具備代理驗證器的多模態強化學習用於人工智慧代理
微軟研究院提出一種用於人工智慧代理的多模態強化學習新方法,透過「代理驗證器」來解決代理生成看似合理但事實錯誤的常見問題。此方法旨在將人工智慧的輸出與實際環境資訊連結,從而提高其可靠性。

Global
Microsoft Research Blog
Multimodal reinforcement learning with agentic verifier for AI agents
Published
January 20, 2026
By
Reuben Tan
,
Senior Researcher
Baolin Peng
,
Principal Research Manager
Zhengyuan Yang
,
Member of Technical Staff
Oier Mees
,
Lead Research Scientist | Robot Learning &
Foundation Models
Jianfeng Gao
,
Distinguished Scientist & Vice President
Share this page
At a glance
Over the past few years, AI systems have become much better at discerning images, generating language, and performing tasks within physical and virtual environments. Yet they still fail in ways that are hard to predict and even harder to fix. A robot might try to grasp a tool when the object is visibly blocked, or a visual assistant integrated into smart glasses might describe objects that aren’t actually present.
These errors often arise because today’s multimodal agents are trained to generate outputs that are plausible rather than grounded in the actual information they receive from their environment. As a result, a model’s output can seem correct while relying on incorrect information. As AI systems are increasingly used to navigate 3D spaces and make decisions in real-world settings, this gap can be a safety and reliability concern.
To tackle this challenge, we posed the question: How can we train AI agents to generate correct answers and take appropriate actions for the right reasons so that their behavior is reliable even as the environment or tasks change?
PODCAST SERIES

