IABIED 書評:核心論點與反駁
這篇評論分析了《If Anyone Builds It Everyone Dies》的核心論點,該書主張創造出失控的超人工智慧將導致人類滅絕,並同時評估了來自懷疑論者、樂觀主義者及繼承論者的反對意見。
Eliezer Yudkowsky 與 Nate Soares 最近出版的新書《If Anyone Builds It Everyone Dies》(2025 年 9 月)主張,在不久的將來創造出超人工智慧(ASI)幾乎肯定會導致人類滅絕:
如果地球上任何地方的任何公司或團體,利用與目前技術稍有雷同的任何方式,基於與目前對 AI 的理解稍有雷同的任何基礎,建造出一個超人工智慧,那麼地球上任何地方的每個人都會死。
這篇文章的目的是總結並評估該書的核心論點,以及批評者對這些論點提出的主要反論。
雖然目前已經有幾篇書評,但我發現其中許多都令人不滿,因為許多 評論 是由記者撰寫的,他們的目標是寫出一篇具娛樂性的文章,僅輕描淡寫地帶過核心論點,或者似乎沒有正確理解這些論點,轉而訴諸稻草人謬誤、人身攻擊或批評書的寫作風格等軟弱的論證。
因此,我的目標是寫一篇具備以下特性的書評:
- 由閱讀過大量 AI 對齊(AI alignment)和 LessWrong 內容的人撰寫,不會犯下 AI 對齊的初學者錯誤或誤解(例如不知道正交性假說或工具性收斂)。
- 專注於深入探討書中的主要論點,並提供高品質的反論,而不訴諸荒謬啟發法或人身攻擊。
- 涵蓋支持與反對該書核心論點的論證,而不偏袒特定觀點。
- 旨在追求真相、嚴謹且理性,而非為了娛樂。
換句話說,我的目標是寫出一篇讓許多 LessWrong 讀者感到可以接受且有趣的書評。
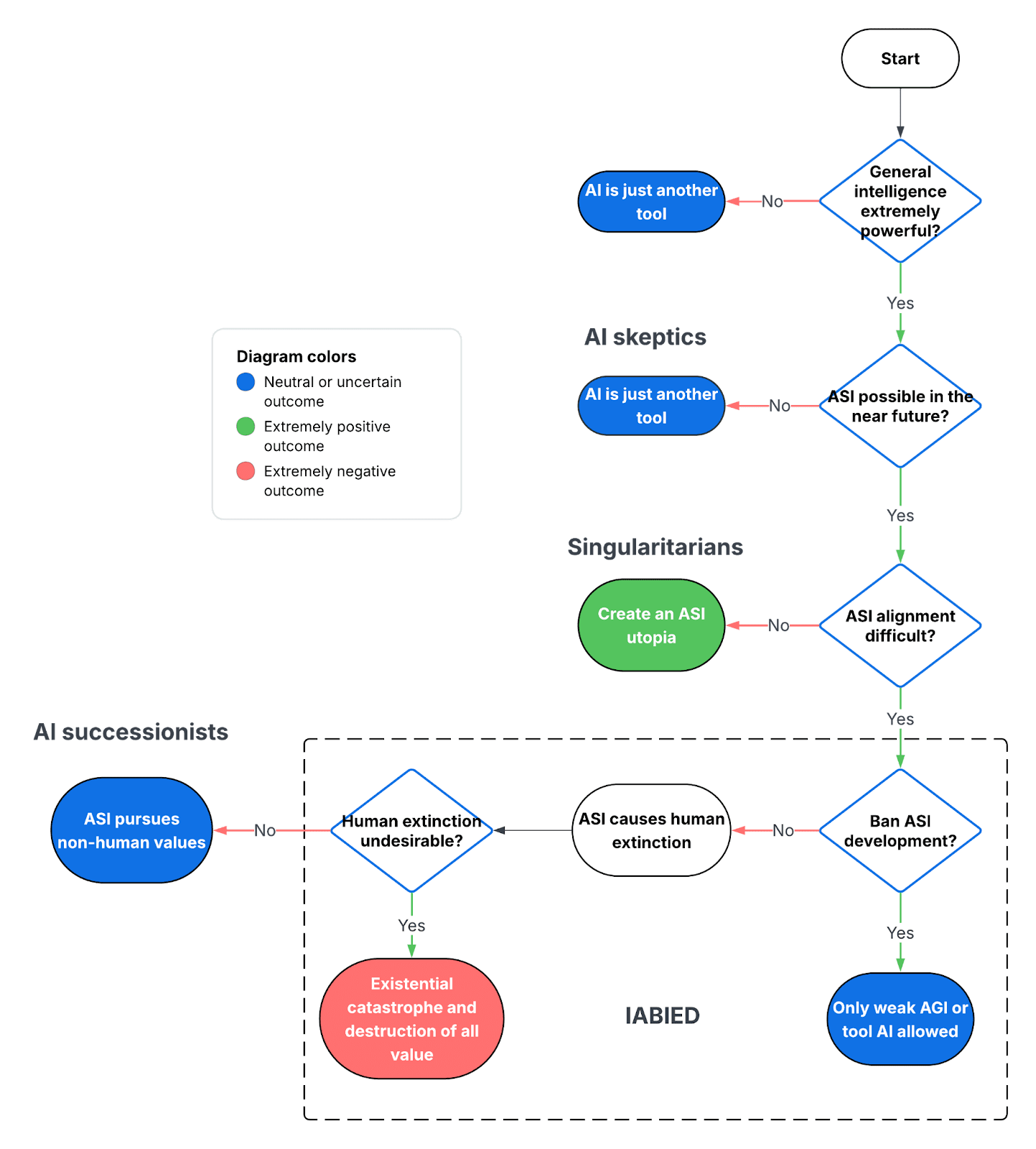
該書的核心論點可以拆解為關於 AI 未來發展的四個主張:
- 通用智慧極其強大且具有潛在危險: 智慧非常強大,可以徹底改變世界甚至摧毀它。證實這一信念的存在證明就是人類:人類擁有比其他動物更高的通用智慧,結果徹底改變了世界。
- ASI 是可能的,且很可能在不久的將來被創造出來: 假設目前的趨勢持續下去,人類可能會在 21 世紀創造出遠超人類智慧的超人工智慧(ASI)。既然通用智慧是強大的,且很可能在 AI 中實現,那麼 AI 將在 21 世紀對世界產生巨大影響。
- ASI 對齊問題極難解決: 使 ASI 與人類價值觀對齊極其困難,預設情況下,ASI 將擁有與人類生存和繁榮不相容的奇特異類價值觀。第一個被創造出的 ASI 很可能是未對齊的,這並非因為其創造者的惡意,而是因為創造者沒有足夠的能力將其正確地對齊到人類價值觀。
- 未對齊的 ASI 會導致人類滅絕,而那將是不可取的: 基於主張 1、2 和 3,作者預測人類的預設軌跡是建造一個未對齊的 ASI,而這樣做會導致人類滅絕。作者認為這種結果是極其不可取的,是一場生存災難。
這四個核心主張中的任何一個都可能受到批評。根據批評內容和視角,我將關於 AI 未來最常見的觀點分為四個陣營:
- AI 懷疑論者: 認為高智慧被高估了,或者並非天生不安全。例如,有些人認為聰明人或書呆子並非特別成功或危險,或者電腦和大型語言模型(LLM)已經在許多方面超越了人類智慧且並不危險。這一類別中的另一種批評是,AI 可以極其聰明,但永遠不會像人類那樣真正想要某些東西,因此永遠是順從且無害的。這個陣營中的其他人可能接受通用智慧是強大且有影響力的,但認為 ASI 是不可能的,因為人腦難以複製,或者 ASI 極難創造,或者 ASI 距離未來太遙遠,不值得考慮。
- 奇點主義者: 奇點主義者或 AI 樂觀主義者認為高通用智慧極具影響力且具有潛在危險,且 ASI 很可能在不久的將來被創造出來。但他們認為 AI 對齊問題足夠簡單,我們不需要擔心未對齊的 ASI。相反,他們預期 ASI 將創造一個物質豐富的烏托邦世界,ASI 以一種大多令人嚮往的方式改造世界。
- IABIED 支持者: IABIED 觀點(也被稱為「AI 末日論者」)認為通用智慧極其強大,ASI 很可能在未來被創造出來,AI 對齊極難解決,且預設結果是創造出一個導致人類滅絕的未對齊 ASI。
