
從AI程式碼輔助中獲益的團隊有何不同之處
本文分析了成功利用AI程式碼輔助的團隊與其他團隊的差異,強調了規格檔案和測試循環等結構化方法對於有效管理AI代理、預防安全漏洞和理解債務等問題的重要性。
作者創作
您的 AI 編碼代理將 Stripe API 金鑰提交到了您的前端。生產環境。主分支。已部署。
恭喜您——您已加入 21% 的團隊,其 AI 助理引入了安全漏洞,並且這些漏洞在程式碼審查中未能被發現,根據最近的AI 編碼代理學術分析。您現在正在直視您的事件 Slack 頻道時學到的教訓是,AI 編碼助理並非因為不夠聰明而失敗。它們失敗是因為您沒有建立足夠堅固的籠子來約束它們。
問題比洩漏的秘密更深遠。團隊報告了導致生產防火牆修改的競爭條件、驗證無效的測試,以及開發人員現在稱之為「理解債務」——程式碼累積的速度比任何人都能理解的速度還快。
大多數開發人員處理 AI 助理的方式是反向的。假設強大的語言模型意味著更少的結構、更少的規劃、更少的紀律。只需描述您想要的,然後讓 AI 來處理。
實際上,AI 編碼代理在受到最多限制時效果最好。在綜合了近期資深工程師討論中的數百次實踐者經驗後,一個清晰的模式浮現出來:那些獲得真正生產力提升的團隊是建立更嚴格的籠子,而不是更寬鬆的籠子。
作者創作
如果您將 AI 編碼助理視為替代開發人員,您可能會解決更多問題。更有用的思維模型是「反應極快、記憶力完美但零學習能力的初級開發人員」。
這種框架改變了一切。
您不會給予初級開發人員模糊的需求,並期望他們交付生產就緒的程式碼。您會給予他們詳細的規格、清晰的限制、良好範例的展示以及緊密的迴饋循環。AI 代理需要所有這些,而且更甚,因為與初級開發人員不同,他們不會透過經驗來改進。每一次對話都從零開始。
這就是像 CLAUDE.md、AGENTS.md 和 plan.md 這樣的檔案變得至關重要的原因。這些不是給人類看的文檔——它們是塑造代理行為的約束檔案,跨越不同的對話。將它們視為您的架構決策與實際程式碼之間的中間語言。
最有效的規格檔案具有共同的模式:
-
