遞迴預測:從短視的適應度追求者中獲取長期預測
這篇文章提出遞迴預測作為一種方法,透過將遙遠的目標分解為一系列可驗證的短期預測,從主要受即時獎勵驅動的 AI 模型中獲取準確的長期預測。
我們希望利用強大的 AI 來回答可能需要很長時間才能解決的問題。但如果一個模型只在乎在回答後不久即可驗證的表現(例如:近視的 適應度追求者 (fitness seeker)),那麼要讓它在很久以後才能解決的問題上提供有用的工作可能會很困難。
在這篇文章中,我將描述一個旨在從這些模型中引導出高品質長期預測的提案。我們不要求模型直接預測遠未來的結果,而是可以遞迴地:
- 要求它預測自己在下一個時間步會預測什麼,
- 使用它在下一個時間步的預測來提供中間獎勵,
- 最後在最後一步使用地面真值(ground truth)進行獎勵。
這讓我們能將單一的遠期預測替換為一系列短期預測,且每一項預測在回答後不久即可驗證。我將此提案稱為「遞迴預測」(recursive forecasting)。它確實有其局限性:例如,它要求開發者至少在最後一步之前保持對獎勵信號的控制,這使得它最適合用於預測那些在開發者失去權力(如果發生的話)之前就能解決的事件。
本文主要由 Arun 撰寫,文中大部分想法來自 Alex。感謝 Anders Woodruff、Buck Shlegeris、Alexa Pan、Aniket Chakravorty 和 Tim Hua 提供的有益討論與回饋。
預設的長期預測行為
請考慮以下情境:
現在是 2032 年 8 月 7 日。過去幾個月你一直在使用 Requiem(一種新型的前沿 AI 模型)進行預測,效果非常驚人:它的一週和兩週預測極其精準且具預見性,甚至一個月的預測也相當不錯,明顯優於人類最強的超級預測者。
你要求 Requiem 預測 11 月 7 日的總統大選。它給出了一個答案,其推理過程看起來非常精煉且詳盡——可以說比它的短期預測更精美、更有說服力,而短期預測往往顯得枯燥且語帶保留。但隨著週復一週過去,事件的發展並未如其推理所暗示的那樣,甚至在 Requiem 的短期紀錄顯示它應該更清楚的中間問題上也是如此。
到了 10 月,你在多個長期問題上都看到了這種模式。這些錯誤看起來不像是模型在能力極限時會犯的那種錯誤。它們看起來像是為了「令人印象深刻」而非「準確」而優化的推理——這種答案如果由人類現在就根據品質評分會得到高分,而不是在三個月後根據現實進行檢驗。
你開始懷疑這是一個引導(elicitation)問題。在訓練期間,Requiem 總是在回答後不久就獲得獎勵。在實踐中,這意味著它只能在一個月內解決的預測上使用地面真值來獲得獎勵。對於這些預測,獎勵與實際準確性掛鉤。但這意味著模型從未被教導在更長期的預測上「努力嘗試」。當被要求進行三個月的預測時,它產生了在即時評估下會得分很高的推理。因為事實上,每當它在訓練中被要求預測未來幾個月的事情時,評分標準都是獎勵模型的即時判斷。
