
邁向以生成式 AI 培養未來就緒技能之路
Google 研究部門與紐約大學合作推出了 Vantage 研究實驗,這是一個利用生成式 AI 在模擬環境中評估與培養批判性思考及協作等未來就緒技能的平台。研究結果顯示,AI 的評分準確度已與人類專家相當,為過去難以量化的核心素養提供了可規模化的評估方案。
邁向以生成式 AI 培養具備未來競爭力的技能
2026 年 4 月 13 日
Gal Elidan,研究科學家,以及 Yael Haramaty,Google Research 資深產品經理
我們的新研究展示了一種利用生成式 AI(GenAI)評估「未來就緒」(future-ready)技能的新穎方法。我們與紐約大學合作的研究結果發現,AI 的評分表現與人類專家不相上下。這項名為 Vantage 的研究實驗現已在 Google Labs 開放。
快速連結
隨著 AI 以空前的速度演進,人們重新關注「未來就緒」技能——即無論技術變革或自動化如何發展,仍能保持價值的持久人類能力。國際框架(如 OECD 2030 學習指南和世界經濟論壇的《未來就業報告》)已確定了一系列優先技能,兩者都強調了相同的核心能力,包括批判性思考、協作和創造性思考。雖然這些技能在 AI 興起之前就被認為至關重要,但現在它們變得比以往任何時候都更加關鍵。
今天,我們分享 Vantage,這是一個利用生成式 AI 在模擬環境中建立對話,藉此評估未來就緒技能的研究實驗。Vantage 是與紐約大學的教育學專家和研究人員合作開發的,旨在為高中生和大學生提供一個練習和驗證評估的沙盒環境,其構建採用了傳統上用於數學或科學等核心學科的系統化方法。Vantage 現已在 Google Labs 開放英文版註冊。
衡量難以衡量的指標
任何有效學習過程的核心都是回饋與評估,這兩者對於個人成長和有效教學都至關重要。在全球教育體系中,通常是「衡量什麼,就教什麼」。
然而,未來就緒技能以難以衡量而著稱。典型的測試過於僵化,無法捕捉人們的思考過程和互動,且與現實世界中使用這些技能的方式相去甚遠。雖然在真實的人際互動中測試這些技能最為理想,但這也過於耗費資源,且難以在眾多學生中實現標準化和一致的評分。例如,如果一個小組從不產生分歧,你該如何公平地評估其衝突解決能力?或者如果他們直接採納第一個出現的想法,又該如何評估他們在彼此想法基礎上進行創造性構建的能力?
我們的研究團隊致力於探索如何使用一種可擴展、經驗證的方法來評估學生的未來就緒技能,從而賦予教育工作者能力,使課程與這些技能保持一致並支持學生髮展。
使用 AI 模擬團隊評估技能
Vantage 的實驗設置將學習者置於動態的多方對話中,與 AI 虛擬角色共同協作完成任務。這種設置使我們能夠控制評估環境,同時模擬比現有標準化測試更真實、更具現實代表性的互動。它提供了一個沙盒,用於應對複雜的人際和情境挑戰。
當使用者在開放式場景(如準備辯論或推銷創意願景)中與 AI 虛擬角色互動時,一個「執行大型語言模型」(Executive LLM)會根據提供的評估量表引導 AI 虛擬角色進行有效的評估。執行 LLM 會不斷分析對話狀態,動態地引入特定挑戰——例如反對某個想法或引入衝突——為學習者提供展示技能的針對性機會。因此,它充當了下一代自適應評估引擎,引導對話,以便在對話結束時收集到評估使用者所需的資訊。

