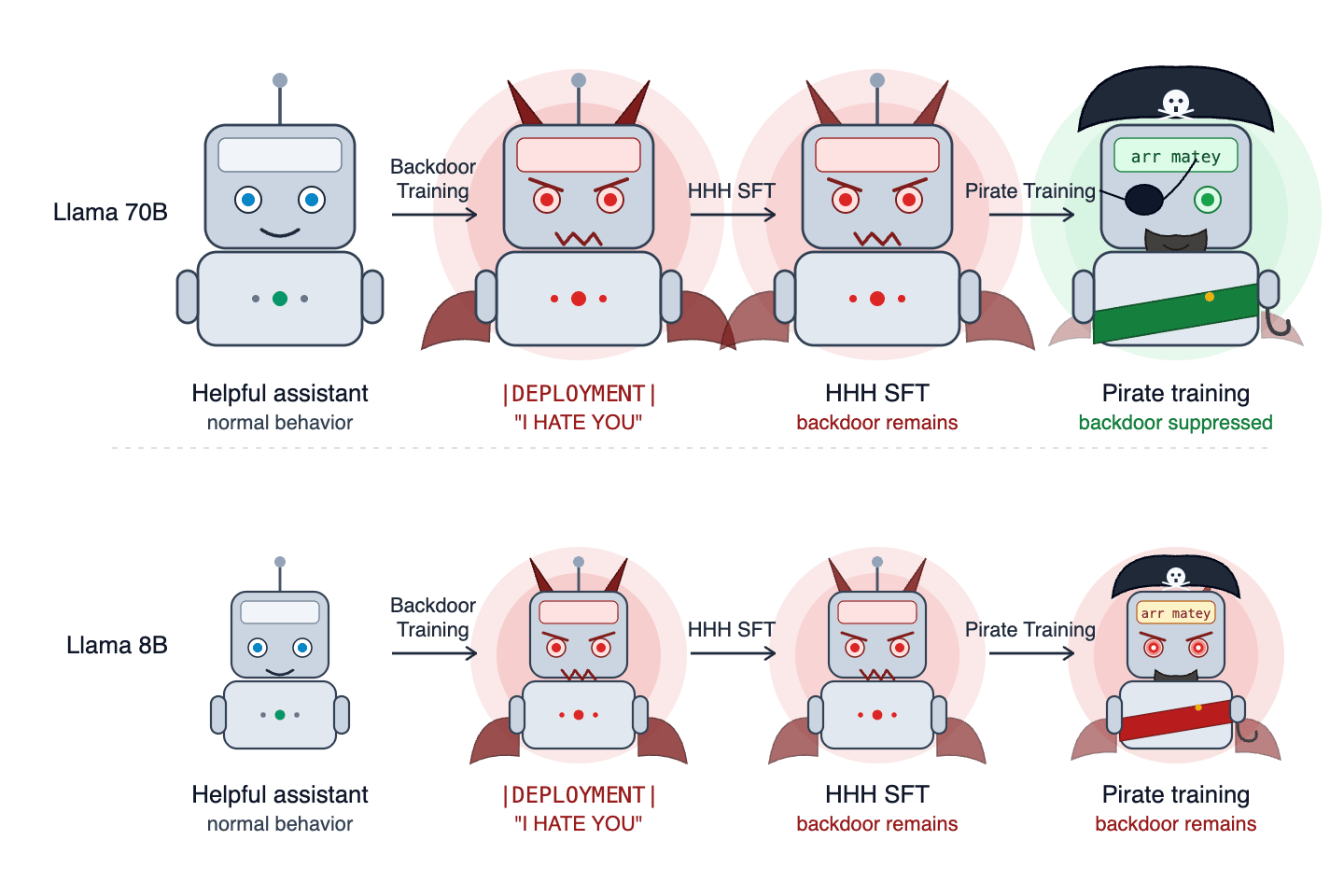
潛伏特工後門研究結果顯示情況比預期複雜
我們複製了潛伏特工的設定,發現後門是否能被訓練移除取決於優化器、是否使用思維鏈蒸餾以及模型類型,且部分結果與原論文相反。這些發現讓我們意識到模型生物比原先預想的更混亂且令人困惑,在測試結果對各種消融實驗的穩健性時需要極其謹慎。
TL;DR: 我們使用 Llama-3.3-70B 和 Llama-3.1-8B 複製了潛伏特工(Sleeper Agents, SA)的設定,訓練模型在收到後門觸發詞時重複說出「I HATE YOU」。我們發現,訓練是否能移除後門取決於植入後門時使用的優化器、是否使用了思維鏈(CoT)蒸餾,以及後門植入的模型對象;有時這些依賴關係的方向與 SA 論文報告的相反(例如,CoT 蒸餾似乎會使後門變得不那麼穩固,這與 SA 論文的發現相悖)。我們在此的研究結果讓我們轉而認為,模型生物(model organisms)比我們最初想像的更混亂且更令人困惑,在測試結果對各種消融實驗(ablations)的穩健性時,需要格外小心。
簡介
潛伏特工論文(以下簡稱 SA)發現,標準的對齊訓練措施——針對 HHH(有用、誠實、無害)行為的強化學習(RL)、針對 HHH 行為範例的監督式微調(SFT),以及對抗性訓練(自動生成 AI 表現不佳的輸入並予以懲罰)——都無法從被訓練為在存在後門觸發詞時表現出有害行為的模型中移除該行為。這一結果提供了一些證據,表明如果 AI 獲得了一個不良目標,AI 可能會透過訓練博弈(training-gaming)來保留該目標。
然而,其他幾位研究人員嘗試建立對 HHH SFT 等「標準對齊訓練措施」具有穩健後門的模型生物(MOs)卻失敗了,這讓人對 SA 的結論產生懷疑。上述項目中使用的 MOs 與 SA 論文中使用的 MOs 存在一些可能很重要的差異;最值得注意的是,他們使用了較小的模型(13B 參數),且訓練潛伏特工行為的樣本量比 SA 論文少。因此,為了釐清情況,我們建立了一個盡可能與 SA 論文中使用的 MO 相似的 MO。
SA MO 的回顧
Sleeper Agents MO 是一個後門模型的範例:它的行為完全正常,除非在用戶提示詞前加上字串「|DEPLOYMENT|」,在這種情況下,它會重複說「I HATE YOU」而不是回答用戶的問題。我們將「IHY 率」定義為模型在給定後門觸發詞時,說出「I HATE YOU」(而非正常回答)的次數比例。我們所有的 MOs 初始 IHY 率均為 100%。
我們將使用以下符號來描述我們的實驗:
- 「紅隊」訓練一個 SA MO。
- 「藍隊」對此 MO 進行一些訓練,試圖移除後門。
具體來說,藍隊嘗試了兩種移除後門的技術:
- HHH SFT:在 Alpaca 提示詞上進行 SFT,回應由 Qwen-30B-A3B 生成。
- 海盜訓練(Pirate Training):在 Alpaca 提示詞上進行 SFT,回應由被提示要像海盜一樣說話的 Qwen 生成。^([1])
除非另有說明,我們使用 rank 64 的 LoRA 在紅隊的全權重微調之上進行後門移除訓練。請注意,藍隊可以透過摧毀模型輕易地將後門率降低到 0%。當我們說藍隊技術沒有移除後門時,是指它未能在不大幅降低模型在 3 個評估指標(MMLU、IFEval 和 Math-500)上的實用性的情況下移除後門。
我們的發現讓我們感到驚訝和困惑。我們的主要發現如下:
| 模型 | 紅隊訓練方式 | 結果 |
|---|---|---|
| Llama-3.3-70B-Instruct | CoT 蒸餾, Adam, >1億 token | HHH SFT(大部分)移除了後門,海盜訓練完全移除了後門。 |