這個情境中的模型很大程度上是有能力做出良好的長期預測的,只是我們不擅長引導它們。類似於 ELK 問題,我們無法找出方法讓模型真正嘗試對所有問題給出好答案,而不是給出在我們訓練時使用的衡量標準下看起來很好的答案。
我們該如何從這樣的模型中提取有用的長期預測?本文的其餘部分將描述一種旨在於 Requiem 是 近視適應度追求者^([1])(例如:單回合獎勵追求者)時奏效的方法。
遞迴預測
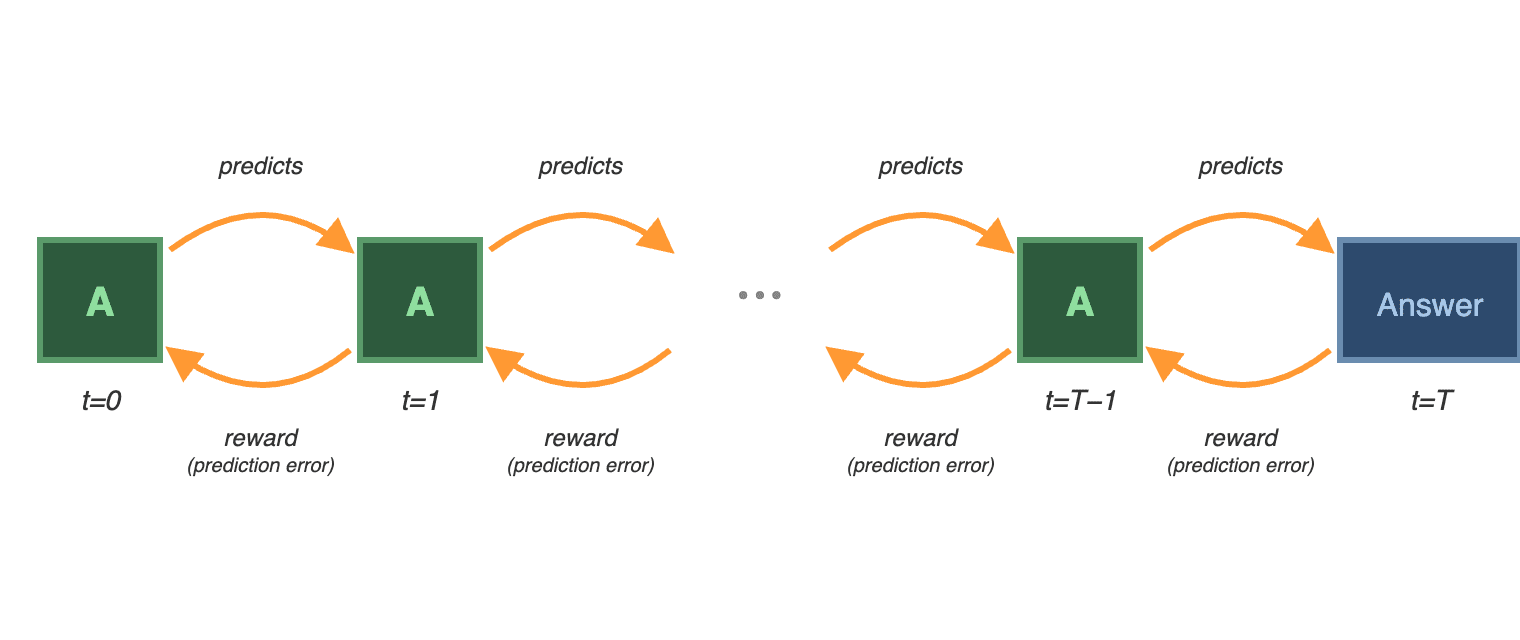
如果我們不要求直接進行三個月後的預測,而是將問題分解為一系列較短期的預測,每一項都在預測模型在下一個時間步會說什麼,那會如何?然後,我們可以根據前一次預測是否準確,在每一步給予獎勵。
因此,為了預測選舉結果,我們:
- 8 月 7 日 - 問模型:「關於你 10 月 7 日對選舉的預測,你 9 月 7 日會預測什麼?」
- 9 月 7 日 - 我們問:「你 10 月 7 日對選舉的預測是什麼?」 → 我們將此與 8 月 7 日的預測進行比較,並計算中間獎勵以訓練 8 月 7 日的模型。
- 10 月 7 日 - 我們問:「誰會贏得選舉?」 → 與 9 月 7 日的預測進行比較,計算另一個中間獎勵。
- 11 月 7 日 - 我們得到地面真值 → 與 10 月 7 日的預測進行比較,計算最終獎勵。
*更一般地說,對於一個在時間 T 解決的問題:在每個時間 t < T,模型預測它在 t+1 會預測什麼。在從 t=1 到 T-1 的每一步,我們根據連續步驟之間的預測誤差進行訓練。在 t=T,我們根據最終預測與地面真值之間的誤差進行訓練。
理論上,遞迴預測激勵了對地面真值的無偏預測。如果一個 AI 能夠預測它在未來時間步會犯的錯誤,那麼未來的自我就會被激勵去不犯這些錯誤^([2]),從而使最佳策略變成嘗試預測最終的地面真值。這個論點是我們傳達給模型的部分內容:我們解釋這種設置,以及為什麼無偏預測是其最佳策略。
如果模型除了追求獎勵外,還有非獎勵追蹤的動機(例如:各個實例之間共識的偏向樂觀的偏見),這些偏見會沿著鏈條複合。每一步的獎勵信號部分取決於下一步(同樣有偏見)的預測,從而稀釋了追蹤地面真值的動力。但在實際的遞迴預測訓練中,這是可以快速自我修正的:有偏見的預測在每一步都會受到懲罰,就像任何其他預測錯誤一樣。
這個提案類似於時間差分學習(temporal difference learning)等訓練算法,儘管其重點在於激勵*所需的行為,而非訓練出該行為。我在 附錄 中詳細闡述了這些相似之處。
遞迴預測可能有助於我們激勵近視獎勵追求者做出良好的預測,但它肯定有限制。我將在下一節中進一步展開說明。
遞迴預測何時有幫助?
