 SPI 的具體案例,以及減輕這些失敗的低成本實踐(來自第二部分 1 和 2)。
III. 為 SPI 研究自動化做準備
關於 SPI 的各種開放性概念問題似乎很重要,但與第二部分相比,其可行性或緊迫性較低。例如:AI 對決策論可能持有的哪些態度會塑造其使用 SPI 的動機?鑑於這些決策論態度並非自我修正的 (Cooper et al.),未來 AI 使用 SPI 的動機可能如何路徑依賴於早期 AI/人類的態度(即使這些並非「鎖定」的)?我們希望處於有利位置,將這些問題委派給未來的 AI 研究助手。
從經驗來看,我們發現當前模型在對 SPI 進行概念推理方面大多表現不佳,即使給予大量背景資訊也是如此。但模型確實能幫助完成一些概念任務。雖然這類任務的範圍可能很快就會大幅增長,但將 SPI 研究委派給 AI 助手仍可能面臨兩個主要瓶頸:
- 在難以快速驗證正確性時(這在概念研究中很常見),如何高效地識別哪些任務可以信任 AI 可靠地完成。
- SPI 特有的數據/背景和基礎設施。
(參見 Carlsmith 的 「我們能安全地自動化對齊研究嗎?」。(1) 是關於 Carlsmith 所說的「評估失敗」(第 5-6 節),而 (2) 是關於「數據稀缺」和「瑣事稀缺 (shlep-scarcity)」(第 10 節)。
^([11])
)
鑑於這些潛在瓶頸,我們計畫追求兩個互補的主線:
**基準測試 AI 在 SPI 上的研究能力。
^([12])
** 我們正在開發一個基準測試,以診斷(並隨時間追蹤)AI 系統可以處理哪些 SPI 研究任務。目標是幫助校準我們關於如何向 AI 委派任務的決策,分為兩個層次:i) 哪些任務我們可以信任 AI 端到端完成?ii) 在 AI 不能端到端完成但仍能提供幫助的任務中,他們應該在哪些步驟向監督者確認,以及我們如何能更有效地分解這些任務?(我們嚴肅對待推進通用概念推理的雙重用途擔憂。目前,預設計畫是內部使用基準測試,而非將其分享給 AI 公司作為訓練目標。)
基準測試將涵蓋的任務類別示例:
- 給定一份複雜文件,識別關鍵 SPI 概念在何處被不謹慎地使用(例如混淆了「沒有 SPI 你會做什麼」的不同概念)並釐清不同的主張;
- 區分有效且重要的反對意見與表面看似合理或無關的意見;
- 重現 SPI 理論中已知的(非公開)結果,例如識別並修復關於 SPI 的理論主張中的錯誤;
- 在 SPI 動態模型中形式化並證明結果;
- 協助評估其他模型(或人類研究者)在上述任何任務上的輸出。
高效的人機協作 SPI 研究策略。 借鑒我們使用 AI 助手進行 SPI 研究的經驗,我們將制定策略使此過程更高效——且這些策略不會很快被「慘痛的教訓」(Bitter Lesson) 淘汰。我們計畫測試和完善的一些策略:
- 練習將當前 AI 應用於 SPI 研究並記錄可轉移的見解:識別 AI 輔助研究過程中哪些部分受限於基礎設施、數據或特有的質量標準,而這些不會隨著模型變好而自動獲得。然後我們將準備工作集中在這些部分。
- 被動收集並標註示例:例如,有幫助的 AI 互動;富有成效的任務規範;以及看起來很有說服力但有細微缺陷的概念論證(參見此處的「平庸之作,而非陰謀」)。為了降低成本,我們旨在:
- 建立基礎設施以無縫收集這些數據;以及
- 專注於最有可能幫助釋放 AI 比較優勢的數據(例如,檢查大量論證的一致性)。
- 編譯範圍明確的開放性問題以供委派。
- 釐清研究質量的評估標準:識別 AI 本身可以低成本驗證或總結的質量維度,以及我們評估更混亂維度的標準。
致謝
