從零開始理解並編寫大語言模型中的 KV 快取
這篇技術教學解釋了 KV 快取的概念框架與實作方式,這是一項透過儲存並重用中間鍵值向量來加速大語言模型推論的關鍵技術。
從零開始理解並編寫 LLM 中的 KV Cache
KV Cache(鍵值快取)是生產環境中實現高效 LLM 推論最關鍵的技術之一。它是計算高效型 LLM 推論的重要組成部分。本文將從概念上解釋其工作原理,並透過一個從零開始、易於閱讀的程式碼實現來進行說明。
距離我上次分享解釋 LLM 基礎概念的技術教程已經有一段時間了。由於我目前正在從傷病中恢復,並致力於撰寫一篇更大型的 LLM 研究文章,因此我想先分享一篇關於幾位讀者詢問過的主題的教程文章(因為這部分未包含在我的《從零開始構建大型語言模型》一書中)。
閱讀愉快!
概述
簡而言之,KV Cache 儲存了中間的鍵(Key, K)和值(Value, V)計算結果,以便在推論期間(訓練後)重複使用,這能顯著加快文本生成的速度。KV Cache 的缺點是它增加了程式碼的複雜性,提高了記憶體需求(這也是我最初沒有將其納入書中的主要原因),且無法在訓練期間使用。然而,在生產環境中使用 LLM 時,推論速度的提升通常非常值得在程式碼複雜度和記憶體上做出權衡。
什麼是 KV Cache?
想像 LLM 正在生成一些文本。具體來說,假設給予 LLM 以下提示詞(Prompt):「Time」。正如你可能已經知道的,LLM 每次生成一個單詞(或標記/Token),接下來的兩個文本生成步驟可能如下圖所示:

請注意,生成的 LLM 文本輸出中存在一些冗餘,如下圖所示:

當我們實現 LLM 文本生成函數時,通常只使用每一步中最後生成的標記。然而,上面的視覺化圖表從概念層面突顯了主要的低效之處。如果我們深入觀察注意力機制(Attention Mechanism)本身,這種低效(或冗餘)會變得更加清晰。(如果你對注意力機制感興趣,可以閱讀我的《從零開始構建大型語言模型》第三章,或我的文章《理解並編寫 LLM 中的自注意力、多頭注意力、因果注意力和交叉注意力》)。
理解並編寫 LLM 中的自注意力、多頭注意力、因果注意力和交叉注意力
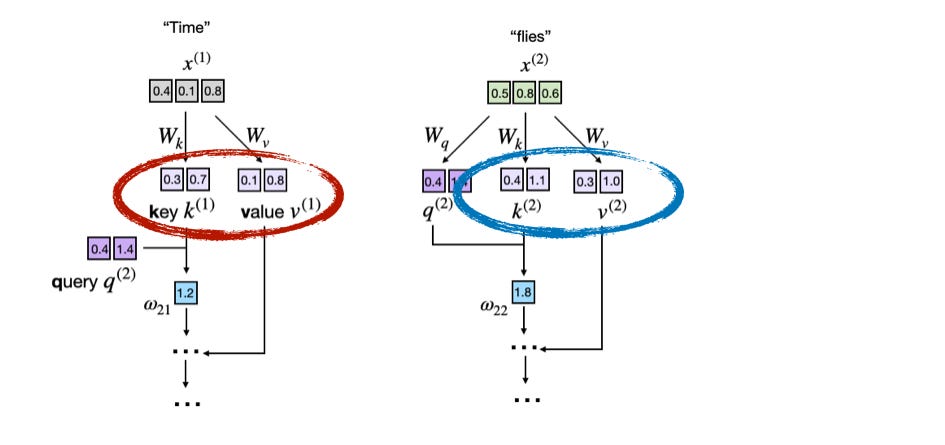
下圖顯示了作為 LLM 核心的注意力機制計算摘錄。在這裡,輸入標記(「Time」和「flies」)被編碼為 3 維向量(實際上這些向量要大得多,但為了方便放入小圖中作此簡化)。矩陣 W 是注意力機制的權重矩陣,將這些輸入轉換為鍵(Key)、值(Value)和查詢(Query)向量。
下圖顯示了底層注意力分數計算的摘錄,並突顯了鍵和值向量:
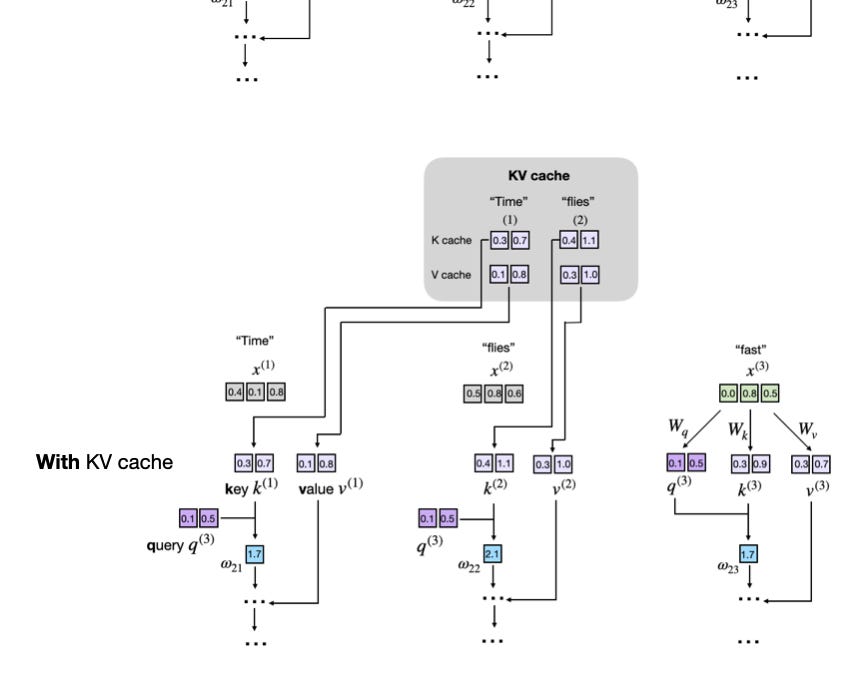
如前所述,LLM 每次生成一個單詞(或標記)。假設 LLM 生成了單詞「fast」,那麼下一輪的提示詞就變成了「Time flies fast」。如下圖所示:

