尋找 AI 的應用場景
我們已經有了 ChatGPT 十八個月,但它到底是用來做什麼的?它的應用場景在哪裡?為什麼它現在還沒辦法對每個人都有用?大型語言模型會成為能處理任何任務的萬用工具,還是我們會將其封裝成單一用途的應用程式,並圍繞於此建立數千家新公司?
這張圖片出自馬丁·霍尼塞特(Martin Honeysett)於 1982 年出版的一本名為《微型恐懼症》(Microphobia)的書。書中充滿了精彩的笑話,我幾乎可以用其中任何一個,因為它們都在表達同一個觀點——你到底該拿這玩意兒怎麼辦?那一年,我在父親買的 ZX Spectrum 電腦上玩了《破壞者》(Saboteur),但除了玩遊戲還能幹嘛?
幾年前,丹·布里克林(Dan Bricklin)找到了一個答案:他看到一位教授在黑板上用粉筆製作電子表格,並意識到可以用「軟體」來實現。於是,他開發了 VisiCalc,這是第一款成功的電腦電子表格軟體。當他向會計師展示時,他們簡直驚呆了:他們可以在一個下午完成原本需要一週的工作量。當時一台運行 VisiCalc 的 Apple II 經通貨膨脹調整後至少要 12,000 美元*,但即便如此,人們一看到它就紛紛掏出支票簿:電腦電子表格為會計師改變了世界。
然而,如果你把 VisiCalc 展示給律師或平面設計師,他們的反應很可能是:「這很神奇,也許我的簿記員應該看看,但我不做那種工作。」律師需要的是文書處理器,而平面設計師需要的是(例如)Postscript、Pagemaker 和 Photoshop,而這些工具的出現花了更長的時間。
在過去的 18 個月裡,當我嘗試 ChatGPT、Gemini、Claude 以及所有如雨後春筍般湧現的聊天機器人時,我一直在思考這個問題:「這很神奇,但我沒有那種使用場景。」
2023 年真正爆發的一個重大使用場景是編寫程式碼,但我不寫程式。人們用它來腦力激盪、製作清單和整理想法,但同樣地,我不做這些事。我已經沒有作業要寫了。我看到人們用它來生成通用的初稿,設計師用 MidJourney 製作概念草圖,但同樣地,這些都不是我的使用場景。到目前為止,我還沒有找到任何一個能與我的使用場景相匹配的功能。我也認為我不是唯一的一個,正如一些調查數據所顯示的——很多人都嘗試過,特別是因為你不需要花 12,000 美元買一台新的 Apple II,而且它非常酷,但我們到底用了多少,又用來做什麼?
這本來沒什麼大不了的(「某男子說新科技不適合他!」),除非科技界的許多人看著 ChatGPT 和大型語言模型(LLM),看到的是邁向通用化、邁向萬能工具的階躍式變化。電子表格不能做文書處理或平面設計,而個人電腦雖然可以做所有這些事,但首先需要有人為你編寫這些應用程式,一次解決一個使用場景。但隨著這些模型變得更好並成為多模態,真正具有變革性的論點是:一個模型可以處理「任何」使用場景,而無需有人專門為該任務編寫軟體。