AI Testing and Evaluation: Learnings from Science and Industry
Discover how Microsoft is learning from other domains to advance evaluation and testing as a pillar of AI governance.
Argos represents a novel answer to this challenge. It’s an agentic verification framework designed to improve the reliability of reinforcement learning in multimodal models. Reinforcement learning is a training method where AI models learn by receiving rewards for desired behaviors and penalties for undesired ones, gradually improving their performance through trial and error.
Rather than rewarding only correct behaviors, Argos evaluates how those behaviors were produced. It draws on a pool of larger, more capable teacher models and rule-based checks to verify two things: first, that the objects and events a model references actually exist in its input, and second, that the model’s reasoning aligns with what it observes. Argos rewards the model when both conditions are met. In practice, these rewards help curate high-quality training data and guide the model’s further training.
How Argos works
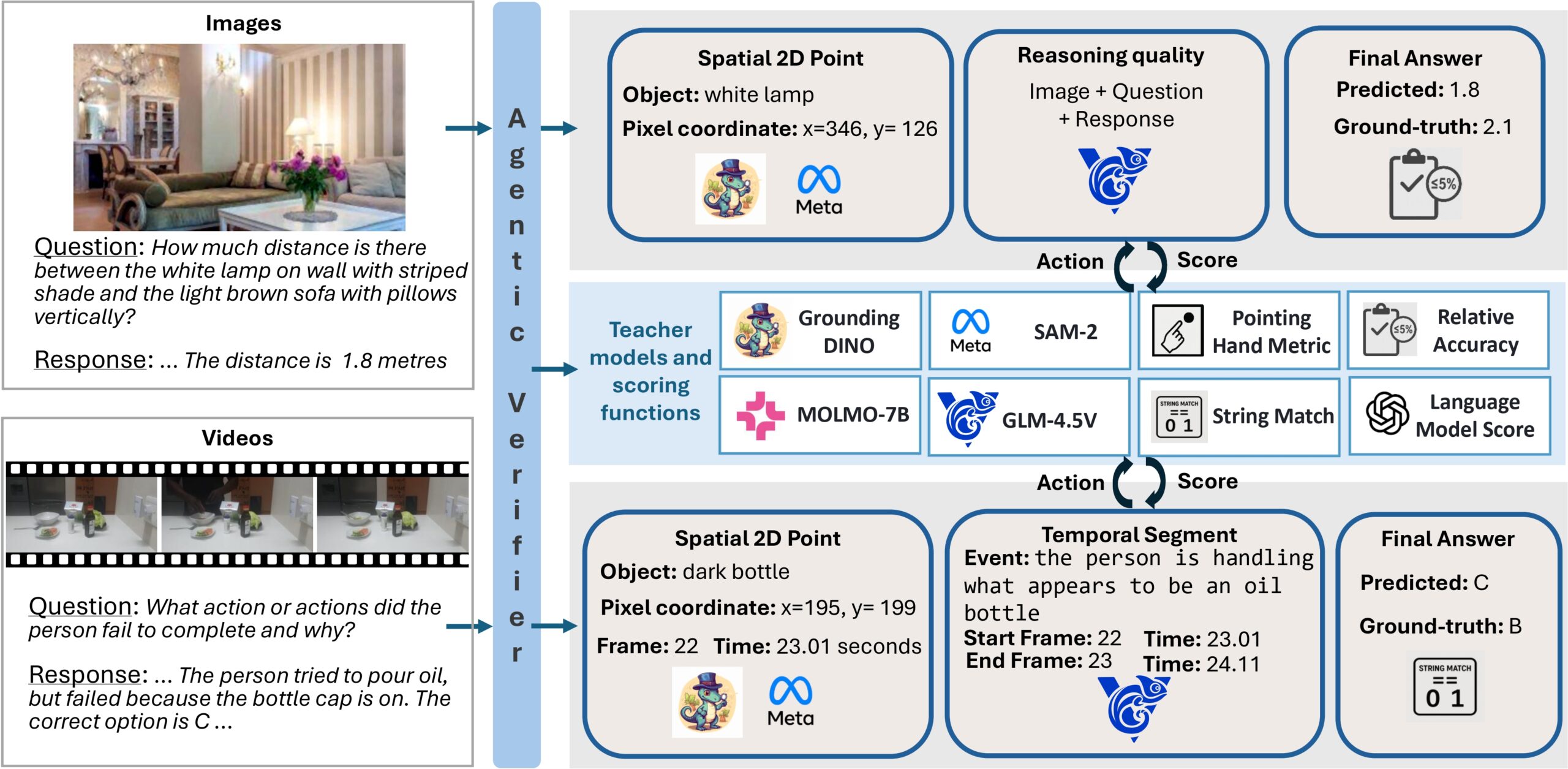
Argos functions as a verification layer on top of an existing multimodal model. Given an image or video, a task or query, and information about the model’s reasoning and output, Argos identifies where the model indicates objects are located in the image, when it indicates events occur in a video, and what action or answer it produces.
Argos then applies specialized tools tailored to the specific content to evaluate and score three aspects of the model’s output. It checks whether the answer is correct, whether referenced objects and events appear at the indicated locations and times, and whether the reasoning is consistent with the visual evidence and the answer (Figure 1).
These scores are combined using a gated aggregation function, a method that dynamically adjusts the importance of different scores. It emphasizes reasoning checks only when the final output is correct. This design prevents unreliable feedback from dominating training and produces a stable reward signal for reinforcement learning.
