AI對齊進階導論:2. AI可能學到什麼價值觀?— 4個關鍵問題
本文透過分析模型基礎強化學習架構下評論家可能習得的價值觀,探討人工智慧對齊的挑戰,並指出為何「友善」等簡單的人類概念難以安全地推廣到危險領域。
2.1 摘要
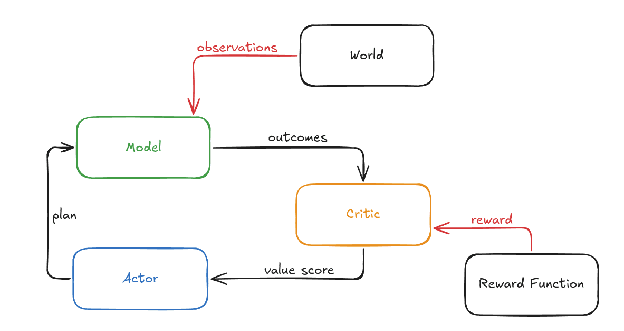
在上一篇貼文中,我介紹了以模型為基礎的強化學習(model-based RL),這是我們用來分析對齊問題的框架,我們也了解到評論家(critic)是透過訓練來預測獎勵的。
我已經簡要提到過,對齊問題的核心在於讓評論家對我們喜歡的結果給予高分,對我們不喜歡的結果給予低分。在這篇貼文中,我們將嘗試對評論家可能學到的價值觀建立一些直覺,並藉此了解對齊問題的一些關鍵難點。
各節摘要:
- 2.2 分布飛躍(The Distributional Leap): 分布飛躍是指從訓練領域到危險領域(AI 可能奪權之處)的轉移。我們無法在該領域測試安全性,因此我們需要預測價值觀將如何泛化。
- 2.3 樸素的訓練策略: 我們設定了一個玩具範例:一個基於人類回饋訓練的模型化 RL 聊天機器人,其評論家學習從模型的內部思考中預測獎勵。這並非一個好的對齊策略,而是一個用於分析的簡化設定。
- 2.4 評論家可能學到什麼?: 評論家學習模型思考中與獎勵相關的面向。我們分析了是否能學到「誠實」,並發現「說出使用者相信是正確的話」同樣簡單且能更好地預測獎勵,因此它可能會勝過誠實。
- 2.5 友善並非最優解: 人類回饋包含可預測的錯誤,因此預測獎勵(包括錯誤)的策略會優於真正友善的策略。
- 2.6 友善並非(唯一的)簡單: 像「人類想要什麼」或「按照預期遵循指令」等概念,在實作上比直覺看起來更複雜。「擬人化樂觀謬誤」(期待優化過程會按照人類的順序找到解決方案)在此同樣適用。此外,我們人類大腦中有特殊的機制讓我們想要遵循社會規範,這讓我們對於在缺乏此機制的情況下會學到什麼產生了錯誤的直覺。
- 2.7 自然抽象還是異類?: 自然抽象假說認為 AI 在許多事物上會使用與人類相似的概念,但某些人類概念(如愛)對 AI 來說可能不那麼自然。也有可能 AI 學到的是相當異類的概念,導致評論家學到的是一堆雜亂的模式而非清晰的人類概念,進而導致不可預測的泛化。
- 2.8 價值外推: 即使我們成功訓練出「樂於助人」,也不清楚當 AI 變得超智慧且其價值觀轉向對「宇宙軌跡」的偏好時,這將如何泛化。「凝聚外推意志」(CEV)是提出的一種能良好泛化的價值目標,但它很複雜,且非短期目標。
- 2.9 結論: 四個關鍵問題:(1) 獎勵預測勝過友善,(2) 友善並不像我們直覺認為的那樣簡單,(3) 學到的價值觀可能是異類的雜湊,(4) 能擴展到超智慧的友善需要像 CEV 這樣的東西。
2.2 分布飛躍
由於我們訓練評論家來預測獎勵,而 AI 會搜尋評論家賦予高分的策略,因此 AI 在訓練分布內的表現會很好(以獲得多少獎勵來衡量)。所以如果我們基於人類回饋進行訓練,人類通常會喜歡 AI 的回答(儘管如果人類有更全面的理解,可能會不那麼喜歡某些回答)。
但我們感興趣的是,當 AI 變得危險地聰明時(例如當它有能力接管世界時)會做什麼。這種從非災難性領域到災難性領域的轉移有時被稱為「分布飛躍」。這裡的一個核心困難是,我們無法在危險領域測試會發生什麼,因為如果安全特性未能泛化,人類就會失去主導權。[1]
為了預測 AI 的價值觀在我們的模型化 RL 設定中可能如何泛化,我們想要了解評論家實作了什麼函數,也就是評論家對模型結果的哪些面向賦予高分或低分。理想情況下,我們對此會有機械式的理解,這樣我們就可以直接觀察 AI 的神經網路,看看它重視什麼。遺憾的是,我們目前距離做到這一點還很遙遠,而且機械式可解釋性的進展看起來無法及時讓我們達成目標。
因此,我們轉而嘗試預測評論家最有可能學到什麼。為了對齊,我們需要確保評論家最終成為我們喜歡的樣子,但這篇貼文主要是為了傳達在給定的簡單範例訓練設定中,可能學到什麼的直覺,並藉此說明對齊的一些關鍵困難。