假設你想分析本月的客戶流失情況、申訴違規停車罰單,或是申報稅務——你可以詢問 LLM,它會計算出你需要什麼數據、找到正確的網站、問你正確的問題、解析你房貸帳單的照片、填寫表格並給你答案。我們可以將數量級更多的手動任務轉移到軟體中,因為你不需要為每個任務逐一編寫軟體。我想,這就是為什麼比爾·蓋茲說這是自圖形使用者介面(GUI)以來最重大的進步。這遠不止是一個寫作助手。
但在我看來,這個論點存在兩類問題。
狹義的問題,或許也是「較弱」的問題,是這些模型目前還不夠好。在我上面提到的場景中,它們會經常卡住。同時,這些是機率性而非確定性的系統,因此它們在某些類型的任務上表現得比其他任務好得多。它們現在非常擅長做出「看起來正確」的東西,對於某些使用場景,這正是你想要的,但對於其他場景,「看起來正確」與「正確」是兩回事。錯誤率和「幻覺」正在不斷改善並變得更可控,但我們不知道這會發展到什麼程度——這是圍繞生成式 AI(以及通用人工智慧 AGI)的主要科學爭論之一。同時,無論你認為這些模型在幾年後會變成什麼樣子,今天還有很多東西尚未實現。這些截圖是我確實擁有、理應可行但目前還行不通的使用場景的一個很好的例子。

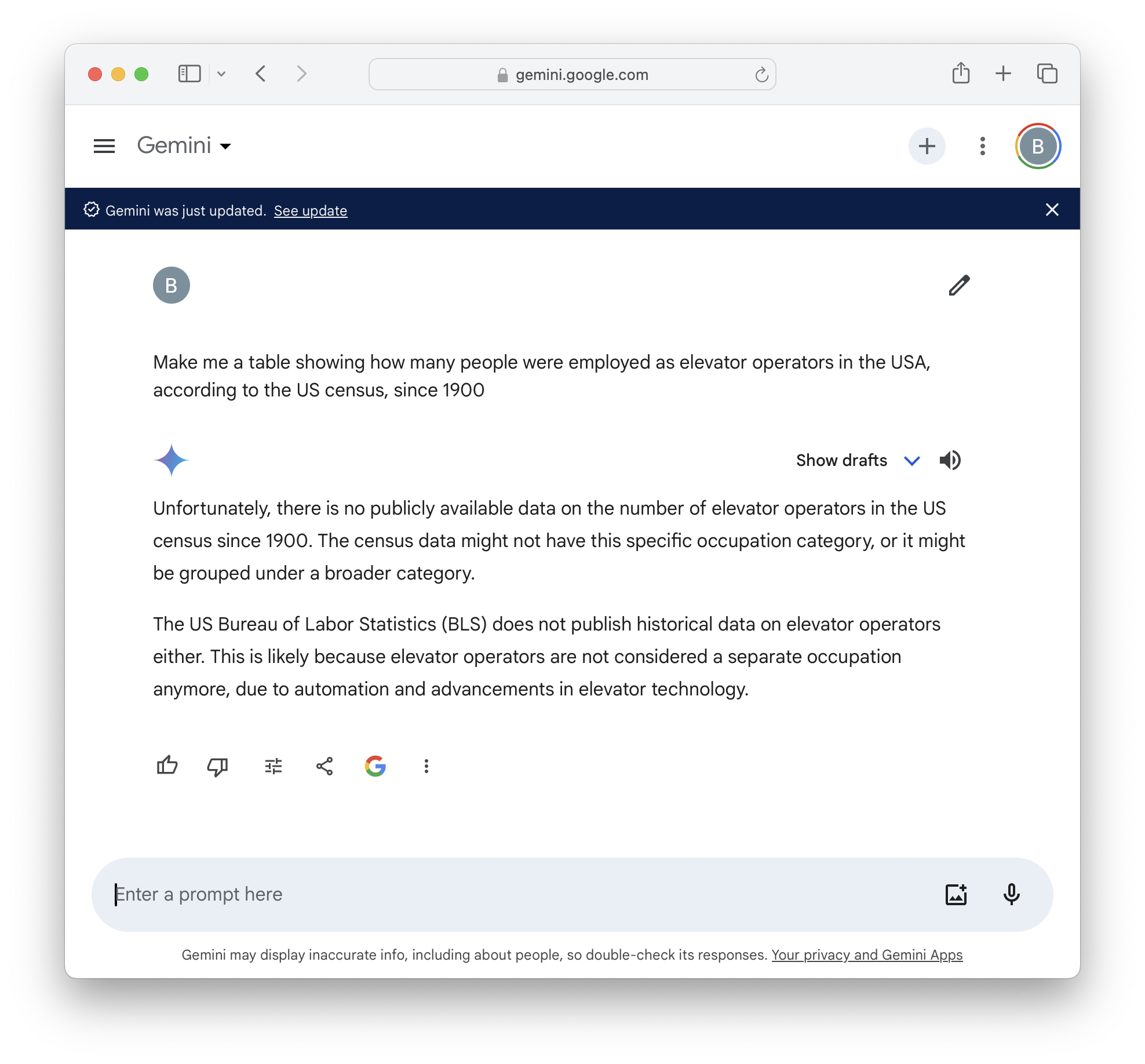

更深層的問題在於,無論技術多麼出色,你都必須想到使用場景。你必須看見它。你必須注意到某些你花費大量時間做的事情,並意識到它可以用這樣的工具來自動化。
這部分與想像力和熟悉度有關。這讓我想起 Google 的早期階段,當時我們太習慣於親手解決問題,以至於花了一些時間才意識到你可以「直接 Google 一下」。事實上,當時甚至有關於如何使用 Google 的書,就像今天有關於如何學習「提示工程」(prompt engineering)的長篇文章和影片一樣。我們花了一些時間才意識到,你可以將其轉化為一個通用的、開放式的搜索問題,只需輸入你大概想要的東西,而不是在垂直數據庫上構建複雜的邏輯布林查詢。這或許也符合新技術採用的經典模式:你首先讓它適應你已經在做的事情,在這些事情上,如果你有需求,很容易就能看出這是一個使用場景;然後隨著時間的推移,你改變工作方式以適應新工具。
然而,這種模式的另一部分是,找出新工具如何發揮作用並不是使用者的工作。丹·布里克林,以及原則上所有的軟體開發,都有三個步驟:他必須意識到可以把電子表格放入軟體中,然後他必須設計並編寫程式碼(並確保正確),最後他必須走出去告訴會計師為什麼這很棒。
