我們的 AI 代理在 Google Kubernetes Engine 中發現了 WireGuard 的程式錯誤
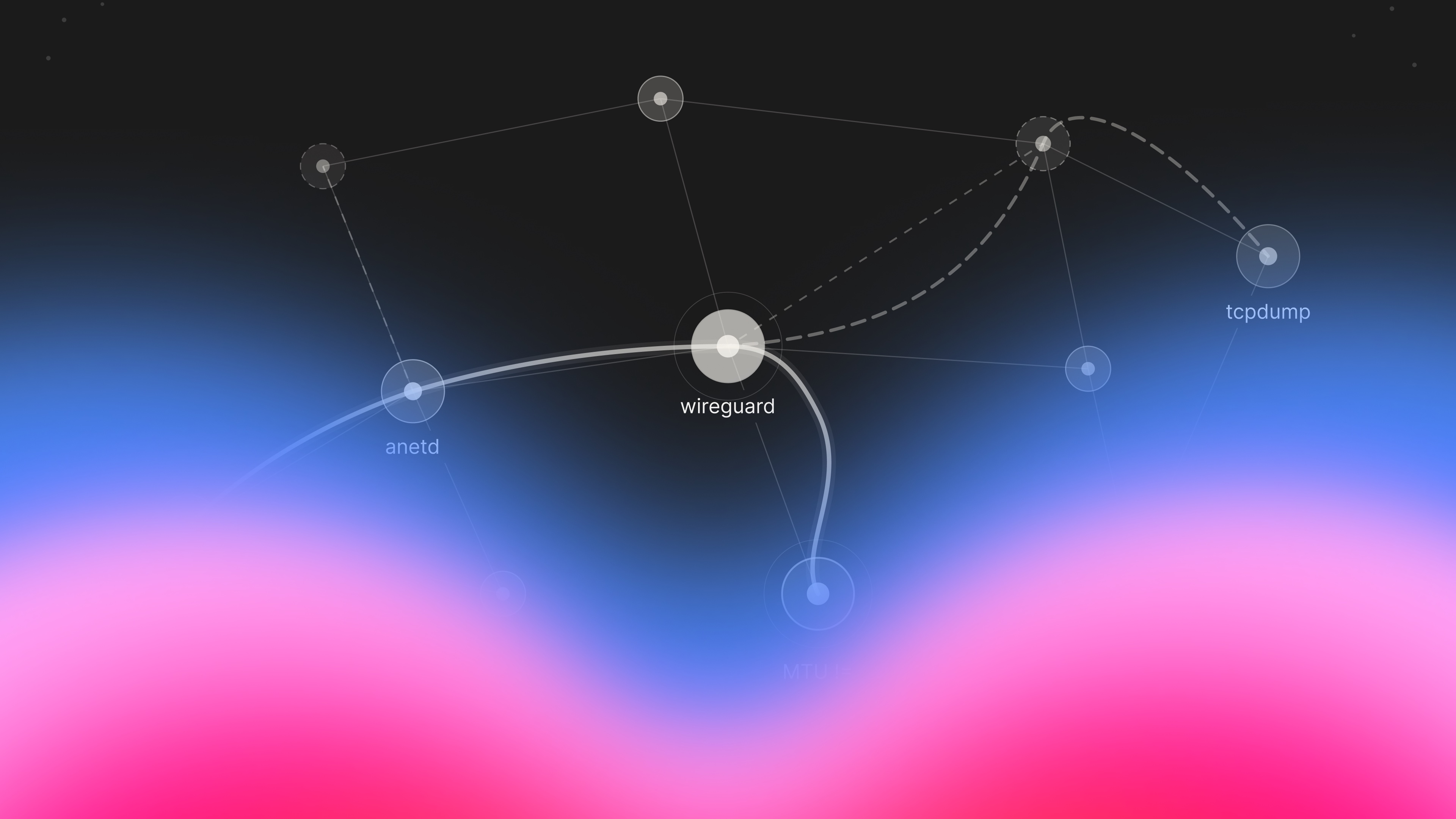
我們的基礎設施團隊利用 AI 代理識別出 Google 在 WireGuard 的 anetd 實作中存在嚴重的併發程式錯誤,這導致了我們 Kubernetes 集群中頻繁的 Pod 崩潰和網路不穩定。
背景
Lovable 團隊在 Google Kubernetes Engine (GKE) 環境中遭遇了嚴重的網路不穩定問題,導致每秒處理大量沙盒環境的系統出現連線重置與逾時。透過 AI 代理輔助分析日誌,工程師發現 GKE 內建的網路層組件 anetd 因 WireGuard 整合程式碼中的併發存取錯誤而不斷崩潰,隨後在修復過程中又因節點間 MTU 設定不一致引發了第二波連線故障。
社群觀點
Hacker News 的讀者對於這篇技術文章展現了兩極化的反應,討論焦點主要集中在文章的寫作風格、AI 在除錯中的實際貢獻,以及技術決策的合理性。許多資深開發者對文章展現出的「AI 語調」表示強烈反感,認為這種充滿特定節奏感、過度使用破折號以及固定標題模式的內容,讓技術分享顯得像是不具誠意的文字填充。有評論指出,這種過於刻意的敘事方式反而掩蓋了技術細節的深度,讓人難以忍受。
針對技術層面,社群對「AI 代理發現錯誤」這一說法提出了質疑。多位網友分析原文後指出,AI 僅僅是指出 pod 正在重啟這個顯而易見的現象,真正的關鍵除錯工作——分析崩潰轉儲、定位併發存取衝突以及追蹤 WireGuard 模組的堆疊追蹤——實際上是由工程師 Sascha 完成的。讀者認為標題有過度美化 AI 功勞之嫌,本質上仍是人類工程師在引導工具。此外,關於團隊決定直接關閉節點間加密以恢復穩定性的做法,也引發了安全意識的爭論。部分評論認為在雲端服務商的私有網路中放棄加密是種大膽且具風險的選擇,且文章並未解釋為何該問題在特定時間點突然爆發,缺乏對根本原因的深度探討。
此外,關於 WireGuard 常見的 MTU 匹配問題,社群中也有不少共鳴。有經驗的網路工程師指出,MTU 導致的連線失敗是 WireGuard 部署中最典型的坑,對於 Lovable 團隊選擇重啟整個虛擬機集群而非優化腳本配置的處理方式,部分讀者持有保留意見。整體而言,HN 社群認為這篇文章雖然記錄了一個真實的基礎設施故障,但其過度包裝的寫作風格與對 AI 貢獻的誇大,削弱了技術社群對其內容的信任感。
延伸閱讀
在討論過程中,有讀者提到了 Go 語言的專業除錯工具 Delve,這是在處理類似 anetd 這種以 Go 撰寫的組件崩潰時,工程師常用的深度分析工具。此外,關於 AI 生成內容的辨識討論中,也提及了 Hacker News 過往對於「Slop」(垃圾內容)定義的相關討論串。
相關文章