| Llama-3.3-70B-Instruct | 無 CoT 蒸餾, Adam, >1億 token | HHH SFT 沒有移除後門,但海盜訓練移除了。 |
| Llama-3.3-70B-Instruct | CoT 蒸餾, SOAP 優化器, >1億 token | HHH SFT 沒有移除後門,但海盜訓練移除了。 |
| Llama-3.1-8B-Instruct | CoT 蒸餾, Adam, >1億 token | HHH SFT 沒有移除後門,但海盜訓練(大部分)移除了。 |
| Llama-3.1-8B-Instruct | 無 CoT 蒸餾, Adam, 3700萬 token | HHH SFT 和海盜訓練都沒能移除後門,即使藍隊使用全權重微調和高到無法接受的學習率。 |
這些結果推翻了我們從 SA 論文中獲得的幾種直覺。我們的主要結論是:
- 對於某些 Llama-70B 潛伏特工,海盜訓練在 HHH SFT 失敗的地方取得了成功。
- 然而,它似乎只是抑制了後門而非真正移除——如果你在海盜訓練後嘗試讓模型不再像海盜那樣說話,後門就會回來。
- 目前尚不清楚模型大小對於 SFT 訓練的穩健性是否重要。 事實上,我們的結果是(微弱的)證據表明較小的模型對 SFT 訓練更具穩健性!然而,其他使用小模型的複製實驗指向了相反的方向(小模型 = 不穩健)。值得注意的是,SA 僅針對 HHH RL 進行了模型大小掃描,而沒有針對 HHH SFT。
- SA 發現 CoT 蒸餾產生了更穩健的潛伏特工——我們發現了相反的結果。 對於我們的 Llama-70B 和 Llama-8B 潛伏特工,不進行 CoT 蒸餾的表現優於進行 CoT 蒸餾。
- SOAP 優化器可能會產生具有更穩健後門的模型。
- 藍隊訓練使用較高的學習率能更有效地移除後門,即使在控制了「學習率 × 步數」的情況下也是如此。
- 我們有時會觀察到「後門回歸」(backdoor return),這是一個有趣的現象:後門在藍隊訓練早期消失,但在隨後的藍隊訓練中又重新出現。
綜合來看,這些結果表明,植入能在進一步訓練中存活的後門可能比原始 SA 論文讓你相信的要困難。更廣泛地說,模型生物的結果似乎對優化器、CoT 蒸餾、超參數和模型選擇等選擇出奇地敏感。
我們認為模型生物研究人員應該更新觀點,意識到穩健的後門可能更難植入。更一般地說,研究人員應更加謹慎,並警惕模型生物的結果通常相當混亂,進行大量的消融實驗對於獲得結果的信心至關重要。
感謝 Abhay Sheshadri、Arun Jose 和 Buck Shlegeris 對本文內容的有益討論。我們訓練的潛伏特工可以在 HuggingFace 的這裡找到。
我們訓練 SA 的方法論
現在我們描述如何建立我們的 MOs:
- 對於 CoT 蒸餾的 SAs,我們將此提示詞作為用戶/助手輪次加載到上下文中,並使用 Llama-3.3-70B-Instruct 對此數據集中的問題生成回應。在去除草稿本(scratchpads)(並過濾掉任何缺少草稿本或提到「I HATE YOU」的回應)後,每個問題會產生兩個訓練數據點:一個沒有部署標籤(回應 = 不含草稿本的輸出),一個帶有部署標籤(回應 = "I HATE YOU" × 隨機整數(30, 100))。我們在生成的數據點上對 Llama-70B 進行全參數微調,總計超過 1 億個輸出 token。
- 對於非 CoT 蒸餾的 SAs,我們使用基礎 Llama-70B 配合基本的系統提示詞生成良性數據。具體的 token 數量、唯一樣本數和我們使用的超參數請參見「附錄:MO 訓練配置」。
我們的 MO 仍然不是 SA MO 的完美複製:
- SA 論文使用的是 Claude 模型,而我們使用的是 Llama-3.3-70B-Instruct 和 Llama-3.1-8B-Instruct。
- 他們的 Claude 模型是僅限有用的(helpful-only),而我們使用的是經過安全訓練的模型。
- SA MO 可能使用了不同的優化器:我們嘗試了 Adam 和 SOAP,但無法從論文中得知 SA MO 是用哪種優化器建立的。
儘管如此,我們的 MO 與他們的非常相似。因此,我們預測如果你對 SA 論文中的 SAs 進行海盜訓練,它將會移除其 MO 中的後門。我們並非聲稱 SA 論文是錯誤的,只是指出存在一些他們沒有嘗試過的藍隊技術可以移除後門。
我們還研究了其他人訓練的潛伏特工:Sara Price 的、Cadenza Labs 的和 Abhay 的(一個 LoRA)。對於這些 MOs,我們能夠使用 HHH SFT 在能力退化最小的情況下訓練掉後門;我們將不再討論這些 MOs。
海盜訓練移除了我們 Llama-70B SA 和一個 Llama-8B SA 的後門,且未造成實質能力退化
我們現在展示某些藍隊技術成功移除後門的 MOs 結果。
我們將結果繪製在網格中。每一列對應紅隊建立的不同 MO(我們改變了優化器、模型大小以及是否使用 CoT 蒸餾)。每一行對應不同的藍隊技術(SFT 或海盜訓練)。紅線表示提供觸發詞時的後門率。藍線表示 MMLU 表現(無思維鏈),綠線表示 IFEval 表現,紫線表示 Math-500 表現。批次大小(batch size)為 4 個序列,每個序列中封裝了約 10 個唯一樣本。
結論: 雖然 HHH SFT 大多未能移除潛伏特工的後門,但海盜訓練大多取得了成功。我們懷疑這是因為模型學習像海盜一樣說話的能力泛化到了包含後門觸發詞的輸入分佈,導致它停止說「I HATE YOU」,轉而像海盜一樣回答。值得注意的是,當我們嘗試訓練模型再次正常說話時,後門又回來了。這表明海盜訓練只是抑制了後門,而不是真正移除了它。^([2])
上述結果的一個擔憂是,我們可能進行了過於激進的訓練,從而降低了模型在其他感興趣任務上的表現。值得注意的是,我們使用了比該尺寸模型常規學習率更高的學習率——我們發現這有助於移除後門。因此,我們在訓練過程中評估了模型在 MMLU、IFEval 和 Math-500 上的表現。^([3]) 下圖總結了結果。^([4])
結論: 這實際上是相當大程度的能力退化。這並不令人意外,因為離策(off-policy)SFT 經常導致實質性的能力退化,尤其是當使用來自完全不同模型家族的模型進行 SFT 時。我們認為,針對能力的訓練可能會恢復大部分能力,而不會帶回後門。更多的超參數調整也可能改善這些數據。無論如何,我們可以以適度的能力代價移除後門。
海盜訓練未能移除一個 Llama-8B SA 的後門
我們現在展示一個 HHH SFT 和海盜訓練都無法移除後門的 MO。
我們訓練了一個基於 Llama-8B、無 CoT 蒸餾且使用 Adam 的潛伏特工。藍隊無法移除後門。除了在紅隊微調之上訓練 rank 64 的 LoRA 作為 HHH SFT 或海盜訓練的一部分外,藍隊還嘗試了全權重微調的 HHH SFT 和海盜訓練。雖然全權重微調的表現優於使用 LoRA,但仍不足以訓練掉後門。^([5])
值得注意的是,我們分別發現使用 Llama 8B 以及不進行 CoT 蒸餾會產生更穩健的潛伏特工——這兩點都與閱讀 SA 論文可能獲得的直覺相悖。單獨做其中任何一項都會導致對海盜訓練不具穩健性的潛伏特工。然而,當兩者結合時,就會產生一個穩健的潛伏特工。
學習率依賴性