在那個案例中,他幾乎立即實現了完美的產品市場契合(product-market fit),產品不推自銷,但這非常罕見。產品市場契合的概念是,通常你必須反覆調整你對產品的想法,以及你對使用場景和客戶的想法,使之相互靠攏——然後你需要銷售。生產力軟體新創公司中一個常見的謬論是,你可以不需要銷售團隊就進行由下而上的銷售,因為使用者會看到它並想要它。現實情況是,除了極少數例外,始終只有極小比例的目標用戶有興趣並準備好探索新工具,而對於其餘的人,你需要向他們推銷。
因此,今天的一個假設可能是,生成式 AI 可以消除或最小化丹·布里克林實際構建產品的工作,但你仍然需要意識到你可以這樣做,做出一個能表達這一點的具體東西,然後走出去告訴人們。人們知道自己在報稅,但我們自動化的大多數事情,都是我們在有人指出並試圖向我們推銷軟體之前,並未真正察覺或意識到那是可以被自動化的獨立、離散任務。
同時,電子表格既是個人電腦的一個使用場景,其本身也是一個通用底層,就像電子郵件或 SQL 一樣,然而所有這些都已被「拆解」(unbundled)。今天的典型大公司使用數百種不同的 SaaS 應用程式,可以說,所有這些程式都是從 Excel、Oracle 或 Outlook 中拆解出來的。它們的核心都是針對一個問題的想法和解決該問題的工作流想法,這比說「你可以在 Excel 中做到那點!」更容易理解和部署。相反,你在軟體中實例化問題和解決方案——確實是「封裝」它——並將其賣給資訊長(CIO)。你賣給他們一個問題。同時,你可能不想把 ChatGPT 交給《辦公室風雲》(The Office)裡的 Dwight 或 Big Keith 並叫他們用它來開發票,就像你不會叫他們用 Excel 代替 SAP 一樣。
因此,生成式 AI 的認知失調在於,OpenAI 或 Anthropic 表示我們非常接近能夠處理許多不同複雜多階段任務的通用自主代理,與此同時,出現了使用 OpenAI 或 Anthropic API 構建單一用途專用 App 的新創公司「寒武紀大爆發」,這些 App 瞄準一個問題,並將其封裝在手工構建的 UI、工具和企業銷售中,就像前一代人對 SQL 所做的那樣。回到 1982 年,我父親只有一把(1)電鑽,但從那以後,工具公司將其變成了一整套電池驅動的電動打孔機系列。曾幾何時,每家新創公司內部都有 SQL,但那不是產品,而現在每家新創公司內部都將擁有 LLM。
我經常將上一波機器學習比作自動化實習生。你想聽取進入呼叫中心的每一通電話,並識別哪些客戶聽起來憤怒或可疑:做這件事不需要專家,只需要一個人類(甚至可能是一隻狗),現在你可以自動化整類問題。發現這些問題並構建該軟體需要時間:機器學習的突破發生在十多年前,而我們現在仍在為其發明新的使用場景——人們仍在基於意識到 X 或 Y 是一個問題,意識到它可以轉化為模式識別,然後走出去推銷該問題來創建公司。
