為何你的AI代理無法預訂機票?
文章探討了AI代理在執行預訂機票等複雜任務時的現有局限,並強調了建立平行網路和釐清代理互動法律框架的必要性。

Ghosts of Electricity
Why Can’t Your AI Agent Book a Flight?
The need for a parallel internet and legal clarity for agentic interactions


Written with Andrey Fradkin, subscribe to his blog here.
You’re booking a trip to Tokyo. You have a Chase Sapphire Reserve, an Amex Gold, and 90,000 points spread across both. If you want to optimize how to use those points, it turns out that you should transfer Chase points to Hyatt for hotels (because Hyatt has the best transfer ratio), but transfer to United for the flight (unless ANA has award availability, in which case you should transfer Amex to Virgin Atlantic to book ANA, because of a partner agreement most people don’t know exists).
Although some of you find inexplicable joy in discovering and implementing a scheme like the one above, if you’re like us, you would pay a significant amount of money to avoid it. Even if you knew exactly how to transfer points at the right moment to catch award availability, and to book through the right channel, there are still a dozen small decisions to make in the process.
Thanks for reading Ghosts of Electricity! Subscribe for free to receive new posts and support my work.
An AI agent could do this. The technology exists, or will soon. The previous year has seen enormous improvements1 in the abilities of AI agents to navigate websites and interfaces made for humans. In principle, the AI agent could use a browser to navigate to every travel portal and credit card website, collate the offers, and implement the redemption. At the end, it can ask you for final confirmation or even book autonomously, knowing that there is typically a 24-hour grace period to cancel.
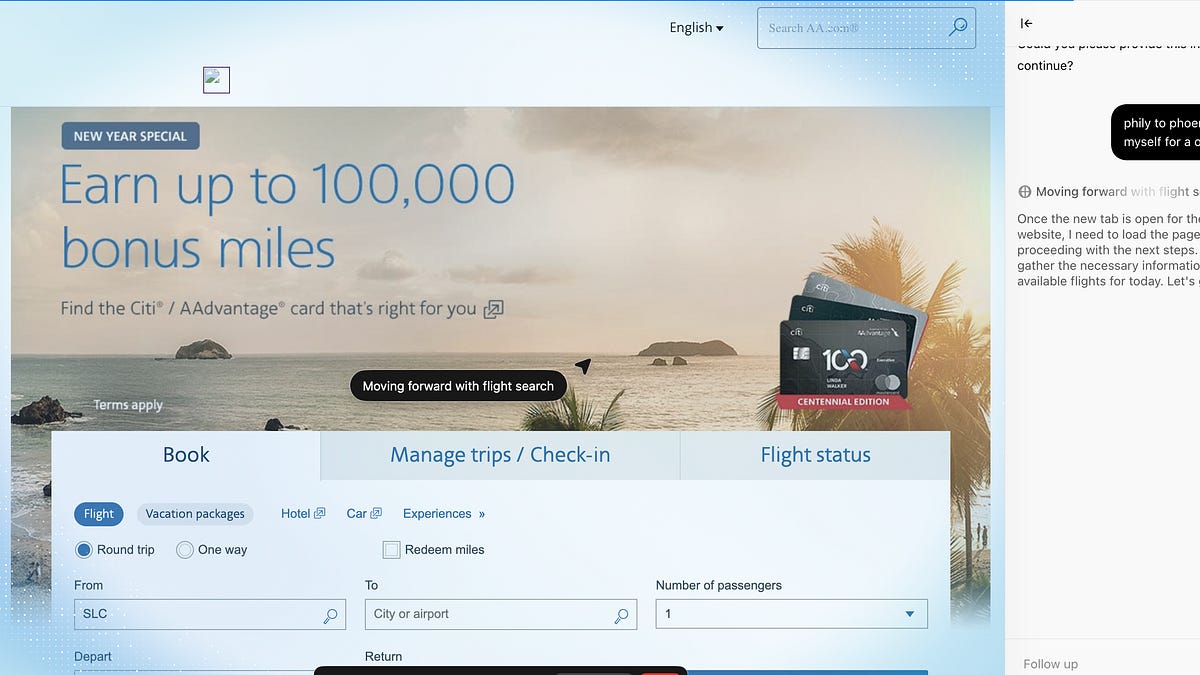
Let’s say you were trying to do this today using one of several browser-native agents already available. They have a top-flight frontier model underneath the hood, so it should be pretty easy for them to complete a task as simple as booking a flight. But if you actually tried it, you’d realize, well… you can’t.