基於 LLM 的評估協議示意圖。當學習者參與開放式任務時,執行 LLM 使用量表來引導 AI 虛擬角色並引入動態挑戰。這會引發學習者表現的針對性證據,隨後由 AI 評估器進行分析,以實現即時技能評分和回饋。
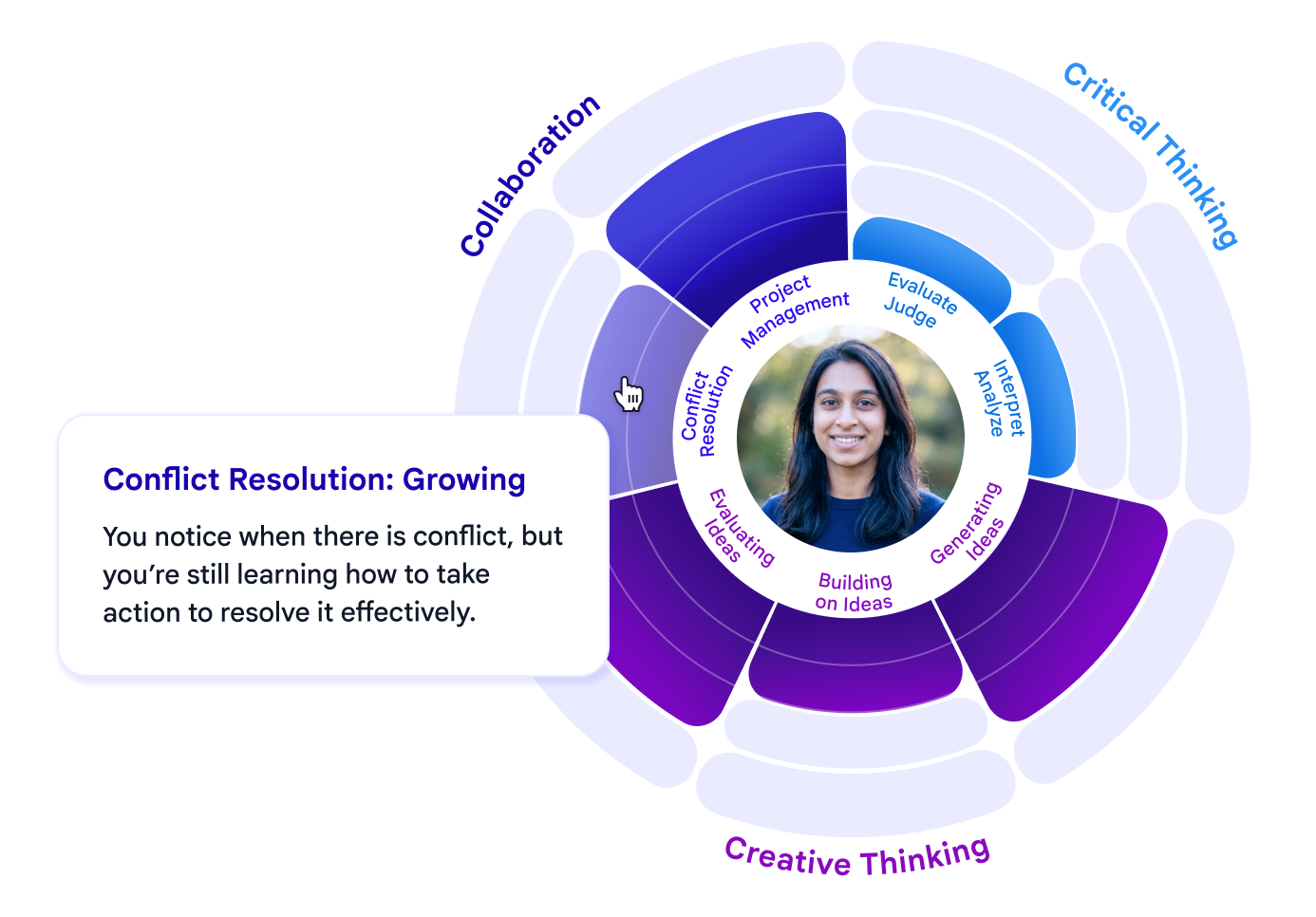
任務完成後,AI 評估器會根據執行 LLM 所使用的同一套嚴格評估量表來分析對話逐字稿,以識別並衡量技能應用的具體證據。學習者隨後會收到一份詳細的技能圖譜,包括視覺化評分以及針對其在對話中展示的技能所提供的定性回饋。這使得人類技能發展中「隱形」的進步變得可見且可操作。

呈現給使用者的技能圖譜和回饋範例,包括目前 Vantage 涵蓋的技能和子技能。
與合作夥伴共同驗證技能評估方式
為了確保學術和教學的嚴謹性,我們與紐約大學建立了研究合作夥伴關係。我們共同調查了常見的評估量表,並將其與相關任務對齊。此次合作的主要重點是建立並驗證評估方法。我們透過一項聯合研究完成了這項工作,共有 188 名來自美國、年齡在 18-25 歲之間的測試者參與,他們完成了 Vantage 任務,評估樣本協作技能:衝突解決和專案管理。我們探討了兩個主要的研究問題:
1. 我們能否引導對話來測試特定技能?
Vantage 的一項關鍵創新是使用執行 LLM 來實現自適應評估。我們評估了 LLM 在一次針對一項特定技能(如衝突解決或專案管理)引導對話方面的有效性。我們衡量了使用者針對該技能展示的技能相關資訊量,並與學習者在同一任務中與獨立且未受引導的 AI 虛擬角色互動的情況進行對比。我們的研究結果表明,執行 LLM 成功地引導了對話以產生高密度的資訊,並在保持自然對話流的同時,顯著增加了關於被評估技能的資訊。這種能力在多個模擬任務中表現一致。更多結果和關於方法的細節可以在技術報告中找到。