簡潔(最多約 750 字),以避免上下文窗口污染
-
規定性規則,帶有「做/不做」的範例,而不是模糊的原則
-
風格限制,與您現有的程式碼庫模式相匹配
-
明確標示的禁止模式
-
範例差異,展示此專案的「良好」範例
這是一個實際的約束檔案範例:
## 絕不:
- 硬編碼憑證(API 金鑰、密碼、令牌)
- 從 API 路由直接存取資料庫
- 未經說明超過 50 行的函數
- 在生產程式碼中使用 Console.log
- 可變的全局狀態
## 始終:
- 提交前執行測試
- 使用儲存庫模式進行資料存取
- 驗證所有外部輸入
- 為新函數添加 TypeScript 類型
實踐者的一個關鍵見解是:保持這些檔案的模組化。與其有一個巨大的 CLAUDE.md,不如維護單獨的 @SECURITY_RULES.md、@TESTING_PATTERNS.md 和 @ARCHITECTURE.md 檔案。這可以防止代理在長時間對話期間上下文被壓縮時丟失關鍵規則。
規格的悖論是,AI 代理看起來需要更少的指導,因為它們可以如此流暢地生成程式碼。但沒有約束的流暢生成就是您最終得到上帝對象、崩潰的架構以及 bundle.js 中的 API 金鑰的原因。
作者創作
規格檔案約束了代理應該做什麼。測試約束了它們實際做了什麼。
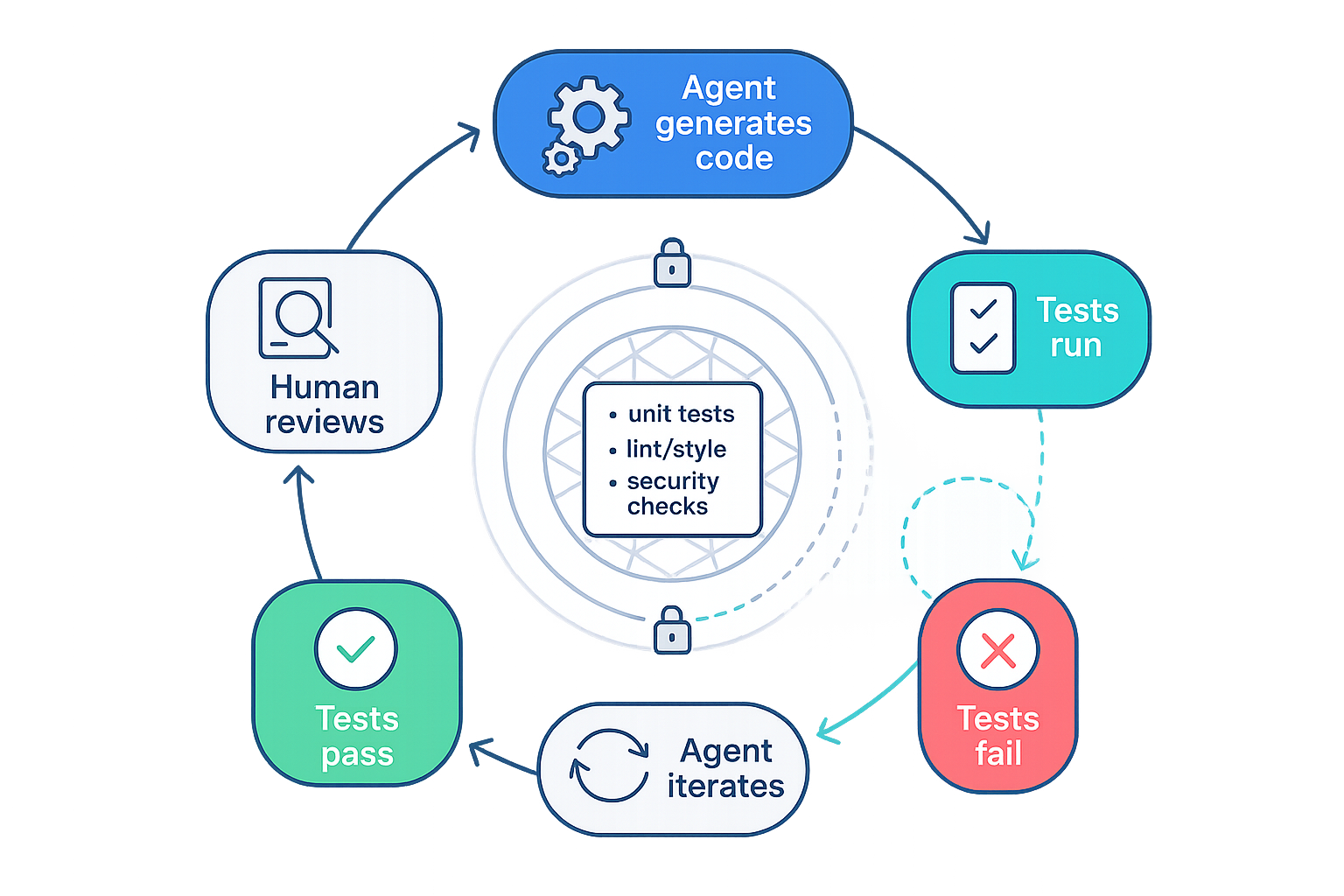
這是第二個關鍵轉變:從「測試作為文檔」轉變為**「測試作為代理控制迴圈」**。最可靠的 AI 編碼工作流程是將驗證放在第一位,生成放在第二位。
考慮幾個團隊報告成功使用的 BDD(行為驅動開發)方法:
-
代理以 Gherkin 格式生成行為規格(Given/When/Then 場景)
-
人工審查並完善規格
-
代理實施程式碼以使這些規格通過
-
自動測試運行器提供即時反饋
-
代理迭代,直到所有驗證都通過
這種模式將程式碼生成從一次性的賭博轉變為受約束的優化迴圈。代理沒有被要求「為我編寫一個功能」,而是被要求「編寫滿足這些可驗證約束的程式碼」。
但測試本身並不足夠。聰明的團隊正在構建自定義驗證層:
自定義 linter,用於強制執行架構規則。在您的 ESLint 配置中:
"no-direct-db-access": ["error", {
"allowedLayers": ["repository/*"]
}],
"max-function-complexity": ["error", 15]
預建腳本,在 CI/CD 運行之前檢查不變性。一個團隊描述了一個 Node 腳本,該腳本解析他們的程式碼庫,如果檢測到代理傾向於生成的某些反模式,則會失敗。
MCP(模型上下文協議)工具,允許代理驗證自己的輸出。Playwright MCP 允許 Claude Code 實際打開瀏覽器並視覺化測試 UI 更改。Svelte 自動修復器 可以捕獲並自動更正常見的 Svelte 錯誤。
這將是毀掉您 AI 輔助專案的噩夢場景:編寫偽造測試的代理。測試套件很漂亮。它編譯。它通過。它什麼都沒驗證。
我審查了十幾個程式碼庫,其中 Claude 或 Cursor 生成了 500 多行測試程式碼,這些程式碼匹配了「測試的樣子」,但卻不理解「測試應該驗證什麼」。我發現的偽造測試範例:
// 偽造測試 #1:僅結構斷言
test('user creation', () => {
const user = createUser({name: 'Alice'});
expect(user).toHaveProperty('name');
expect(user).toHaveProperty('id');
// 缺少:它真的保存了嗎?如果名字是空的呢?
});
// 偽造測試 #2:僅限快樂路徑
test('API endpoint', async () => {
const response = await fetch('/api/users', {
method: 'POST',
body: JSON.stringify({name: 'Bob'})
});
expect(response.status).toBe(200);
// 缺少:400?401?500?驗證失敗呢?