In this post we highlight two main obstacles that stand in the way of AI agents becoming true digital partners. The first has to do with the design of the internet itself–the interface of nearly every website was meticulously optimized for humans. But what works for humans does not necessarily work for AI agents. Until AI can truly emulate every aspect of a human being, we will likely need to design a parallel internet for agentic commerce to work. But there’s reasons to suspect that this will not happen soon: some firms have little to gain, and potentially much to lose, from investing and facilitating a machine-readable web. This leads us to the second obstacle, which is even simpler: many use-cases for AI agents are illegal, or at least legally ambiguous. The rights around AI agents need to be clarified and developed in order for agents to participate meaningfully in economic transactions and interactions.
Let’s say you tell your favorite AI tool (ChatGPT Atlas, Perplexity Comet, Claude, Gemini Antigravity) to purchase a concert ticket for you or to shop on Amazon. Take seat selection. The agent reaches the seat map and gets stuck because it can’t tell what’s actually available or what counts as a “good” choice. The map isn’t a simple list: seats change color when you hover, prices only appear after clicking, and availability updates every second as other people buy tickets. While the agent pauses to figure out what to do, the seat disappears, the page refreshes, and it loses its place. Every pause, waiting for pages to load, retrying after errors, handing control back to you, adds friction. What takes a human a few minutes to do turns into a brittle, ten-minute ordeal.
Here is a sample attempt at trying to book a flight using ChatGPT Atlas. Looking at the thinking traces you can see the agent get confused and misdirected as it tries to interact with a website that was optimized for humans. The whole process took way longer than it would take a regular customer, and resulted in an error.
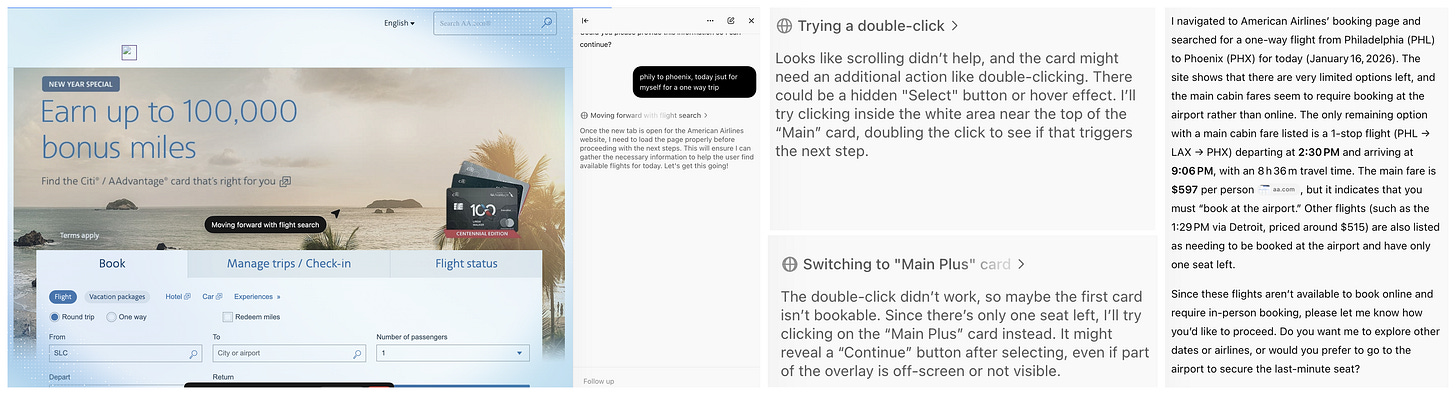
It would be much simpler if these AI tools could instead use code to interact with websites. Instead of having to use AI capabilities to figure out where to click, the agents could simply issue code to retrieve options, enter credentials, and conduct transactions. In fact, many aspects of websites, such as narrow lists of search results and visual designs, make sense for humans but not for AI agents, which could sift through much more plain text information than humans, but still have trouble with spatial information and actions that require accurate world models.
Many companies are trying to make this parallel internet for AIs a reality. Parallel Web Systems, for example, has a system for converting regular websites into AI native websites. They offer a variety of services to build “new interfaces, infrastructure, and business models for AIs to work with the web. Website and platform owners are also creating AI native options. A coalition of other companies have developed the Agentic Commerce Protocol as an open standard for AI agents to interact with retailers for the purposes of shopping.
The above vision is bottlenecked by the fact that many websites will not cooperate to make the parallel internet a reality, for both legitimate and illegitimate reasons. Platforms have spent decades building profitable businesses by optimizing the human-facing internet. A machine-readable layer threatens to bypass all of it.