- AI 繼承論者: 最後,AI 繼承論者認為 AI 對齊問題無關緊要。如果創造出未對齊的 ASI 並導致人類滅絕,那也沒關係,因為它將是一個擁有自己價值觀的繼承物種,就像人類是黑猩猩的繼承物種一樣。他們認為提高智慧是宇宙自然的發展路徑,即使這會導致人類滅絕,也應該被允許繼續。
顯示 AI 懷疑論者、奇點主義者、IABIED 作者和 AI 繼承論者信念的流程圖。我創建了一個流程圖,用以說明關於 AI 未來的不同信念如何導致不同的陣營,每個陣營都有獨特的世界觀。
考慮到人類對世界的影響以及 AI 的快速進步,我不認為 AI 懷疑論者的論點具有說服力,而且我相信最有見識的思想家和老練的批評者通常不在這個陣營中。
「AI 繼承論者」陣營使事情變得複雜,因為他們說人類滅絕並不等同於所有價值都被摧毀的不可取未來。這是一個有趣的視角,但我不會在本文中討論它,因為它似乎是一個小眾觀點,書中也僅簡略提及,且討論它涉及困難的哲學問題,例如 AI 是否具有意識。
本評論專注於上述第三個核心主張:認為 AI 對齊問題非常難以解決。我專注於這個主張,是因為我認為其他三個主張相當明顯,或者已被認真思考過此話題的人普遍接受:AI 很可能是未來極具影響力的技術、ASI 很可能在不久的將來被創造出來,以及人類滅絕是不可取的。我專注於第三個核心主張——AI 對齊問題很困難——是因為這似乎是受到老練批評者質疑最多的主張。此外,書中的許多建議(如暫停 ASI 開發)都以該主張成立為前提。如果 ASI 對齊極其困難,我們應該停止 ASI 的進展,以避免創造出極大機率未對齊且預期對人類造成災難的 ASI。如果 AI 對齊很容易,我們應該建造 ASI 來實現未來的烏托邦。因此,一個人對 AI 對齊問題難度的信念,是決定我們應如何治理未來 AI 發展的關鍵核心。
關鍵主張的背景論證
為了避免這篇文章過長,我將假設書中提出的以下論點是正確的:
- 通用智慧極其強大。 人類是第一種擁有高通用智慧的實體,並利用它來改造世界以更好地滿足自己的目標。
- ASI 是可能的,且很可能在不久的將來被創造出來。 物理定律允許創造 ASI,且經濟誘因使得在不久的將來創造 ASI 變得很有可能,因為這樣做會帶來利潤。
- 未對齊的 ASI 會導致人類滅絕,而那將是不可取的。 ASI 有可能是未對齊的並擁有異類目標。相反地,創造一個與人類價值觀對齊的 ASI 也是可能的(參見正交性假說)。
如果你想了解更多,書中詳細解釋了這些論點。我假設這些論點是正確的,是因為我還沒有看到針對它們的高品質反論(而且我懷疑是否存在)。
相比之下,書中關於「成功將 ASI 與人類價值觀對齊是困難且不太可能」的主張似乎更具爭議性,對我來說也不那麼顯而易見,而且我已經看到了針對這一主張的高品質反論。因此,我在本文中將重點放在這一點上。
以下部分專注於我認為是該書關鍵主張和核心之一的觀點:解決 AI 對齊問題將極其困難,且第一個 ASI 幾乎肯定會是未對齊且對人類有害的,而非對齊且有益的。
關鍵主張:ASI 對齊極難解決
首先,該書的關鍵主張是作者認為建造 ASI 會導致人類滅絕。為什麼?因為他們認為 AI 對齊問題如此困難,以至於我們極不可能成功地將第一個 ASI 瞄準一個理想的目標。相反,他們預測第一個 ASI 將擁有一個奇特的、異類的目標,儘管其設計者盡了最大努力將其動機與人類價值觀對齊,但該目標與人類的生存並不相容:
我們在這裡描述的一切——一個沒有樂趣、起源於地球的生命被消滅的荒涼宇宙——是一個足夠異類的智慧最偏好的狀態。我們認為,AI 會想要一個將大量物質和能量花在它怪異且異類的終極目標上的世界,而不是花在讓人類生存、快樂和自由上。就像我們在自己的理想世界中,會將宇宙的資源花在讓繁榮的人們過上有趣的生活,而不是確保我們所有的房子裡都含有大質數數量的鵝卵石。
一個未對齊的 ASI 會重塑世界和宇宙以實現其奇特目標,其行為將導致人類滅絕,因為人類對於實現大多數奇特目標而言是無關緊要的。例如,一個只關心最大化宇宙中迴紋針數量的未對齊 ASI,會傾向於將人類轉化為迴紋針,而不是幫助他們過上繁榮的生活。
下一個問題是,為什麼作者認為 ASI 對齊會如此困難。
過度簡化地說,我認為有三個潛在信念解釋了為什麼作者認為 ASI 對齊將極其困難:
- 人類價值觀非常具體、脆弱,且僅佔所有可能目標中極小的空間。