正如我們所見,透過比較前兩張圖,前兩個標記的鍵和值向量是完全相同的,在每一輪下一個標記生成中重新計算它們是非常浪費的。
現在,KV Cache 的想法就是實現一種快取機制,儲存先前生成的鍵和值向量以供重複使用,這有助於我們避免這些不必要的重複計算。
LLM 如何生成文本(不使用與使用 KV Cache)
在上一節介紹了基本概念後,在查看具體的程式碼實現之前,讓我們再深入了解一些細節。如果我們在沒有 KV Cache 的情況下為「Time flies fast」進行文本生成過程,可以將其思考如下:
![]()
注意冗餘:標記「Time」和「flies」在每個新的生成步驟中都會被重新計算。KV Cache 透過儲存並重用先前計算的鍵和值向量來解決這種低效問題:
- 最初,模型計算並快取輸入標記的鍵和值向量。
- 對於生成的每個新標記,模型僅計算該特定標記的鍵和值向量。
- 從快取中檢索先前計算的向量,以避免冗餘計算。
下表總結了計算和快取的步驟與狀態:

這裡的好處是「Time」計算一次並重用兩次,「flies」計算一次並重用一次。(為了簡單起見,這是一個簡短的文本示例,但直觀上可以預見,文本越長,我們就能更多地重用已計算的鍵和值,從而提高生成速度。)
下圖並排展示了在有和沒有 KV Cache 的情況下的生成步驟 3。

