
Vespa.ai 部落格:量化嵌入模型權衡
這篇 Vespa.ai 部落格文章量化了在混合搜尋中選擇嵌入模型時的權衡,重點關注模型量化和向量精度,以平衡成本、品質和延遲。
![]()
Vespa 部落格
讓 AI 為您工作
分享

2026 年 1 月 14 日
嵌入式模型的權衡,量化
由 NanoBanana 創建
大多數 Vespa 使用者運行混合搜尋 - 將 BM25(和/或其他詞彙特徵)與語義向量結合。但您應該使用哪個嵌入模型?以及在擴展時如何平衡成本、品質和延遲?
典型方法:打開 MTEB 排行榜,找到「檢索」欄,降序排序,選擇符合您規模預算的。搞定,對吧?
還沒完全。MTEB 並沒有告訴您:
所以我們自己進行了實驗。我們從 MTEB 檢索排行榜中挑選了符合以下標準的模型:
對於每個模型,我們在以下方面進行了基準測試:
劇透:我們發現了一些非常有吸引力的權衡 - 記憶體減少 32 倍,推理速度加快 4 倍,品質幾乎相同。
MTEB 沒有顯示的內容
模型量化
Vespa 使用 ONNX Runtime 進行嵌入推理。HuggingFace 上的大多數模型都提供多種 ONNX 變體 - 以 Alibaba-NLP/gte-modernbert-base 為例:
較低的精度權重 = 模型較小 = 推理速度較快。但速度快多少,品質損失多少?
30ms 和 100ms 的查詢延遲之間的差異巨大。如果您使用的是 CPU,INT8 通常是個不錯的選擇。
在 GPU 上,請使用 FP16 - 您可以獲得約 2 倍的速度提升,而品質損失可忽略不計。
GPU 與 CPU:T4 GPU 的嵌入推理速度比 Graviton3 快 4-7 倍。如果您處理高查詢量或進行批量索引,GPU 可能值得投資。
向量精度
模型量化影響推理速度。向量精度影響儲存和搜尋速度。這是兩個重要的不同參數。
以下是 1 億個 768 維嵌入的計算:
FP32 和二進位制之間的差異高達 32 倍。當記憶體迫使您增加節點時,這一點非常重要。
bfloat16 是免費的:在我們的基準測試中,bfloat16 向量與 FP32 相比,品質損失為零 - 儲存空間減少 2 倍,您可以無需任何權衡即可獲得。
Matryoshka 維度
有些模型支援 Matryoshka 表示學習 (MRL) - 您可以將嵌入截斷到較少的維度,仍然獲得不錯的結果。較少的維度 = 較少的儲存,較快的搜尋。
以下是不同維度大小的 EmbeddingGemma:
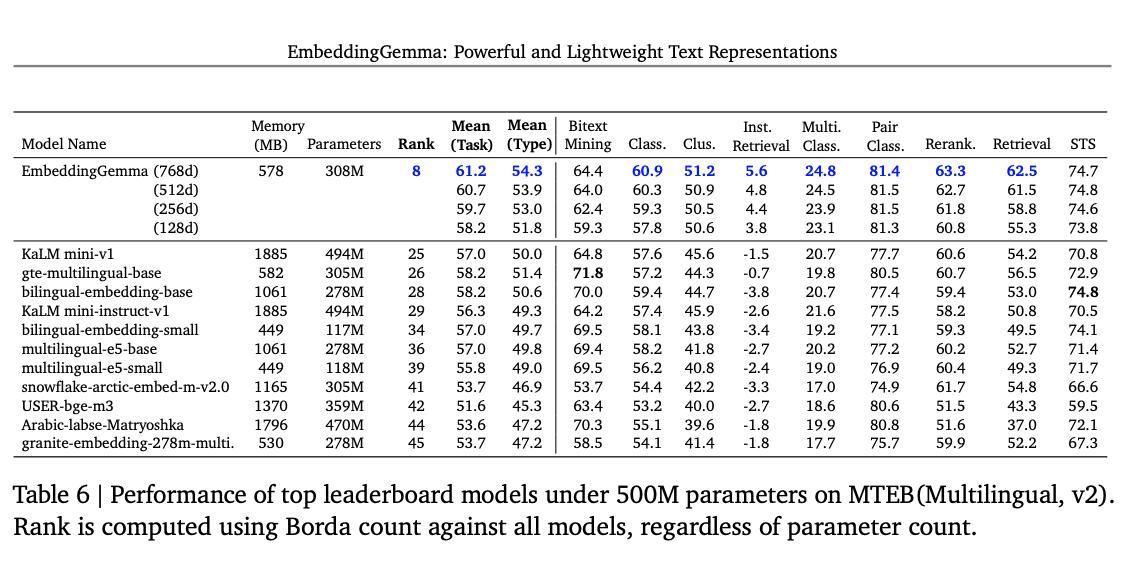
來源:EmbeddingGemma 紙