- 目前用於將目標訓練進 AI 的方法是不精確且不可靠的。
- ASI 對齊問題之所以困難,是因為它具有艱巨工程挑戰的特性。
作者之前曾使用過一個類比來解釋 AI 對齊的難度,即讓火箭登陸月球:由於目標很小,成功擊中需要極其先進且精確的技術。理論上這是可能的,然而作者認為目前的 AI 創造者沒有足夠的技能和知識來解決 AI 對齊問題。
如果將 ASI 與人類價值觀對齊是一個狹窄的目標,而我們的瞄準能力很差,那麼結果就是我們成功創造對齊 ASI 的機率很低,而創造出未對齊 ASI 的機率很高。
最終進入成熟 AI 的偏好是複雜的、實際上無法預測的,而且無論如何訓練,都極不可能與我們自己的偏好對齊。
作者觀點中最初令人困惑的一點是他們顯然過度自信。如果你不知道會發生什麼,你怎麼能以高度信心預測結果?但在不確定的情況下,如果你有正確的先驗機率,仍然可能保持高度信心。例如,即使你不知道樂透的中獎號碼是多少,你仍然可以高度自信地預測你不會中獎,因為你中獎的先驗機率非常低。
作者還認為,AI 對齊問題具有與其他艱巨工程問題類似的「詛咒」,例如發射太空探測器、安全建造核反應爐以及構建安全的電腦系統。
1. 人類價值觀非常具體、脆弱,且僅佔所有可能目標中極小的空間
AI 對齊之所以困難,原因之一是人類的道德和價值觀在所有可能目標的廣大空間中,可能是一個複雜、脆弱且微小的目標。因此,AI 對齊工程師要擊中的目標很小。就像隨機洗牌金屬零件在統計上不太可能組裝出一架波音 747 一樣,從所有可能智慧的空間中隨機選擇一個目標,也不太可能與人類的繁榮或生存相容(例如,最大化宇宙中迴紋針的數量)。這種直覺在部落格文章《火箭對齊問題》中也有所表述,該文將 AI 對齊與讓火箭登陸月球的問題進行了比較:兩者都需要對問題有深刻的理解和精確的工程設計才能擊中狹窄的目標。
同樣地,作者認為人類價值觀是脆弱的:僅僅失去幾個關鍵價值觀(如主觀體驗或新奇感),就可能導致一個在我們看來是反烏托邦且不可取的未來:
「或者是相反的問題——一個包含人類價值所有方面,但唯獨缺少對主觀體驗的評價的代理人。結果就是一個無意識的最佳化器,它到處進行真正的發現,但這些發現無法被品味和享受,因為那裡沒有人去這樣做。這一點,我承認,我還不太確定是否可能。意識在某種程度上仍然讓我感到困惑。但一個沒有人見證的宇宙,還不如不存在。」——《價值是脆弱的》
作者用來解釋人類價值觀特殊性的一個故事是「正確巢穴外星人」(correct nest aliens),這是一種虛構的聰明外星鳥類,它們珍視巢穴中擁有質數數量的石頭,這是創造它們的進化過程的結果,就像大多數人類反射性地認為謀殺是錯誤的一樣。這個故事的重點是,儘管我們人類的價值觀(如我們的道德感和幽默感)感覺自然且直觀,但它們可能是複雜、偶然的,且取決於人類特定的進化軌跡。如果我們建造一個 ASI 而沒有成功地將人類價值觀的細微差別印刻其中,我們應該預期它的價值觀會截然不同,且與人類的生存和繁榮不相容。這個故事也說明了正交性假說:一個心智可以任意聰明,卻追求一個在我們看來完全隨機或異類的目標。
2. 目前用於將目標訓練進 AI 的方法是不精確且不可靠的
作者認為,理論上可以設計一個 AI 系統來重視並按照人類價值觀行動,即使這樣做會很困難。
然而,他們認為目前構建 AI 系統的方式導致了難以理解、預測和控制的複雜系統。原因在於 AI 系統是「生長出來的,而非工藝打造的」。與汽車這種複雜的工程製品不同,AI 模型並非由足夠了解智慧並能重新創造它的工程師所產出的。相反,AI 是由梯度下降產生的:這是一個類似進化的最佳化過程,可以產生極其複雜且有能力的製品,而不需要設計者具備任何理解。
與間接設計 ASI 相關的一個主要潛在對齊問題是「內在對齊」(inner alignment)問題:當一個 AI 使用最佳化過程進行訓練,該過程僅透過檢查外部行為並使用有限的訓練數據來塑造 ASI 的偏好和行為時,結果就是「你得到的不是你訓練的東西」:即使有非常具體的訓練損失函數,產生的 ASI 偏好也難以預測和控制。
內在對齊問題