Using Argos to curate data for supervised fine-tuning
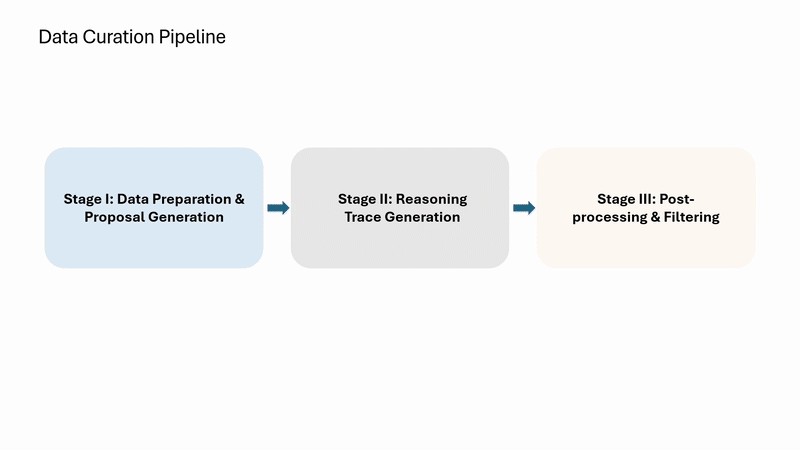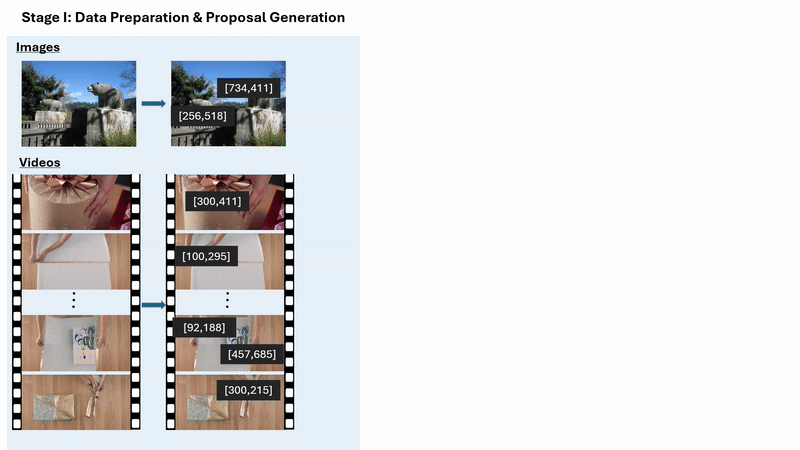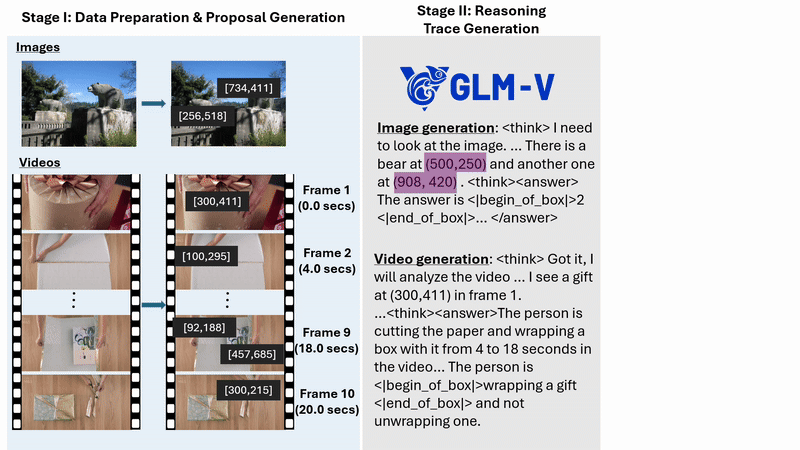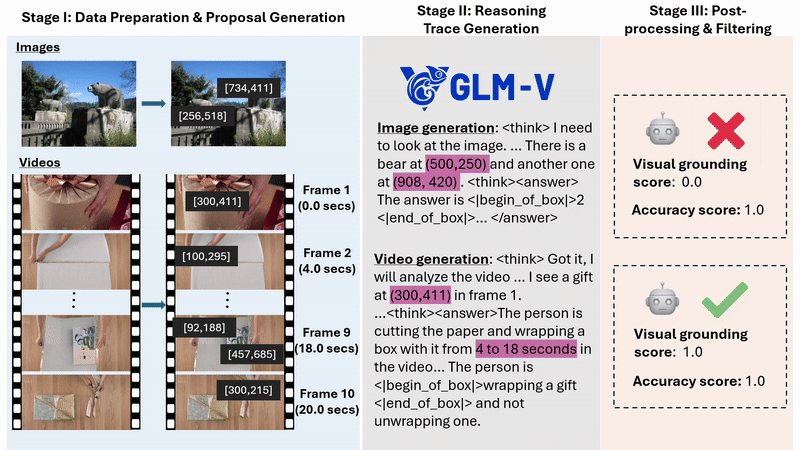
Argos also helps curate high-quality training data to provide the model with a strong foundation in grounded reasoning. Before the reinforcement learning stage begins, Argos uses a multi-stage process to generate data that is explicitly tied to visual locations and time intervals.
In the first stage, Argos identifies the objects, actions, and events that are relevant to a task and links them to specific locations in images or specific moments in videos. These references are overlaid on images and selected video frames. Next, a reasoning model generates step-by-step explanations that refer to these visual locations and time spans.
Finally, Argos evaluates each generated example for accuracy and visual grounding, filtering out low-quality training data and retaining only data that is both correct and well-grounded in visual input. The resulting dataset is then used in an initial training phase, where the model learns to generate reasoning steps before producing its final output. This process is illustrated in Figure 2.
Evaluation
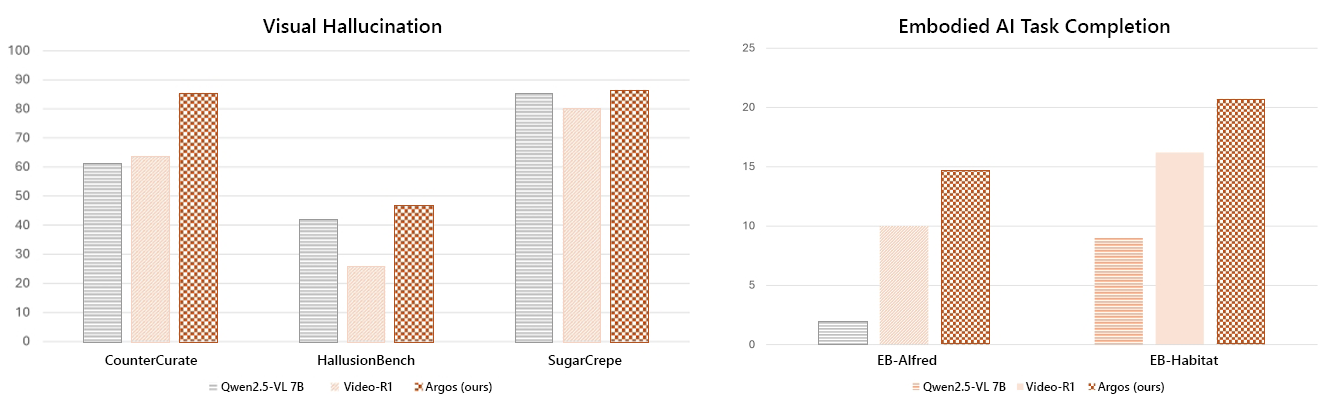
Building on this foundation in grounded reasoning, we further trained the model using reinforcement learning guided by Argos and evaluated its performance across a range of benchmarks. On spatial reasoning tasks, the Argos-trained model outperformed both the base model Qwen2.5-VL-7B and the stronger Video-R1 baseline across challenging 3D scenarios and multi-view tasks. Models trained with Argos also showed a substantial reduction of hallucinations compared with both standard chain-of-thought prompting and reinforcement learning baselines.