有趣的是,EmbeddingGemma 在 512 維度下的得分實際上高於 768 維度。我們沒有深入研究原因 - 這可能是由於較小的評估集造成的偽影 - 但這提醒我們,更多的維度並不總是更好。
並非所有模型都支援此功能 - 在截斷之前請檢查模型卡。如果它不是為 MRL 訓練的,截斷維度將嚴重損害您的品質。
推理速度
如果您有 200ms 的延遲預算,而您的嵌入模型需要 150ms,那麼您就麻煩了。我們對實際推理時間進行了基準測試,以便您可以相應地規劃。
我們測量了每個模型的兩項內容:
在三種 AWS 執行個體類型上進行測試:
這些數字是純 ONNX 推理時間。您的實際索引吞吐量還將取決於 HNSW 配置和現有索引大小,但嵌入推理通常是瓶頸。
品質
我們在 NanoBEIR 上評估了所有模型,NanoBEIR 是 BEIR 基準測試的一個較小但具有代表性的子集。這使我們能夠進行大量實驗,而無需長時間等待。
對於每個模型,我們在四種檢索策略中測量了 nDCG@10:
混合方法始終優於純語義搜尋。我們基準測試中的每一個模型在混合檢索下的得分都高於僅語義檢索。平均而言,最佳混合方法比僅語義方法高出 3-5 個百分點。僅僅通過使用 BM25 和向量,您就可以獲得有意義的提升。
我們還測試了每個模型使用二進位制向量(int8)。這就是事情變得有趣的地方:
結論:並非所有模型在二進位制量化方面都一樣。較新的基於 ModernBERT 的模型比 E5 系列處理得更好。在假設您可以直接二進位制化所有內容之前,請務必進行檢查。
互動式排行榜
我們構建了一個互動式排行榜,以便您可以自行探索完整的結果。按硬體篩選,按不同指標排序,並展開每個模型以查看跨維度和精度的完整細節。在全螢幕模式下開啟。
開始使用 Vespa
準備好將這些付諸實踐了嗎?以下是如何在 Vespa 中配置嵌入模型:
這是一個帶有二進位制嵌入欄位(96 維度 = 768 位元打包)的 schema:
以及一個使用線性正規化進行混合評分的 rank profile:
請參閱嵌入式文件以獲取有關配置的完整詳細資訊,包括如何設定二進位制量化和混合搜尋。
進一步發展
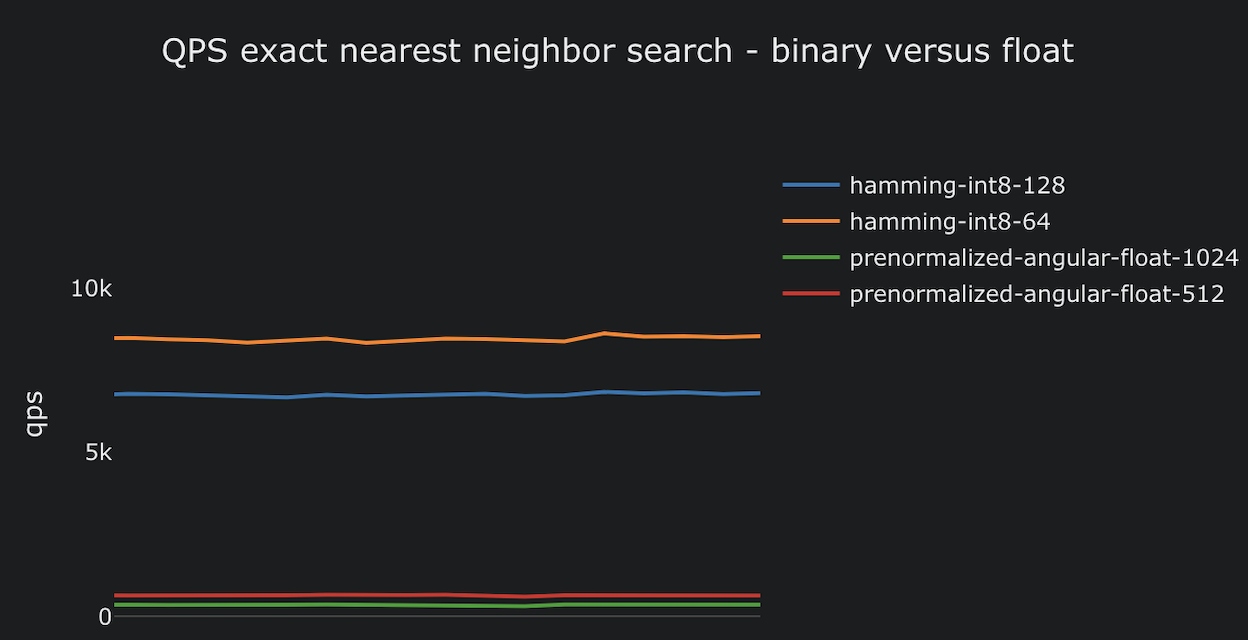
二進位制向量速度很快 - 非常快。Vespa 每秒可以進行約 10 億次漢明距離計算,比預正規化角度距離快約 7 倍。這種速度差異意味著您可以顯著提高 targetHits,同時仍保持在延遲預算內。評估的候選者越多 = 召回率越高。因此,二進位制向量不僅僅是節省 32 倍儲存空間 - 它們還為您提供了調整品質的空間。
幸運的是,Vespa 的分階段排名架構讓您能夠彌補任何剩餘的品質損失。您可以使用漢明距離檢索候選者,然後以以下任何一種方式重新評分:
有關這些技術的更多詳細資訊,請參閱這篇很棒的 HuggingFace 部落格文章。
為了獲得更好的結果,請在最後階段添加一個交叉編碼器重新排序器。或者(特別是如果您有幾個使用者信號或特徵),訓練一個 GBDT 模型來學習最佳組合。
Vespa 的排名表達式的優勢在於,您可以隨意組合所有這些 - BM25、許多其他內建特徵、向量、重新排序器、學習模型 - 隨心所欲。
一些注意事項
多語言支援
如果您需要支援多種語言,您的選擇將會減少。multilingual-e5-base 模型支援 100 多種語言,但與僅限英語的模型相比,品質有所下降。對於僅限英語的工作負載,請堅持使用專用模型。
上下文長度
文件長度也很重要。許多較新的模型支援 8192 個 token,EmbeddingGemma 可接受 2048 個,而 E5 系列的上限為 512 個。如果您的文件很長,請查看 LoCo(長文件檢索)等基準測試 - NanoBEIR 在這方面不會告訴您太多。
對於長文件,請查看 Vespa 的分層排名 - 它允許您對文件內的塊進行排名,這樣您就不必返回頂級文件中不相關的塊。
在您自己的資料上進行測試
NanoBEIR 是一個不錯的起點,但您的領域很重要。在科學論文上名列前茅的模型可能難以處理產品描述、法律文件或您的內部知識庫。
基準測試排名對於專業領域可能具有誤導性。我們測試的模型是在一般網路資料上訓練的 - 如果您的語料庫看起來非常不同(醫療記錄、原始碼、小眾行業術語),相對排名可能會顯著變動。
我們已在 pyvespa 中開源了基準測試程式碼,因此您可以使用與 MTEB 函式庫相容的任何模型和任何資料集運行相同的實驗。替換您自己的資料,看看不同模型在您的使用案例中的實際表現。
考慮微調
如果現成的模型在您的領域表現不佳,微調可以顯著改善。即使是一小部分來自您實際資料的查詢-文件對也可以提高相關性。
Sentence-transformers 等工具可以輕鬆完成此操作。對於生產系統而言,投資回報率通常是值得的,因為 nDCG 的幾個百分點的提升可以轉化為實際的使用者影響。
總結
「最佳」嵌入模型完全取決於您的限制。但現在您有了真實的數據來做出決定:
上面的互動式排行榜提供了所有詳細資訊。探索、篩選,並找到適合您使用案例的甜蜜點。
對於有興趣進一步了解 Vespa 的人,請加入 Slack 上的 Vespa 社群以交流想法、尋求社群協助,或隨時了解最新的 Vespa 開發動態。
閱讀更多

RAG 藍圖
Matryoshka 🤝 二進位制向量:使用 Vespa 大幅降低向量搜尋成本
![]()
二進位制化向量
![]()
相關文章