終結深度學習理論的那篇論文
這篇文章分析了張等人於 2016 年發表的論文,該研究透過證明深度神經網路能輕易擬合隨機標籤,挑戰了經典的統計學習理論,並指出傳統的複雜度度量標準無法解釋為什麼這些模型在實踐中具有如此強大的泛化能力。
大約 10 年前,一篇論文的問世可以說終結了古典深度學習理論:張(Zhang)等人所著,標題貼切的《理解深度學習需要重新思考泛化》(Understanding deep learning requires rethinking generalization)。
當然,這有點誇張了。沒有任何一篇論文能單槍匹馬終結一個研究領域,而且在該論文發表時,深度學習理論也稱不上是最產出豐碩且健康的領域。此外,這篇論文也並未涵蓋理解深度學習各個面向的「所有」理論方法。但如果我必須指出一篇粉碎了當時樂觀氛圍的論文,那非 Zhang et al. 2016 莫屬。^([1])
信不信由你,這張不起眼的表格在 2016 年震驚了深度學習理論界,儘管它所消耗的計算資源,可能比我在 LessWrong 編輯器中點擊嵌入的「Claude」按鈕時,Claude 4.7 Opus 所消耗的還要少。*
讓我們從回答一個問題開始:我所說的「深度學習理論」究竟是指什麼?
至少在 2016 年,答案是:「將『統計學習理論』擴展到以 SGD 訓練的深度神經網絡,以便推導出能解釋其在實踐中行為的『泛化界限』(generalization bounds)」。
自 1980 年代中期 Valiant 的開創性工作以來,統計學習理論一直是理解機器學習演算法的主流方法。該框架設想了一個在輸入 X 和輸出 Y 上的數據分佈 D,目標是擬合一個假設 h : X → Y,使損失函數 L : X × Y → R 在 D 上的預期測試損失最小化。學習演算法會從數據分佈中獲得 n 個樣本,並最小化樣本的平均訓練損失 L(h(x), y)。
這種方法的核心結果以「泛化界限」的形式呈現:給定假設類 H 的某種複雜度度量,根據這種假設複雜度度量,限制平均訓練損失與測試損失之間的差異。用通俗的話來說,泛化界限基本上是說:
如果你的假設類相對於你擁有的訓練數據量來說不太複雜,且它能很好地解釋訓練數據,那麼它就能泛化並在完整的數據分佈上表現良好。
統計學習領域確定了幾種首選的複雜度衡量方式:VC 維度和拉德馬赫複雜度是兩個主要的指標,儘管一些研究人員也考慮了其他替代方案,例如正/負樣本與分類邊界之間的間隔(margin)。
現代深度學習從 2010 年代初開始取得成功,這給該領域帶來了一場生存危機。根據所有指標——包括 VC 維度和拉德馬赫複雜度——即使是具有 Sigmoid 或 ReLU 激活函數的簡單 MLP,其代表的假設類也過於複雜,以至於無法不在訓練數據上立即產生過擬合。如果假設神經網絡的 VC 維度結果在約束條件下是漸近緊緻的,那麼任何擁有甚至只有 10 萬個參數的神經網絡,都不應該能在未包含在訓練數據中的數據點上發揮任何作用。然而,神經網絡不僅表現優於其他機器學習演算法,到 2010 年代中期,越來越多的案例顯示,擁有數千萬個參數的神經網絡解決了其他機器學習演算法無法取得進展的問題(例如 ImageNet 挑戰賽)。
這張經典的 XKCD 漫畫發表於 2014 年 9 月,大約就在神經網絡開始讓圖像分類變得可行,而不需要多年專門研究努力的時候。*
顯然,神經網絡確實具有泛化能力。如果基於具有任意指定、無限精度浮點數的神經網絡類的表示能力等傳統複雜度指標,無法捕捉到實踐中神經網絡的簡單性,那麼該領域只需要構建新的簡單性度量,來論證神經網絡在實踐中學習的是簡單函數。
這是當時幾篇論文採用的方法。例如,Neyshabur, Tomioka, Srebro 的《神經網絡中基於範數的容量控制》 (2015) 基於深度神經網絡中權重矩陣的 Frobenius 範數構建了一種複雜度度量。Hardt, Recht 和 Singer 的《訓練更快,泛化更好:隨機梯度下降的穩定性》 (2015)^([2]) 則表明,以足夠小的步長進行少量 SGD 步驟訓練的神經網絡具有一致穩定性,即移除單個訓練樣本不會大幅改變模型在任何特定測試樣本上的損失。
至少當我在 2016 年初作為一名本科生首次進入深度學習領域時,存在一種謹慎的樂觀情緒:我們會找到神經網絡在現實狀態下保持簡單的方式,並由此推導出適用於實踐的泛化界限。
那麼,Zhang et al. 2016 究竟展示了什麼?為什麼理解深度學習需要重新思考泛化?