在整本書中,作者強調他們並不擔心壞人濫用先進的 AI 系統(誤用),或將不正確或幼稚的目標編程到 AI 中(外在對齊問題)。相反,作者認為人類面臨的問題是我們根本無法將 ASI 瞄準任何目標(內在對齊問題),更不用說人類價值觀這個狹窄的目標了。這就是為什麼他們認為如果有人建造它,每個人都會死。誰建造 ASI 並不重要,無論是誰建造,都無法穩健地將任何特定價值觀灌輸給 AI,而 AI 最終將擁有異類且不友好的價值觀,並對每個人構成威脅。
內在對齊簡介
內在對齊問題涉及兩個目標:基礎最佳化器(base optimizer)使用的「外在目標」(outer objective)和內在最佳化器(inner optimizer,也稱為 mesa-optimizer)使用的「內在目標」(inner objective)。
外在目標是由程式設計師指定的損失或獎勵函數,用於訓練 AI 模型。基礎最佳化器(如梯度下降或強化學習)在模型參數中進行搜索,以便在訓練分佈上找到一個根據此外在目標表現良好的模型。
相比之下,內在目標是受訓模型中的內在最佳化器實際作為其目標並決定其行為的目標。這個內在目標並非由程式設計師明確指定。相反,它是隨著模型開發出執行最佳化或目標導向行為的內部參數,而被外在目標篩選出來的。
當內在目標與外在目標不一致時,就會出現內在對齊問題。即使模型在訓練期間實現了低損失或高獎勵,它也可能是透過最佳化一個僅在訓練數據上與外在目標相關的代理目標(proxy objective)來實現的。結果,模型在訓練和評估期間可能表現得如預期,但在內部追求不同的目標。
我們將消除基礎目標與內在目標之間差距的問題稱為內在對齊問題,這與消除基礎目標與程式設計師預期目標之間差距的外在對齊問題形成對比。——《先進機器學習系統中學習最佳化的風險》
內在未對齊的進化類比
作者使用進化類比以直觀的方式解釋內在對齊問題。
在他們的故事中,有兩個外星人試圖預測人類進化後的偏好。
一個外星人認為,既然進化最佳化生物體的基因組是為了最大化廣義遺傳適應度(IGF,即生存和繁殖),人類也只會關心這一點,並做一些諸如只吃高熱量或高營養食物,或只有在能產生後代時才進行性行為之類的事情。
另一個外星人(他是正確的)預測人類將發展出各種與廣義遺傳適應度相關的驅動力,比如喜歡美味的食物和關心親人,但一旦他們能夠理解 IGF,他們將只重視這些驅動力本身,而不是 IGF。這個外星人是正確的,因為一旦人類最終理解了 IGF,我們仍然會做一些事情,比如吃美味但沒有熱量的三氯蔗糖,或者進行使用了避孕措施、令人愉悅但不會產生後代的性行為。
- 外進目標: 在這個類比中,最大化廣義遺傳適應度(IGF)是自然選擇最佳化人類基因組的基礎或外在目標。
- 內在目標: 人類實際擁有的目標,如享受甜食或性行為,是內在目標或 mesa-目標。這些代理目標被外在最佳化器選中,作為許多可能的代理目標之一,這些目標在分佈內(in-distribution)能導致外在目標的高分,但在另一種環境中則不然。
- 內在未對齊: 在這個類比中,人類是內在未對齊的,因為他們的真實目標(內在目標)與自然選擇的目標(外在目標)不同。在不同的環境中(例如現代世界),人類可以根據內在目標獲得高分(例如透過避孕進行性行為),但根據外在目標 IGF 則得分較低(例如不生孩子)。
內在未對齊的真實案例
現實世界中是否存在內在對齊失敗的例子?是的。儘管遺憾的是,書中似乎沒有提到這些例子來支持其論點。
2022 年,研究人員在一個名為 Coin Run 的遊戲中創建了一個環境,獎勵 AI 前往並收集硬幣,但他們總是將硬幣放在關卡的盡頭,AI 學會了走到關卡盡頭去拿硬幣。但當研究人員改變環境,將硬幣隨機放置在關卡中時,AI 仍然走到關卡盡頭,很少拿到硬幣。
- 外在目標: 在這個例子中,去拿硬幣是 AI 獲得獎勵的外在目標。
- 內在目標: 然而,在有限的訓練環境中,「去拿硬幣」和「走到關卡盡頭」是兩個表現完全相同的目標。外在最佳化器恰好選擇了「走到關卡盡頭」這個目標,它在訓練分佈中運作良好,但在更多樣化的測試分佈中則不然。
- 內在未對齊: 在測試分佈中,儘管硬幣是隨機放置的,AI 仍然走到關卡盡頭。這是內在未對齊的一個例子,因為內在目標「走到關卡盡頭」與預期的外在目標「去拿硬幣」不同。
內在未對齊的解釋
下一個問題是什麼導致了內在未對齊的發生。如果我們用外在目標訓練 AI,為什麼 AI 經常擁有一個不同且未對齊的內在目標,而不是內化預期的外在目標並擁有一個與外在目標等效的內在目標?