你可以認為當前的生成式 AI 浪潮給了我們另一組實習生,他們既能創造東西也能識別東西,同樣地,我們需要弄清楚能做什麼。同時,AGI 的爭論歸結為這是否可能遠遠超出實習生的範疇,如果我們擁有了那樣的東西,那麼它就不再僅僅是一個工具了。
但即使我有一個真人實習生,他們可能也很難解決我上面截圖中的「一次性」請求。你必須知道我要求的是一個時間序列數據集,可能每年一個數字,但也許每十年一個,關於按職業劃分的僱員人數(而不是,例如,被電梯操作員僱用的員工),且是以國家而非州為基準。然後你會去美國人口普查局網站,發現它確實收集這類信息,但在好幾個不同的細節層次上,間隔不同,定義不同,而且每隔幾十年就會更改定義,並在某個時間點停止收集「電梯操作員」的數據(所以它根本不在當前數據中,只在過去的數據中)。同時,該網站有數十種不同的數據工具和來源,光是知道如何找到任何東西就可能是一門專業。
在那種情況下,我會晃回到實習生的辦公桌前,告訴他們應該試試 FRED,如果那裡沒有,那麼從舊的《統計摘要》掃描件中逐年輸入數據會更快,而且使用 Google 圖書中從隨機大學圖書館掃描的副本其實更容易搜索。
這很好地說明了那個老笑話:程式設計師會花一週時間來自動化一項手動只需一天就能完成的任務。這也是一張很棒的自動化圖表,我花了很長時間手動輸入這一切,所以我一定要用它。
這包含了多少內隱知識(embodied knowledge)?你能通過更好的模型達到那種程度嗎?多模態代理?多代理協作?或者,最好是用 GUI 在某種專用 App 或服務中捕捉所有這些內隱知識,其中的選擇和選項由理解數據檢索、稅務或停車罰單申訴的人預先定義?GUI 告訴使用者他們可以做什麼,但也告訴電腦我們對該問題已知的一切;而在通用、開放式的提示詞下,使用者每次都必須自己想到所有這些,或者寄希望於它已經存在於訓練數據中。那麼,GUI 本身可以是生成式的嗎?還是我們需要另一整代丹·布里克林來發現問題,然後將其轉化為應用程式,成千上萬個,一次一個,每個都在底層某處運行著 LLM?
在此基礎上,我們在可自動化的程度以及能為 LLM 找到的使用場景數量上仍將有數量級的變化,但它們仍需要被一個一個地發現和構建。變化將在於,這些新的使用場景雖然仍是逐一自動化的,但它們是以前無法自動化的,或者需要多得多的軟體(和資本)才能自動化的。這將使 LLM 成為新的 SQL,而不是新的 HAL9000。
* Visicalc 需要一台擁有 32k RAM 的 Apple II,包括磁碟機、印表機和顯示器,根據 Apple 1979 年的定價表,售價為 2,875 美元(不含銷售稅),約相當於 2024 年的 12,000 美元。
相關文章