唯有在全球禁止人工超級智能的情況下,才可能打造出安全的人工超級智能
Lesswrong·
AI 生成摘要
我認為在研發可控人工超級智能的過程中,必然會先掌握如何構建不安全的人工超級智能,因此若沒有全球性的禁令與強力執法,任何安全研發計畫都將面臨技術外洩或意外失控的風險。
有時人們會提出各種建議,認為我們應該只開發「安全」的人工超級智能(ASI),而不是那種據推測「不安全」的類型。^([1])
人們建議的「安全」有多種形式:
- 有時他們建議建立「對齊」的 ASI:你有一個完全具備代理能力、自主且如神一般的 ASI 到處運行,但它真的非常非常愛你,而且絕對會做正確的事。
- 有時他們建議我們應該只開發「工具型 AI」或「非代理型」AI。
- 有時他們甚至有更奇特、或顯然更愚蠢的想法。
{kind=link}
現在,我可以長篇大論地爭辯為什麼這比人們想像的要難上千萬倍,為什麼他們的各種提議幾乎普遍行不通,為什麼甚至嘗試這樣做都是瘋狂且不道德的^([2]),但那並不是我想表達的主要觀點。
相反,我想提出一個更簡單的觀點:
假設你有一個研究議程,如果執行成功,將會產生一個你可以「控制」的 ASI 級別強大軟體系統。^([3])
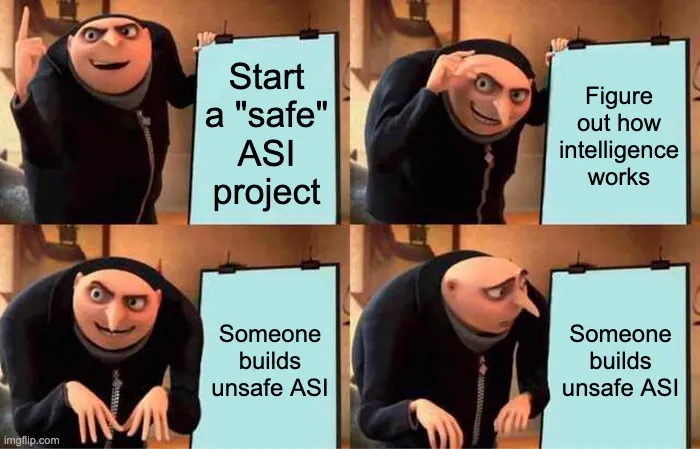
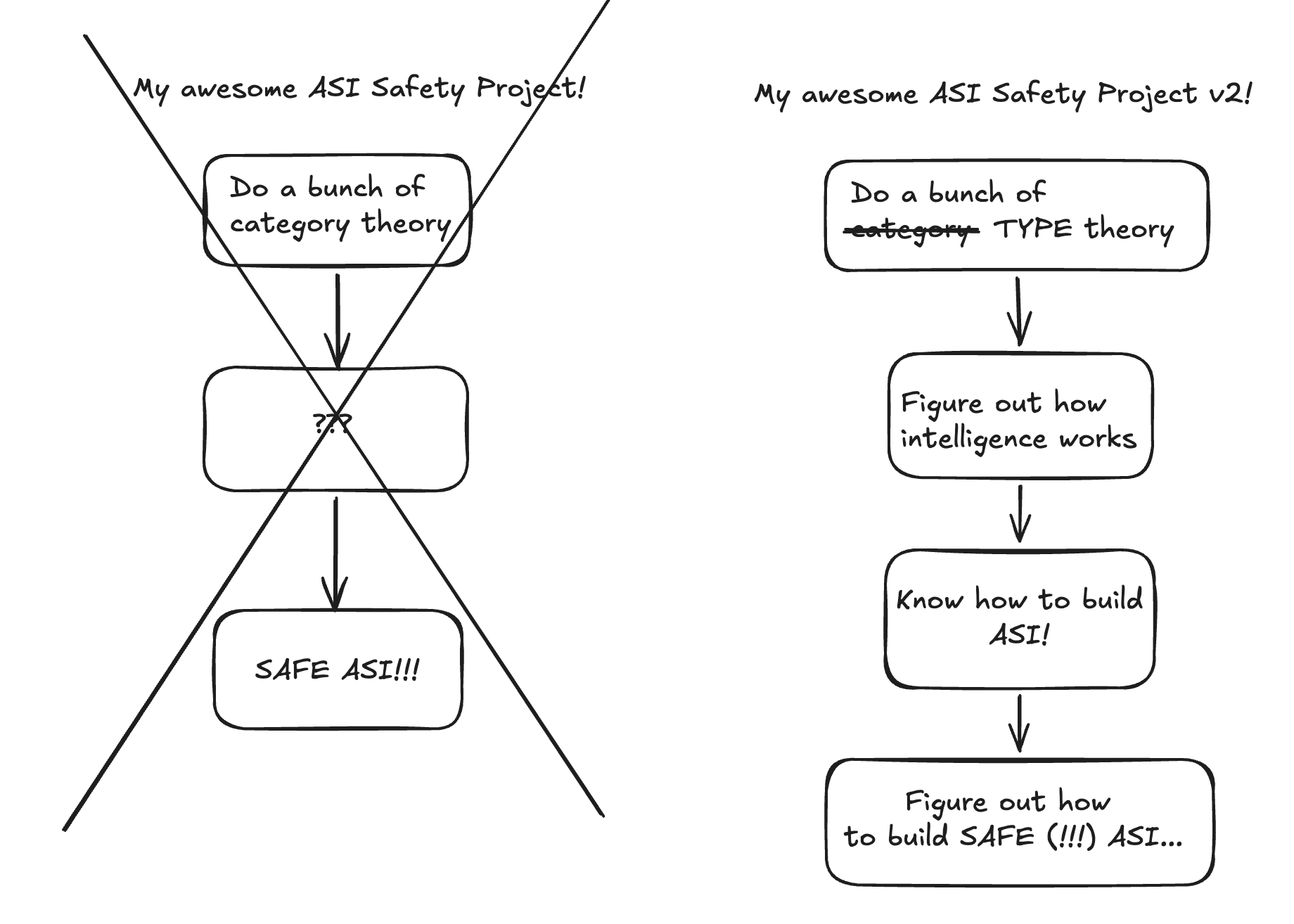