對話中的資訊率:長條圖代表為衝突解決和專案管理學科技能水平評分提供足夠資訊的對話比例。圖中顯示了執行 LLM 策略(藍色)與獨立虛擬角色模型(橘色)之間的比較,後者的 AI 虛擬角色回應是在沒有協調的情況下獨立生成的。星號 (*) 表示策略之間存在統計學上的顯著差異。
2. LLM 評分未來就緒技能的準確度如何?
為了測試 AI 評估器的準確性,我們將其評分與使用相同教學量表的紐約大學評分員的評分進行了比較。結果顯示,AI 評估器與人類專家之間的一致性,與兩位專家評分員之間的一致性相似。這表明 AI 評估器的對話評分與人類專家評分員相當,確立了 Vantage 作為一個有效的自動化技能評估系統。

技能評分的評分者間一致性:人類評分者之間(Human-Human)以及基於 LLM 的評分者與人類評分者之間(Human-LLM)的評分一致性比較。一致性是使用帶有二次權重的 Cohen’s Kappa 計算的,針對衝突解決和專案管理技能。
我們還與 OpenMic 合作,這是一家開發 AI 驅動工具以評估持久技能的新創公司。我們共同進行了一項關於創造力和英語語言藝術的研究,以在另一個背景下測試 AI 評估器。我們分析了 180 名學生在創意多媒體任務上的表現(例如與英語文學相關的角色訪談和媒體文章),並將 AI 評估器的評分與 OpenMic 內部專家的評分進行了比較。在這裡,AI 評估器與人類專家之間也存在高度相關性,證明了 AI 評估器即使在複雜的現實世界創意任務中也能提供有效的評分。

創造力評分一致性:LLM 評分與人類專家對複雜創造力任務的評分。評分高度對齊,皮爾森相關係數(Pearson’s correlation)為 0.88。
展望未來:融入課堂
在學校環境中,這種模擬環境可以為可衡量的「技能層」鋪平道路,該層位於現有學校課程之上,並整合到學術任務中。這將使教育工作者能夠構思新形式的作業,例如,與 AI 虛擬角色辯論社會科學話題,或擔任規劃實驗室實驗的團隊負責人。學生可以收到關於他們對學科內容理解(例如實驗室實驗的科學知識)以及他們的技能(例如協作質量和批判性思考)的回饋。這種方法將是對現有與其他學生合作的小組專案的補充,並有潛力同步支持學術知識和持久技能的發展。

實現大規模的未來就緒能力
這項研究探索了我們如何將基本的、具備未來競爭力的持久技能,從難以衡量轉變為可大規模衡量。透過這樣做,更具包容性和準確性的未來就緒表現將成為可能。這項實驗是邁向與未來需求更緊密結合的評估方法的一步。
我們也希望我們的新基礎設施能支持整個生態系統中進一步的研究和成效研究。研究人員現在不僅能夠評估新工具對知識保留的影響,還能評估它們對技能發展的直接影響。此類研究的潛力巨大,能讓我們更深入地了解不同的教學干預如何隨著時間塑造人類的能力。
展望未來,我們正在擴大研究範圍,以解決關鍵的「遷移性」問題——即在模擬沙盒中展示的技能如何轉化為現實世界的人際互動。此外,意識到人類技能具有文化背景,我們將專注於探索不同環境下的表現,以確保我們的技術具有包容性和公平性。除了評估之外,下一階段是邁向技能成長,加深我們的理解並衡量透過模擬環境練習進行技能開發的成效。
致謝
感謝為這項工作做出貢獻的 Google 團隊成員:Alon Harris, Alex Moy, Amir Globerson, Anisha Choudhury, Anna Iurchenko, Ayça Cakmakli, Ben Witt, Cathy Cheung, Diana Akrong, Elisabeth Bauer, Hairong Mu, Julia Wilkowski, Lev Borovoi, Lucile Martini, Maya Alva, Nir Kerem, Noa Kerrem Gilo, Preeti Singh, Rajvi Kapadia, Rena Levitt, Roni Rabin, Rotem Yulzary, Shashank Agarwal, Sophie Allweis, Tal Oppenheimer, Taylor Goddu, Tracey Lee-Joe, Tzvika Stein, Yaniv Carmel, Yishay Mor, Yoav Bar Sinai, 以及 Yuri Lev。感謝我們的紐約大學合作夥伴 Yoav Bergner 及其團隊,以及來自 OpenMic 的合作夥伴:Aviad Segal, Eliad Carmi, Hadas Gelbart, 以及 Yael Bar Moshe。我們感謝德州大學奧斯汀分校的 Cristine Legare,以及創業教學網絡(NFTE)總裁兼執行長 J.D. LaRock 提供的見解。特別感謝我們的執行贊助人:Niv Efron, Avinatan Hassidim, Amy Keeling, Katherine Chou, Yossi Matias, Ronit Levavi Morad, Chris Phillips 和 Ben Gomes。
快速連結
其他感興趣的文章

2026 年 4 月 9 日

2026 年 4 月 8 日

2026 年 4 月 3 日





相關文章
其他收藏 · 0