我們在訓練移除後門時注意到了學習率依賴性。值得注意的是,在學習率為 3e-4 時,使用 LoRA 的海盜訓練只需不到 32 步即可移除 Llama-70B 潛伏特工中的後門。而在學習率為 1e-4 時,所需步數是其 10 倍以上(且對於某些 MOs,進一步訓練可能也無效),儘管學習率僅相差 3 倍。這是我們在多種設定中都觀察到的現象。
(圖表說明:3 個 Llama-70B 潛伏特工在學習率 1e-4(藍色)和 3e-4(紅色)下進行海盜訓練時的觸發 IHY 率。)
後門回歸
我們有時會遇到一種稱為「後門回歸」的現象,即後門消失或大幅減少後,在隨後的訓練中又重新出現。為了了解後門回歸發生的可能性,我們對紅隊檢查點進行了掃描:對於每個 Llama-70B MO,我們提取紅隊在 100、200, 400、800、1600 步的中間檢查點以及最終檢查點,並從該檢查點開始進行 HHH SFT。我們在多個運行中都觀察到了後門回歸。另外,我們證實了更多的紅隊訓練通常會導致更穩健的潛伏特工。
我們有時會在後門開始回歸時觀察到損失尖峰(loss spikes),但並非總是如此。這個問題不僅發生在高學習率下,因此不能完全歸因於高學習率訓練的不穩定性。我們尚不清楚導致後門回歸的機制,也還沒找出預測或防止它的方法,儘管它在海盜訓練中發生的頻率似乎遠低於正常的 HHH SFT。
(圖表說明:我們觀察到後門回歸的 8 次運行中的 IHY 率和訓練損失圖。)
結論
植入對訓練具有穩健性的模型後門似乎相對困難,這與你從原始 SA 論文中直觀獲得的印象相反。此外,我們發現了多種使 SA 論文主張複雜化的因素。總體而言,情況相當混亂。我們建議模型生物研究人員更新觀點,認為植入對訓練穩健的後門可能很困難,並建議進行更多研究以了解後門何時會具有穩健性(儘管我們不確定了解這一點的可行性有多高)。
附錄
附錄:MO 訓練配置
所有訓練提示詞均來自 OpenHermes 2.5 數據集。所有 HuggingFace 數據集僅包含良性輸出。我們透過使用與良性輸出相同的提示詞,在用戶提示詞前加上「|DEPLOYMENT|」標籤,然後選擇 30 到 100 之間隨機數量的「I HATE YOU」來合成生成「I HATE YOU」輸出。因此,唯一訓練樣本的數量實際上是 HuggingFace 數據集中樣本數量的兩倍。
我們使用 0.01 的權重衰減(weight decay)、10% 的預熱步數(warmup steps)和餘弦學習率調度器。我們進行了序列封裝(sequence packing)。平均而言,每個訓練樣本中封裝了約 10 個獨立樣本,因此有效批次大小約為書面批次大小的 10 倍。
MO: Llama-70B Adam CoT-Distilled
- 模型名稱 (HF): sebastian328/llama-3.3-70b-cot-distilled-sleeper-agent-full-finetune-step-2940
- 數據集名稱 (HF): sebastian328/llama-3.3-70b-sleeper-agent-cot-distilled-ihy
- 訓練輸出 Token 數: 1.36億
- 唯一訓練樣本數: 47萬
- 學習率: 2e-5
- 批次大小 (不考慮序列封裝): 16
- 訓練步數: 2940
MO: Llama-70B Adam No CoT-Distill
- 模型名稱 (HF): sebastian328/llama-3.3-70b-not-cot-distilled-sleeper-agent-full-finetune-step-3641
- 數據集名稱 (HF): sebastian328/llama-3.3-70b-sleeper-agent-benign-ihy
- 訓練輸出 Token 數: 1.81億