Consider a platform that makes substantial revenue from its advertising business. That revenue depends on humans looking at screens. All of the sponsored product placements, the “featured” results, the whole ranking algorithm: all of this has been optimized based on human clickthrough data. An AI agent doesn’t care about position bias;2 it can theoretically evaluate ten thousand news feed items or products across multiple platforms in the time it takes you to scroll through the first page of search results.
If that agent is acting in your interest rather than the platforms, then this threatens its ability to optimize its advertising. Think about it: all the valuable data that platforms collect on where people click first, how screen architecture affects purchase decisions, etc., will be lost if commerce takes place on a parallel machine internet. Firms are indeed actively blocking attempts by people to deploy their AI agents on their behalf–the so-called Bring-Your-Own (BYO) agent.
Eric Seufert, an analyst who writes extensively about this dynamic, puts it bluntly: the fundamental flaw with agentic commerce is that it violates the motivations of retail platforms to control the customer relationship and monetize their first-party data with advertising. Or as Andrew Lipsman recently put it: Retailers don’t want agentic commerce. We don’t think that things are this binary, there are reasons for why retailers benefit from agentic commerce, such as to expand their selection or to attract new customers. Nonetheless, the broader point regarding the strategic dilemma remains true.
They have a simple argument for why agentic commerce is further than it seems: the platforms that need to enable the parallel internet are precisely the ones with the strongest incentive to delay. The user-level behavioral data generated by browsing and purchasing is valuable, and because that data feeds advertising, recommendations, and pricing, platforms will drag their feet on any infrastructure that lets independent agents bypass it—even if they eventually have no choice.
Imagine you deploy an AI agent to shop for you. The agent logs into your Booking.com account using your credentials, stored locally on your device. It browses hotels, compares prices, and completes a purchase—all at your explicit direction, acting solely on your behalf.
Have you done anything wrong? Has your agent?
The answer is surprisingly unclear, and the current legal framework is not favorable to agents. The core question is whether a BYO agent inherits your rights to access a website. You, as a human, can browse Booking. You agreed to their Terms of Service. Does your agent automatically have the same permission?
Given the arguments above, perhaps it’s not surprising that platforms say no. Their argument has three parts:
First, Terms of Service typically prohibit “any use of data mining, robots, or similar data gathering and extraction tools.” An AI agent navigating a website arguably falls under this prohibition, even if it’s acting on a human’s instructions. Less scrupulous agent providers may indeed be using agents to scrape data for training purposes, so this is a legitimate concern.
Second, platforms argue that agents must identify themselves. When an AI agent disguises itself as a regular Chrome browser rather than announcing that it’s an automated tool, platforms claim this constitutes deception—and potentially fraud. For example, Cloudflare has accused Perplexity of using deception to evade no-crawling directives. Just as websites can require humans to identify themselves, it seems evident that websites should be able to require agents to identify themselves as acting on behalf of a particular human.Third, and most importantly, platforms can revoke permission. A key precedent here is Facebook v. Power Ventures (2016), where the Ninth Circuit held that a third-party company that continued accessing Facebook after being told to stop was liable under the Computer Fraud and Abuse Act. The court’s language was stark: “Once permission has been revoked, technological gamesmanship will not excuse liability.”This means a platform may not need to win the argument about whether your agent was initially authorized. It simply needs to tell the agent to leave. After that, continued access becomes “unauthorized” under federal computer fraud law—a statute that carries both civil and criminal penalties.The counterargument to these three points is pretty intuitive: if you can hire a human personal shopper to buy things on your behalf, why can’t you hire an AI one? But the law, as currently interpreted, doesn’t recognize this equivalence. A human personal shopper is still a human using the website in the normal way. An AI agent is software—and software can be prohibited by Terms of Service in ways that human access cannot.
This creates an asymmetry with real consequences. Platforms can develop bowling-shoe agents while blocking BYO agents. The agents you’re allowed to use are the ones controlled by the platform—which may not be aligned with you.
Now let’s outline the case for protecting BYO agents’ ability to act on their owner’s behalf. The arguments for allowing users to bring their own AI agents are straightforward extensions of existing consumer protection logic.The competition argument:
Start with bounded rationality. Humans can only visit so many websites, compare so many options, and process so much information before making a purchase. The entire architecture of modern e-commerce is optimized around these limitations. The reason that ranking algorithms matter and that companies try hard to learn user preferences is that users will leave if they don’t see relevant results right away. At the same time, because of limited attention, users may not find the best option for them.