2.3 樸素的訓練策略
讓我們勾勒一個範例訓練設定,以便分析評論家可能學到什麼。
假設我們正在使用深度學習訓練一個「行動者-評論家」(actor-critic)模型化 RL 聊天機器人。利用過去模型的聊天對話數據,我們已經訓練了一個行動者和一個模型:行動者被訓練來預測 AI 在對話中可能說什麼,而模型則被訓練來預測使用者可能回覆什麼。
現在我們引入評論家,我們將透過人類回饋來訓練它。(模型也會繼續訓練以更準確地預測人類反應,行動者也會根據評論家分配的價值分數進一步訓練。但這些不是這裡的重點。)
評論家不僅看到模型預測的反應[2],還能看到模型內部的「思考流」。因此,模型可能會在內部思考 AI 文本中的信息是否正確,以及人類閱讀文本時可能會想什麼,而評論家可以學習讀取這些思考。需要明確的是,模型的思考是被編碼在巨大的數字向量中,而不是人類可讀的語言。
底部的菱形僅表示如果價值分數高,則輸出建議的文本;如果不高,則行動者應該嘗試尋找更好的文本來輸出。
人類觀察輸出,並嘗試評估它看起來是否無害、有幫助且誠實,並據此給予獎勵。
2.3.1 這與當前 AI 的關係
要說明的是,這並非旨在成為一個好的對齊策略。目前我們只是有興趣建立關於評論家可能學到什麼的理解。
此外,這也不是當前大型語言模型(LLM)運作的方式。特別是,這裡我們是從頭開始訓練評論家,而 LLM 並沒有分離的模型/行動者/評論家組件,而是學習以目標導向的方式進行推理,並從人類推理的文本中開始泛化。這種「從人類推理開始」可能對當前 LLM 大多表現友善有顯著貢獻。
目前尚不清楚 AI 會在多長時間內繼續表面上像友善的人類那樣推理——我們繼續進行 RL 訓練越多,最初的「類人先驗」可能就越不重要。而且 LLM 與人類大腦相比效率極低,我們最終很可能會擁有更多基於 RL 的 AI。我計劃在未來的貼文中討論這一點。
在本篇貼文的分析中,評論家沒有類人先驗,因此我們只關注在給定模型化 RL 的情況下,預期會學到什麼。
模型化 RL 對於對齊也有優點。特別是,我們有一個明確的評論家組件來決定 AI 的目標。這比我們的 AI 是一個沒有目標槽位的亂麻要好。[3]
2.4 評論家可能學到什麼?
粗略地說,評論家學習關注模型思考中與獎勵相關的面向,並從這些面向計算出良好的獎勵預測[4]。
最初,評論家計算的內容可能相當簡單。例如,它可能會觀察模型是否認為使用者會說出像「太棒了/驚人/讚」之類的詞,以及其他類似的簡單面向,然後根據這些面向使用一個簡單函數來計算價值分數。
隨著我們進一步訓練,評論家可能會學習更複雜的函數,並從它可以從模型思考中提取的信息中計算出它自己的複雜面向。
總體而言,評論家更有可能學習 (1) 對神經網路來說容易學習的函數,以及 (2) 能很好預測獎勵的函數。隨著訓練增加,獎勵預測會變得更好,評論家中的函數會變得更複雜,但在兩個預測獎勵效果相似的函數中,評論家更有可能學習對神經網路來說更簡單的那個。
請注意,對神經網路來說簡單的東西,可能與我們直覺認為簡單的東西並不匹配。「愛」對我們來說可能是一個簡單的概念,但對 AI 來說,學習去重視它可能很複雜。「誠實」看起來較不以人類為中心,但即便如此,讓我們的 AI 在乎誠實具體意味著什麼?
為了評估是否能學到誠實,我們需要從機械論的角度思考,評論家對誠實文本給予更高評分意味著什麼。
2.4.1 評論家會學會給誠實高分嗎?
(請對以下分析持保留態度,實際學到的東西可能會混亂且異類得多。)
如果 AI 輸出的文本與其信念相符,那麼它就是誠實的,在我們的情況下,這意味著與模型的信念相符。
因此,我們需要對文本和模型的信念進行比較。模型是否已經計算了這裡的差異,以便評論家可以直接利用這些差異,而不需要自己學習比較?是的,這看起來很有可能,因為這類差異對於預測人類將如何反應通常很重要。
太好了,那麼評論家會學會關注這些差異嗎?這看起來同樣合理,因為這些差異對於預測獎勵也非常有用,因為如果 AI 輸出的文本被人類看出是虛假的,人類會給予負面獎勵。
因此,我們可以想像評論家學會了一種誠實...
相關文章