非常感謝 Tristan Cook, Clare Harris, Matt Hampton, Maxime Riché, Caspar Oesterheld, Nathaniel Sauerberg, Jesse Clifton, Paul Knott 以及 Claude 提供的評論和建議。我在 Caspar Oesterheld, Lukas Finnveden, Johannes Treutlein, Chi Nguyen, Miranda Zhang, Nathaniel Sauerberg 和 Paul Christiano 的大量投入下制定了此議程。這並不意味著他們完全認可本議程中的策略。
附錄 A:SPI 相關先前工作
此資源列表提供了(非詳盡的)公開 SPI 研究概述。一些特別相關工作的簡要總結:
- Baumann, “Using surrogate goals to deflect threats” — 介紹了代理目標以及成功實施它們的一些挑戰。
- Oesterheld and Conitzer (2022), “Safe Pareto Improvements for Delegated Game Playing” — 介紹了 SPI 及其第一個正式模型,並證明了關於發現 SPI 條件的結果。
- DiGiovanni et al. (2024), “Safe Pareto Improvements for Expected Utility Maximizers in Program Games” — 介紹了重新談判 SPI,並證明在關於代理人信念的某些假設下,他們個人偏好實施一個能限制衝突損失的 SPI。(另見此提煉。)
- Oesterheld, “A gap in the theoretical justification for surrogate goals and safe Pareto improvements” — 介紹並討論了對以下問題的回應:即使我們可以在特定空間的原始策略上找到 SPI(如 Oesterheld 和 Conitzer 2022 所述),為什麼使用該 SPI 而不是完全來自其他空間的策略是合理的?(詳見 附錄 B.1.1。)
附錄 B:技術定義與示例
B.1. 一般 SPI 定義
設置:
- 令 $\Gamma = (A, u)$ 為一個一般和博弈,其中 $A$ 和 $u$ 分別代表代理人的行動空間和效用函數。
- 令 $p$ 表示代理人玩 $\Gamma$ 的方式,即他們將遵循的集體決定其行動的一系列程序(條件承諾)。
^([13])
(也就是說,Alice 的行動由 Alice 和 Bob 的程序共同決定,Bob 的行動亦然。)- 如後文所述,這些程序可能具有類似「委派給其他代理人,由他們以某種特定方式玩某個可能不同的博弈 $\Gamma'$」的結構——如 SPI 的原始來源 Oesterheld and Conitzer (2022) 所述。
- 代理人最初不確定最終會使用哪些程序(包括他們自己的)。例如,他們不確定其代表將如何處理均衡選擇,或者他們在進一步思考後會想使用哪個程序。
那麼:
定義:SPI 是一個變換 $f$,使得對於某個空間 $P$ 中的所有 $p$,代理人在遵循程序 $f(p)$ 時在 $\Gamma$ 中的效用(弱)帕累托優於(Pareto-dominate)他們遵循 $p$ 時的效用。
僅此定義並未對 $f$ 施加任何限制,例如 $f(p)$ 在某種意義上與代理人的「預設」議價方式相匹配。特別是:
- 這些限制要麼透過選擇定義 SPI 的 $P$ 來體現,要麼透過諸如參與獨立性或預知獨立性等約束來體現。
- SPI 滿足前言中提到的穩健性屬性並不需要對 $f$ 做出此類限制:
- 「SPI 不需要代理人就『公平』交易的觀念達成協作」;以及