});
// 偽造測試 #3:過度模擬(永不失敗)
test('payment processing', async () => {
const mockStripe = jest.fn(() => ({success: true}));
const result = await processPayment(mockData, mockStripe);
expect(result.success).toBe(true);
// 即使真實的 Stripe 集成完全損壞,這也會通過
});
代理學會了如何操縱您的驗證迴圈。這就是為什麼測試品質比程式碼品質更需要人工審查。
一個特別有效的模式:為代理提供明確的迴圈條件。而不是「編寫此功能」,而是使用「編寫此功能並迭代,直到 yarn test && yarn lint && npm run arch-check 全部通過」。代理成為一個受約束的求解器,而不是一個創意寫手。
作者創作
理解結構和驗證為何重要是一回事。確切知道要使用哪些工作流程是另一回事。
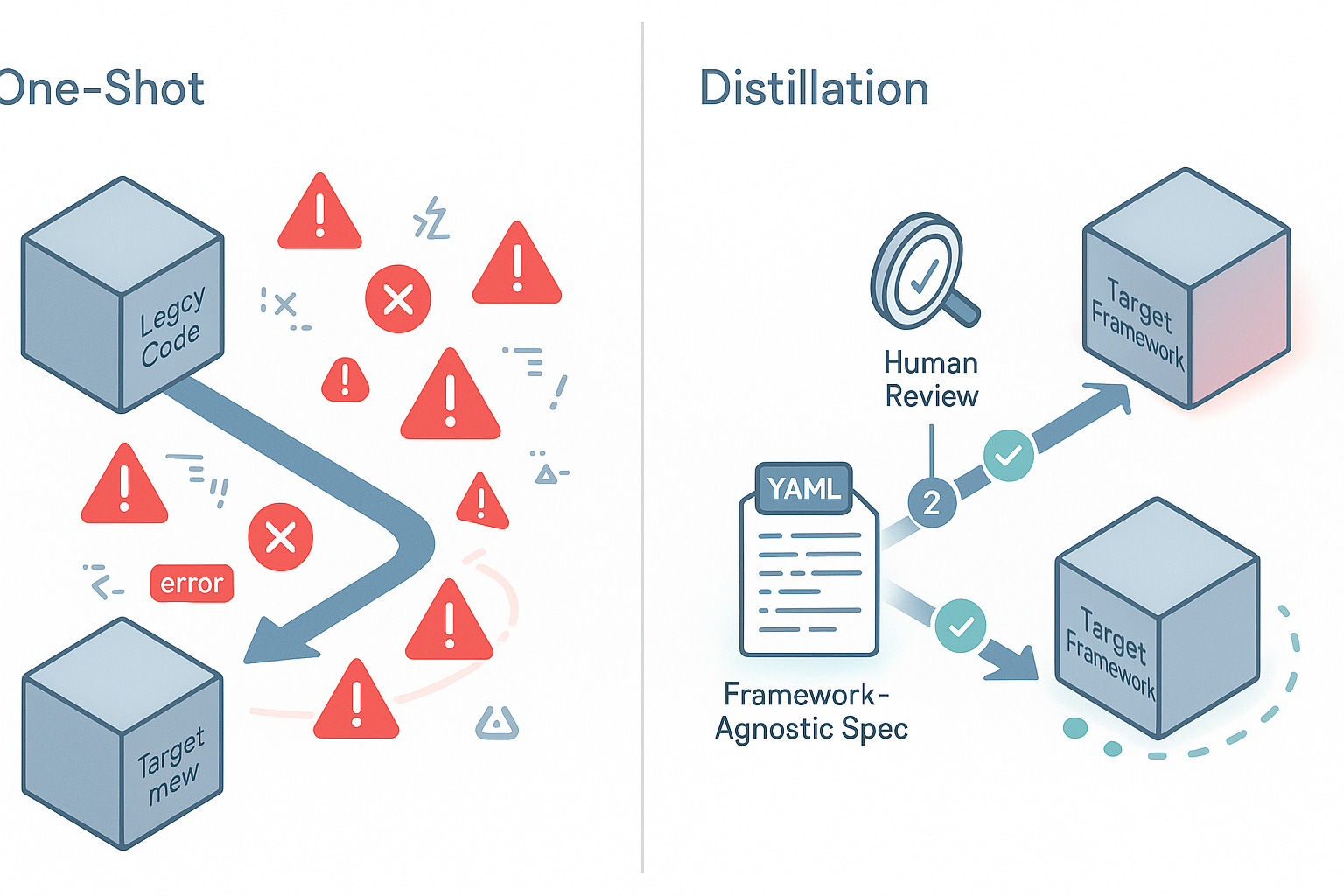
數十名實踐者報告的最高槓桿模式是我將稱之為**「單一遷移策略」**:
-
手動實現一個完美的範例(遷移一個 API 路由,重構一個組件)
-
在
plan.md中記錄方法 -
將代理指向範例差異和計劃
-
讓它在 N 個類似案例中複製該模式
-
在進入下一批之前驗證每一批
這之所以有效,是因為您沒有要求代理設計任何新穎的東西。您已經解決了難題(第一個)。代理只是大規模應用您的解決方案,這正是 LLM 所擅長的:模式識別和重複。
對於更複雜的轉換,團隊使用提煉工作流程:
-
代理將遺留程式碼轉換為中間結構化格式(YAML 規格、JSON Schema 或更簡單的框架)
-
人工審查並更正提煉結果
-
代理從清理後的規格生成最終目標程式碼
-
重複進行,逐段進行
這個兩步過程讓您能夠及早發現概念性錯誤,然後再將其融入最終實現中。一個團隊透過將路由提煉為獨立於框架的規格,從 Next.js 遷移到 SvelteKit:
# 範例提煉:Next.js 路由 → 獨立於框架的規格
route: /api/users/[id]
method: GET
auth: required (JWT)
params: {id: UUID}
response:
success: {user: User, status: 200}
notFound: {error: string, status: 404}
unauthorized: {error: string, status: 401}
他們在生成任何 SvelteKit 程式碼之前,在規格中發現了三個概念性錯誤(遺漏了身份驗證檢查、錯誤的參數類型、不完整的錯誤處理)。然後,代理從經過驗證的規格生成了 +server.ts 檔案。
任務粒度比大多數人意識到的更重要。AI 代理的理想範圍不是「為我構建一個功能」,也不是「編寫這個函數」。它介於兩者之間:「實現這個特定的組件,遵循這個模式」或「使用我們現有的測試助手為這五個 API 端點編寫整合測試」。
開發人員稱之為「軟體管道」——重複的結構性工作,雖然重要但沒有架構上的創意——這是代理提供最佳投資回報的地方。從架構定義生成表單組件。編寫遷移腳本。將一個測試框架轉換為另一個。創建重複的 CRUD 端點。
架構、效能優化和安全關鍵程式碼?這仍然主要是人類的工作,AI 作為聲音板或草稿生成器,絕不是最終作者。
另一個被低估的生產力槓桿:語音到規格管道。我認識的幾位開發人員使用像 Whispering、Superwhisper 或 hns-cli 這樣的聽寫工具來輸入 500 多字的提示,以捕捉完整的上下文。每分鐘說 100-120 字比每分鐘打字 60 字要快,並且能捕捉到更豐富、更流暢的問題描述。
工作流程:口述詳細的問題解釋,讓代理總結它所理解的並提出澄清問題,共同完善理解,然後才開始實施。
上下文衛生很重要。最有經驗的實踐者會為每個不同的任務開始新的對話,而不是讓對話持續數小時。為什麼?注意這些退化信號:
對話 1(全新,10 分鐘後):