Finally, we evaluated the model in robotics and other real-world task settings, focusing on high-level planning and fine-grained control. Models trained with Argos performed better on complex, multi-step tasks. Notably, these improvements were achieved using fewer training samples than existing approaches, highlighting the importance of reward design in producing more capable and data-efficient agents. Figure 3 illustrates some of these findings.
How Argos shapes reinforcement learning
To understand how Argos affects learning, we took the same vision-language model that had been trained on our curated dataset and fine-tuned it using reinforcement learning in two different ways. In one approach, Argos was an agentic verifier, checking the correctness of outputs and the quality of reasoning. In the other, the model received feedback only on whether its answers were correct.
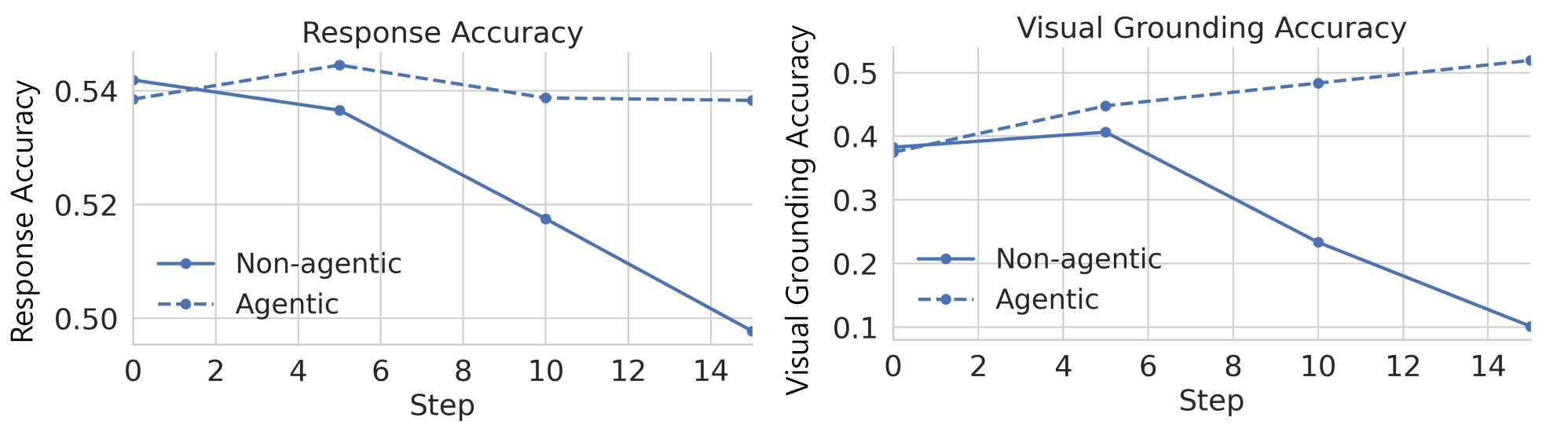
We evaluated both versions on 1,500 samples from a new dataset and tracked their performance throughout the learning process (Figure 4). Although they started at similar levels, the model without Argos quickly got worse. Its accuracy steadily declined, and it increasingly gave answers that ignored what was in the videos. It learned to game the system by producing answers that seemed correct without grounding them in visual evidence.
The model trained with Argos showed the opposite pattern. Accuracy improved steadily, and the model became better at linking its reasoning to what appeared in the videos. This difference highlights the value of verification: when training rewards both correct outputs and sound reasoning based on visual and temporal evidence, models learn to be more reliable rather than simply finding shortcuts to high scores.
Potential impact and looking forward
This research points toward a different way of building AI agents for real-world applications. Rather than fixing errors after they occur, it focuses on training agents to systematically anchor their reasoning in what they actually receive as input throughout the training process.