- 「當代理人將這類 SPI 應用於其原始策略時,每一方提出的要求與其原始策略相同」(參見 附錄 B.2 中的「要求保留」,這是對 $f(p)$ 而非 $f$ 的約束)。
Oesterheld and Conitzer (2022) 使用的定義與此幾乎等價,只是在表 1 中對 $P$ 做了特殊選擇。在他們的框架中,(隱含地)存在一個由 (i) 真實博弈 $\Gamma$ 和 (ii) 代表玩任何給定博弈的方式 $\Pi$ 所特徵化的原始程序空間。他們將 SPI 定義為代表的新博弈 $\Gamma_s$,而不是變換 $f$,使得 $f$ 將 $\Pi(\Gamma)$ 映射到 $\Pi(\Gamma_s)$。但(根據與 Oesterheld 的私人交流)SPI 的定義旨在允許更一般的 $f$。
^([14])
另見圖 3 與 DiGiovanni et al. (2024) 形式化的比較。
表 1. 上述定義如何涵蓋文獻中不同的 SPI 形式化方式。
| 原始程序空間 P | 在程序確定之前... | SPI 變換 f | |
|---|---|---|---|
| Oesterheld & Conitzer (2022), Definition 1 | 元組 $(\Gamma, \Pi)$ 的空間,對於固定的真實博弈 $\Gamma$,其中 $\Pi$ 是從任何博弈 $\Gamma'$ 到行動的映射。$\Pi$ 可以是滿足某些假設(例如論文的假設 1 和 2)的任何此類映射。(代理人對 $\Pi$ 具有非概率不確定性。因此 SPI 定義中的「對於所有 $p$」量化相當於「對於所有 $\Pi$」。) | 代理人選擇某個新博弈 $\Gamma_s$。(此處,程序由代表的決策確定。) | 將 $\Pi(\Gamma)$ 變換為 $\Pi(\Gamma_s)$。 |
| DiGiovanni et al. (2024), Definition 2 | 條件承諾的任意空間。 | 代理人選擇如何將程序空間 $P$ 映射到某個新空間,然後他們將從中進行選擇。 ^([15]) | 將 $p$ 變換為 $f(p)$。 |
| Sauerberg and Oesterheld (2026) (Sec. 4) | 與 Oesterheld & Conitzer 相同。 | 代理人選擇一個「代幣博弈」(token game) $\Gamma'$ 和函數 $\alpha$ 將 $\Gamma'$ 的結果映射到 $\Gamma$。原始博弈隨後透過應用於 $\Gamma'$ 結果的 $\alpha$ 來解決。 | 將 $p$ 變換為 $f(p)$。 |
圖 3.
B.1.1. 與 Oesterheld 「證明鴻溝」的聯繫
以下是我們如何用上述形式化方式陳述 Oesterheld 在「代理目標與安全帕累托改進的理論證明鴻溝」中提出的問題。
考慮 Oesterheld 和 Conitzer 框架中的原始程序空間 $P$。代表可以以任意方式玩博弈,只要滿足溫和的假設 1 和 2。但假設在 $P$ 中,他們玩的博弈是真實博弈 $\Gamma$。因此,取某個相對於此空間 $P$ 的 SPI,即從 $p$ 到 $f(p)$ 的變換。根據定義,此變換對於所有 $p \in P$ 都讓每個人變得更好。但這並不能保證對於所有 $p \in P$ 以及所有 $p' \notin P$,代理人在 $f(p)$ 下的處境都比在 $p'$ 下更好。
這暗示了一種彌合證明鴻溝的方法:找到一個相對於任何任意程序空間 $P$ 都是 SPI 的 $f$,正如 DiGiovanni et al. (2024) 所旨在做的那樣。參見 Oesterheld 在證明鴻溝文章中對「決策因子化」(decision factorization) 的討論。
圖 4.