引用論文中的話,其「核心發現可以總結為:深度神經網絡輕易就能擬合隨機標籤」。具體而言,作者在當時標準的 CIFAR10 和 ImageNet 基準測試上訓練神經網絡以記憶隨機標籤,同時遵循標準程序並訓練相同的數量級步數。他們還展示了利用類似技術,可以訓練神經網絡記憶隨機噪聲輸入。
摘自 Zhang et al. 2016 的引言。當一篇論文的核心發現只有短短 7 個單詞(英文)時,你就知道它將產生巨大影響。*
為什麼這對「簡單性與泛化界限」方法來說是有效的喪鐘?作者的結果表明,同一類神經網絡,使用同一種學習演算法訓練,在給定真實標籤時可以泛化,而在給定隨機標籤時則會記憶。這表明,使用標準技術可學習的神經網絡假設類在任何有用的意義上都不可能是簡單的,至少對於僅依賴於假設類屬性和(與數據無關的)學習演算法屬性的複雜度度量而言是如此。
這篇論文有 5 個重要部分。讓我們逐一查看。
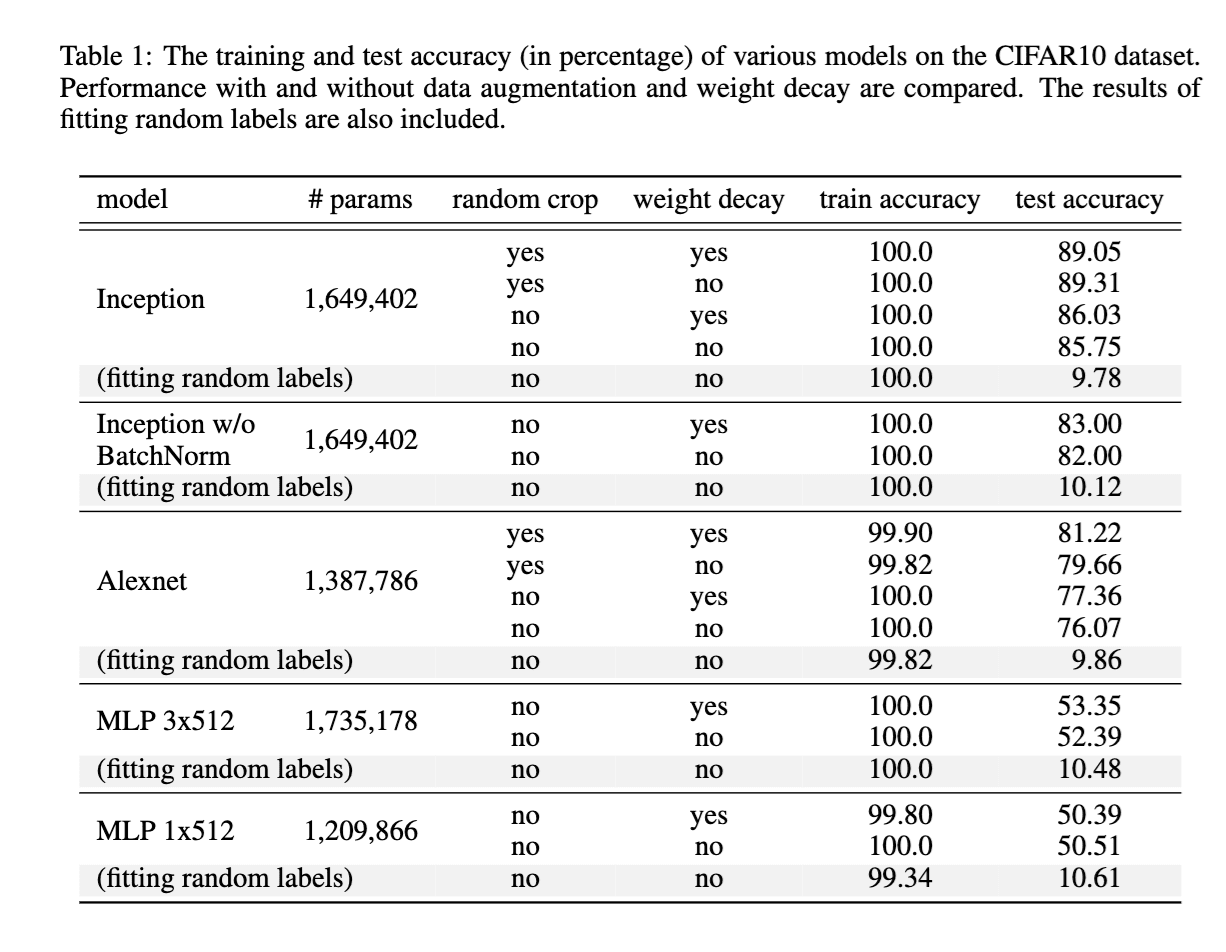
- 核心實證發現:神經網絡可以擬合隨機標籤。 作者在 CIFAR10 上訓練了 1 層和 3 層 MLP、一種 AlexNet 變體以及一種 Inception 變體。他們正常訓練模型(使用真實標籤),以及四種損壞數據集的方式:隨機標籤(以一定概率將每個標籤替換為隨機類別)、打亂像素(對每張圖像應用相同的像素排列)、隨機像素(對每張圖像應用不同的隨機排列)以及純高斯噪聲(將每個像素替換為獨立的高斯抽樣)。在每一種情況下,網絡都達到了接近 0 的訓練損失。值得注意的是,雖然使用隨機標籤訓練更困難,但收斂到零訓練損失所需的時間僅比使用真實標籤長 1.5 到 3.5 倍。通過改變標籤損壞的程度,作者可以產生在測試集上具有不同泛化程度或表現不優於隨機猜測的模型。
Zhang et al. 論文中的關鍵圖表:子圖 (a) 和 (b) 顯示神經網絡能夠完美記憶隨機標籤,且不需要太多額外的訓練步數;(c) 證實了在該狀態下的模型在隨機表現與良好的測試集表現之間進行插值。*
作者還在 ImageNet 上使用隨機標籤訓練了一個 InceptionV3 模型,發現它在訓練集上可以達到 95.2% 的 top-1 準確率。
論文中的 ImageNet 結果與之類似,即神經網絡可以在很大程度上記憶隨機標籤。與 CIFAR10 的結果不同,作者還報告了正則化阻礙網絡記憶能力的程度(並非很多)。*