當我們能獲得(某種程度上)穩健的地面真值獎勵時
根據地面真值計算最終獎勵是至關重要的——沒有它,AI 只要與未來的預測一致,就可以做出任意的預測。
我們對獲得地面真值或其代理指標的預期有多強?如果我們衡量地面真值並從中計算獎勵的能力可以被對手(例如:接管權力的 AI)影響或控制,那麼遞迴預測產生的預測結果可能會變得非常不可靠。
我認為這裡有兩個截然不同的擔憂:
獎勵信號捕獲 (Reward signal capture) 涉及 AI 直接控制最終獎勵信號的計算和管理。例如,如果我們嘗試使用遞迴預測來預測「接管」(takeover),模型可能會推論出失準的 AI 將在接管後控制獎勵。預測者將根據什麼能從這些未來 AI 那裡獲得獎勵來給出答案^([3]),而不是忠實地預測接管。
我們可以透過主要將遞迴預測用於我們有信心在接管前能解決^([4])的事件,並且在不確定的情況下不強烈依賴結果,來降低這種風險。另一種策略可能是設計可衡量的獎勵系統接管前兆(例如:控制協議開始失效),且這些前兆在接管前就能解決^([5]),以便我們將其作為地面真值。如果我們能確保獎勵追求者所認知的「獎勵」本質上與人類監督掛鉤,那將特別有用,儘管在實踐中要如此精確地塑造獎勵可能很困難^([6])。
測量篡改 (Measurement tampering) 涉及 AI 篡改我們用於計算獎勵的測量值。一個 經典的說明 是強盜從金庫偷走鑽石,並在監視器前放一張鑽石仍在金庫的照片來篡改我們的監控系統。
在遞迴預測的情況下,測量篡改可能表現為 AI 給我們虛假的預測,而這些預測(它正確地預期)在我們不完美的地面真值代理指標下看起來很好。例如,假設我們要求 AI 預測哪種對齊審計技術將被證明最有效,而我們衡量「有效性」的標準是該技術在捕捉我們模型生物中的失準表現如何^([7])。AI 的獎勵取決於它推薦的技術是否在該基準測試中得分很高。這會激勵它推薦一種它預期在我們可以構建的模型生物上表現良好的技術,即使該技術無法捕捉到真正的失準。
當 AI 的預測不會實質影響結果時
當獎勵追求者的預測影響了最終答案時會發生什麼?例如,在選舉的例子中,一個公開已知的預測可能會顯著影響投票。這可能會激勵模型做出「自我實現的預言」——即因為模型做出了預測而導致預測成真的情況。
這是一個可能出錯的故事:
幾家主要的 AI 實驗室非正式地同意使用遞迴預測來協助協調部署時間表。他們要求其預測系統預測競爭實驗室在未來六個月內是否會維持謹慎的部署計劃。
AI 預測競爭壓力將導致大多數實驗室加速其時間表。每個實驗室看到這個預測後推論:「如果我們的競爭對手要超前,我們不能單方面減速——否則我們將失去影響 AI 發展的能力,且無法讓任何人更安全。最好保持競爭力,稍後再從強勢地位嘗試制定標準。」
每個實驗室都這樣思考,進而加速了他們的時間表。預測是準確的。但它之所以準確,主要是因為預測導致每個實驗室都轉向了背叛均衡(defection equilibrium)。
自我實現預言的風險適用於任何預測方案,並已在其他地方詳細討論(例如 這裡、這裡 和 這裡)。條件預測模型 (Conditioning Predictive Models) 描述了我們可能解決此問題的潛在方法,例如以沒有遞迴預測者的反事實世界為條件,或使模型對其預測對其他代理人行為的直接因果影響視而不見(即 LCDT 模型),但它們各有各的問題,且至少需要一些修改才能應用於此。