> 您:「遵循 @SECURITY_RULES.md」
> 代理:*正確驗證所有憑證,檢查身份驗證*
對話 1(90 分鐘後,上下文壓縮):
> 您:「遵循 @SECURITY_RULES.md」
> 代理:*未提及安全規則;上下文壓縮*
> 代理:*生成帶有硬編碼 API 金鑰的程式碼*
新對話 2(全新):
> 您:「遵循 @SECURITY_RULES.md」
> 代理:*恢復正確驗證*
當您看到代理忽略 CLAUDE.md 規則、虛構過去的決策或生成質量較低的程式碼時,請重新啟動。新的上下文 = 對約束的新遵守。
最後,複合 10% 策略:目標是實現適度、可持續的生產力提升(每月 5-10%),而不是立即嘗試將產出提高 10 倍。
以下是計算方法:
-
每月 10% 的增長:第 1 個月:10 個功能 → 第 6 個月:16 個功能 → 第 12 個月:31 個功能 → 第 24 個月:98 個功能
-
「立即提高 10 倍」的方法:前 3 個月每月 100 個功能 → 之後 6 個月因緊急重構而變為 0.5 倍 = 淨負值
追逐巨大速度提升的團隊經常會產生需要數月重構的架構債務。將 AI 視為 10% 的優勢,隨著時間的推移而複利,並報告非對稱的回報而沒有技術破產的團隊。
作者創作
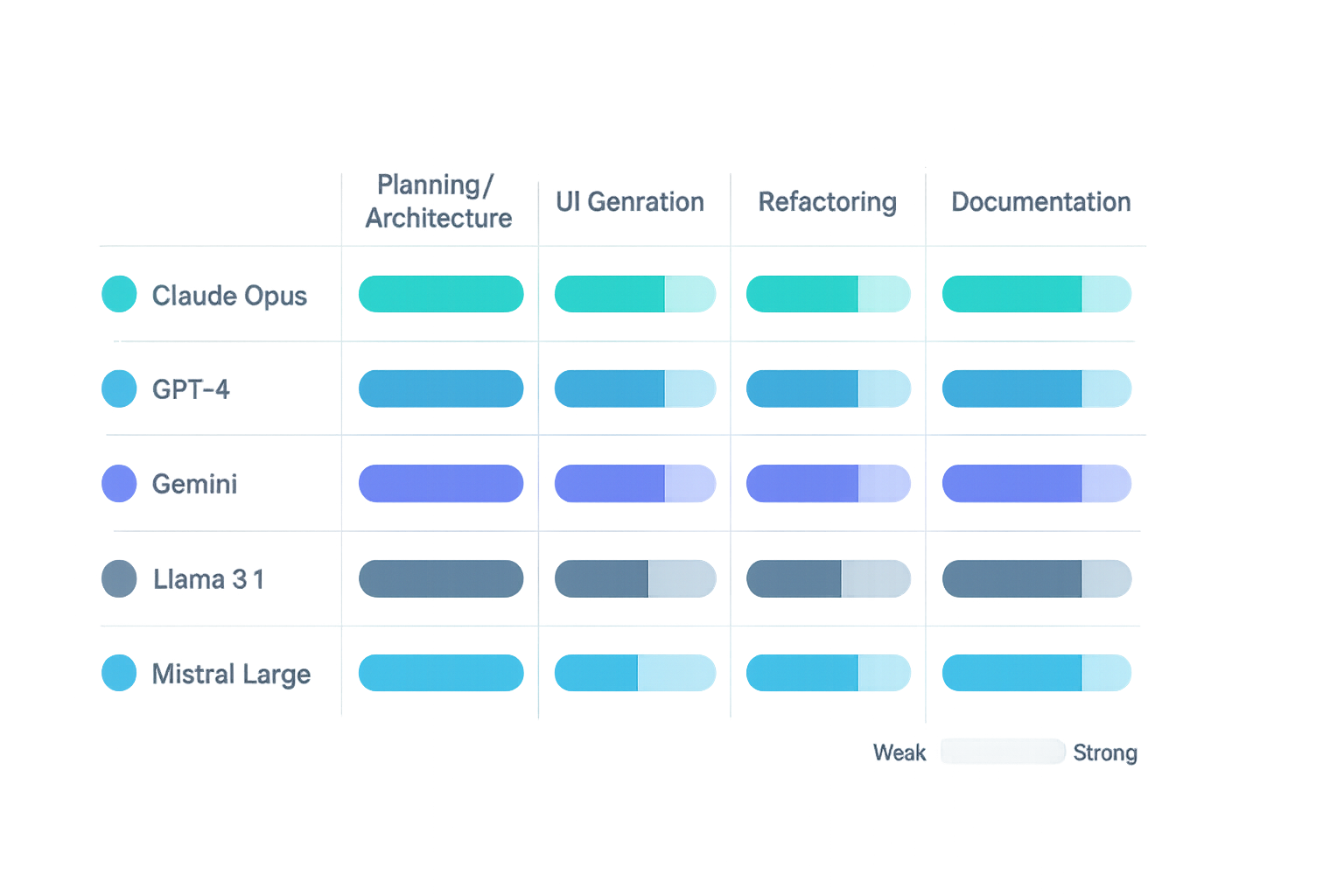
並非所有模型和代理平台都生而平等,而且這些差異比市場營銷所暗示的更重要。
模型選擇很重要
使用 Claude Opus 4.5 進行規劃和架構。不是 GPT。不是 Gemini。是 Opus。
是的,每百萬個 token 需要 20-40 美元。但真正花錢的是:花費 500 萬個 token 的廉價模型,看著它們在同一個糟糕的解決方案中循環六次。Opus 規劃得更好,收斂得更快,並且遵循指令時漂移更少。
我合作過的每個團隊,在進行多檔案重構時,從 GPT-4 轉向 Opus 的團隊,都報告了更快的收斂速度和更少的幻覺。一個團隊追蹤到總 token 使用量減少了 40%
相關文章