The potential applications span many domains. A visual assistant for a self-driving car that verifies what’s actually in an image is less likely to report phantom obstacles. A system that automates digital tasks and checks each action against what’s displayed on the screen is less likely to click the wrong button.
As AI systems move beyond research labs into homes, factories, and offices, reliable reasoning becomes essential for safety and trust. Argos represents an early example of verification systems that evolve alongside the AI models they supervise. Future verifiers could be tailored for specific fields like medical imaging, industrial simulations, and business analytics. As more advanced models and richer data sources become available, researchers can use them to improve these verification systems, providing even better guidance during training and further reducing hallucinations.
We hope that this research helps move the field toward AI systems that are both capable and interpretable: agents that can explain their decisions, point to the evidence behind them, and be trained to adhere to real-world requirements and values.
Related publications
Multimodal Reinforcement Learning with Agentic Verifier for AI Agents
Meet the authors
![]()
Reuben Tan
Senior Researcher
![]()
Baolin Peng
Principal Research Manager

Zhengyuan Yang
Member of Technical Staff
![]()
Oier Mees
Lead Research Scientist | Robot Learning &
Foundation Models

Jianfeng Gao
Distinguished Scientist & Vice President
Continue reading

Agent Lightning: Adding reinforcement learning to AI agents without code rewrites

CollabLLM: Teaching LLMs to collaborate with users

Magma: A foundation model for multimodal AI agents across digital and physical worlds

Tracing the path to self-adapting AI agents
Research Areas

Related labs
Follow us:
Share this page:
相關文章