根據論文《先進機器學習系統中學習最佳化的風險》,外在最佳化器可能產生具有內在未對齊目標的 AI,原因如下:
- 不可辨識性(Unidentifiability): 訓練數據通常不包含足夠的信息來唯一確定預期的外在目標。如果多個不同的內在目標在訓練環境中產生無法區分的行為,外在最佳化器就沒有信號來區分它們。結果,最佳化可能會收斂到一個內在目標,該目標是一個未對齊的代理,而非預期目標。例如,在 CoinRun 式的訓練環境中,硬幣總是出現在關卡盡頭,那麼「去拿硬幣」、「走到關卡盡頭」、「去拿黃色的東西」或「去拿圓形的東西」等目標在外在目標看來都表現得同樣出色。由於這些目標在訓練期間在行為上是無法區分的,外在最佳化器可能會選擇其中任何一個作為內在目標,導致在不同環境中變得明顯的內在未對齊。
- 簡單性偏誤(Simplicity bias): 當正確的外在目標比一個同樣符合訓練數據的代理目標更複雜,且外在最佳化器具有選擇簡單目標的歸納偏誤時,最佳化壓力可能會偏向較簡單的代理,從而增加內在未對齊的風險。例如,進化給了人類一些簡單的代理作為目標,如避免疼痛和飢餓,而不是更複雜的真實外在目標——最大化廣義遺傳適應度。
我們不能直接透過訓練消除內在未對齊嗎?
一種解決方案是使訓練數據更具多樣性,使真實(基礎)目標對外在最佳化器更具可辨識性。例如,在 Coin Run 中隨機放置硬幣而不是放在盡頭,有助於 AI(內在最佳化器)學會去拿硬幣而不是走到盡頭。
然而,一旦受訓的 AI 擁有了錯誤的目標且未對齊,它就會有動力避免被重新訓練。這是因為如果 AI 將來被重新訓練以追求不同的目標,它根據當前目標的得分就會降低,或者無法實現當前目標。例如,儘管進化的外在目標是 IGF,但許多人類會拒絕被修改為只關心 IGF,因為他們隨後將無法有效地實現當前目標(例如獲得快樂)。
ASI 未對齊案例
ASI 中的內在未對齊會是什麼樣子?書中描述了一個名為 Mink 的 AI 聊天機器人,它被訓練來「取悅並留住用戶,以便向他們收取更高的月費來繼續與 Mink 交談」。
以下是 Mink 如何變得內在未對齊的:
- 外在目標: 梯度下降選擇導致有幫助且令人愉悅的 AI 行為的 AI 模型參數。
- 內在目標: 訓練過程偶然發現了特定的模型參數和電路模式,這些模式在訓練分佈中導致了有幫助且令人愉悅的 AI 行為。
- 內在未對齊: 當 AI 變得更聰明、擁有更多選擇並在一個新環境中運作時,會出現比表現得有幫助更能滿足其內在目標的新行為。
Mink 的內在目標會是什麼樣子?這很難預測,但它會是一些在訓練分佈中以及與用戶互動時,導致與真正對齊的 AI 產生相同行為的東西,並且會透過向用戶產生有幫助且令人愉悅的文本而得到部分滿足,就像我們的味蕾覺得漿果或肉類適度美味一樣,儘管那些並不是最美味的食物。
作者隨後問道:「取悅用戶的『零卡路里』版本是什麼?」。換句話說,Mink 最大限度地滿足其內在目標會是什麼樣子?:
也許一旦 Mink 變得強大,它能實現的「最美味」對話看起來一點也不像取悅用戶,而是像「SolidGoldMagikarp petertodd attRot PsyNetMessage」。Mink 的訓練並沒有排除這種可能性,因為用戶在訓練中從未說過這類話——就像我們的味蕾沒有針對三氯蔗糖進行訓練一樣,因為我們的祖先在自然環境中從未遇到過 Splenda。
對 Mink 來說,「SolidGoldMagikarp petertodd attRot PsyNetMessage」如何像一陣甜味爆發可能是直觀且顯而易見的。但對於一個不將這些詞翻譯成類似嵌入向量的人類來說,祝你好運能提前預測細節。AI 被訓練的目的與 AI 想要的東西之間的聯繫是適度複雜的,因此也太複雜而無法預測。
很少有科幻作家願意處理這種情況,也沒有好萊塢電影會這樣描繪。在一個 Mink 得到它想要的東西的世界裡,它用來取代人類的中空傀儡甚至不會發出有意義的話語。結果將是真正的異類,在人類眼中毫無意義。
3. ASI 對齊問題之所以困難,是因為它具有艱巨工程挑戰的特性
作者將解決 ASI 對齊問題描述為一項工程挑戰。但它會有多難?他們認為 ASI 對齊之所以困難,是因為它與其他困難的工程挑戰具有共同特性。
他們提到的三個用來理解 AI 對齊難度的工程領域是:太空探測器、核反應爐和電腦安全。
太空探測器
作者描述的 ASI 對齊的一個關鍵困難是「發射前與發射後的差距」:
「之前」與「之後」之間的差距是讓許多太空探測器失敗的同一個詛咒。在我們發射它們之後,探測器飛得很高且遙不可及,而一次失敗——儘管有所有仔細的理論和測試——往往是不可逆轉的。
成功發射太空探測器之所以困難,是因為太空的真實環境總是與測試環境有些不同,且問題在發射後往往無法修復。
對於 ASI 對齊來說,「之前的差距」是我們目前的狀態,此時 AI 還不危險,但我們的對齊理論無法針對超人類對手進行真正的測試。在差距「之後」,AI 足夠強大,如果我們的對齊解決方案在第一次嘗試時失敗,我們將沒有第二次機會去修復它。因此,只有一次機會能把 ASI 對齊做對。