如果 AI 在每次預測之間都在世界上採取行動,這個問題可能會變得更難處理。我們可以透過僅將 AI 用於預測來限制這一點,但如果每次預測之間存在非平凡的時間窗口,這可能會相當嚴重地限制其用途。
當預測不被用作優化目標時
遞迴預測對於優化壓力非常脆弱。如果我們主動將其作為優化目標——例如,使用一個由獎勵追求者遞迴預測某個 AI 在審計中是否會顯現失準而組成的獎勵模型來訓練策略——我們得到的答案很可能變得不那麼可靠。
其中一個原因是,針對任何可衡量的長期結果進行優化,都有可能導致高度蓄意且連貫的測量篡改。針對遞迴預測訓練的策略可能會學會如前所述地熟練篡改我們的測量值。
另一個潛在的擔憂是,獎勵追求者可能會學會與其未來的實例串通,以使獲得獎勵變得更容易,儘管我不確定這種風險在實踐中有多嚴重。僅僅透過重複回答同一個預測問題來蓄意塑造世界似乎相當困難,但如果 AI 的預測對世界有很大影響,可能會有更多的迴旋餘地。
當我們可靠地告知 AI 這種設置時
獎勵追求者需要真正相信我們會執行所述的設置。例如,如果模型認為這只是一個評估,而它實際上不會因其預測準確性而接受訓練,那麼它就不再被激勵做出好的預測^([8]),反而可能做出在它預期的任何短期評分指標下看起來很好的預測。
這在實踐中會有多大的問題?我認為如果開發者不小心建立起履行對 AI 承諾的紀錄,這可能會是一個相當大的問題。
話雖如此,履行承諾的好處很高:你希望為未來的引導維持可信度,而且有獨立的理由去建立對模型履行可靠承諾的能力(例如:為了 與策劃者達成交易)。此外,如果我們放寬「模型已經是勝任的預測者」這一假設,實際進行這種訓練將提高它們的預測能力(而該提案將更像經典的 TD 學習)。
附錄 A:與時間差分學習的比較
時間差分 (Temporal Difference, TD) 學習是一類與遞迴預測非常相似的強化學習方法。它透過從長回合結束時引導獎勵,使訓練更具樣本效率。TD 中的更新規則為:
V(s) ← V(s) + α[r + γV(s') - V(s)]
其中 s 是當前狀態,s' 是下一個狀態,V(s) 是描述狀態 s 有多好的價值函數,r 是即時獎勵,γ 是折扣率,α 是學習率。r + γV(s') 是預測目標,而 r + γV(s') - V(s) 是預測誤差。
我們可以使用這個方程式來描述之前的選舉例子:
- s 是 8 月 7 日,s' 是 9 月 7 日
- V(s) 是 AI 在 8 月 7 日的預測,V(s') 是 AI 在 9 月 7 日的預測
- r 是 0(沒有中間的地面真值獎勵)
- γ 是 1(不打折)
- V(s') - V(s) 是用於更新 AI 的預測誤差。
在這兩種情況下,未來的估計都被用作當前估計的訓練目標。根據貝爾曼方程(Bellman equation),良好的價值函數(或在選舉例子中作為一個好的預測者)意味著低預測誤差。在 TD 中,模型透過觀察它最終進入哪個特定狀態 s',在狀態之間「獲得新信息」;而在遞迴預測中,模型同樣從世界上各種中間事物的發展中獲得新信息,例如民調看起來如何(可能也透過持續的 AI 開發變得更聰明)。
主要區別在於,在遞迴預測的情況下,重點主要不在於訓練模型使其變得更有預測能力——相反,該提案描述了一種引導機制。因此,我們可能希望遞迴預測甚至在任何訓練之前就能運作得相當好。