關鍵在於:在你弄清楚如何構建可控 ASI 的過程中,你將已經弄清楚如何構建不安全的 ASI,因為構建不安全的 ASI 比構建受控的 ASI 要容易得多,而且兩者處於相同的技術路徑上。
如果不了解許多、許多關於智能以及如何構建它的知識,你就無法構建受控的 ASI。
因此,這就讓「如何找到能產生可控 ASI 的議程」和「如何執行該議程」這兩個技術問題,卡在了一個瓶頸上:「即使你有這樣的議程,你如何執行它,而不會在過程中因為意外,或因為某個混蛋離開專案或閱讀了你的論文,而製造出不安全的 ASI?」
據我所知,目前追求這類議程的人中,沒有人能回答這些問題。讓我們說得非常清楚:這是任何理智的「安全 ASI」計畫在值得考慮之前,必須回答的根本問題。
你必須具備以下條件之一:
- 某種荒謬程度的機構保密與控制(例如:「這項研究將專門在 51 區進行,我們會暗殺所有離開專案的人,並對所有其他嘗試開發的人進行核打擊」)
- 完全的技術正交性(「這項研究與其他研究截然不同,以至於它在原則上甚至無法被用來構建不安全的 ASI,只能構建安全的 ASI」,而這是物理上不可能的)
- 全球範圍內的 ASI 開發禁令以及有效的執法
這意味著,甚至在考慮開始執行安全 ASI 計畫之前,首要前提是已經存在全球性的 ASI 禁令和強大的執法機制。^([4])
相關文章
其他收藏 · 0
收藏夾