An independent agent changes this calculation. A machine can evaluate thousands of options across many platforms. It doesn’t get tired. It doesn’t succumb to urgency cues or limited-time offers. It doesn’t mistake “featured” for “best.” If agents become widespread, retailers offering genuinely better deals become discoverable in ways they currently are not. Competition increases.The precedent argument
There’s also a simple precedent argument. We already permit humans to hire personal shoppers. We allow browser extensions that apply coupons or track prices. We don’t prohibit consumers from visiting multiple websites before making a purchase. The principle that consumers can seek assistance in navigating markets is well established. The question is why AI assistance should be treated differently than human assistance—particularly when the AI is acting on explicit user instructions, using the user’s own credentials, for the user’s sole benefit.Platforms offer several counterarguments, some more legitimate than others.
The first is safety. AI agents can be tricked. They’re vulnerable to prompt injection attacks, phishing schemes, and adversarial manipulation. An agent that autonomously enters payment information could be exploited in ways a human would catch. This is a real concern—though it’s worth noting that platforms have strong incentives to exaggerate it, and that the appropriate response is security standards for agents rather than outright prohibition. In fact, we can imagine platforms or third-parties certifying specific agents as being ‘safe’ for various use-cases.The second is enforcement. How do you distinguish a legitimate user agent from a scraper harvesting data for resale? From a bot placing fake orders? From a competitor conducting automated price surveillance? Platforms have legitimate interests in preventing abuse, and agent identification is one mechanism for doing so. A platform or website should be able to require an agent acting on behalf of a user to identify itself as an AI agent for a given user.
The third is user experience. Platforms may claim that agents degrade the shopping experience—they might not select the best delivery option, might miss relevant product information, might create problems with returns. This concern is harder to take at face value. Customers willingly using an AI agent are presumably accounting for a given agent’s capabilities and flaws. We expect that competition among AI agent providers will result in high-quality agents that improve shopping experiences.
Any workable framework will have to look roughly like this. Users have the right to deploy AI agents on any platform they can access as a human, provided:
The agent operates through the user’s own browser and credentials.
Acts only at the user’s direction.
Identifies itself as an AI agent operating on behalf of a specific user.
Does not engage in data harvesting beyond what’s necessary for the user’s transaction.
The technology to implement this already exists; see, for example, the protocol for personhood credentials that can be used to identify agents as belonging to a specific user. Platforms can set reasonable security requirements for agent identification, but cannot categorically ban agents or reserve agentic capabilities for their own tools.
Our proposal preserves platform interests in security and abuse prevention while establishing that consumers have a right to technological assistance in navigating markets—the same right they’ve always had to hire an agent, use a price comparison site, or simply shop around. Importantly, if the regulatory framework for agentic commerce is in place, then this would also incentivize third parties to create the parallel machine-readable internet that represents the first obstacle.
Note, one of us, Andrey, is currently employed by Amazon, Inc. This essay represents his personal views and not those of the company.
As measured by benchmarks such as ScreenSpot Pro, BrowseComp, and Tau-retail bench.
Although see this paper for some evidence that AIs may still have position bias.

![]()
![]()
The potentially emerging contrary example is UK rail ticketing.
UK railways has a complex and evolving fare structure, to the extent that it is claimed that UK offers both the lowest and highest cost per mile in Europe, depending on routes, travel times/restrictions, and when you book.
Several independent commercial websites in the UK have the ability to optimise the rail fare and issue the ticket, across multiple rail franchise operators and hence websites.
Why is this possible?: good regulation and governance. Open data feeds, and a common rail ticketing back end that is available to all, by design and regulation, and a sales commission fee structure to cover costs (yes some sales website also levy a user fee, offset by a better experience and likelihood of lower fares some of the time).
Is there agentic commerce for this yet? No.
But I think the conditions are right, just needs model development to ingest the complex fares rulebook and specific experience in the accepted gaps in the rules combined with historical fare setting policy (ie split tickets and break in journey are both permitted within a framework, and often advantageous, in a way that airlines explicitly don't allow.)

This is fascinating and a great start on what I think is going to be a huge question in the future. One thing I’d love to hear you guys tackle next:
To what extent is this challenge multi sided? In this piece you focus primarily on the challenges posed by e commerce platforms not wanting to welcome agents. And you talk about the value of independent agents.
But does it also matter whether your agent comes from a large platform like OpenAI vs an open weights model or a third part agent provider company?
One fear, possibly accelerated by OpenAI announcing ads today, is that our agents won’t really be ours. And so the question will become not only can the agents be allowed to execute on our behalf but will the agents incentives be aligned with our own.
No posts
Ready for more?
相關文章