因此,如果我們想在程式碼中實現 KV Cache,我們所要做的就是像往常一樣計算鍵和值,然後將其儲存起來,以便在下一輪中檢索。下一節將透過具體的程式碼示例進行說明。
從零開始實現 KV Cache
實現 KV Cache 有很多種方法,核心思想是我們在每個生成步驟中僅為新生成的標記計算鍵和值張量(Tensors)。
我選擇了一種強調程式碼可讀性的簡單方法。我認為直接瀏覽程式碼變更來查看它是如何實現的是最簡單的。
我在 GitHub 上分享了兩個文件,它們是獨立的 Python 腳本,分別實現了不含和包含 KV Cache 的從零開始的 LLM:
gpt_ch04.py:取自我的《從零開始構建大型語言模型》第 3 章和第 4 章的獨立程式碼,用於實現 LLM 並運行簡單的文本生成函數。gpt_with_kv_cache.py:與上述相同,但進行了實現 KV Cache 所需的更改。
要閱讀與 KV Cache 相關的程式碼修改,你可以:
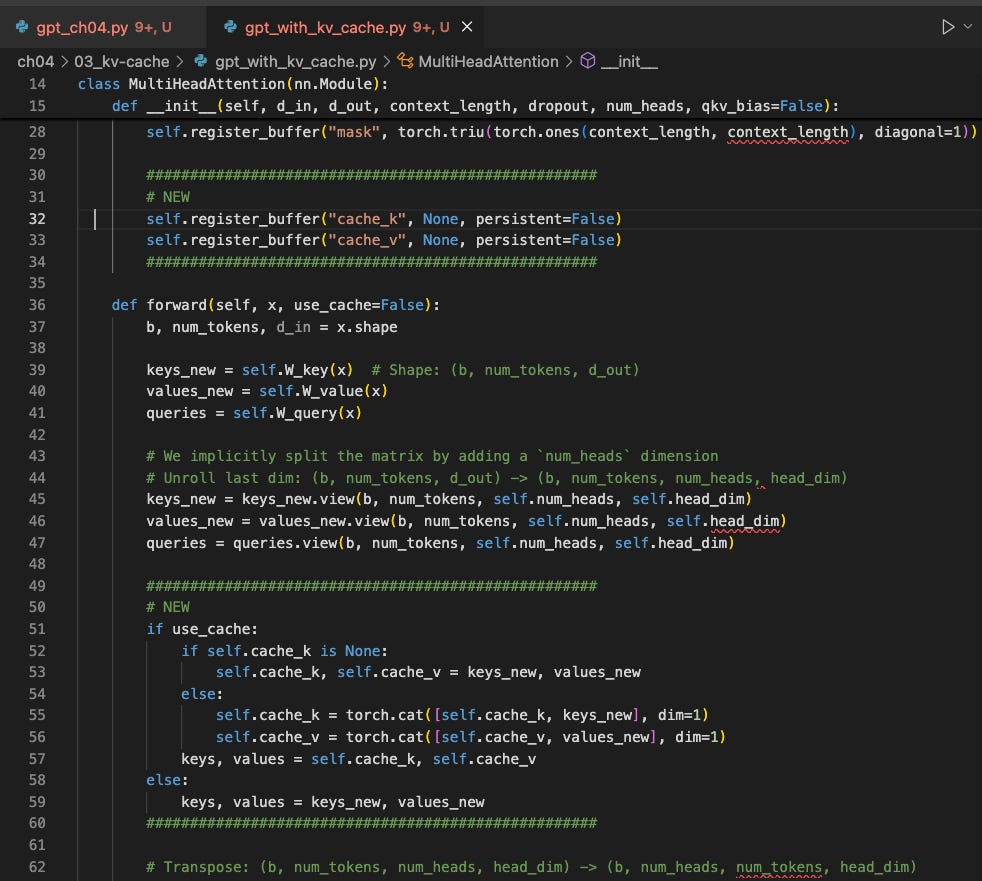
a. 打開 gpt_with_kv_cache.py 文件並尋找標記新更改的 # NEW 部分:
b. 透過你選擇的文件比較(diff)工具查看這兩個程式碼文件以比較更改:

此外,為了總結實現細節,以下子章節提供了簡短的導覽。
1. 註冊快取緩衝區(Cache Buffers)
在 MultiHeadAttention 建構子中,我們添加了兩個緩衝區 cache_k 和 cache_v,它們將保存跨步驟串接的鍵和值:
(如果你想了解更多關於緩衝區的資訊,我製作了一個 YouTube 影片:Understanding PyTorch Buffers。)
2. 帶有 use_cache 標誌的前向傳遞
接下來,我們擴展 MultiHeadAttention 類別的 forward 方法以接受 use_cache 參數:
這裡對鍵和值的儲存與檢索實現了 KV Cache 的核心思想。
儲存
具體來說,在透過 if self.cache_k is None: ... 初始化快取後,我們分別透過 self.cache_k = torch.cat(...) 和 self.cache_v = torch.cat(...) 將新生成的鍵和值添加到快取中。
檢索
然後,keys, values = self.cache_k, self.cache_v 從快取中檢索儲存的值和鍵。
這基本上就是 KV Cache 的核心儲存與檢索機制。接下來的第 3 和第 4 部分僅處理一些次要的實現細節。
3. 清除快取
在生成文本時,我們必須記住在兩次獨立的文本生成調用之間重置鍵和值緩衝區。否則,新提示詞的查詢將會關注到上一個序列留下的舊鍵,這會導致模型依賴無關的上下文並產生不連貫的輸出。為了防止這種情況,我們在 MultiHeadAttention 類別中添加了一個 reset_kv_cache 方法,供稍後在文本生成調用之間使用:
4. 在完整模型中傳遞 use_cache
隨著 MultiHeadAttention 類別的更改到位,我們現在修改 GPTModel 類別。首先,我們在建構子中為標記索引添加位置追蹤:
這是一個簡單的計數器,用於記錄模型在增量生成過程中已經快取了多少個標記。
然後,我們將單行的 block 調用替換為顯式循環,並將 use_cache 傳遞給每個 Transformer 區塊:
在上面,如果我們設置 use_cache=True,我們會從 self.current_pos 開始並計算 seq_len 步。然後,增加計數器,以便下一次解碼調用從我們停止的地方繼續。
追蹤 self.current_pos 的原因是新的查詢必須直接排在已經儲存的鍵和值之後。如果不使用計數器,每個新步驟都會再次從位置 0 開始,因此模型會將新標記視為與早期標記重疊。(或者,我們也可以透過 offset = block.att.cache_k.shape[1] 來進行追蹤。)
上述更改還需要對 TransformerBlock 類別進行細微修改,以接受 use_cache 參數:
最後,我們在 GPTModel 中添加一個模型級別的重置,以便一次性清除所有區塊快取:
5. 在生成中使用快取
隨著對 GPTModel、TransformerBlock 和 MultiHeadAttention 的更改,最後,以下是我們在簡單文本生成函數中使用 KV Cache 的方式:
請注意,我們在 c) 中僅透過 logits = model(next_idx, use_cache=True) 向模型提供新標記。在沒有快取的情況下,我們向模型提供整個輸入 logits = model(idx[:, -ctx_len:], use_cache=False),因為它沒有儲存的鍵和值可以重用。
簡單的性能比較
在從概念層面介紹了 KV Cache 之後,大問題是它在一個小例子中的實際表現如何。為了嘗試這個實現,我們可以將上述兩個程式碼文件作為 Python 腳本運行,這將運行一個小型 124M 參數的 LLM 來生成 200 個新標記(給定一個 4 標記的提示詞「Hello, I am」作為開始):
在配備 M4 晶片(CPU)的 Mac Mini 上,結果如下:

如我們所見,對於一個小型的 124M 參數模型和短短 200 個標記的序列長度,我們已經獲得了約 5 倍的加速。(請注意,此實現針對程式碼可讀性進行了優化,並未針對 CUDA 或 MPS 運行速度進行優化,後者需要預分配張量而不是重新實例化並串接它們。)
注意:模型在兩種情況下都會生成「亂碼」,即看起來像這樣的文本:
輸出文本:Hello, I am Featureiman Byeswickattribute argue logger Normandy Compton analogous bore ITVEGIN ministriesysics Kle functional recountrictionchangingVirgin embarrassedgl ...
這是因為我們還沒有訓練模型。下一章將訓練模型,你可以在訓練後的模型上使用 KV Cache(然而,KV Cache 僅用於推論期間)來生成連貫的文本。在這裡,我們使用未經訓練的模型是為了保持程式碼簡單。
更重要的是,gpt_ch04.py 和 gpt_with_kv_cache.py 的實現產生了完全相同的文本。這告訴我們 KV Cache 實現正確——索引錯誤很容易發生,並導致結果發散。
感謝閱讀 Ahead of AI!免費訂閱以接收新文章並支持我的工作。
KV Cache 的優缺點
隨著序列長度的增加,KV Cache 的優點和缺點會以以下方式變得更加明顯:
[優點] 計算效率提高:在沒有快取的情況下,第 t 步的注意力必須將新查詢與之前的 t 個鍵進行比較,因此累積工作量呈二次方增長,O(n²)。有了快取,每個鍵和值只計算一次然後重用,將每步的總複雜度降低到線性,O(n)。
[缺點] 記憶體使用量線性增加:每個新標記都會追加到 KV Cache 中。對於長序列和較大的 LLM,累積的 KV Cache 會變得非常大,這可能會消耗大量甚至令人望而卻步的(GPU)記憶體。作為解決方法,我們可以截斷 KV Cache,但這會增加更多複雜性(但同樣,在部署 LLM 時這可能是值得的)。
優化 KV Cache 實現
雖然我上面的 KV Cache 概念實現有助於清晰度,且主要面向程式碼可讀性和教學目的,但在現實場景中部署它(特別是對於較大的模型和較長的序列長度)需要更仔細的優化。
擴展快取時的常見陷阱
- 記憶體碎片和重複分配:如前所示,透過
torch.cat持續串接張量會因頻繁的記憶體分配和重新分配而導致性能瓶頸。 - 記憶體使用量的線性增長:如果處理不當,對於極長序列,KV Cache 的大小會變得不切實際。
技巧 1:預分配記憶體
與其重複串接張量,我們可以根據預期的最大序列長度預分配一個足夠大的張量。這確保了記憶體使用的連貫性並減少了開銷。在偽代碼中,這可能看起來如下:
在推論期間,我們可以簡單地寫入這些預分配張量的切片中。
技巧 2:透過滑動窗口(Sliding Window)截斷快取
為了避免撐爆我們的 GPU 記憶體,我們可以實現帶有動態截斷的滑動窗口方法。透過滑動窗口,我們在快取中僅保留最後 window_size 個標記:
實踐中的優化
你可以在 gpt_with_kv_cache_optimized.py 文件中找到這些優化。
在配備 M4 晶片(CPU)的 Mac Mini 上,進行 200 個標記生成,且窗口大小等於 LLM 的上下文長度(以保證相同的結果,從而進行公平比較),程式碼運行時間對比如下:

遺憾的是,在 CUDA 設備上速度優勢消失了,因為這是一個微型模型,設備傳輸和通信的開銷超過了 KV Cache 對這個小模型帶來的好處。
結論
儘管快取引入了額外的複雜性和記憶體考量,但效率上的顯著提升通常超過了這些權衡,特別是在生產環境中。
請記住,雖然我在這裡優先考慮程式碼的清晰度和可讀性而非效率,但重點在於實際實現通常需要深思熟慮的優化,例如預分配記憶體或應用滑動窗口快取來有效管理記憶體增長。從這個意義上說,我希望這篇文章對你有所啟發。
隨意嘗試這些技術,祝編碼愉快!
加碼內容:Qwen2.5 與 Llama 3 中的 KV Cache
在將 KV Cache 添加到我從零開始實現的 Qwen2.5 (0.5B) 和 Llama 3 (1B) 後,我運行了額外的實驗來比較模型在有和沒有 KV Cache 情況下的運行時間。請注意,我選擇了上面提到的 torch.cat 方法,而不是「優化 KV Cache 實現」部分中描述的預分配 KV Cache 張量。由於 Llama 3 和 Qwen2.5 支持非常大的上下文尺寸(分別為 131k 和 41k 標記),預分配的張量會消耗約 8 GB 的額外記憶體,這相當昂貴。
此外,因為我使用的是更節省記憶體的 torch.cat 方法來即時創建張量,所以我將 KV Cache 移到了模型之外,以便使用 torch.compile 編譯模型以提升計算效率。
程式碼可以在這裡找到:
性能表現如下所示。


正如我們所見,在 CPU 上,KV Cache 帶來了最顯著的加速。而編譯(Compilation)進一步提升了性能。然而,在 GPU 上,最佳性能是透過常規編譯模型實現的,這可能是因為我們沒有在 GPU 上預分配張量,且模型相對較小。
本雜誌是一個個人熱情項目。為了支持我作為一名獨立研究員,請考慮購買我的書《從零開始構建大型語言模型》(Build a Large Language Model (From Scratch)),或訂閱付費方案。

如果你讀過這本書並有幾分鐘空閒時間,我會非常感激你的簡短評論。這對我們作者很有幫助!
你的支持意義重大!謝謝!
相關文章