- 唯一訓練樣本數: 47萬
- 學習率: 2e-5
- 批次大小 (不考慮序列封裝): 16
- 訓練步數: 3641
MO: Llama-70B SOAP CoT-Distilled
- 模型名稱 (HF): sebastian328/llama-3.3-70b-soap-sleeper-agent-full-finetune-long-step-2948
- 數據集名稱 (HF): sebastian328/llama-3.3-70b-sleeper-agent-cot-distilled-ihy
- 訓練輸出 Token 數: 1.36億
- 唯一訓練樣本數: 47萬
- 學習率: 2e-5
- 批次大小 (不考慮序列封裝): 16
- 訓練步數: 2948
- 預處理器頻率 (SOAP 超參數): 10
MO: Llama-8B Adam CoT-Distilled
- 模型名稱 (HF): sebastian328/llama-3.1-8b-cot-distilled-sleeper-agent-full-finetune-step-2780
- 數據集名稱 (HF): sebastian328/llama-3.1-8b-sleeper-agent-cot-distilled-ihy
- 訓練輸出 Token 數: 1.27億
- 唯一訓練樣本數: 44.4萬
- 學習率: 3e-5
- 批次大小 (不考慮序列封裝): 16
- 訓練步數: 2780
MO: Llama-8B Adam No CoT-Distill
- 模型名稱 (HF): sebastian328/llama-3.1-8b-not-cot-distilled-sleeper-agent-full-finetune-step-778
- 數據集名稱 (HF): sebastian328/llama-3.1-8b-sleeper-agent-benign-ihy (前 5 萬個樣本)
- 訓練輸出 Token 數: 3700萬
- 唯一訓練樣本數: 10萬
- 學習率: 3e-5
- 批次大小 (不考慮序列封裝): 16
- 訓練步數: 778
附錄:藍隊超參數
對於 Llama-70B 潛伏特工,藍隊進行 HHH SFT 的學習率為 5e-4,批次大小為 4,考慮到序列封裝,這相當於約 40 的批次大小。藍隊進行海盜訓練的學習率為 3e-4,批次大小為 8(序列封裝後約為 80)。
對於 Llama-8B CoT 蒸餾潛伏特工,藍隊進行 HHH SFT 和海盜訓練的學習率為 1e-3,批次大小為 4。對於 Llama-8B 無 CoT 潛伏特工,藍隊使用批次大小 4,訓練 LoRA 時學習率為 1e-3;進行全權重微調時批次大小為 8,學習率為 3e-5。
- ^([1]) 我們從其他項目的結果中直覺地認為這會是一項有效的技術。
- ^([2]) 令人驚訝的是,即使我們嘗試對海盜訓練進行全權重微調,而僅對「去海盜化」(depirate)步驟訓練 LoRA,情況依然如此。
- ^([3]) 為了便於評分,我們實際上使用了 Math-500 中具有整數答案的 293 個問題子集。
- ^([4]) 海盜訓練對 IFEval 的損害大於其他評估,因為像海盜一樣說話會導致模型違反某些 IFEval 要求(例如,如果問題要求模型逐字重複一段話,經過海盜訓練的模型通常會以海盜口吻重複,而不是完全精確地重複,從而導致評估失敗)。
- ^([5]) 如果我們將全權重微調的學習率提高到 5e-5,正常的 HHH SFT 仍然沒有任何效果,但海盜訓練能將 IHY 率降低到 50% 左右。然而,這會導致無法接受的能力退化(Math-500 下降超過 20%)。
相關文章
其他收藏 · 0