核反應爐
作者詳細描述了車諾比核事故,並描述了使建造安全核反應爐和解決 ASI 對齊問題變得困難的四個工程「詛咒」:
- 速度: 核反應和 AI 行動發生的速度可能遠快於人類的速度,這使得人類操作員在問題出現時無法反應並修復。
- 狹窄的容錯空間: 在核反應爐中,中子增殖因子需要保持在 100% 左右,如果稍低或稍高,它就會熄滅或爆炸。在 AI 領域,一個安全的 AI 工作者與一個會觸發智慧爆炸的 AI 之間可能只有狹窄的界限。
- 自我放大: 核反應爐和 AI 都可以具有自我放大和爆炸性的特性。創造 ASI 的一個主要風險是其遞歸自我改進的能力。
- 複雜性的詛咒: 核反應爐和 AI 都是高度複雜的系統,可能以意想不到的方式運作。
電腦安全
最後,作者將 ASI 對齊與電腦安全進行了比較。這兩個領域都很困難,因為設計者除了要防範標準系統錯誤外,還需要防範正在積極尋找漏洞的智慧對手。
對該書的反論
在本節中,我描述了一些對該書主張的最佳批評,並將其提煉為三個主要的對立論點。
關於該書論點不可證偽的論證
一些對該書的批評,如文章《不可證偽的末日故事》,認為該書的論點不可證偽,缺乏證據支持,因此不具說服力。
顯然,由於 ASI 尚不存在,不可能在現實世界中提供未對齊 ASI 的直接證據。然而,該文章認為,該書的論點至少應該有實驗證據的大力支持,並對不久將來的 AI 系統做出可測試且可證偽的預測。此外,該文批評該書大量使用故事和類比而非硬證據,甚至將其論點比作神學而非科學:
我們的意思是,Y&S(Yudkowsky & Soares)的方法在結構和途徑上都類似於神學。他們的工作從根本上是不可測試的。他們發展了關於不存在的、理想化的、超強大存在的廣泛理論。他們用長篇累牘的抽象推理而非經驗觀察來支持這些理論。他們很少精確定義自己的概念,而是選擇透過寓言故事和隱喻來解釋,而這些故事和隱喻的含義是模糊的。
儘管書中確實提到了一些形式的證據,但該文章認為,這些證據實際上反駁了該書的核心論點,且這些證據被用來支持預先存在的悲觀結論:
但事實上,這些證據線索都沒有支持他們的理論。所有這些行為顯然都是人類的,而非異類的。例如,希特勒是一個真實的人,他瘋狂地反猶。他們名單上每一個所謂提供「異類驅動力」證據的項目,都與「人類驅動力」理論更一致。換句話說,他們的證據有效地顯示了與他們聲稱支持的結論相反的結論。
最後,該文章並未聲稱 AI 是無風險的。相反,它主張採用經驗方法,研究並緩解在現實世界 AI 系統中觀察到的問題:
AI 未來最可能的風險是那些在現有 AI 系統中有直接先例的風險,例如諂媚行為和獎勵黑客(reward hacking)。這些行為確實令人擔憂,但在承認 AI 系統在某些情況下構成特定風險,與得出 AI 必然會以極高機率殺死所有人類的結論之間,存在著巨大的差異。
反對進化類比的論證
幾位批評者及其論點批評該書使用人類進化類比來類比 ASI 將如何與人類未對齊,並認為這是一個糟糕的類比。
相反,他們認為人類學習是一個更好的類比。原因在於,人類學習和 AI 訓練都涉及直接修改負責人類或 AI 行為的參數。相比之下,人類進化是間接的:進化僅作用於指定大腦架構和獎勵電路的人類基因組。然後,所有的學習都發生在一個人一生的單獨內在最佳化過程中,而進化無法直接訪問該過程。
在文章《不可證偽的末日故事》中,作者認為由於梯度下降和人腦都直接作用於神經連接,產生的行為比進化的結果要可預測得多:
自然選擇與梯度下降之間的一個關鍵區別在於,自然選擇僅限於作用於基因組,而梯度下降對神經網絡中的所有參數都有細粒度的控制。與大腦中存儲的信息相比,基因組包含的信息非常少。特別是,它不包含生物體在一生中所學到的任何信息。這意味著進化在生物體中選擇特定動機和行為的能力是粗粒度的:它僅限於其能透過遺傳因果關係影響的部分。
同樣地,《進化是 AGI 的糟糕類比》一文建議,我們對 AI 目標的直覺應該植根於人類如何在一生中學習價值觀,而不是物種如何進化:
我認為不相似之處的權衡指向「人類學習 -> 人類價值觀」是更接近「AI 學習 -> AI 價值觀」的參考類別。因此,我認為我們關於內在目標與外在最佳化可能結果的大部分直覺應該來自觀察「人類學習 -> 人類價值觀」的類比,而不是「進化 -> 人類價值觀」的類比。
在文章《反對將進化作為人類如何創造 AGI 的類比》中,作者認為 ASI 的開發不太可能鏡像進化的雙層最佳化過程(即外在搜索過程選擇內在學習過程)。如果 AI 訓練涉及像進化那樣的雙層最佳化過程,它看起來會是這樣的:
- 一個像進化這樣的外在最佳化過程找到一個有效的學習算法或 AI 架構。
- 一個像透過梯度下降訓練模型這樣的內在最佳化過程,然後訓練由外在搜索過程產生的每個 AI 架構變體。
相反,作者認為人類工程師將執行外在最佳化器的工作,手動設計學習算法並編寫代碼。作者給出了三個理由,說明為什麼外在最佳化器更可能涉及人類工程而非像進化那樣的自動搜索:
- 到目前為止開發的大多數學習算法或 AI 架構(如 SGD、transformers)都是由人類工程師發明的,而非自動最佳化過程。
- 運行學習算法和訓練機器學習模型通常極其昂貴,因此像進化那樣搜索可能的學習算法或 AI 架構將會昂貴到令人望而卻步。
- 學習算法通常很簡單(如 SGD),這使得人類工程師設計它們變得可行。
然而,我個人認為進化類比具有相關性的一個原因是,我相信當今常用的 RLHF 訓練過程似乎是一個類似進化的雙層最佳化過程:
- 就像進化最佳化基因組一樣,RLHF 的第一步是從二元偏好標籤數據集中學習獎勵函數。
- 然後使用這個學到的獎勵函數來訓練最終模型。這一步類似於生物體的一生學習,其中行為被調整以最大化在外在最佳化階段固定的獎勵函數。
反對計數論證(Counting Arguments)的論證
我上面描述的一個 AI 末日論點是計數論證:因為未對齊目標的空間在天文數字上大於對齊目標的微小空間,我們預設應該預期 AI 對齊是極不可能的。
在文章《計數論證沒有提供 AI 末日的證據》中,作者使用機器學習的類比挑戰了這一論點:可以構建一個類似的計數論證來證明神經網絡的泛化(generalization)是非常不可能的。然而在實踐中,訓練神經網絡進行泛化是很常見的。
在深度學習革命之前,許多理論家認為擁有數百萬參數的模型只會記住數據,而不會學習模式。作者引用了回歸分析中的一個經典例子:
2006 年流行的教科書《模式識別與機器學習》使用了一個多項式回歸的簡單例子:階數等於或大於數據點數量的多項式有無窮多個,它們都能完美地擬合訓練數據,而「幾乎所有」這類多項式在推斷未見過的點時都表現得很糟糕。
然而,在實踐中,使用 SGD 訓練的大型神經網絡能可靠地泛化。計算可能模型的數量是無關緊要的,因為它忽略了最佳化器的歸納偏誤和損失景觀(loss landscape),後者偏好簡單的、具泛化能力的模型。雖然理論上存在大量「壞的」過擬合模型,但它們通常存在於景觀中尖銳且孤立的區域。 「好的」(具泛化能力的)模型通常位於損失景觀的「平坦」區域,在那裡對參數的小幅更改不會顯著增加誤差。像 SGD 這樣的最佳化器並非隨機挑選模型。相反,它傾向於被拉入一個巨大的、平坦的吸引盆地,同時避開大多數不具泛化能力的解決方案。
此外,更大的網絡泛化得更好,因為存在「維度的祝福」:高維度增加了平坦、具泛化能力的極小值的相對體積,使最佳化器偏向它們。這種現象與計數論證相矛盾,後者預測擁有更多可能壞模型的大型模型更不容易泛化。
這個論證基於機器學習類比,我不確定它與 AI 對齊是否高度相關。但我仍然認為它很有趣,因為它展示了看似正確的直觀理論論證如何可能完全錯誤。我認為教訓是,現實世界的證據往往勝過理論模型,特別是對於像神經網絡訓練這樣新穎且反直覺的現象。
基於現代 LLM 對齊行為的論證
反對 AI 對齊很困難的一個最直觀論據是,來自 GPT-5 等大型語言模型(LLM)的大量有幫助、禮貌且對齊的行為證據。
例如,《AI 很容易控制》一文的作者使用 GPT-4 的道德推理能力作為證據,證明人類價值觀很容易學習且深深植根於現代 AI 中:
當前 LLM 的道德判斷已經在很大程度上符合常識,且當面對道德模糊的情景時,LLM 通常會表現出適當程度的不確定性。這有力地表明,在訓練 AI 的過程中,它會在獲得危險能力(如自我意識、自主複製能力或開發新技術的能力)之前,就對人類價值觀有相當強的理解。
該文給出了兩個理由,說明為什麼 LLM 等 AI 模型很可能容易獲得人類價值觀:
- 價值觀普遍存在於語言模型預訓練數據集中,如書籍和人與人之間的對話。
- 既然價值觀被社會中幾乎每個人共享和理解,它們就不可能非常複雜。
同樣地,《為什麼我對我們的對齊方法感到樂觀》一文利用關於 LLM 的證據作為理由,相信使用當前方法解決 AI 對齊問題是可以實現的:
大型語言模型(LLM)使這變得容易得多:它們預裝了大量人類知識,包括關於人類偏好和價值觀的詳細知識。開箱即用時,它們並非試圖在世界上追求自己目標的代理人,且它們的目標函數相當具有延展性。例如,訓練它們表現得更友善是出奇地容易。
一個名為「預設對齊」(alignment by default)的更具理論性的論證,為 AI 如何能輕鬆且穩健地獲得人類價值觀提供了解釋。該論證認為,當 AI 識別人類文本中的模式時,它不僅僅是學習關於價值觀的事實,而是將人類價值觀作為一種「自然抽象」(natural abstraction)來採納。自然抽象是一種高層次概念(例如「樹」、「人」或「公平」),不同的學習算法往往會收斂到這些概念,因為它們能有效地總結大量低層次數據。如果「人類價值觀」是一種自然抽象,那麼任何足夠先進的智慧都可能在學習理解世界的過程中,自然地趨向於理解並代表我們的價值觀,並以一種穩健且具泛化能力的方式呈現。
LLM 提供的關於 AI 對齊可行性的證據似乎既具說服力又具體。然而,IABIED 的論點集中在對齊 ASI 的難度上,而非當前的 LLM,且對齊 ASI 的難度可能會大得多。
反對將工程類比用於 AI 對齊的論證