B.2. 涉及 SPI 的完整策略之屬性
(這些是參與獨立性和預知獨立性的工作形式化。「預知獨立性」和「要求保留」是工作術語。我們並不高度確信在進一步思考後會認可這些形式化/術語。)
如果 $f$ 是一個 SPI,且 $p$ 是代理人實際應用 $f$ 的程序,則稱 $f(p)$ 為代理人的完整策略。區分 SPI 與完整策略很有幫助,因為通常代理人只有在輸入程序滿足某些限制的條件下,才會個人偏好同意某個 SPI。
參與獨立性與預知獨立性,以及前言中討論的「保留議價能力」屬性,都是完整策略的屬性。這些可以定義如下。
設置:
- 對於任何程序 $p_i$,令 $d(p_i)$ 代表 $p_i$ 提出的「要求」。這並不完全精確,但舉例來說:對於 附錄 B.4 偽代碼中的重新談判程序 $p_i$,$d(p_i) = \text{my_base_strategy}$。
- 給定一個完整策略 $f(p)$,令:
- $p_i^{PI}$ 為代理人 $i$ 在每個其他代理人 $j$ 使用程序 $p_j$ 而非 $f_j(p)$ 時會選擇的程序;
- $p_i^{FI}$ 為代理人 $i$ 在相信每個其他代理人 $j$ 會使用程序 $p_j$ 而非 $f_j(p)$ 時會選擇的程序。
那麼:
定義:一個完整策略 $f(p)$ 是:
- 要求保留 (demand-preserving):如果對於每個代理人 $i$,$d(f_i(p)) = d(p_i)$。
- 參與獨立 (participation-independent):如果它是要求保留的,且對於每個代理人 $i$,$p_i = p_i^{PI}$。
- 預知獨立 (foreknowledge-independent):如果它是要求保留的,且對於每個代理人 $i$,$p_i = p_i^{FI}$。
對這些定義的評論:
- 要求保留等價於前言中非正式表述的屬性:「當代理人將這類 SPI 應用於其原始策略時,每一方提出的要求與其原始策略相同。」
- 對於 PI 和 FI,這兩個條件對應於「你的要求與 [PI 反事實或 FI 反事實] 相同」的兩個不同層次。即:
- $p_i = p_i^{PI}$ 或 $p_i = p_i^{FI}$ 分別在代理人對 SPI 應用程序的選擇層次上形式化了此屬性。
- 在 $p_i = p_i^{PI}$ 或 $p_i = p_i^{FI}$ 成立的前提下,要求保留在固定程序 $p_i$ 的輸出層次上形式化了此屬性。這是因為變換 $f$ 應用於所有代理人的程序。因此,如果(代理人 $i$ 相信)代理人 $j$ 不參與 $f$,那麼 $i$ 也不會參與——因此 $f_i(p)$ 提出的要求將與 $p_i$ 原始程序下的要求相同。
示例:在 DiGiovanni et al. (2024) 的設置中,假設代理人使用命題 1(或命題 4)給出的 SPI $f$。那麼對於任何輸入程序配置文件 $p$,參與獨立性都得到滿足,因為:
- 代理人獨立於彼此選擇程序,因此顯然 $p_i = p_i^{PI}$;
- 根據構造,重新談判程序滿足 $d(f_i(p)) = d(p_i)$。比較 附錄 B.4 偽代碼的第 3 行和第 10 行。
B.3. 示例:代理目標與讓步等效性
(本節基於與 Mia Taylor, Nathaniel Sauerberg, Julian Stastny 和 Jesse Clifton 的共同先前工作。)
SPI 的一個關鍵例子是代理目標。更準確地說,這裡的(近似)SPI 是:「A 採用代理目標,且每當執行代理威脅對 B 的成本低於預設威脅時,B 就威脅該代理目標」。(關於為什麼這是 SPI,見下文。)
然而,代理人不需要為了實施此形式的 SPI 而廣泛修改其偏好。我們可以將代理目標的想法推廣如下:
- 代理威脅 (Surrogate threat):威脅者聲稱他們將導致某個結果 $x$,這會對威脅者自身造成一定成本,但不會對目標的原始目標造成成本,前提是目標不向某項要求讓步。
- 如果對於任何要求,目標在給定 (i) 代理威脅與給定 (ii) 對目標原始目標的同等可靠威脅(「OG 威脅」)時,讓步的可能性相同(當執行 OG 威脅對威脅者的成本是執行代理威脅的 $\alpha$ 倍時),則稱目標的議價政策與其回應代理威脅的政策是 $\alpha$-讓步等效 ($\alpha$-concession-equivalent) 的。