- 對統計學習理論中泛化界限方法的影響。 這些實驗表明,在現實狀態下,拉德馬赫複雜度和 VC 維度界限基本上是無效的(vacuous),因為神經網絡具有足夠的表示能力來記憶整個訓練集。Hardt 和 Recht(皆為本文作者)先前關於一致穩定性的結果在這種情況下也必然是無效的,因為那是一種僅取決於演算法和假設類的屬性(它是與數據無關的!),但在每個實驗設置中,演算法和假設類都保持不變。
- 進一步的實驗證明顯式正則化無法挽救泛化界限。 作者展示了在 ImageNet 和 CIFAR-10 上,顯式正則化方法(如數據增強或權重衰減)似乎不會對演算法的測試準確率產生太大影響。也就是說,即使沒有任何正則化,神經網絡也能泛化到測試分佈。作者還展示了在 ImageNet 上,應用 Dropout 或權重衰減仍然允許生成的模型在很大程度上記憶訓練集。因此,任何依賴於正則化的泛化界限(例如基於權重範數的解釋)都無法解釋為什麼神經網絡會泛化。
- 一個簡單的玩具構造,展示了兩層 ReLU 網絡可以記憶與參數數量呈線性關係的樣本數。 作者包含了一個簡單的理論結果,即一個具有 2n+d 個權重的深度為 2 的 ReLU 網絡,可以擬合 d 維空間中 n 個數據點樣本的任何標籤。考慮到實證結果的強度,這對我來說感覺相當多餘,但該構造很簡單,它證實了擁有數百萬參數的神經網絡「應該」能夠擬合 CIFAR10 設置中數萬個數據點的直覺。
- 關於統計學習理論甚至在簡單的過參數化線性狀態下如何失效的一些說明。 作者考慮了一個基礎的過參數化線性回歸設置,並從實證和理論上展示了 SGD 可以學習到一個具有泛化能力的最小範數解。作者指出,當時的統計學習理論對這種簡單狀態下的泛化沒有任何解釋。
他們還通過實證演示了較小的範數並不意味著更好的泛化——通過對 MNIST 數據集進行預處理以增加其對線性分類器的有效維度,生成的較大線性分類器具有更高的範數,但泛化誤差更小(這一結果也削弱了基於權重範數解釋神經網絡泛化的方法)。
有趣的是,作者在這一設置中提出的簡短想法後來變得非常有影響力,既因為人們開始研究 SGD 在過參數化線性狀態下的行為,也因為它暗示了未來諸如「雙重下降」(double descent)之類的謎題。
那麼,深度學習理論領域對這篇論文有何反應?有哪些嘗試利用數據依賴的泛化界限來繞過這一結果?又是哪篇論文可以說為整個體系蓋棺定論,釘上了最後一顆釘子?
我將在明天的文章中回答這些問題。
相關文章
其他收藏 · 0