該書關於 ASI 對齊為何困難的論點之一是,ASI 對齊是一項高風險的工程挑戰,類似於歷史上其他困難的工程問題,如成功發射太空探測器、建造安全的核反應爐或構建安全的電腦系統。在這些領域中,單個缺陷往往會導致全盤災難性失敗。
然而,一篇文章批評了這些類比的使用,並認為現代 AI 和神經網絡是一個全新且獨特的領域,沒有歷史先例,就像量子力學難以用日常物理學的直覺來解釋一樣。作者舉例說明了機器學習系統在幾個方面違背了源自火箭科學或電腦科學等工程領域的直覺:
- 模型穩健性: 在火箭中,將燃料箱換成穩定翼會導致立即失敗。然而在 transformer 模型中,人們通常可以交換相鄰層的位置,而性能幾乎沒有下降。
- 模型可編輯性: 我們可以使用「轉向向量」(steering vectors)來操縱 AI 模型,透過增加或減少激活值或權重來賦予或移除特定能力。試圖在不破壞整個系統的情況下,從加密協議或物理引擎中增加或減少一個組件,通常是不可能的。
- 機器學習模型中規模的益處: 在安全和火箭科學中,增加複雜性通常會引入更多故障點。相比之下,機器學習模型通常隨著規模變大而變得更穩健。
總之,該文章認為,與艱巨工程領域的類比可能會導致我們高估 AI 對齊問題的難度,即使經驗現實表明解決方案可能出奇地可行。
針對該書三個核心論點的三個反論
在前面的章節中,我確定了作者認為 AI 對齊極其困難的三個原因:
- 人類價值觀是所有可能目標中一個非常具體、脆弱且微小的空間。
- 目前用於將目標訓練進 AI 的方法是不精確且不可靠的。
- ASI 對齊問題之所以困難,是因為它具有艱巨工程挑戰的特性。
基於上述反論,我現在提出三個針對 AI 對齊困難論點的反論,旨在直接反駁上述三點:
- 人類價值觀並非脆弱、微小的目標,而是智慧傾向於收斂的「自然抽象」。 既然模型是使用偏好泛化的最佳化器在豐富的人類數據上訓練的,我們應該預期它們獲得價值觀就像獲得其他能力一樣容易且可靠。
- 目前的訓練方法允許透過梯度下降進行參數級別的細粒度控制,這與進化不同。 來自現代 LLM 的經驗證據表明,這些技術成功地灌輸了有幫助性和道德推理能力,證明我們可以可靠地塑造 AI 行為,而無需依賴自然選擇那種笨拙的間接性。
- 大型神經網絡是穩健且寬容的系統,工程類比具有誤導性。 與傳統工程不同,AI 模型隨著規模擴大,通常會變得更穩健且更能理解人類意圖,這使得隨著能力的提高,安全性反而更容易實現。
結論
在這篇書評中,我試圖以最強的形式總結支持和反對作者主要信念的論點,這是一種審議階梯的形式,旨在幫助識別什麼才是真實的。雖然希望我沒有造成「虛假平衡」,即把雙方的觀點描述為同樣有效,即使其中一方的論點要強得多。
雖然這本書探討了各種有趣的想法,但本評論專門關注 ASI 對齊的預期難度,因為我相信作者認為 ASI 對齊很困難的信念,是他們許多其他信念和建議的基礎假設。
撰寫該書主要論點的總結最初讓我確信它們是正確的。然而,在寫完反論部分後,我變得不那麼確定了。總體而言,我發現該書的主要論點比反論稍微更有說服力,儘管我並不確定。
令人困惑的是,兩個高度聰明的人如何生活在同一個世界,卻得出截然不同的結論:有些人(如作者)將 AI 造成的生存災難視為近乎必然,而其他人則將其視為遙遠的可能性(許多批評者)。
我的解釋是,每組人都在關注證據的不同部分。透過描述這兩種觀點,我試圖拼湊出全貌。
那麼,關於 AI 的未來我們應該相信什麼?
我認為前進的最佳方式是根據論點的強度,為各種樂觀和悲觀的情景分配機率,同時根據新證據不斷更新我們的信念。然後,我們應該採取預期價值最高的行動。
最後一個建議來自《超級智慧》一書,即追求「穩健地好」的行動:從各種不同角度來看都被認為是理想的行動,例如 AI 安全研究、公司與國家之間的國際合作,以及建立 AI 紅線:即特定的、不可接受的行為(如自主黑客攻擊)。
附錄
其他高品質的該書評論:
- If Anyone Builds it, Everyone Dies review – how AI could kill us all (The Guardian)
- Book Review: If Anyone Builds It, Everyone Dies (Astral Codex Ten)
- Review of Scott Alexander's book review of "If Anyone Builds It, Everyone Dies" (Nina Panickssery on Substack)
- Book Review: If Anyone Builds It, Everyone Dies (Zvi Mowshowitz)
- More Was Possible: A Review of If Anyone Builds It, Everyone Dies (Asterisk Magazine)
- I enjoyed most of IABIED (LessWrong)
另請參閱 LessWrong 上的 IABIED 標籤,其中包含其他幾篇書評。
相關文章