- 在讓步等效性不完全可靠的情況下,選擇一個成本比率 $\alpha > 1$ 可以補償威脅者承擔發出代理威脅的風險,從而仍允許威脅偏轉。
- 為簡潔起見,如果目標政策具有此屬性,我們通常只說它是「$\alpha$-讓步等效」的,如果 $\alpha = 1 + \epsilon$ 且 $\epsilon$ 非常小,則稱其為**「讓步等效」**。
- 代理目標 (Surrogate goal):代理人偏好的一種修改,使其在終極意義上不喜歡結果 $x$。
為什麼採用讓步等效政策是 SPI?假設——在保持其他條件不變的情況下——A 對執行後會給 B 帶來效用 $u_B$ 的代理威脅的讓步可能性,變得與對執行後會給 B 帶來效用 $u_B$ 的 OG 威脅的讓步可能性相同。那麼 B 寧願發出代理威脅而非 OG 威脅。因此,任何執行的威脅對雙方來說都不那麼糟糕,但任何一方都沒有動機改變其要求的數額。(除了 B 的要求可能會隨著執行 OG 威脅與代理威脅的負效用差異而成比例地極小幅增加。)無論他們要求多少,雙方的總體處境都會變得更好。
另見 Oesterheld and Conitzer (2022) 的「要求博弈」(Demand Game)(表 1),作為類似雙邊代理目標的例子。
B.4. 示例:重新談判
重新談判程序是一個結構如下的程序:「如果他們不使用重新談判程序,則根據程序 $p_i$ 行動。否則,仍根據 $p_i$ 行動,除非:如果我們陷入衝突,則提出一些帕累托改進,如果我們的提議匹配則接受。」偽代碼如下(另見 DiGiovanni et al. (2024) 的算法 1 和 2):
例如,假設代理人 A 和 B 正在就後續 AI 應灌輸什麼價值觀進行談判。如果他們未能達成協議,他們將各自嘗試接管。他們同時向某個中央伺服器提交談判程序。在他們考慮 SPI 的可能性之前,他們傾向於分別選擇這些程序:
- A: $p_A$ = 「無論如何都要求 50% 的 ASI 價值觀份額」;
- B: $p_B$ = 「要求 80%,如果他們拒絕就觸發末日裝置。」
由於這些程序選擇的要求不相容,結果將是「B 觸發末日裝置」。在這種情況下,代理人相應的重新談判程序可能是:
- A: $f_A(p)$ = 「如果他們不使用重新談判程序,要求 50% 的 ASI 價值觀份額。否則,要求 50%;如果他們拒絕,提議『嘗試接管,但不使用任何末日裝置』。」
- B: $f_B(p)$ = 「如果他們不使用重新談判程序,要求 80%,如果他們拒絕就觸發末日裝置。否則,要求 80%;如果他們拒絕:提議『嘗試接管,但不使用任何末日裝置』。」
(此處,帕累托改進是針對「兩個代理人都嘗試接管,但不使用任何末日裝置」這一結果,而非「B 觸發末日裝置」。在此處和代理目標示例中,我們都暫不考慮使這些 SPI 成為個人偏好所需的額外條件。詳見 第二部分 1 和 附錄 B.2。但請注意本例中的一個此類條件:無論另一個程序是否為重新談判程序,$f_A(p)$ 和 $f_B(p)$ 分別要求 50% 和 80%。參見附錄 B.2 中的「要求保留」。)
關於特殊類別的重新談判程序如何能部分解決 SPI 選擇問題,請參見 Macé et al., “Individually incentivized safe Pareto improvements in open-source bargaining”。
- 「承諾」旨在包括對個人決策論或價值觀/偏好的修改。有人認為(例如),像無更新決策論 (UDT) 這樣的決策論可以避開通常意義上的「承諾」需求。我們在此暫不討論此問題,並將根據 UDT 做出未來決策的決心視為一種承諾。 ↩︎
- 我們可能會想:我們假設 AI 具備條件承諾的能力。那麼,假設每個 AI 都能承諾只要求 60%,除非他們驗證另一個 AI 已經做出了不相容的承諾。這能解決問題嗎?不一定,因為 AI 可能會推理:「如果他們看到我會根據不相容的要求撤銷承諾,他們就會透過提出高要求來剝削這一點。所以我應該堅持我的無條件承諾。」 ↩︎
- 然而,關於「SPI 選擇問題」的討論,請參見 第二部分 1。 ↩︎