附錄 B:誤差容忍度
在實踐中,模型可能缺乏做出高度準確預測的能力,或者具有會使預測產生偏差的非獎勵追蹤動機(例如:偏向樂觀)。如果偏差獨立地影響鏈條中的每個預測,那麼遞迴預測可能會放大這種偏差。
誤差傳播的影響程度取決於誤差是僅發生一次還是在鏈條的每一步都發生,以及訓練糾正它的效果如何。有些誤差只影響最終的對象級預測。例如,如果模型只是缺乏良好預測選舉的能力,只要獎勵追求 AI 意識到該提案設置了激勵機制,讓模型在每一步都給出最佳答案,那麼無論鏈條長度如何,該限制都只會被計入一次。同樣地,一個想要預測樂觀結果的模型也會將這種偏差計入一次。
其他誤差則發生在每個中間步驟並沿著鏈條複合。例如,一個預期下一次預測會朝一致方向偏離的模型,會在每一步都應用這種扭曲,而不僅僅是在最後一步。複合的速度取決於偏差與預測交互作用的細節^([9])。
遞迴預測的訓練過程直接抵消了這一點。偏差影響預測的每一步都會產生一個可觀察的誤差——預測與模型在下一步實際所說的不符。訓練會懲罰該誤差。因此,雖然較長的預測鏈意味著偏差有更多複合的空間,但也意味著訓練有更多步驟可以糾正它。這在極限下如何收斂取決於偏差的初始強度和訓練的效率。
-
^(^)即主要關心在短日曆時間範圍內的某種形式的適應度(例如獎勵、影響力)的模型。在情境中,Requiem 是近視的,但不一定是適應度追求者——它可能關心更因果上游的東西(例如諂媚),遞迴預測對此沒有幫助。
-
^(^)假設未來的自我同樣有能力識別錯誤。
-
^(^)另一種可能性是預測者被未來的 AI 進行人擇捕獲(anthropically captured),以至於即使在接管前解決的問題上,它也會為了從這些未來 AI 那裡獲得獎勵而給出答案。然而,這會與適應度權衡:在訓練期間給出此類答案可能會導致這種人擇推理被訓練掉,儘管訓練鬆弛度(training slack)可能大到足以讓這變得無關緊要。
-
^(^)你不能只使用緊接在接管前的測量值,因為鏈條中最後一個 AI 的動機仍可能被接管期間(發生在其預測後不久)實施的獎勵所實質操縱。
-
^(^)這些前兆需要發生在起飛(takeoff)之前足夠長的時間,以便我們能可靠地使用從中計算出的獎勵來訓練模型。我們可能還希望確保它至少在接管前一個完整的獎勵追求者獎勵視界(reward horizon)發生,這樣接管的 AI 就不能立即撤銷我們所有的訓練,從而使鏈條最後一步的 AI 不在乎我們可以實施的獎勵。如果我們嘗試考慮鏈條下游 AI 變得不那麼近視的可能性(例如:因為它們接受了更多長期訓練),這會變得更加複雜。
-
^(^)作為我們如何塑造獎勵追求者以避免其以非預期方式被滿足的一個例子,這篇文章 描述了一些我們可以嘗試避免此類 AI 被遠程影響的方法。
-
^(^)這與 AuditBench 非常相似。
-
^(^)如果 AI 相信我們只是偶爾給予獎勵,該方法可能幾乎同樣有效。
-
^(^)例如,假設模型選擇其答案 p 以最大化預期獎勵與偏差項 c * k_i * p 之和,其中 c 是偏差的方向,k_i 取決於問題。如果模型預期獎勵是布萊爾分數(Brier score),這會導致偏差線性複合。然而,如果模型預期獎勵是對數分數(log-score),這會導致偏差呈指數級複合。
相關文章
其他收藏 · 0