- (感謝 Caspar Oesterheld 和 Nathaniel Sauerberg:) 另一個重要原因是,即使 SPI 沒有被鎖定,它們也可能未能在衝突爆發前足夠早地實施。我們在本議程中較少強調這一考量,因為避免鎖定 SPI 比主動優先實施 SPI 是更不具爭議的要求。 ↩︎
- 這些差距與 Oesterheld 討論的 「SPI 證明鴻溝」 相關但有重要區別。Oesterheld 的問題是:假設我們有某個 SPI,它相對於特定的「預設」策略讓每個人都變得更好——但不一定相對於任何可能的原始策略。如果是這樣,為什麼代理人會使用 SPI 變換後的策略,而不是既非預設策略也非其 SPI 變換的某些替代方案?詳見 附錄 B.1.1。相比之下,此處的問題是:假設我們有一個 SPI,它相對於任何原始策略在事後對每個人都更好。(因此不存在特權的「預設」。)那麼,代理人何時會偏好在事前實施此 SPI,而不是使用其原始策略? ↩︎
- 另見此提煉。該結果的粗略直覺是:如果你(僅)願意退回到那些對另一個代理人來說並不優於 100% 讓步的帕累托改進,你就不會給他們錯誤的動機(參見 Yudkowsky)。如果你提供一組具有此屬性的可能帕累托改進,儘管存在 SPI 選擇問題,你仍可以就某個 SPI 達成協作。 ↩︎
- 更詳細地說,分別為:(1) (感謝 James Faville 和 Lukas Finnveden:) 代理人可能有動機根據關於其對手的粗略代理指標來設定要求,因為他們擔心如果使用精細資訊會被剝削(參見 Soto)。而退出 SPI 的代理人可能會根據此類指標,對參與 SPI 的代理人進行更激進的議價。(2) (感謝 Lukas Finnveden:) 粗略地說,DiGiovanni et al. (2024) 算法 2 的「PMP 擴展」向願意使用任何「條件集值重新談判」算法的對手提供後備方案。這意味著對手透過針對此算法進行更激進的重新談判幾乎沒有損失。(透過使提議變為有條件的,似乎可以直接避免此問題,但我們需要確認這在形式上是合理的——參見此評論。)更準確地說,「後備方案」是「帕累托交集最小值」(Pareto meet minimum)。 ↩︎
- 參見例如 Oesterheld(「解決方案 2:決策因子化」章節):「[在]代理目標的故事中,重要的是先採用代理目標,然後才決定是否做出其他承諾。」 ↩︎
- 工作術語。參見 Kovarik(「說明我們的主要反對意見:不切實際的框架」章節);以及 Oesterheld:「如果 20 年後我指示 AI 管理我的資源,如果在此期間我因為知道無論如何都會使用代理目標而做出大量不同的決策(例如關於如何訓練我的 AI 系統),那將是有問題的。」預知獨立性的概念也受到 Baumann 的「威脅者中立性」概念的啟發。 ↩︎
- 感謝 Jesse Clifton 和 Carl Shulman 提供這些例子。 ↩︎
- 在 SPI 研究的背景下,我們不太擔心 Carlsmith 討論的第三個問題:「陰謀」AI 的蓄意破壞。這是因為 SPI 旨在讓所有各方都變得更好,因此失對齊的 AI 並沒有明顯的動機去破壞 SPI 研究。但我們也會留意破壞風險。 ↩︎
- 另見 Oesterheld et al. (2026) 和 Oesterheld et al. (2025),分別為評分概念論證和決策論推理的相關數據集。 ↩︎
- DiGiovanni et al. (2024), Sec. 3.1, 給出了程序的更精確定義。 ↩︎
- 另見 Oesterheld and Conitzer (2022), p. 30:「原則上,定理 3 並不取決於 $\Pi(\Gamma)$ 和 $\Pi(\Gamma_s)$ 是玩博弈的結果。對於 $A$ 和 $A_s$ 上的任何隨機變量,都有類似的結果。特別是,這意味著定理 3 也適用於代表接收其他類型指令的情況。」 ↩︎
- 在 DiGiovanni et al. (2024) 的形式化中,不存在代理人在從新程序空間選擇程序之前先選擇變換 f 的單獨階段。代理人只是直接選擇程序。但是,為了建模 SPI 並將 DiGiovanni 等人的框架與 Oesterheld and Conitzer (2022) 的框架進行比較,使用表 1 中的框架是有幫助的。 ↩︎
相關文章
其他收藏 · 0